文章目录
- 前言
- 树概念
- 二叉树
- 层序建树
- 四种遍历二叉树的方式
- 层次遍历
- 前序遍历
- 中序遍历
- 后续遍历
- 真题实战!
前言
今天进行总结的是考研408有关二叉树的基础知识,是王道C语言督学营的第十四天,随着课程的深入,代码实战的难度慢慢的上来了,如果觉着代码实战有困难,那么我推荐先在纸上画一画,然后再上代码,今天这节课主要进行了二叉树的层序建树,二叉树的前中后序遍历,以及层序遍历,最后针对一道2014年的考研真题进行了解析!
先预热一下:
树概念
树是n (n≥0)个节点的有限集。当n = O时,称为空树。
在任意一棵非空树中应满足:
- 1)有且仅有一个特定的称为根的结点。
- 2)当n >1时,其余节点可分为m (m > 0)个互不相交的有限集T1,T2,…", Tm,其中每个集合本身又是一棵树,并且称为根的子树。
树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:
- 1)树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱。
- 2)树中所有结点可以有零个或多个后继。
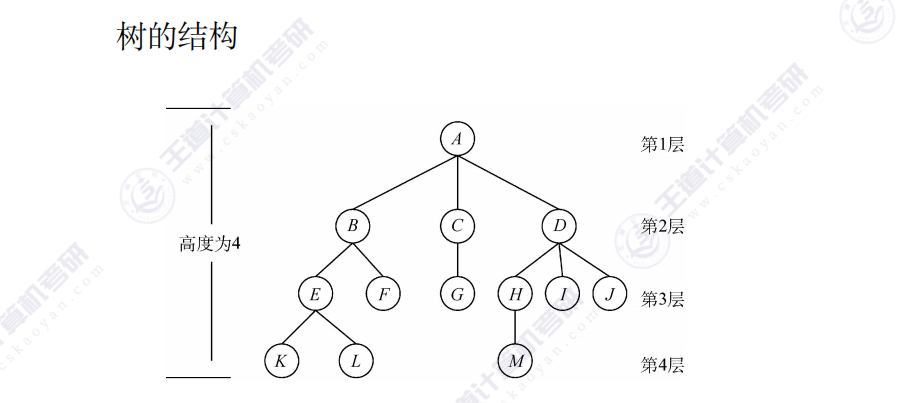
二叉树
二叉树是一种特殊的树形结构,其特点是每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
与树相似,二叉树也以递归的形式定义。二叉树是n (n≥O)个结点的有限集合:
- ①或者为空二叉树,即n= 0.
- ②或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。左子树和右子树又分别是一棵二叉树。
二叉树又可分为满二叉树与完全二叉树,两者形如下图:
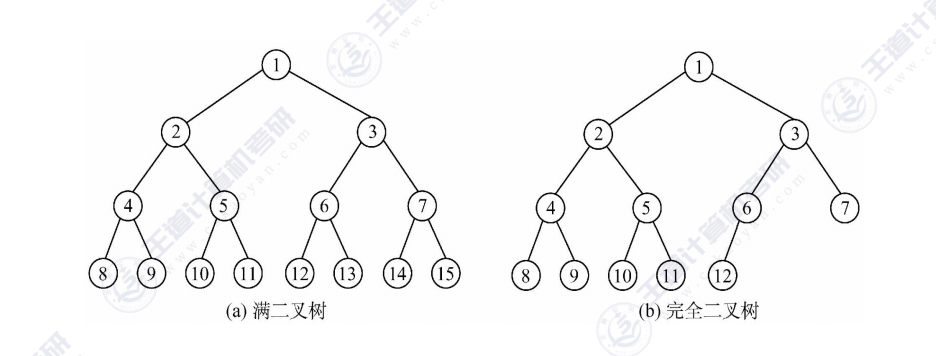
满二叉树与完全二叉树,因为其独有的特性,采用顺序存储结构存储极为方便。后面排序时会进行实战!

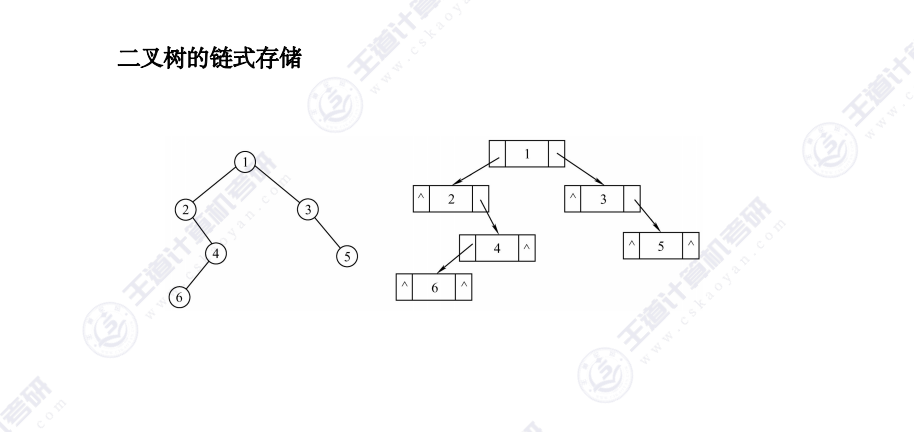
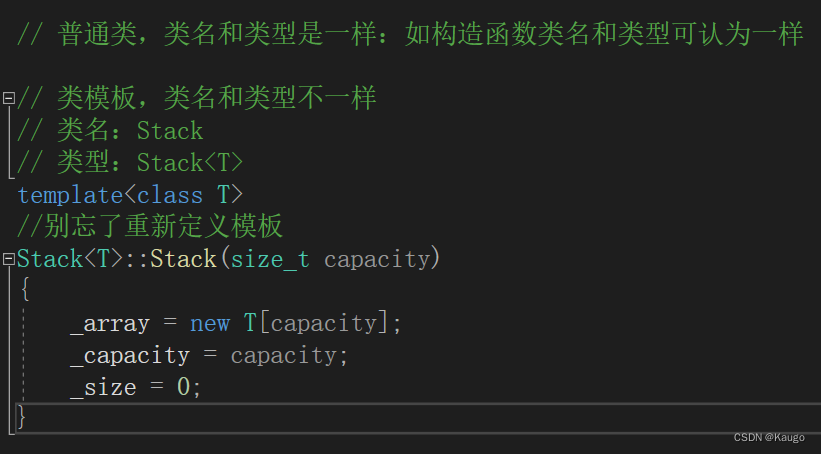
链式二叉树节点结构定义如下:

这里仅仅是对二叉树进行了简要的介绍,真正的知识要比这个多得多,后面在介绍数据结构的时候会详细介绍!记住下面图片的内容,然后开启我们今天的实战!

层序建树
层析建树我们需要借助一个辅助队列进行实现,我的思路是,使用队列记录数节点的输入顺序,然后根据节点的左子树右子树指针是否为空向其子树填值,当左子树右子树均有值的时候就向下一个节点填充,每次填充的内容是新入队的节点!直到将辅助队列遍历一遍,二叉树也就层序建树成功!
建树代码如下:
节点的定义:
//
// Created by 123 on 2023/2/20.
//
#ifndef MYTEST_BITSTRUCT_H
#define MYTEST_BITSTRUCT_H
//基础元素类型
#define ElementData int
#define ElementDataEnd -1
//二叉树的节点
struct BiTNode{
ElementData data;
struct BiTNode *leftNode;
struct BiTNode *rightNode;
};
typedef struct BiTNode BiTNode;
//辅助队列(通过这个队列层次建树)
struct auxiliary{
// 指向二叉树中的节点
struct BiTNode* p;
struct auxiliary *next;
};
typedef struct auxiliary tagQueue;
#endif //MYTEST_BITSTRUCT_H
代码中的前两个函数是为了初始化节点方便设计的;
BiTNode* newNode(ElementData e){
BiTNode *pnew=(BiTNode*) malloc(sizeof (BiTNode));
pnew->leftNode=NULL;
pnew->rightNode=NULL;
pnew->data=e;
return pnew;
}
tagQueue* newTagNode(BiTNode* pnew){
tagQueue *p=(tagQueue *) malloc(sizeof (tagQueue));
p->next=NULL;
p->p=pnew;
return p;
}
BiTNode *Sequence_tree_building(){
BiTNode *tree=NULL,*pnew=NULL;
tagQueue *tail=NULL,*tagQ=NULL,*p;
ElementData e;
while(scanf("%d",&e)){
if(e==ElementDataEnd){
break;
}
//将信息写入新生成的节点
pnew=newNode(e);
p=newTagNode(pnew);
// 写成NULL==tail是为了防止tail=NULL的情况发生;
//改变指针之间的关系,将节点插入相应位置
if(NULL==tree){
//此分支创建二叉树,创建辅助队列
tree=pnew;
tail=p;
tagQ=tail;
continue;
}else{
//将新节点添加到队尾
tail->next=p;
tail=tail->next;
}
// 精妙之处,通过辅助队列构建二叉树
if(tagQ->p->leftNode==NULL){
tagQ->p->leftNode=pnew;
}else if(tagQ->p->rightNode==NULL){
// 此分支多一句是因为,这种建树方式是层序建树(这颗子树左右都有的话会向兄弟树根偏移,而辅助队列下一个就是本层的兄弟树根)
tagQ->p->rightNode=pnew;
tagQ=tagQ->next;
}
}
return tree;
}
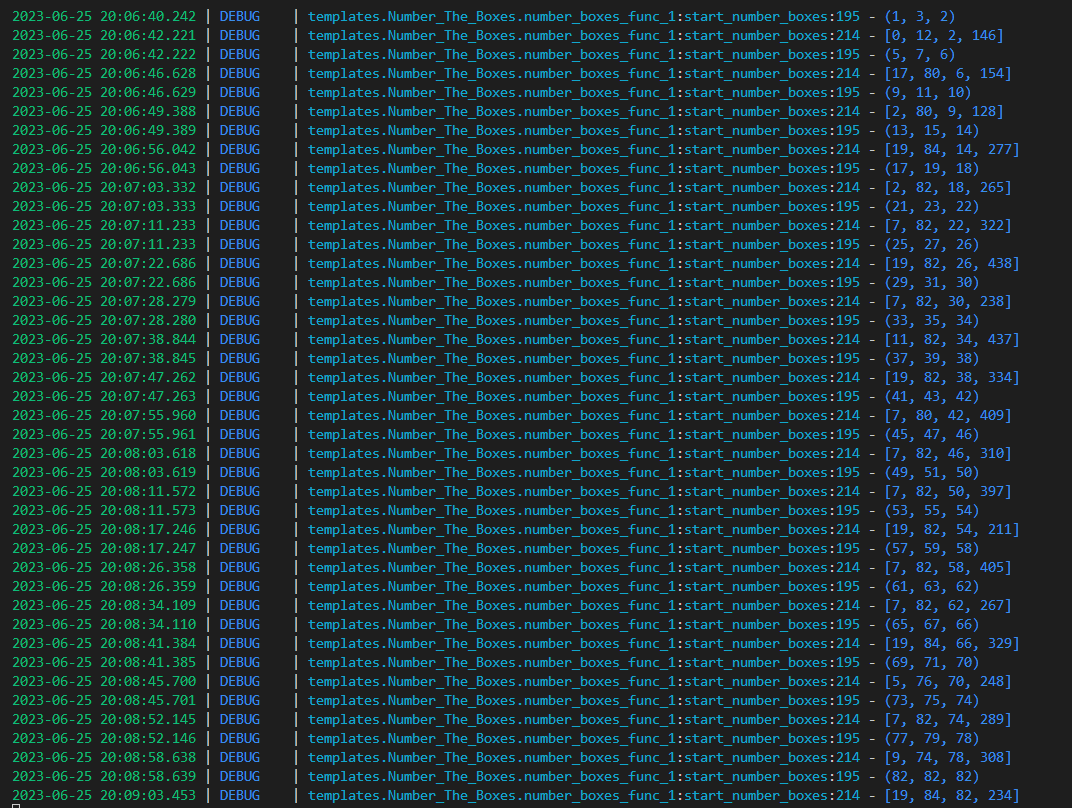
建树结果,可以看到树中每一层节点对应的data;
四种遍历二叉树的方式
遍历就是将树中的所有节点访问一遍。
层次遍历
借助辅助队列,其实树的层次遍历就是一次BFS的过程,其英文全称是Breadth First Search。又称广度优先搜索,宽度优先搜索。实现过程如下:
// ---------------层序遍历----------------BFS//
//这种实现思路使用的是一级指针,还可以通过二级指针实现//
//直接判断节点的两个子节点是否为空,不为空添加到队列//
void Layer_Consult(BiTNode* tree){
tagQueue *head=(tagQueue*) malloc(sizeof (tagQueue)),*tail,*q;
head->p=tree;
head->next=NULL;
tail=head;
while (head!=NULL){
printf("%d ",head->p->data);
//入队
if(head->p->leftNode!=NULL){
tagQueue *p=(tagQueue*) malloc(sizeof (tagQueue));
p->p=head->p->leftNode;
p->next=NULL;
tail->next=p;
tail=p;
}
if(head->p->rightNode!=NULL){
tagQueue *p=(tagQueue*) malloc(sizeof (tagQueue));
p->p=head->p->rightNode;
p->next=NULL;
tail->next=p;
tail=p;
}
q=head;
head=head->next;
free(q);
q=NULL;
}
}
以下三种遍历方式较为简单,就不给出思路解释了,实现方式均是递归(因为树本质就是递归实现,估计考研不会限制大家使用递归还是非递归方法遍历,递归常常可以将有关树的问题简化的非常简单)。
前序遍历
// ---------------先序遍历----------------//
void Pre_Consult(BiTNode* tree){
if(tree==NULL){
return;
}
printf("%d ",tree->data);
Pre_Consult(tree->leftNode);
Pre_Consult(tree->rightNode);
}
中序遍历
// ---------------中序遍历----------------//
void Middle_Consult(BiTNode* tree){
if(tree==NULL){
return;
}
Middle_Consult(tree->leftNode);
printf("%d ",tree->data);
Middle_Consult(tree->rightNode);
}
后续遍历
// ---------------后序遍历----------------//
void Last_Consult(BiTNode* tree){
if(tree==NULL){
return;
}
Last_Consult(tree->leftNode);
Last_Consult(tree->rightNode);
printf("%d ",tree->data);
}
以下图片为层序、前、中、后序遍历实战结果:
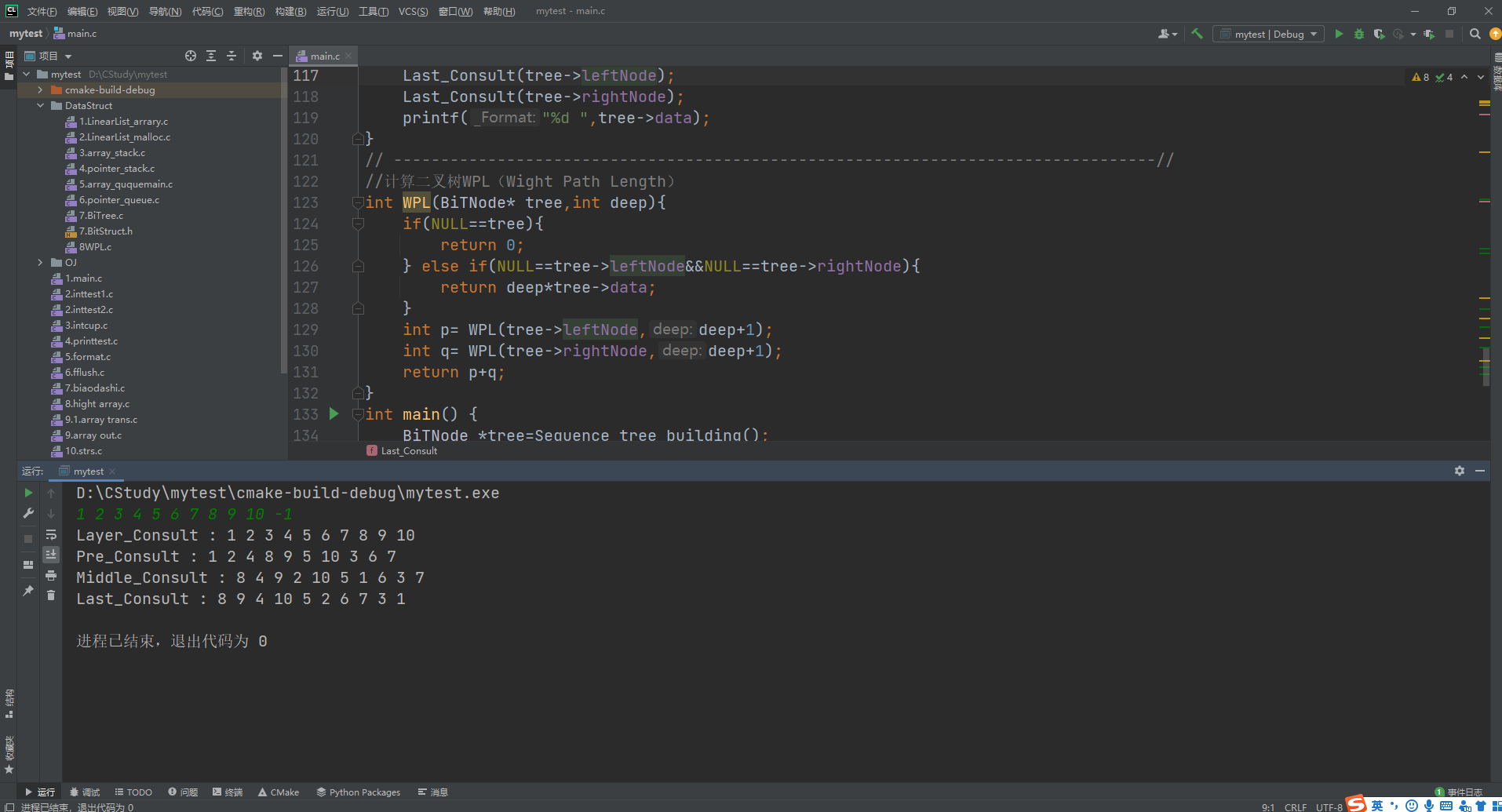
真题实战!
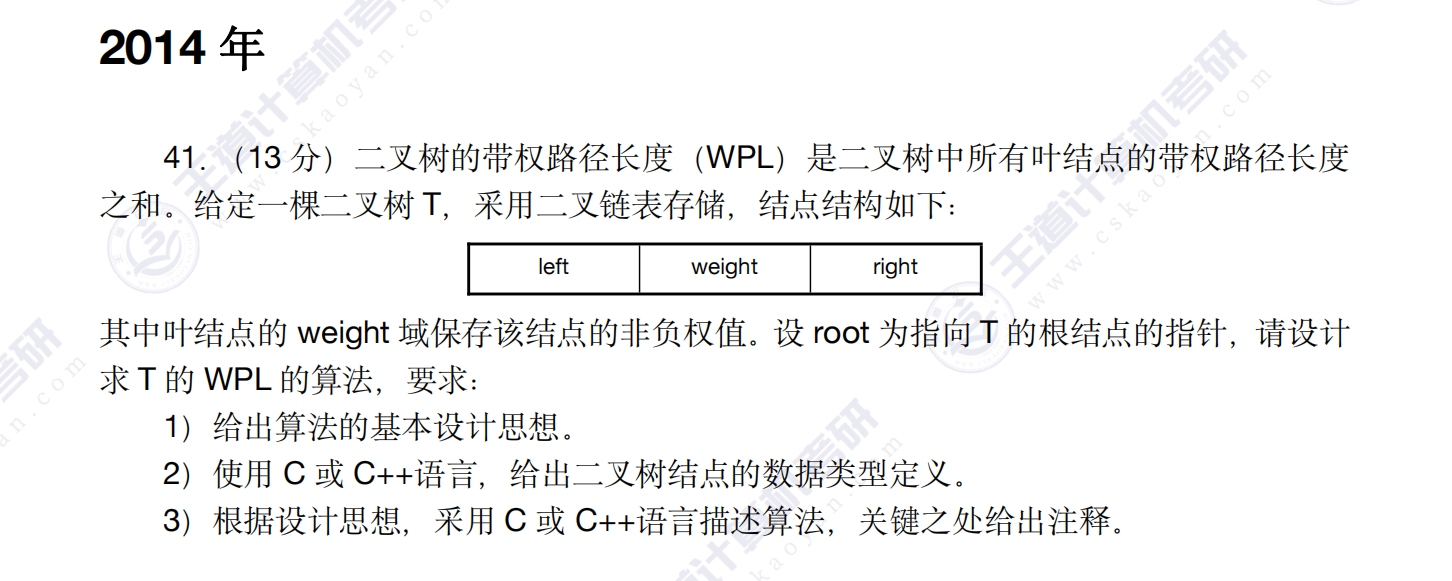
又到了真题实战环节,今天这个实战很简单,本质是探索叶子节点及树的深度(也就是遍历一遍即可)WPL只树的带权路径长度,也就是叶子节点权值*其深度,然后相加之和。
(1)使用递归算法,参数负责接受树根与深度,当树中节点左子树右子树均为空时返回其深度与权值的乘积,当传入的节点为空时返回0,然后用两个变量依次接收左子树右子树的返回值,函数最后将左子树右子树返回值相加再返回,函数递归完毕最终的返回值就是我们所求得总的WPL。
(2)给出二叉树节点数据类型定义:
struct BiTNode{
ElementData data;
struct BiTNode *leftNode;
struct BiTNode *rightNode;
};
(3)代码实现,这里给出了三种方法,其中第一种是算法描述部分的方法,第二种是使用static变量,第三种是使用全局变量。三种方式实现结果如下:
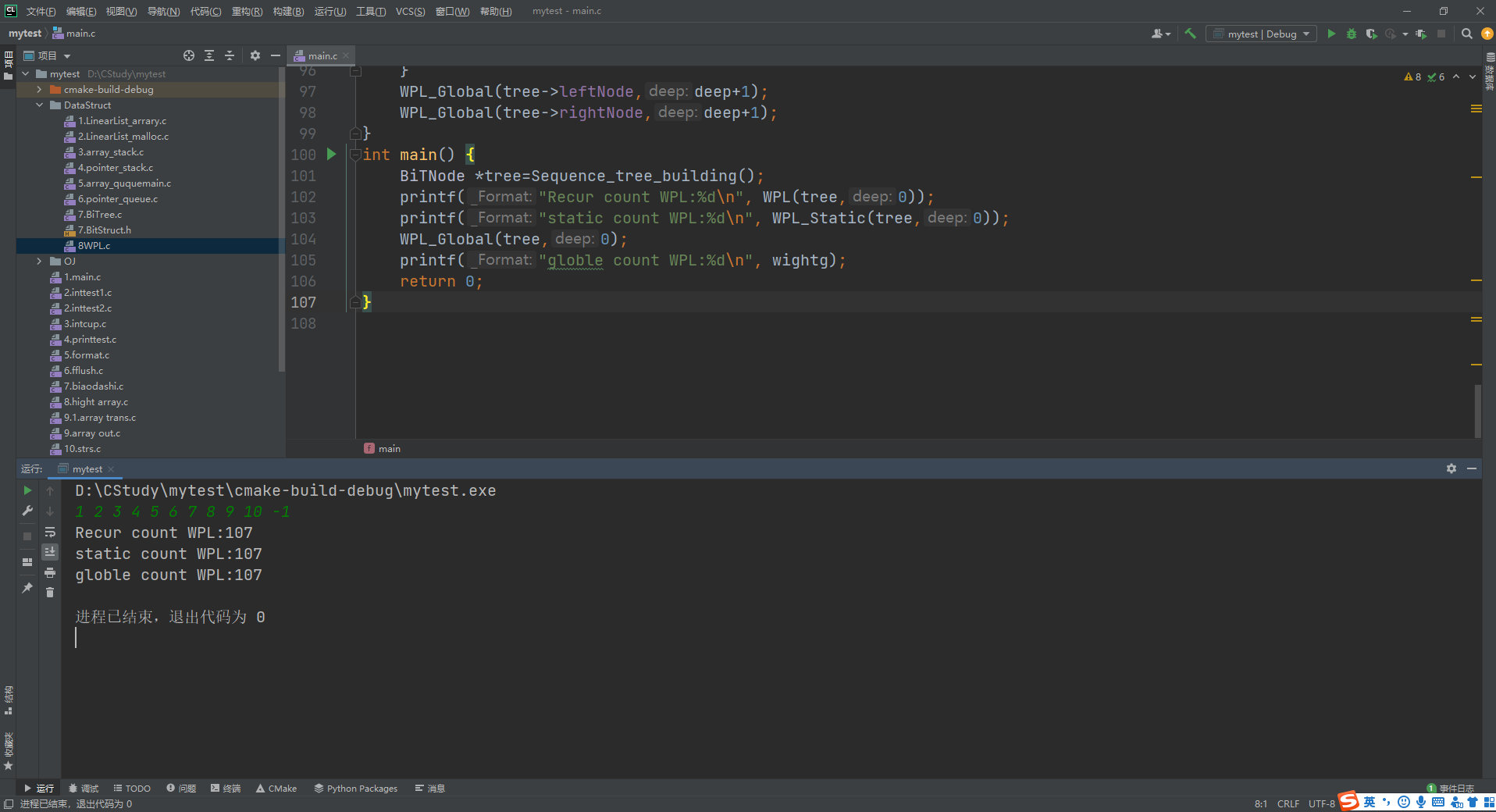
//
// Created by Zhu Shichong on 2023/1/9.
//
#include <stdio.h>
#include <stdlib.h>
#include "BitStruct.h"
#define bool int
#define true 1
#define false 0
//封装函数初始化一个根节点
BiTNode* newNode(ElementData e){
BiTNode *pnew=(BiTNode*) malloc(sizeof (BiTNode));
pnew->leftNode=NULL;
pnew->rightNode=NULL;
pnew->data=e;
return pnew;
}
tagQueue* newTagNode(BiTNode* pnew){
tagQueue *p=(tagQueue *) malloc(sizeof (tagQueue));
p->next=NULL;
p->p=pnew;
return p;
}
// -------------------层序建树------------------------------//
BiTNode *Sequence_tree_building(){
BiTNode *tree=NULL,*pnew=NULL;
tagQueue *tail=NULL,*tagQ=NULL,*p;
ElementData e;
while(scanf("%d",&e)){
if(e==ElementDataEnd){
break;
}
//将信息写入新生成的节点
pnew=newNode(e);
p=newTagNode(pnew);
// 写成NULL==tail是为了防止tail=NULL的情况发生;
//改变指针之间的关系,将节点插入相应位置
if(NULL==tree){
//此分支创建二叉树,创建辅助队列
tree=pnew;
tail=p;
tagQ=tail;
continue;
}else{
//将新节点添加到队尾
tail->next=p;
tail=tail->next;
}
// 精妙之处,通过辅助队列构建二叉树
if(tagQ->p->leftNode==NULL){
tagQ->p->leftNode=pnew;
}else if(tagQ->p->rightNode==NULL){
// 此分支多一句是因为,这种建树方式是层序建树(这颗子树左右都有的话会向兄弟树根偏移,而辅助队列下一个就是本层的兄弟树根)
tagQ->p->rightNode=pnew;
tagQ=tagQ->next;
}
}
return tree;
}
//计算二叉树WPL(Wight Path Length)递归方式实现
int WPL(BiTNode* tree,int deep){
if(NULL==tree){
return 0;
} else if(NULL==tree->leftNode&&NULL==tree->rightNode){
return deep*tree->data;
}
int p= WPL(tree->leftNode,deep+1);
int q= WPL(tree->rightNode,deep+1);
return p+q;
}
//计算二叉树WPL(Wight Path Length)静态变量方式实现
//这种方式纯属遍历一遍二叉树!
int WPL_Static(BiTNode* tree,int deep){
static wight=0;
if(NULL==tree){
return 0;
}
if(NULL==tree->leftNode&&NULL==tree->rightNode){
wight+=deep*tree->data;
}
WPL_Static(tree->leftNode,deep+1);
WPL_Static(tree->rightNode,deep+1);
return wight;
}
//计算二叉树WPL(Wight Path Length)全局变量方式实现
//这种方式纯属遍历一遍二叉树!
int wightg=0;
void WPL_Global(BiTNode* tree,int deep){
if(NULL==tree){
return ;
}
if(NULL==tree->leftNode&&NULL==tree->rightNode){
wightg+=deep*tree->data;
}
WPL_Global(tree->leftNode,deep+1);
WPL_Global(tree->rightNode,deep+1);
}
int main() {
BiTNode *tree=Sequence_tree_building();
printf("Recur count WPL:%d\n", WPL(tree,0));
printf("static count WPL:%d\n", WPL_Static(tree,0));
WPL_Global(tree,0);
printf("globle count WPL:%d\n", wightg);
return 0;
}