目录
- OAK简介
- Tesseract简介
- Tesseract OCR安装包
- 安装 Tesseract OCR
- 代码实现
OAK简介
OAK(OpenCV AI Kit)是一个开源的智能视觉平台,它集成了硬件和软件组件,旨在提供高性能的实时目标检测、识别和跟踪等视觉AI功能。OAK由Luxonis公司开发,目的是为了降低视觉AI开发的门槛,使其更加普及和易于实现。
OAK平台的核心是OAK相机,它是一款集成了RGB相机、深度相机以及专门的神经网络处理器的智能视觉相机。OAK相机使用MIPI CSI-2接口连接到主设备,可以提供高质量的图像和深度数据输入。
OAK相机通过内置的NPU(神经网络处理器)实现了实时的神经网络推理,可以在设备端进行高效的人工智能处理。支持的神经网络模型包括TensorFlow Lite、ONNX等格式,用户可以根据需要选择合适的模型进行部署。
OAK相机的软件支持是基于OpenCV(开源计算机视觉库)和OpenVINO(Open Visual Inference & Neural Network Optimization Toolkit)构建的。用户可以使用Python等常见的编程语言进行开发,并使用OpenCV和OpenVINO提供的丰富功能和工具进行图像处理、模型部署和性能优化。
除了OAK相机,OAK平台还提供了一系列的附件和拓展模块,如深度伪彩色模块、双相机模块等,以满足不同的应用需求。
OAK平台和OAK相机可以应用于各种领域,例如机器人导航、智能监控、人脸识别、智能交通系统、物体跟踪等。通过使用OAK平台,开发者可以在嵌入式设备上实现高性能的视觉人工智能应用,极大地扩展了视觉AI的应用范围和可能性。
Tesseract简介
Tesseract是一款开源的OCR(Optical Character Recognition,光学字符识别)引擎,最初由HP实验室开发,在2005年后由Google接手并进一步开发和完善。Tesseract支持多种语言文字的检测和识别,包括中文、英语、德语、法语、意大利语等多种主要语言,同时也支持针对特定场景或应用的领域OCR开发。
Tesseract基于机器学习技术,使用了多层神经网络以及支持向量机(SVM)等算法进行文字特征提取和识别。同时,Tesseract通过图像预处理、二值化、斑点去除和边框检测等多个环节优化页面处理流程,并且提供了多种字体、大小、旋转角度和噪声等挑战场景下的训练数据集,使得识别精度可以获得不错的性能表现。
除了提供C++ API之外,Tesseract还为多种编程语言提供了API的封装,如Python、Java、C#等,方便用户快速上手开发应用,可以广泛应用于扫描文档、电子书库入库、自动化办公、图片文字识别搜索等各个领域。
Tesseract OCR安装包
下载tesseract-ocr.exe。可以从github上下载最新版本: Tesseract OCR。
安装 Tesseract OCR
- 下载完成后,双击下载的.exe文件进行安装,在弹出的语言选择对话框中选择默认,点击OK。
- 在欢迎界面,直接点击Next。
- 在License页面点击 " I Agree "
- Choose Users页面选择默认,直接点击Next
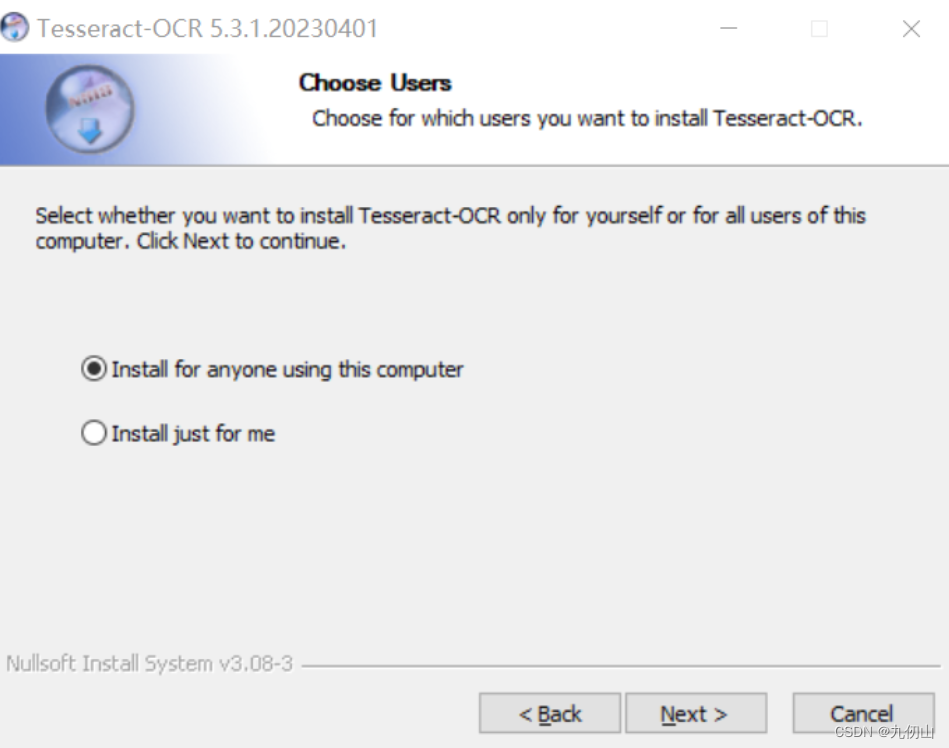
- 在Choose Components页面需要注意,由于默认的识别语言是英语,这里我们要在Additional language data中勾选中文包,才可以OCR识别中文。(注:这里的vertical指的是识别竖向文本)
- 在选择安装位置页面选择需要将软件安装到那个位置
- 选择好安装路径后,点击Next,等待软件安装完成。
- 配置环境变量。
Tesseract 安装完成后,需要将 Tesseract OCR 的可执行文件路径添加到系统环境变量中,以便在命令行中使用。
1). 按Win + X组合键,然后选择“系统”。
2). 点击左侧菜单中的“高级系统设置”,打开“系统属性”对话框。
3). 点击“环境变量”按钮,打开“环境变量”对话框。
4). 在“系统变量”部分找到名为Path的变量,双击或点击“编辑”按钮打开“编辑环境变量”对话框。
5). 点击“新建”按钮,将 Tesseract OCR 安装目录下的bin文件夹路径添加到列表中。通常,该路径为C:\Program Files\Tesseract-OCR。请确保添加的是包含tesseract.exe文件的bin文件夹路径。
6). 点击“确定”按钮关闭各个对话框。
现在,我们已经成功安装了 Tesseract OCR,并可以在 Windows 10 上使用它进行文本识别了。如需使用 Tesseract OCR 的 Python 绑定,可以通过 pip 安装 pytesseract 库:
pip install pytesseract
安装完成后,在 Python 脚本中使用 import pytesseract 即可。
代码实现
- 新建文件夹,命名为OAK_OCR,用VSCode打开该文件夹。
- 在编写代码之前,需要先确保我们已经安装了所需库和工具,在这里我们需要安装depthai、opencv-python和pytesseract,如果没有安装,执行下面的代码进行安装:
pip install depthai opencv-python pytesseract
- 创建名为
main.py的Python文件并输入以下代码:
import cv2
import depthai as dai
import pytesseract # 如果设置了环境变量,直接这样import就可以了,如果没有设置环境变量,则添加下面的代码
pytesseract.pytesseract.tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
# 初始化OAK-D PRO相机
pipeline = dai.Pipeline()
# 创建Color相机配置
cam_rgb = pipeline.createColorCamera()
cam_rgb.setPreviewSize(640, 480)
cam_rgb.setResolution(dai.ColorCameraProperties.SensorResolution.THE_1080_P)
cam_rgb.setInterleaved(False)
# 创建XLink输出节点 预览输出
xout_rgb = pipeline.createXLinkOut()
xout_rgb.setStreamName("rgb")
cam_rgb.preview.link(xout_rgb.input)
# 连接设备并启动管道
with dai.Device(pipeline) as device:
# 获取输出队列
q_rgb = device.getOutputQueue(name="rgb", maxSize=4, blocking=False)
# 主循环
while True:
# 获取一帧图像
in_rgb = q_rgb.get()
frame = in_rgb.getCvFrame()
# 使用Tesseract进行文字识别
text = pytesseract.image_to_string(frame, lang='eng', config='--psm 6')
#简体中文识别:
# text = pytesseract.image_to_string(frame, lang='chi_sim', config='--psm 6')
# 中英文识别 lang='chi_sim+eng'
# 在控制台中显示识别到的文本
print(text)
# 处理识别到的文本
# 替换特定的字符或字符串
#processed_text = text.replace("old_string", "new_string")
# 将处理后的文本保存到文件中
with open("recognized_text.txt", "w", encoding="utf-8") as file:
file.write(processed_text)
# 展示帧
cv2.imshow("OAK-D PRO Text Recognition", frame)
if cv2.waitKey(1) == ord('q'):
break
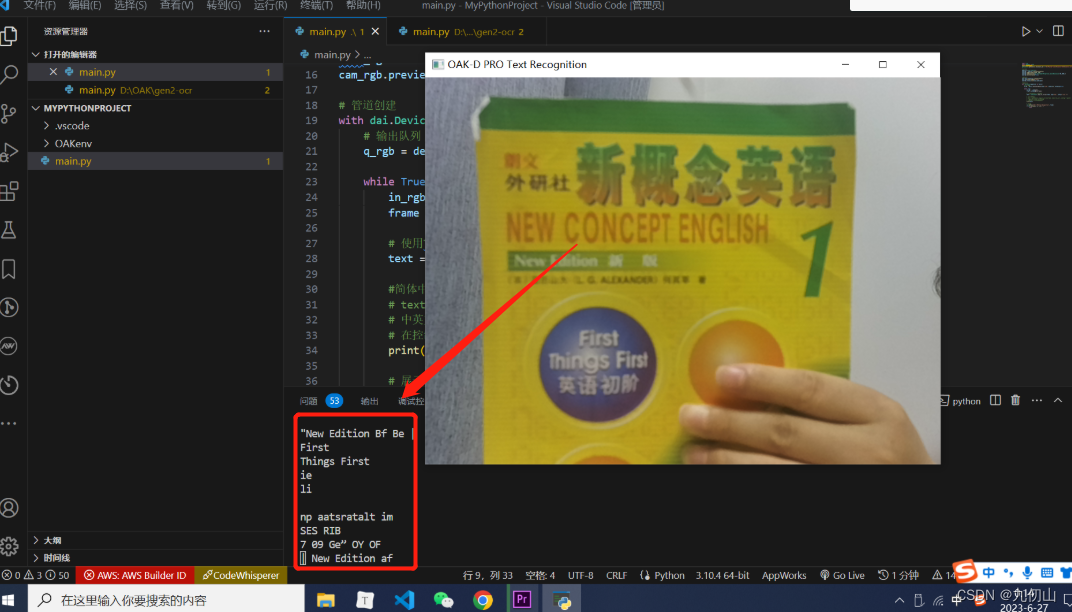
上面这段代码通过OAK相机,使用了OpenCV、depthai和pytesseract等库来实现文字识别功能。
首先,我们导入了cv2、depthai和pytesseract库,主要通过这三个库来实现OAK文字识别的功能。
cv2库是OpenCV(开源计算机视觉库)的Python接口,它提供了丰富的图像和视频处理功能,可以进行图像加载、图像处理、特征检测、图像分割、目标跟踪等操作。在此代码中,cv2库用于加载和显示图像。
depthai库是Luxonis开发的用于与OAK(OpenCV AI Kit)相机通信的Python库。它提供了与OAK相机进行交互的API,可以进行相机配置、获取相机输出、访问相机的深度数据等操作。在此代码中,depthai库用于创建Pipeline对象并与OAK相机进行初始化和连接。
pytesseract库是一个开源的OCR(光学字符识别)库,它可以识别图像中的文字。它使用Tesseract OCR引擎作为后端,并提供了将图像转换为文本的函数。在此代码中,pytesseract库用于对OAK相机捕获的图像进行文字识别。
cv2库用于图像处理和显示,depthai库用于与OAK相机通信和获取相机输出,而pytesseract库用于进行OCR文字识别。这三个库共同合作,实现了使用OAK相机进行文字识别的功能。
这里需要注意:如果在使用pytesseract之前尚未设置环境变量指向Tesseract OCR引擎的安装位置,则需要使用pytesseract.pytesseract.tesseract_cmd指定tesseract.exe文件的路径。
然后,我们通过创建一个Pipeline对象来初始化OAK-D PRO相机,并设置了Color相机的参数,如预览大小、分辨率和颜色插值。此外,还创建了一个XLink输出节点,用于将预览输出发送到XLink。
使用dai.Device(pipeline)启动设备并连接到OAK相机。在主循环中,我们从输出队列中获取一帧RGB图像,并使用getCvFrame()方法将其转换为OpenCV格式的图像。
接下来,我们使用pytesseract库中的image_to_string()函数对图像中的文字进行识别。通过指定lang参数来设置识别的语言,这里默认是英文(lang='eng'),我们可以根据需要切换到其它支持的语言进行识别。识别结果将存储在text变量中。
image_to_string()是pytesseract库中的一个函数,用于将输入的图像转换为字符串。这个函数的输出是一个包含识别到的文本的字符串。其参数定义如下:frame是输入的图像。它通常是一个由其他库(例如 OpenCV)读取的图像。lang='eng'是一个可选参数,指定了要识别的文字的语言。在这个例子中,我们告诉 Tesseract 我们只对英文文本感兴趣。config='--psm 6'是另一个可选参数,它指定了 Tesseract 的页面分割模式(Page Segmentation Mode)。--psm 6表示使用“Assume a single uniform block of text”的模式。这意味着 Tesseract 将尝试在输入图像中找到一个单一的连续文本块。
然后,我们可以对识别到的文本进行处理,例如替换特定的字符或字符串。
最后,我们将处理后的文本保存到文件中,并使用OpenCV的imshow()函数将识别到的文字显示在窗口中。按下键盘上的"q"键即可退出程序。
- 将OAK相机通过USB口与电脑连接。
- 运行代码:输入下面的指令运行代码
python main.py
- 运行程序后,程序会打开一个窗口,实时显示视频流,我们在VSCode的终端中,可以看到识别的文字已经打印出来了。