文章目录
- 1、什么是消息队列
- 2、使用场景
- 3、消息队列与传统设计的区别
- 1、传统设计
- 2、并行处理调优
- 3、消息队列
- 4、三大优点
- 1、异步
- 2、削峰
- 3、解耦
- 5、缺点
- 1、增加了系统复杂性。
- 2、事务问题。
- 3、可用性
- 6、MQ常见问题
- 1、消息堆积问题怎么解决
- 2、重复消费问题怎么解决
- 3、如果避免消息丢失
- 4、如何做到顺序消费
- 5、消费者怎么知道mq里有消息了
- 7、几种常见的消息队列
1、什么是消息队列
消息队列:一般我们会简称它为MQ(Message Queue)。
Message Query(MQ),消息队列中间件,很多初学者认为,MQ通过消息的发送和接受来实现程序的异步和解耦,mq主要用于异步操作,这个不是mq的真正目的,只不过是mq的应用,mq真正的目的是为了通讯。
他屏蔽了复杂的通讯协议,像常用的dubbo,http协议都是同步的。
这两种协议很难实现双端通讯,A调用B,B也可以主动调用A,而且不支持长连接。mq做的就是在这些协议上构建一个简单协议——生产者、消费者模型,mq带给我们的不是底层的通讯协议,而是更高层次的通讯模型。他定义了两个对象:发送数据的叫做生产者,接受消息的叫做消费者,我们可以无视底层的通讯协议,我们可以自己定义生产者消费者。
2、使用场景
最主要的作用是异步、削峰、解耦
3、消息队列与传统设计的区别
1、传统设计
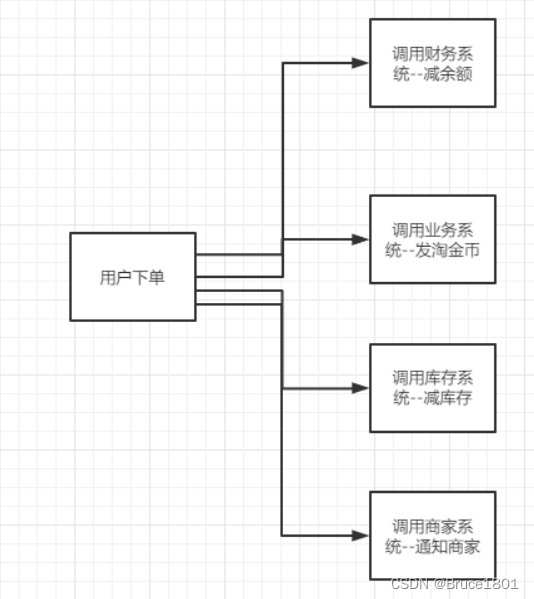
这是一个用户购物下单的流程图:
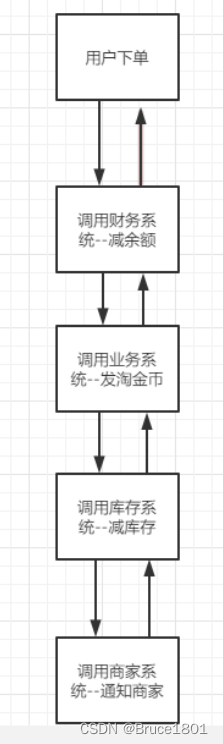
观察一下上面的设计,属于典型的串行化调用,这种设计模式有一个很大的优势,就是代码简单,出现问题很容易定位到问题。但是也有很多劣势,下面咱们从三高(高并发,高性能,高可用)三个方面去评审一下这个设计。
- 高并发:因为这些操作都是由一个线程(主线程)去执行这些操作,所以当我们的QPS如果很高的话,很容易造成超时。
- 高性能:因为上面这种设计模式是串行的,假设我的每次网络传输耗时200ms,业务处理需要20ms,完成上面那些操作需要耗时2s,这样用户体验也会很差(想象一下每次下单都需要等2s),如果用户下单后的操作越来越多,耗时只会越来越高。
所以在一个大型的互联网项目中,以上设计是完全不可取的(非核心模块除外)。 - 高可用:这些服务假如有一个服务挂掉(宕机或者网络波动),就意味着我这个请求失败了,这样用户体验会极差,用户会频繁看到支付失败。
2、并行处理调优
既然上面说的是串行模块,那么我们用自己的线程池把他改为并行的设计,再看评审一下。
所谓的并行设计就是原来由一个线程去串行做的逻辑,改为多个线程并行去做。
- 高可用:这些服务假如有一个服务挂掉(宕机或者网络波动),理论上讲,如果补偿服务做的出色的话,还是满足高可用的。(可以用try,catch)
- 高并发:相比上面的设计,系统的吞吐量可以达到了很大程度上的提升。
- 高性能:相比上面的设计,因为很多业务是并行执行的,所以相当于只有200*2+20,就可以返回。
上面这个设计看起来还是不错的设计,所以在很多这种串行调用,多次io的时候,我们就可以采用这种方案,上面这种设计也是多线程的一种实战应用。
下面来分析一下弊端:
1.系统的可扩展性太差了。上面只是列举了4步,但是实际上会有几十步,这几十步放到代码里就会像屎堆一样,可维护性极差。每次加一个步骤,都要多调一个接口,然后重新发布一下服务。
2,系统的耦合性太高了。想象一下,几十个http调用放到一起并发执行,很有可能会影响其他的点,尤其是淘宝京东这种秒杀敏感的业务,和钱挂钩的业务,很容易出现p0级别的bug。
3,使用的业务本身的线程池,在并发很多的情况下,容易造成cpu的竞争。
3、消息队列
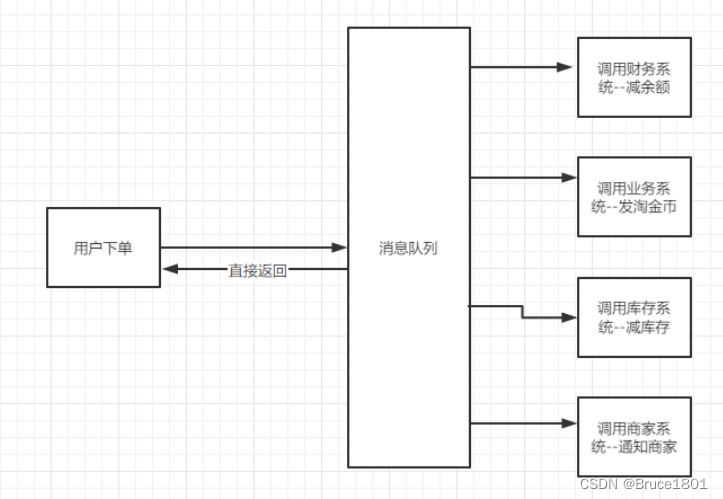
咱们继续从三高的层面去审视一下这个设计:
- 高可用:当我系统里的一个模块宕机了,不会影响到我其他服务。(可以通过数据补偿或者分布式事务来保证数据最终一致性)
- 高性能:用户下单,将下单所需要的数据都放到消息队列里,就直接返回了,所有耗时相当于就是网络传输所耗时。
- 高并发:由于消息队列不处理任何业务上的逻辑,所以它支持的并发是百万级别的。假如有100万个用户下单,100万的数据放到消息队列里,连接消息队列的服务慢慢消费即可,也不至于造成瞬间有百万请求进来,将我的服务压垮。
4、三大优点
1、异步
连接消息队列的服务可以异步去执行。而且每次多增加一个步骤,我下单的代码是不需要动的,只需要再增加一个消费者即可。
2、削峰
比如说我平时服务就只能支撑几万的qps,像淘宝京东那种秒杀,那时候服务突然打进来(如果采用第二种方案)那服务就会直接被压死了。但是如果采用消息队列,这秒杀进来的所有的请求都不会直接打到具体服务上,都会先打到消息队列里,然后我后面的服务再慢慢消费。
可以看看淘宝京东双11秒杀的时候,是不是有的时候慢是慢了点,但是服务起码没挂。等我秒杀结束之后,服务还能正常运转。
消息队列就像是一个三峡大坝,用来拦截上游给的压力。
3、解耦
就像高可用里面说的一样,发淘金币服务挂了,和下单有什么关系,发淘金币服务挂了,我还是可以正常下单,只不过后期可以数据补偿或者分布式事务去解决这个问题
5、缺点
1、增加了系统复杂性。
所以说如果说你的业务量不大,并发也不高,就没必要使用消息队列。
2、事务问题。
事务问题其实是分布式系统肯定会存在的一个问题,只不过消息队列更严重一些。一般解决方案有两种,第一种就是采用分布式事务,这个下单的里涉及的所有服务放到一个事务里面,要么都成功,要么都失败。第二种就是,消费者做好合理的数据补偿措施,比如说,消息重试,人工刷数据等等。
3、可用性
刚才讲了解耦,其实是系统的各个模块之间的解耦,但是这些模块都和消息队列关联,万一消息队列挂了,就真的下不了单了。为了保证可用性,我们可以采用消息队列集群,前端流量限流等,后面会介绍。
6、MQ常见问题
1、消息堆积问题怎么解决
什么是消息堆积:生产者的生产速率远远大于消费者的消费速率,使消息大批量的堆积在消息队列。
解决方案:
- 提升消费者的消费速率(增加消费者集群)
- 消费者分批多线程去处理
- 限流,保证进入到消息队列的都是有用的消息
2、重复消费问题怎么解决
产生原因:
- 生产者产生了两条一模一样的消息
- 消费者一条消息消费了多遍
- 消息重试:消息重试一般发生于一个消费者发生了异常(网络波动或者系统假死),这个时候这个消费者就会通知生产者重新发送。就会带来重复消费的问题。
解决方法:
- 幂等性校验
可以采用常用的幂等解决方案(分布式锁),全局id+业务场景保证唯一性。处理消息的时候,先看一下缓存中有没有,如果有的话,就认为你已经被消费了,默认处理完成,直接return就好了。所有的重复提交问题,都可以用幂等性来解决。为了保险起见,也可以在数据库上做好唯一索引。
3、如果避免消息丢失
- 消息确认机制,生产者必须确认消息成功刷盘到硬盘中,才确认消息发送成功。
- 消息持久化机制,作为mq中间件,会把消息持久化到硬盘,因为内存里的数据断电就丢失了
- 消费者必须确认消息消费成功,否则进行重试,重试达到一定次数后,通知开发人员做好补偿措施
需要关闭自动提交,当消费者消费的完成后,再进行手动提交,通知mq我消费成功了,防止mq的自动提交。
自动提交就是当消费者接收到消息后,mq过了几秒自动认为消费者已经消费了。但这个时候消费者如果挂了,这条消息就没有被消费。
4、如何做到顺序消费
大多数的项目不需要保证顺序一致性,某些特殊场景必须保证顺序一致性,比如说,mq用于保证redis和mysql的数据一致性。
绑定同一个消费队列,消费的时候要注意如果使用了多线程处理,避免重新创建list,要在原来的list进行修改。
5、消费者怎么知道mq里有消息了
两种方案:
1,mq主动通知(push)
当mq中有消息,就会通知消费者来进行消费。这种模型有一个致命伤,就是慢消费。
2,消费者轮询(pull)
消费者去轮询看看有没有自己要消费的消息。这种模型也有弊端就是消息延迟与忙等。
如果消费者的速度比发送者的速度慢很多,势必造成消息在mq的堆积。假设这些消息都是有用的无法丢弃的,消息就要一直在mq端保存。当然这还不是最致命的,最致命的是mq给消费者推送一堆无法处理的消息,消费者不是拒绝就是报错,然后来回踢皮球。
反观pull模式,消费者可以按需消费,不用担心自己处理不了的消息来骚扰自己,而mq堆积消息也会相对简单,无需记录每一个要发送消息的状态,只需要维护所有消息的队列和偏移量就可以了。所以消息量有限且到来的速度不均匀的情况,pull模式比较合适。
由于主动权在消费方,消费方无法准确地决定何时去拉取最新的消息。如果一次pull取到消息了还可以继续去pull,如果没有pull取到则需要等待一段时间重新pull。
但等待多久就很难判定了。当然也不是说延迟就没有解决方案了,业界较成熟的做法是从短时间开始(不会对mq有太大负担),然后指数级增长等待。比如开始等5ms,然后10ms,然后20ms,然后40ms……直到有消息到来,然后再回到5ms。
即使这样,依然存在延迟问题:假设40ms到80ms之间的50ms消息到来,消息就延迟了30ms,而且对于半个小时来一次的消息,这些开销就是白白浪费的。
在阿里的RocketMq里,有一种优化的做法-长轮询,来平衡推拉模型各自的缺点。基本思路是:消费者如果尝试拉取失败,不是直接返回,而是把连接挂在那里等待,服务端如果有新的消息到来,把连接复用起来,这也是不错的思路。但海量的长连接mq对系统的开销还是不容小觑的,还是要合理的评估时间间隔。
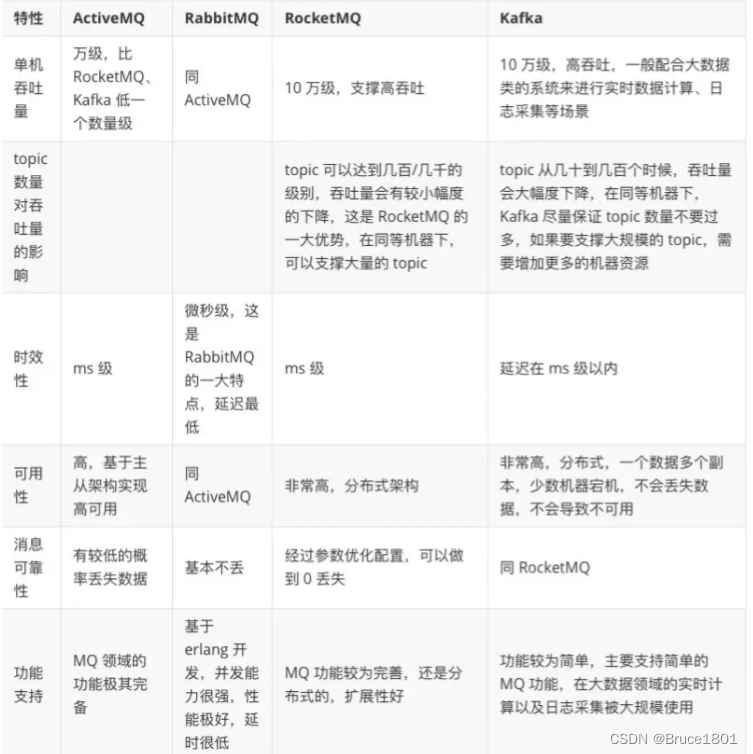
7、几种常见的消息队列