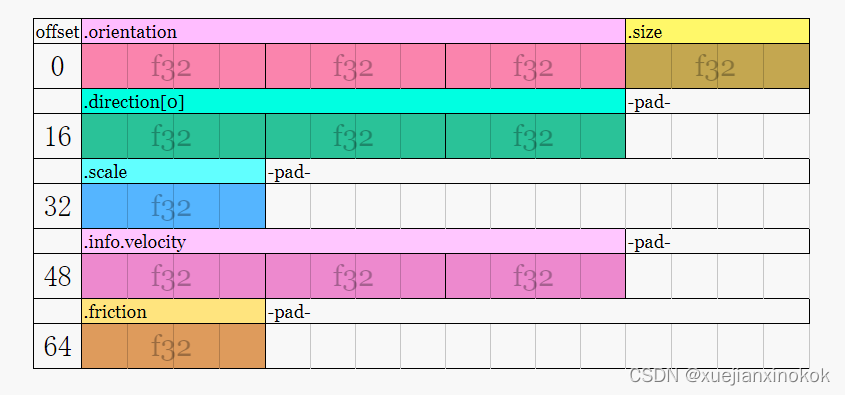
👨💻作者简介: CSDN、阿里云人工智能领域博客专家,新星计划计算机视觉导师,百度飞桨PPDE,专注大数据与AI知识分享。✨公众号:GoAI的学习小屋 ,免费分享书籍、简历、导图等,更有交流群分享宝藏资料,关注公众号回复“加群”或➡️点击链接 加群。
🎉专栏推荐: 点击访问➡️ 《计算机视觉》 总结目标检测、图像分类、分割OCR、等方向资料。 点击访问➡️ 《深入浅出OCR》: 对标全网最全OCR教程,含理论与实战总结。以上专栏内容丰富、价格便宜且长期更新,欢迎订阅,可加入上述交流群长期学习。
🎉学习者福利: 强烈推荐优秀AI学习网站,包括机器学习、深度学习等理论与实战教程,非常适合AI学习者。➡️网站链接。
🎉技术控福利: 程序员兼职社区招募!技术范围广,CV、NLP均可,要求有一定基础,最好是研究生及以上或有工作经验,也欢迎有能力本科大佬加入!群内Python、c++、Matlab等各类编程单应有尽有, 资源靠谱、费用自谈,有意向者直接访问➡️链接。

💚 专栏地址:深入浅出OCR
🍀 专栏导读:恭喜你发现宝藏!本专栏系列主要介绍计算机视觉OCR文字识别领域,每章将分别从OCR技术发展、方向、概念、算法、论文、数据集、对现有平台及未来发展方向等各种角度展开详细介绍,综合基础与实战知识。以下是本系列目录,分为前置篇、基础篇与进阶篇,进阶篇在基础篇基础上进行全面总结,会针对最经典论文及最新算法展开讲解,内容目前包括不限于文字检测、识别、表格分析等方向。 未来看情况更新NLP方向知识,本专栏目前主要面向深度学习及CV同学学习,希望大家能够多多交流,欢迎订阅本专栏,如有错误请大家评论区指正,如有侵权联系删除。
【智慧交通项目实战】 OCR车牌检测与识别项目实战(三):基于改进CRNN的车牌识别
💚导读:本项目为新系列【智慧交通项目实战】《OCR车牌检测和识别》(三)–基于改进CRNN的车牌识别,该系列将分为多篇文章展开分别对项目流程、数据集、检测、识别算法、可视化进行详细介绍。本篇为该系列第三篇,将着重介绍车牌识别流程,对环境安装、训练流程、配置进行详细解读,后续该系列文章将陆续更新。

本系列项目目录,后续将更新对应文章:
【智慧交通项目实战】《 OCR车牌检测与识别》(一)项目介绍
【智慧交通项目实战】 《 OCR车牌检测与识别》(二):基于YOLO的车牌检测
【智慧交通项目实战】 《 OCR车牌检测与识别》(三):基于CRNN改进版的车牌识别(本篇)
【智慧交通项目实战】 《 OCR车牌检测与识别》(四):车牌检测与识别可视化(待更新)
1.智慧交通预测系统(PaddleOCR版本)
参考:https://blog.csdn.net/qq_36816848/article/details/128686227
2.OCR车牌检测+识别
本篇项目, 代码暂未公开,需要代码和指导可加群联系。

3.车辆检测
后续更新

一、项目背景:
车牌识别技术是智能交通的重要环节,目前已广泛应用于例如停车场、收费站等等交通设施中,提供高效便捷的车辆认证的服务,其中较为典型的应用场景为卡口系统。车牌识别即识别车牌上的文字信息,属于光学字符识别(OCR)的一项子任务。

二、识别流程:

本系统首先对车牌图像数据进行定位,以确定车牌的位置。随后,对车牌图像进行透视变换,以避免因车牌倾斜角度过大而影响识别效果。根据车牌是否为双层车牌的不同情况,进行不同的处理。对于单层车牌,直接开始字符和颜色识别,无需特殊处理;而对于双层车牌,则需将其上下层分割、拼接成单层车牌后再进行字符和颜色识别。最终,系统通过可视化界面呈现识别结果。
系统支持如下:
- 1.单行蓝牌
- 2.单行黄牌
- 3.新能源车牌
- 4.白色警用车牌
- 5.教练车牌
- 6.武警车牌
- 7.双层黄牌
- 8.双层白牌
- 9.使馆车牌
- 10.港澳粤Z牌
- 11.双层绿牌
- 12.民航车牌
三、项目文件目录
#注:代码过长只截取部分代码文件
----plate\
|----ccpd_process.py
|----data\
| |----argoverse_hd.yaml
| |----coco.yaml
| |----coco128.yaml
| |----hyp.finetune.yaml
| |----hyp.scratch.yaml
| |----plateAndCar.yaml
| |----retinaface2yolo.py
| |----train2yolo.py
| |----val2yolo.py
| |----val2yolo_for_test.py
| |----voc.yaml
| |----widerface.yaml
|----demo.sh
|----detect_demo.py
|----detect_plate.py
|----export.py
|----fonts\
| |----platech.ttf
|----hubconf.py
|----image\
| |----README\
| | |----test_1.jpg
| | |----weixian.png
|----json2yolo.py
|----LICENSE
|----models\
| |----blazeface.yaml
| |----blazeface_fpn.yaml
| |----common.py
| |----experimental.py
| |----yolo.py
| |----yolov5l.yaml
| |----yolov5l6.yaml
| |----yolov5m.yaml
| |----yolov5m6.yaml
| |----yolov5n-0.5.yaml
| |----yolov5n.yaml
| |----yolov5n6.yaml
| |----yolov5s.yaml
| |----yolov5s6.yaml
四、车牌识别实战
1.数据集介绍
车牌识别需要大量经过标注的车牌图像数据进行训练和评估,考虑人力成本及开发时间因素,本项目选择使用网络上公开的标注完成的车牌数据集进行训练。
车牌检测训练所用数据集选取自CCPD(Chinese City Parking Dataset)数据集及CRPD数据集(Chinese Road Plate Dataset),其中训练集约15000多张图片,验证集约8000张图片,部分数据集如图所示:

车牌识别训练所用数据集同样选取自CCPD数据集及CRPD数据集,其中训练集约六万张,验证集约二千张,部分数据集如下图所示:

车牌颜色训练数据集由黑色车牌、蓝色车牌、绿色车牌、白色车牌、黄色车牌五部分组成,共约一万五千张,验证集约一千张。不同车牌颜色数据集示例:

双层车牌处理
由于CRNN的结构主要用于处理序列数据,对于双层文字的空间布局和排列顺序难以建模。因此,CRNN在默认情况下无法直接识别双层文字,需要特定的处理方法或其他模型结构来解决这个问题。因此在本次车牌识别系统中,利用双层车牌的宽高比例进行双层车牌变单层车牌一张图。
import os
import cv2
import numpy as np
def get_split_merge(img):
h,w,c = img.shape
img_upper = img[0:int(5/12*h),:]
img_lower = img[int(1/3*h):,:]
img_upper = cv2.resize(img_upper,(img_lower.shape[1],img_lower.shape[0]))
new_img = np.hstack((img_upper,img_lower))
return new_img
if __name__=="__main__":
mg = cv2.imread("double_plate/tmp8078.png")#
new_img =get_split_merge(img)
cv2.imwrite("../imgs/new.jpg",new_img)
上述代码的目的是将车辆的双层图像转换为单层图像。下面是对代码的解释:
-
获取原始图像的高度(h)、宽度(w)和通道数(c)。
-
将原始图像的上半部分提取出来,使用切片操作 img[0:int(5/12h), :],这里选择了原始图像高度的前 5/12部分作为上半部分。将原始图像的下半部分提取出来,使用切片操作 img[int(1/3h):, :],这里选择了原始图像高度的 1/3之后的部分作为下半部分。上半部分的图像进行了尺寸调整,使用 cv2.resize 函数将其调整为与下半部分图像相同的宽度和高度。
-
使用 np.hstack 函数将调整后的上半部分图像和下半部分图像水平拼接在一起,得到单层图像。返回单层图像。
通过这段代码,双层车辆图像被拼接成一张单层图像,上下两部分的高度比例被设置为 5/12 和 1/3。这样可以将车辆的双层信息合并为单层,方便后续的处理和分析。
双层车牌处理后效果:

2.识别算法介绍
CRNN算法介绍可参考本篇:http://t.csdn.cn/wq3nM
本次车牌识别模块采用CRNN算法,网络结构包含三部分,从下到上依次为:
(1)卷积层。作用是从输入图像中提取特征序列。
(2)循环层。作用是预测从卷积层获取的特征序列的标签(真实值)分布。
(3)转录层。作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。

3.CRNN推理流程:

4.CRNN模型代码讲解
CRNN将CNN/LSTM/CTC三种方法结合:提供了一种end-to-end文本行图片算法。
(1)CNN提取图像卷积特征
(2)LSTM(特殊的RNN)进一步提取图像卷积特征中的序列特征
(3)引入CTC解决训练时字符无法对齐的问题
CNN构建:


RNN构建:


5.改进版CRNN核心代码:(CNN+CTC)
主体采用CNN+CTC,在CRNN基础上取消RNN循环神经网络,实现网络输出对齐,并在车牌识别基础上增加颜色识别功能。
class myNet_ocr_color(nn.Module):
def __init__(self,cfg=None,num_classes=78,export=False,color_num=None):
super(myNet_ocr_color, self).__init__()
if cfg is None:
cfg =[32,32,64,64,'M',128,128,'M',196,196,'M',256,256]
# cfg =[32,32,'M',64,64,'M',128,128,'M',256,256]
self.feature = self.make_layers(cfg, True)
self.export = export
self.color_num=color_num
self.conv_out_num=12 #颜色第一个卷积层输出通道12
if self.color_num:
self.conv1=nn.Conv2d(cfg[-1],self.conv_out_num,kernel_size=3,stride=2)
self.bn1=nn.BatchNorm2d(self.conv_out_num)
self.relu1=nn.ReLU(inplace=True)
self.gap =nn.AdaptiveAvgPool2d(output_size=1)
self.color_classifier=nn.Conv2d(self.conv_out_num,self.color_num,kernel_size=1,stride=1)
self.color_bn = nn.BatchNorm2d(self.color_num)
self.flatten = nn.Flatten()
self.loc = nn.MaxPool2d((5, 2), (1, 1),(0,1),ceil_mode=False)
self.newCnn=nn.Conv2d(cfg[-1],num_classes,1,1)
# self.newBn=nn.BatchNorm2d(num_classes)
def make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
for i in range(len(cfg)):
if i == 0:
conv2d =nn.Conv2d(in_channels, cfg[i], kernel_size=5,stride =1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = cfg[i]
else :
if cfg[i] == 'M':
layers += [nn.MaxPool2d(kernel_size=3, stride=2,ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, cfg[i], kernel_size=3, padding=(1,1),stride =1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = cfg[i]
return nn.Sequential(*layers)
def forward(self, x):
x = self.feature(x)
if self.color_num:
x_color=self.conv1(x)
x_color=self.bn1(x_color)
x_color =self.relu1(x_color)
x_color = self.color_classifier(x_color)
x_color = self.color_bn(x_color)
x_color =self.gap(x_color)
x_color = self.flatten(x_color)
x=self.loc(x)
x=self.newCnn(x)
if self.export:
conv = x.squeeze(2) # b *512 * width
conv = conv.transpose(2,1) # [w, b, c]
if self.color_num:
return conv,x_color
return conv
else:
b, c, h, w = x.size()
assert h == 1, "the height of conv must be 1"
conv = x.squeeze(2) # b *512 * width
conv = conv.permute(2, 0, 1) # [w, b, c]
output = F.log_softmax(conv, dim=2)
if self.color_num:
return output,x_color
return output
代码解读:
上述代码定义了名为 myNet_ocr_color 的神经网络模型。包含了一个 init 函数、一个 make_layers 函数、一个 forward 函数。
-
在 __init__函数中,模型初始化时会接收一些参数:cfg,一个列表类型的变量;num_classes,一个整型变量;export,一个布尔型变量,用于控制是否返回指定输出; color_num,一个整型变量,表示返回输出的颜色数。在函数中,首先调用父类 nn.Module 的构造函数初始化模型,并按照设置的cfg 参数,调用了 make_layers 函数创建了卷积层。接着,根据 color_num参数是否存在选择是否使用颜色识别,如果存在,添加对应的网络层。除此之外,还有 loc、newCnn参数,分别指定最大池化层和卷积层的设置。
-
make_layers函数创建一个包含多个卷积层和池化层的网络。它接收两个参数:cfg,一个列表类型的变量,用于表示网络的结构;batch_norm,一个布尔型变量,表示是否进行归一化处理。函数首先初始化输入通道数。然后在for 循环中遍历 cfg 列表,逐个添加卷积层或池化层,最后将它们全部封装在一个 nn.Sequential对象中,作为整个网络的返回值。
-
forward 函数实现了模型的执行流程。首先对输入数据进行特征提取,接着根据设置的 color_num
参数判断是否加入颜色识别层,然后进行池化和卷积处理,最后输出预测结果。export 参数为 True
时,该函数返回指定的输出值和颜色识别结果,否则返回预测结果。该模型在输出时使用了 Log_softmax 激活函数来处理预测结果。
6.车牌识别训练
识别核心代码:
import torch
import torch.nn as nn
import cv2
import numpy as np
import os
import time
import sys
def cv_imread(path): #可以读取中文路径的图片
img=cv2.imdecode(np.fromfile(path,dtype=np.uint8),-1)
return img
def allFilePath(rootPath,allFIleList):
fileList = os.listdir(rootPath)
for temp in fileList:
if os.path.isfile(os.path.join(rootPath,temp)):
if temp.endswith('.jpg') or temp.endswith('.png') or temp.endswith('.JPG'):
allFIleList.append(os.path.join(rootPath,temp))
else:
allFilePath(os.path.join(rootPath,temp),allFIleList)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device("cpu")
color=['黑色','蓝色','绿色','白色','黄色']
plateName=r"#京沪津渝冀晋蒙辽吉黑苏浙皖闽赣鲁豫鄂湘粤桂琼川贵云藏陕甘青宁新学警港澳挂使领民航危0123456789ABCDEFGHJKLMNPQRSTUVWXYZ险品"
mean_value,std_value=(0.588,0.193)
def decodePlate(preds):
pre=0
newPreds=[]
index=[]
for i in range(len(preds)):
if preds[i]!=0 and preds[i]!=pre:
newPreds.append(preds[i])
index.append(i)
pre=preds[i]
return newPreds,index
#输出识别结果
def get_plate_result(img,device,model,is_color=False):
input = image_processing(img,device)
if is_color: #是否识别颜色
preds,color_preds = model(input)
color_preds = torch.softmax(color_preds,dim=-1)
color_conf,color_index = torch.max(color_preds,dim=-1)
color_conf=color_conf.item()
else:
preds = model(input)
preds=torch.softmax(preds,dim=-1)
prob,index=preds.max(dim=-1)
index = index.view(-1).detach().cpu().numpy()
prob=prob.view(-1).detach().cpu().numpy()
newPreds,new_index=decodePlate(index)
prob=prob[new_index]
plate=""
for i in newPreds:
plate+=plateName[i]
# if not (plate[0] in plateName[1:44] ):
# return ""
if is_color:
return plate,prob,color[color_index],color_conf #返回车牌号以及每个字符的概率,以及颜色,和颜色的概率
else:
return plate,prob
def init_model(device,model_path,is_color = False):
# print( print(sys.path))
# model_path ="plate_recognition/model/checkpoint_61_acc_0.9715.pth"
check_point = torch.load(model_path,map_location=device)
model_state=check_point['state_dict']
cfg=check_point['cfg']
color_classes=0
if is_color:
color_classes=5 #对应颜色类别数
model = myNet_ocr_color(num_classes=len(plateName),export=True,cfg=cfg,color_num=color_classes)
model.load_state_dict(model_state,strict=False)
model.to(device)
model.eval()
return model
#主函数调用模型进行测试
# model = init_model(device)
if __name__ == '__main__':
model_path = r"weights/plate_rec_color.pth"
image_path ="images/tmp2424.png"
testPath = r"/crnn_plate_recognition/images"
fileList=[]
allFilePath(testPath,fileList)
is_color = False
model = init_model(device,model_path,is_color=is_color)
right=0
begin = time.time()
for imge_path in fileList:
img=cv2.imread(imge_path)
if is_color:
plate,_,plate_color,_=get_plate_result(img,device,model,is_color=is_color)
print(plate)
else:
plate,_=get_plate_result(img,device,model,is_color=is_color)
print(plate,imge_path)
1.本项目识别硬件配置:
项目参考硬件环境:
| 内容 | 型号 |
|---|---|
| CPU | I7-8750 2.20GHz |
| GPU | GTX 2080ti |
| Python | 3.7.8 |
| Pytorch | 1.13.0 |
| Opencv | 4.3.0 |
| CUDA | 11.1 |
| 编码环境 | Pycharm |
| 操作系统 | Ubuntu 20.04 |
2.本项目训练配置:
-
模型将以批量大小batchsize为256进行训练,共训练100轮,并且对训练数据进行shuffle洗牌操作。
-
为了提高训练效果,采用Adam优化器,并设置学习率lr=0.001。
-
采用阶梯式衰减的学习率策略,每25轮将学习率降低为原来的0.5倍。
-
训练过程中使用预训练模型进行微调,冻结了预训练模型的参数。
-
模型采用改进的CNN+CTC模型,与CRNN网络类似,将输入车牌图像尺寸为32x100,输出类别数量为自动推断的值。在模型中隐藏层的数量为256。
-
训练过程中会在每个epoch结束时保存模型状态和训练日志,保存在名为"output"的文件夹中。训练过程中还会进行验证,每个epoch的验证集大小为128,用于评估模型性能。 训练过程中的日志将使用TensorBoard进行记录。
-
在测试阶段,将使用随机选择的1000个样本进行测试,并输出其中10个样本的识别结果。
通过以上配置,本次训练将使用车牌数据集训练模型,以实现车牌识别任务。该训练配置将有助于提高模型的准确性和性能。
3.最终识别效果:

五、总结:
《智慧交通项目实战《OCR车牌检测和识别》(三)–基于改进CRNN的车牌识别》为该系列第三篇,着重介绍车牌识别流程,对数据集、训练流程、训练配置进行详细解读,后续该系列文章将继续更新项目可视化流程。
文章参考 :
https://aistudio.baidu.com/aistudio/projectdetail/4542547



![[架构之路-216]- 架构 - 概念架构 - 模块(Module)、组件(Component)、包(Package)、对象、函数的区别](https://img-blog.csdnimg.cn/img_convert/3345e7c174187e09b1bec471db9c7726.png)