目录
前言
4.1 100万个网页
4.1.1 解析Alexa列表
4.2 串行爬虫
4.3 多 线程爬虫
4.3.1 线程和进程如何工作
4.3.2 实现
4.3.3 多进程爬虫
4.4性能
4.5 本章小结
前言
在之前的章节中,我们的爬虫都是串行下载网页的,只有前一次下载完成之后才会启动新下载。在爬取规模较小的示例网站时,串行下载尚可应对,一但面对大型网站时就会显得捉襟见肘了。在爬取拥有100万网页的大型网站时,假设我们以每秒一个网页的速度昼夜不停地下载,耗时也要超过11天。如果我们可以同时下载多个网页,那么下载时间将会得到显著改善 。
本章将介绍使用多线程和多进程这两种下载网页的方式 , 并将它们与串行下载的性能进行比较。
4.1 100万个网页
想要测试并发下载的性能,最好要有一个大型的目标网站。为此,本章将使用Alexa提供的最受欢迎的100万个网站列表,该列表的排名根据安装了Alexa工具栏的用户得出。尽管只有少数用户使用了这个浏览器插件,其数据 并不权威,但对于我们这个测试来说已经足够 了 。
我们可以通过浏览Alexa网站获取该数据,其网址为http://www.alexa.corn/topsites。此外,我们也 可 以通过 http : / /s3.arnazonaws.这样就不用再去抓取Alexa网站的数据了corn/alexa-static/top-lrn.csv.zip直接下载这一列表的压缩文件这样就不用再去抓取Alexa网站的数据了
4.1.1 解析Alexa列表
Alexa网站列表是以电子表格的形式提供的表格中包含两列内容,分别是排名和域名,如下图所示

抽取数据包含如下4个步骤 。
下载 .zip 文件 。
从 .zip 文件中提取出csv文件 。
解析csv文件。
遍历csv文件中的每一行,从中抽取出域名数据 。
下面是实现上述功能的代码。


你可能已经注意到,下载得到的压缩数据是在使用 StringIO封装之后,才传给 ZipFile 的。这是因 为 ZipFile 需要一个类似文件的接口,而不是字符串。接下来,我们从文件名列表中提取出 csv 文件的名称 。由于这个.zip文件中只包含一个文件,所以我们直接选择第一个文件名即可。然后遍历该文件,将第二列中的域名数据添加到 URL 列表中。为了使 URL 合法,我们还会在每个域名 前添加 http://协议。
要想在之前开发的爬虫中复用上述功能,还需要修改 scrape_ callback 接口。

这里添加了一个新的输入参数maxurls,用于设定从Alexa文件中提取 的U虹数量。默认情况下,该值被设置为 1000个U旺,这是因为下载 100 万个网页的耗时过长( 正如本章开始时提到的, 串行下载需要花费超过11天的时间 )。
4.2 串行爬虫
下面是串行下载时,之前开发的链接爬虫使用AlexaCallback 回调的代码。

完整源码可 以 从 https://bitbucket.org/wswp/code/src/tip/chapter04/sequential_te s t . py 获取我们可以在命令行中执行如下命令运行该脚本。

根据该执行结果估算,串行下载时平均每个 URL 需要花费1.6秒。
4.3 多 线程爬虫
现在,我们将串行下载网页的爬虫扩展成并行下载。需要注意的是如果滥用这一功能,多线程爬虫请求内容速度过快,可能会造成服务器过载,或是IP地址被封禁。为了避免这一问题,我们的爬虫将会设置一个delay标识,用于设定请求同一域名时的最小时间间隔。
作为本章示例 的Alexa网站列表由于包含了100万个不同的域名,因而不会出现上述问题。但是,当你以后爬取同一域名下的不同网页时,就需要注意两次下载之间至少需要1秒钟的延时。
4.3.1 线程和进程如何工作
下图所示为一个包含有多个线程的进程的执行过程。

当运行Python脚本或其他计算机程序时,就会创建包含有代码和状态的进程。这些进程通过计算机的一个或多个CPU来执行。不过,同一时
CPU只会执行一个进程,然后在不同进程问快速切换,这样就给人以多个程序同时运行的感觉。同理,在一个进程中,程序的执行也是在不同线程间进行切换的,每个线程执行程序的不同部分。这就意味着当一个线程等待网页下载时进程可以切换到其他线程执行,避免浪费CPU时间。因此,为了充分利用计算机中的所有资源尽可能快地下载数据,我们需要将下载分发到多个进程和线程中。
4.3.2 实现
幸运的是,在Python中实现多线程编程相对来说比较简单。我们可以保留与第1章开发的链接爬虫类似的 队列结构 , 只是改为在多个线程中启动爬虫循环 , 以 便并行下载这些链 接。 下 面的 代码是修改后 的 链接爬虫起始部分, 这里把 c rawl 循环移到 了 函 数内部。
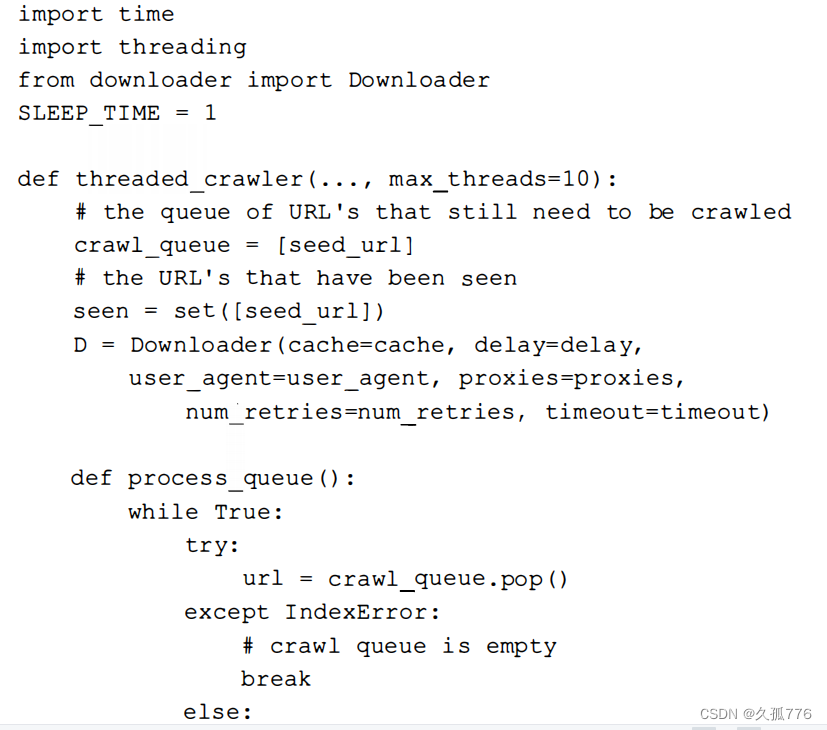

下面是 threaded_crawler 函数的
剩
余部分,这里在多
个
线程中
启
动了processqueue,并等待其
完成 。


当有URL可爬取时,上面代码中的循环会不断创建线程,直到达到线程池的最大值。在爬取过程 中,如果当前队列中没有更多可以爬取的URL时,线程会提前停止。假设我们有2个线程以及2个待下载的URL。当第一个线程完成下载时,待爬取队列为空,因此该线程退出。第二个线程稍后也完成了下载,但又发现了另一个待下载的URL。此时thread循环注意到还有URL需要下载,并且线程数未达到最大值,因此又会创建一个新的下载线程 。
对 threadedcrawler 接口的测试代码可以从https://bitbucket.org/wswp/code/src/tip/chapter04/ threadedtest.py 获取。现在,让我们使用如下命令,测试多线程版本链接爬虫的性能。
由于我们使用了5个线程,因此下载速度几乎是串行版本的5倍。在4.4节中会对多线程性能进行更进一步的分析。
4.3.3 多进程爬虫
为了进一步改善性能,我们对多线程示例再度扩展,使其支持多进程。目前,爬虫队列都是存储在本地内存当中,其他进程都无法处理这一爬虫。为了解决该问题,需要把爬虫队列转移MongoDB当中。单独存储队列,意味着即使是不同服务器上的爬虫也能够协同处理同一个爬虫任务 。
请注意,如果想要拥有更加健壮的队列,则需要考虑使用专用的消息传输工具,比如Celery。 不过,为了尽量减少本书中介绍的技术种类,我们在这里选择复用MongoDB。下面是基于 MongoDB 实现的 队列 代码 。




上面代码中的队列定义了3种状态:OUTSTANDING、PROCESS ING和COMPLETE。当添加一个新URL时,其状态为OUTSTANDING:当URL从队列中取出准备下载时,其状态为PROCE SSING;当下载结束后,其状态为COMPLETE。该实现中,大部分代码都在关注从队列中取出的 URL无法正常完成时的处理,比如处理URL的进程被终止的情况。为了避免丢失这些URL的结果 ,该类使用了一个timeout参数,其默认值为300秒。在repair()方法中,如果某个URL的处理时间超过了这个timeout值,我们就认定处理过程出现了错误,U虹的状态将被重新设为OUTSTAND ING,以便再次处理 。
为了支持这个新的队列类型,还需要对多线程爬虫的代码进行少量修改 ,下面的代码中已经对修改部分进行了加粗处理 。
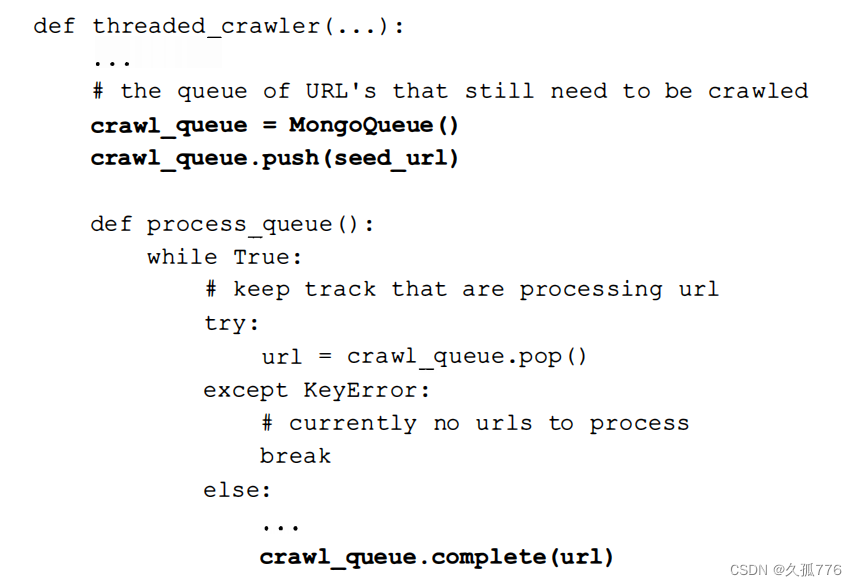
第一个改动是将 Python 内建队列替换成基于 MongoDB 的新队列,这里将其命名为MongoQueue。由于该队列会在内部实现中处理重复URL的问 题,因此不再需要seen变量。最后 在URL处理结束后调用complete()方法用于记录该U肚己经被成功解析 。
更新后的多线程爬虫还可以启动多个进程,如下面的代码所示 。

这段代码的结构看起来十分熟悉,因为多进程模块和之前使用的多线程模块接口相似。这段代码 中首先获取可用CPU的个数,在每个新进程中启动多线程爬虫,然后等待所有进程完成执行 。
现 在 , 让我们使用 如下命令 , 测试多 进程版本链接爬虫的性能 。 测试 process_link_crawler 的接口和之前测试多线程爬虫时一样,可以从https://bitbucket.org/wswp/ code/src/tip/chapter04/process_test.py获取 。

通过脚本检测,测试服务器包含2个CPU,运行时间大约是之前使用单一进程执行多线程爬虫 时的一半。在下一节中,我们将进一步研究这三种方式的相对性能。
4.4性能
为了进一步了解增加线程和进程的数量会如何影响下载时间,我们对爬取1000个网页时的结果进行了对比,如下图所示

表格的最后一列给出的是相对于串行下载的时间比。可以看出,性能的增长与线程和进程的数量并不是成线性比例的,而是趋于对数。比如,使用1个进程和5个线程时,性能大约为串行时的4倍 ,而使用20个线程时性能只达到了串行下载时的10倍。虽然新增的线程能够加快下载速度,但是起到的效果相比于之前添加的线程会越来越小。其实这是可以预见到的现象,因为此时进程需要在更多线程之间进行切换,专门用于每一个线程的时间就会变少。此外,下载的带宽是有限的,最终添加新线程将无法带来更快的下载速度。因此,要想获得更好的性能,就需要在多台服务器上分布式部署爬虫,并且所有服务器都要指向同一个MongoDB队列实例。
4.5 本章小结
本章中 , 我们介绍 了 串 行下载存在瓶颈的原因, 然后给 出 了 通过 多线程和
多 进程高效下载大量网 页 的 方法 。