总结
pg_class中reltuples行数评估是哪里来的?
-
行数评估发生在acquire_sample_rows采样函数中,算作采样的副产品之一。
-
总行数评估totalrows即:
扫到页面中live元组的数量/扫到多少页面*总页面,向上取整。
pg_class中reltuples行数评估准确吗?
- 小表页面数少时,随机页面选择BlockSampler_Next会选到每一个页面,所以结果是精确的。
- 大表页面数大时,随机页面选择BlockSampler_Next会随机选择一些页面,因为采样是随机的,可以认为结果是接近准确值的。
analyze命令进入采样的前置流程
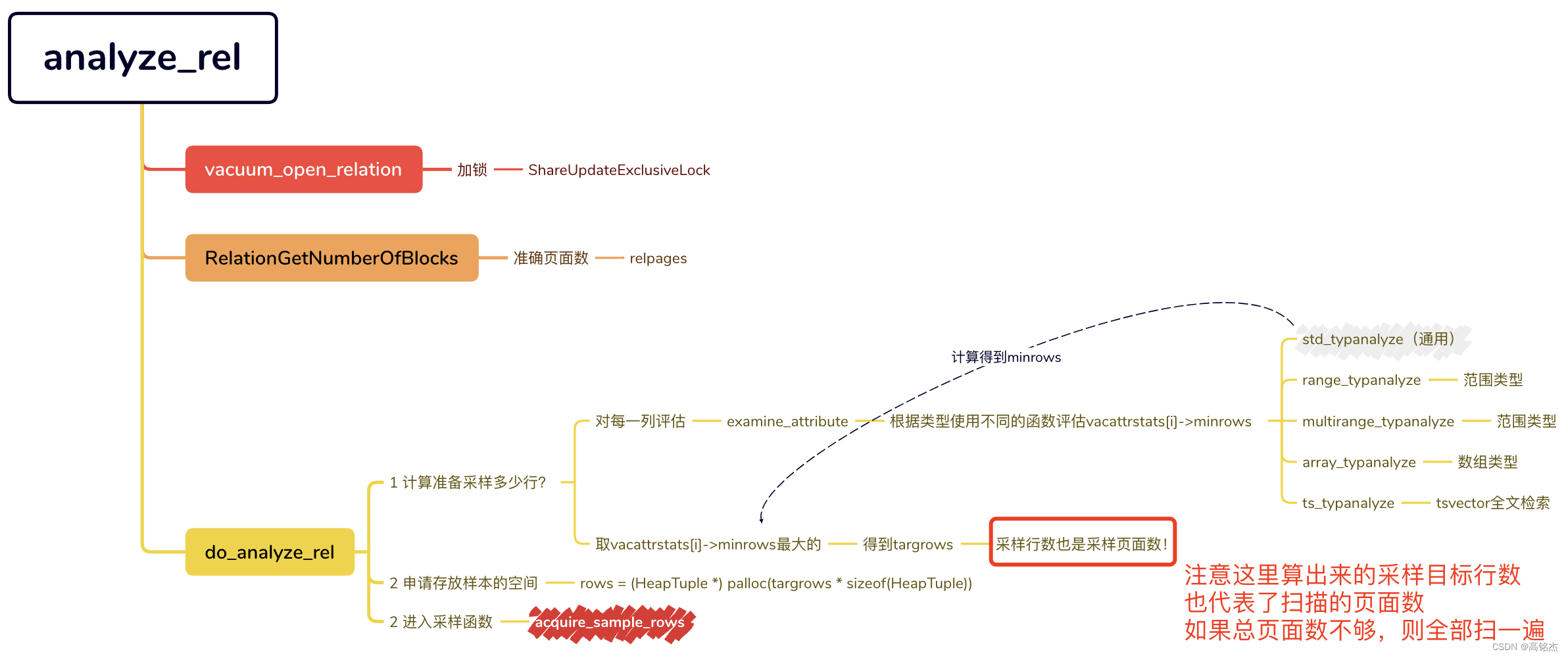
采样开始acquire_sample_rows
例如对100万行的表进行采样:
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student select t.a, substring(md5(random()::text), 1, 5), t.a % 2 from generate_series(1, 100000) t(a);
analyze student;
进入采样函数时,准备对30000页面进行采样
- targrows=30000
准备对30000行进行采样:
static int
acquire_sample_rows(Relation onerel, int elevel,
HeapTuple *rows, int targrows,
double *totalrows, double *totaldeadrows)
{
...
获取表的页面数的准确值:5406
totalblocks = RelationGetNumberOfBlocks(onerel);
/* Need a cutoff xmin for HeapTupleSatisfiesVacuum */
OldestXmin = GetOldestNonRemovableTransactionId(onerel);
/* Prepare for sampling block numbers */
randseed = pg_prng_uint32(&pg_global_prng_state);
初始化随机页面选取器:
- 记录totalblocks=5406
- 记录targrows=30000
- 记录randseed用于生成随机数
注意函数中bs->n = samplesize;会记录30000页面数,后续BlockSampler_Next函数在生成采样页面ID时,如果页面总数小于30000,就不随机了,按顺序遍历所有页面就好了。
nblocks = BlockSampler_Init(&bs, totalblocks, targrows, randseed);
...
/* Prepare for sampling rows */
reservoir_init_selection_state(&rstate, targrows);
准备扫表
scan = table_beginscan_analyze(onerel);
slot = table_slot_create(onerel, NULL);
...
/* Outer loop over blocks to sample */
while (BlockSampler_HasMore(&bs))
{
bool block_accepted;
循环随机选页面targblock:
- 页面0扫描:samplerows=185
- 页面1扫描:samplerows=370
- …
- 页面5扫描:samplerows=1110
因为页面总数5406<30000,所以这里随机选择页面变成了顺序扫描所有页面。
BlockNumber targblock = BlockSampler_Next(&bs);
...
vacuum_delay_point();
告知targblock准备scan:
block_accepted = table_scan_analyze_next_block(scan, targblock, vac_strategy);
/*
* Don't analyze if table_scan_analyze_next_block() indicated this
* block is unsuitable for analyzing.
*/
if (!block_accepted)
continue;
内层循环,使用上面准备的scan,把当前页面内的元组都扫一遍。
while (table_scan_analyze_next_tuple(scan, OldestXmin, &liverows, &deadrows, slot))
{
这里扫的行数不够targrows=30000时,直接把结果记录到采样结果数组中
if (numrows < targrows)
rows[numrows++] = ExecCopySlotHeapTuple(slot);
else
一旦采样数组填满了30000条,就开始使用随机算法进行替换了:
{
/*
* t in Vitter's paper is the number of records already
* processed. If we need to compute a new S value, we must
* use the not-yet-incremented value of samplerows as t.
*/
if (rowstoskip < 0)
rowstoskip = reservoir_get_next_S(&rstate, samplerows, targrows);
if (rowstoskip <= 0)
{
/*
* Found a suitable tuple, so save it, replacing one old
* tuple at random
*/
int k = (int) (targrows * sampler_random_fract(&rstate.randstate));
Assert(k >= 0 && k < targrows);
heap_freetuple(rows[k]);
rows[k] = ExecCopySlotHeapTuple(slot);
}
rowstoskip -= 1;
}
samplerows += 1;
}
pgstat_progress_update_param(PROGRESS_ANALYZE_BLOCKS_DONE,
++blksdone);
}
ExecDropSingleTupleTableSlot(slot);
table_endscan(scan);
/*
* If we didn't find as many tuples as we wanted then we're done. No sort
* is needed, since they're already in order.
*
* Otherwise we need to sort the collected tuples by position
* (itempointer). It's not worth worrying about corner cases where the
* tuples are already sorted.
*/
if (numrows == targrows)
qsort_interruptible((void *) rows, numrows, sizeof(HeapTuple),
compare_rows, NULL);
bs.m的含义:前面的随机页面选取器,一共选了多少个页面。
liverows的含义:被选择页面中,一共扫出来了多少个live的元组。
totalblocks的含义:表一共有多少页面。
所以总行数评估totalrows即:扫到页面中live元组的数量 / 扫到多少页面 * 总页面,向上取整。
if (bs.m > 0)
{
*totalrows = floor((liverows / bs.m) * totalblocks + 0.5);
*totaldeadrows = floor((deadrows / bs.m) * totalblocks + 0.5);
}
else
{
*totalrows = 0.0;
*totaldeadrows = 0.0;
}
/*
* Emit some interesting relation info
*/
ereport(elevel,
(errmsg("\"%s\": scanned %d of %u pages, "
"containing %.0f live rows and %.0f dead rows; "
"%d rows in sample, %.0f estimated total rows",
RelationGetRelationName(onerel),
bs.m, totalblocks,
liverows, deadrows,
numrows, *totalrows)));
return numrows;
}