| 任务一:比较Spark和hadoop的区别 Spark和Hadoop都是用于分布式计算的框架,但两者有以下区别: 1、处理方式不同。Hadoop是基于MapReduce的,而Spark则是基于内存的分布式计算框架。 2、处理速度不同。因为Hadoop是磁盘读写密集型应用,数据处理速度较慢。而Spark则是内存计算型应用,数据处理速度更快。 3、应用场景不同。Hadoop适合于离线数据处理,比如批处理等操作。而Spark则适合于需要实时数据处理,如流处理和机器学习等应用。 4、API支持不同。Hadoop主要提供HDFS和MapReduce API。而Spark则提供了更丰富的API接口,包括Spark SQL、Spark Streaming、MLlib、GraphX等。 5、部署和维护不同。Hadoop的维护比较复杂,需要设置Hadoop集群,配置HDFS和MapReduce等。而Spark则比较简单,只需安装Spark和管理几个参数即可。 综上所述, Spark相较于Hadoop更快、支持更多的API,适合于数据实时处理和机器学习等场景。而Hadoop更适合于大规模数据离线处理。 Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以 Spark 应运而生,Spark 就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。 Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。 Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。 Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。 Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互。 Spark 的缓存机制比 HDFS 的缓存机制高效。 经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce 更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark并不能完全替代 MR。 任务二:完成Spark的三种部署方式,并简述其应用场景
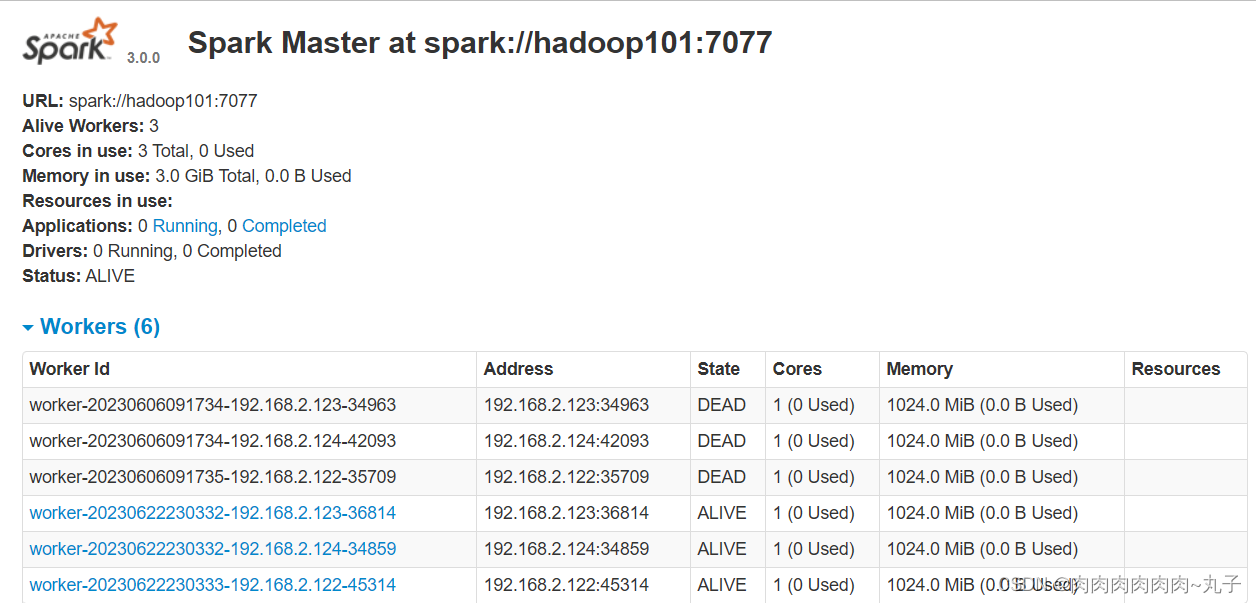
启动成功后,可以输入网址进行Web UI监控页面访问
在解压缩文件夹下的data目录中,添加word.txt文件。
按键Ctrl+C或输入Scala指令 :quit
集群规划 表 2
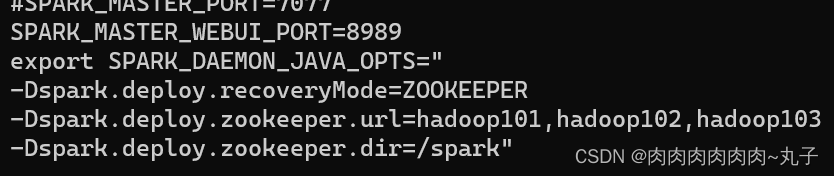
注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop配置
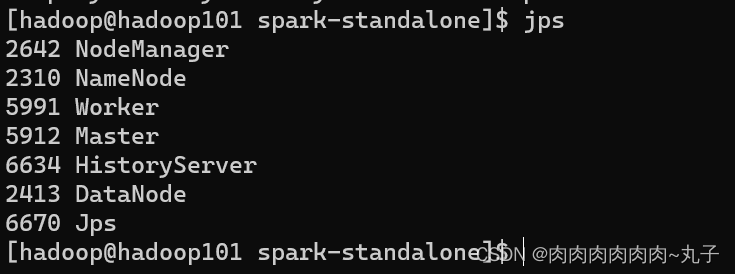
[hadoop@hadoop101 spark-standalone]$ sbin/start-all.sh
http:hadoop101:8080
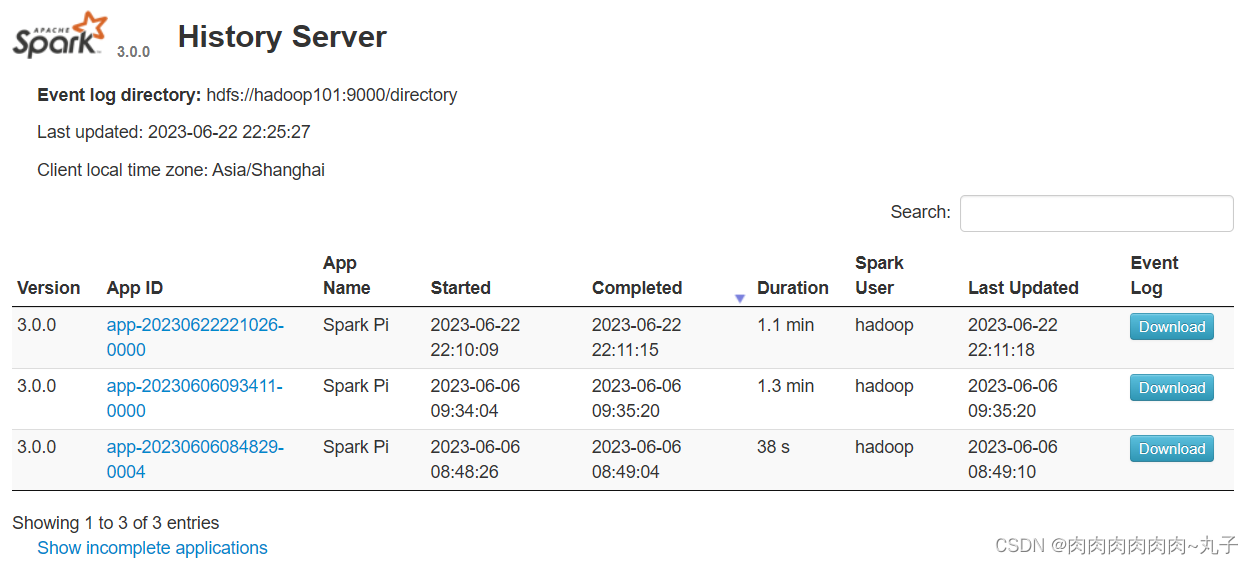
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
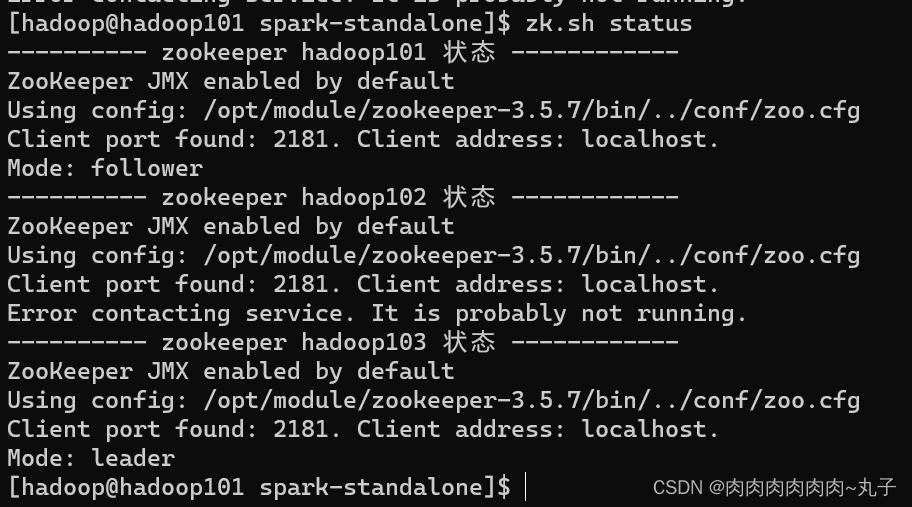
Zookeeper设置 集群规划 表 3
[hadoop@hadoop101 spark-standalone]$ sbin/stop-all.sh
ONF_DIR配置
注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在。
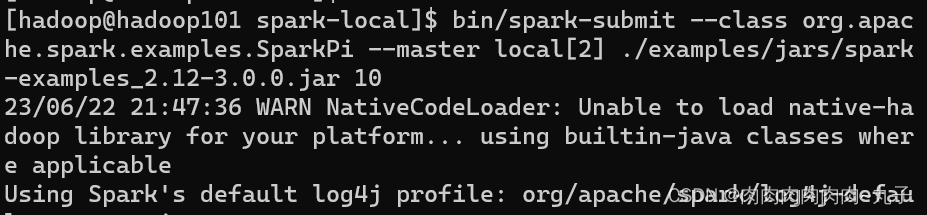
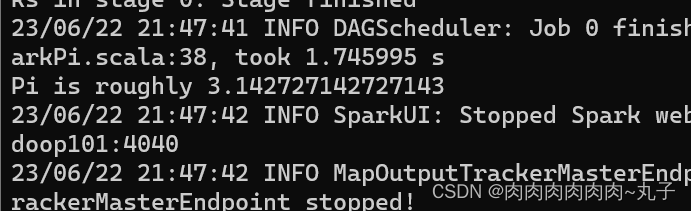
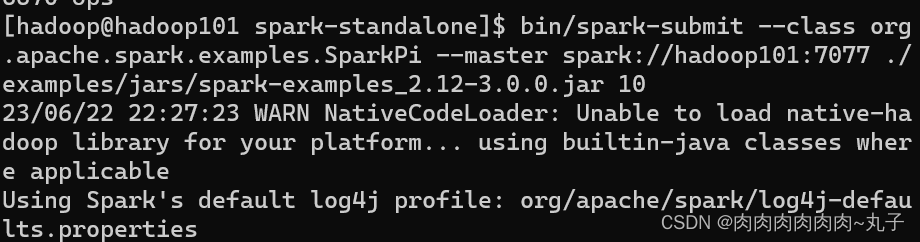
任务三:三种部署方式下,提交Spark自带计算π的测试程序并查看Spark程序运行结果。 3.1 Local模式 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10 1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序 2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量 3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包 4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
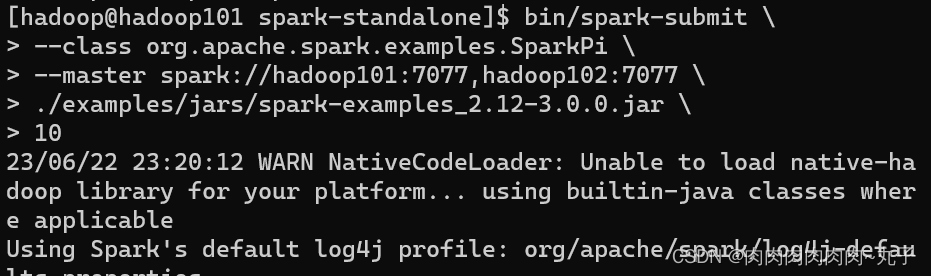
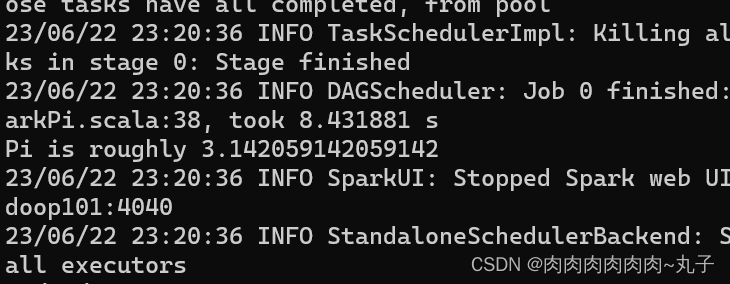
3.2 Standalone模式 (1)提交应用 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://linux1:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10 1) --class 表示要执行程序的主类 2) --master spark://hadoop101:7077 独立部署模式,连接到 Spark 集群 3) spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包 4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
执行任务时,会产生多个 Java 进程 执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。
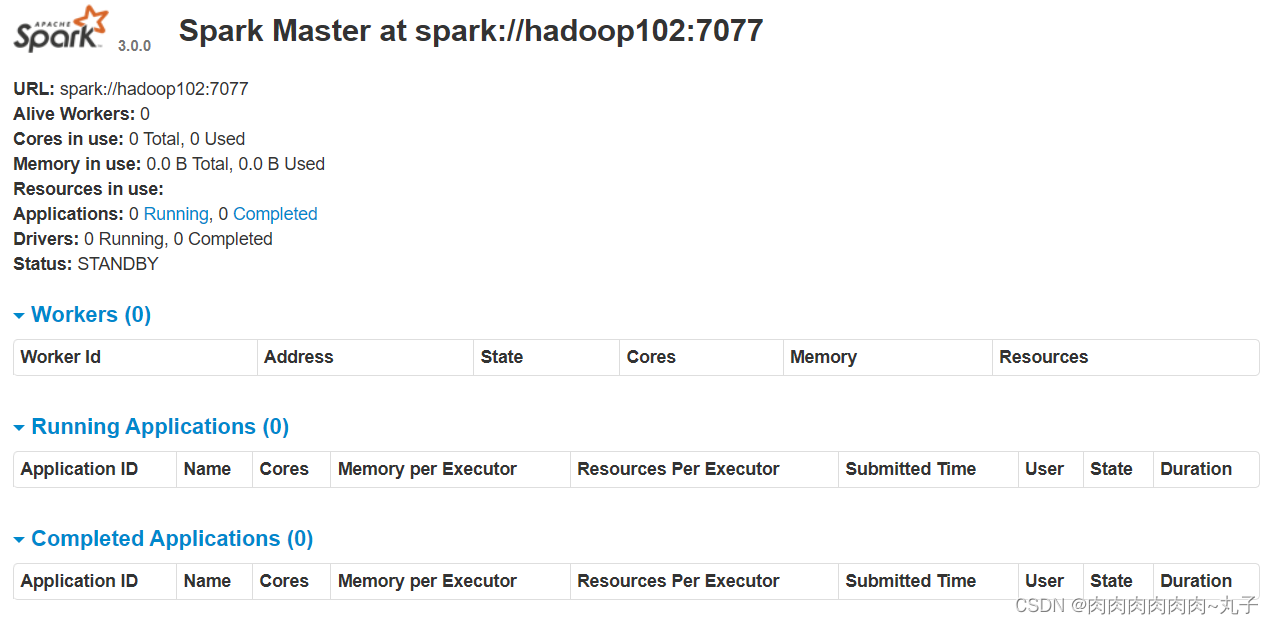
(4)停止hadoop101的Master资源监控进程
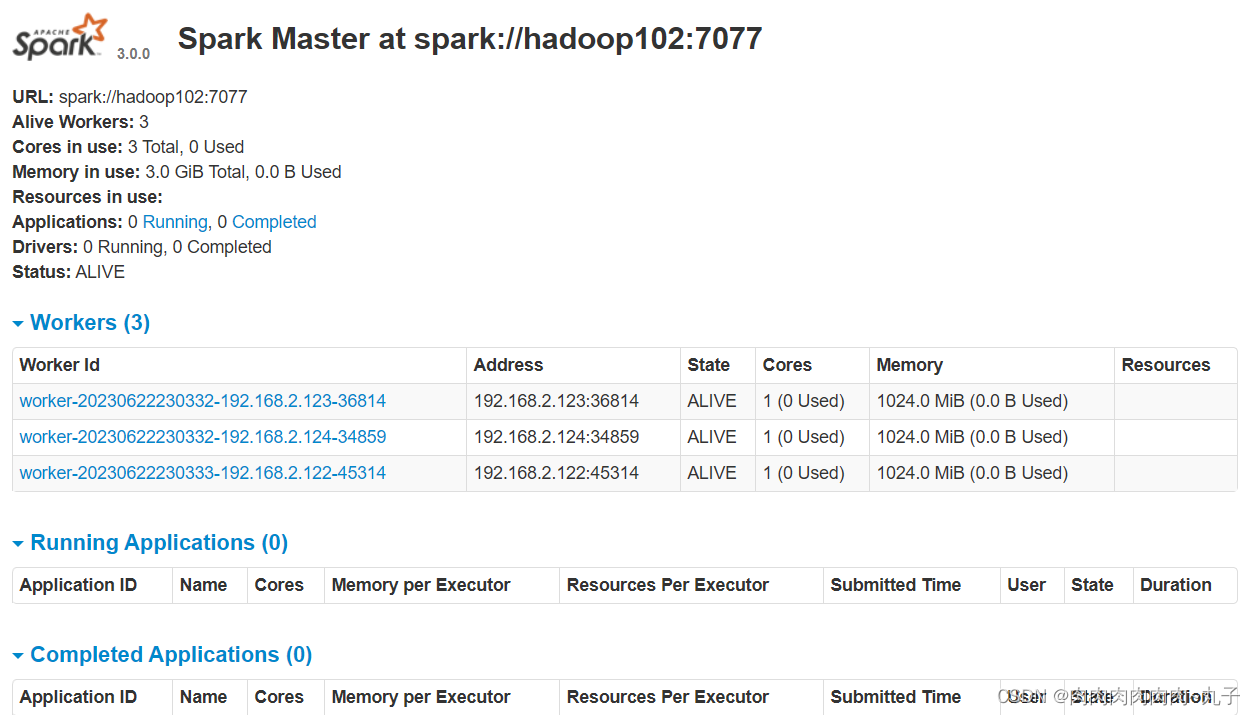
(5)查看hadoop102的Master资源监控Web UI,稍等一段时间后,hadoop102节点的Master状态提升为活动状态
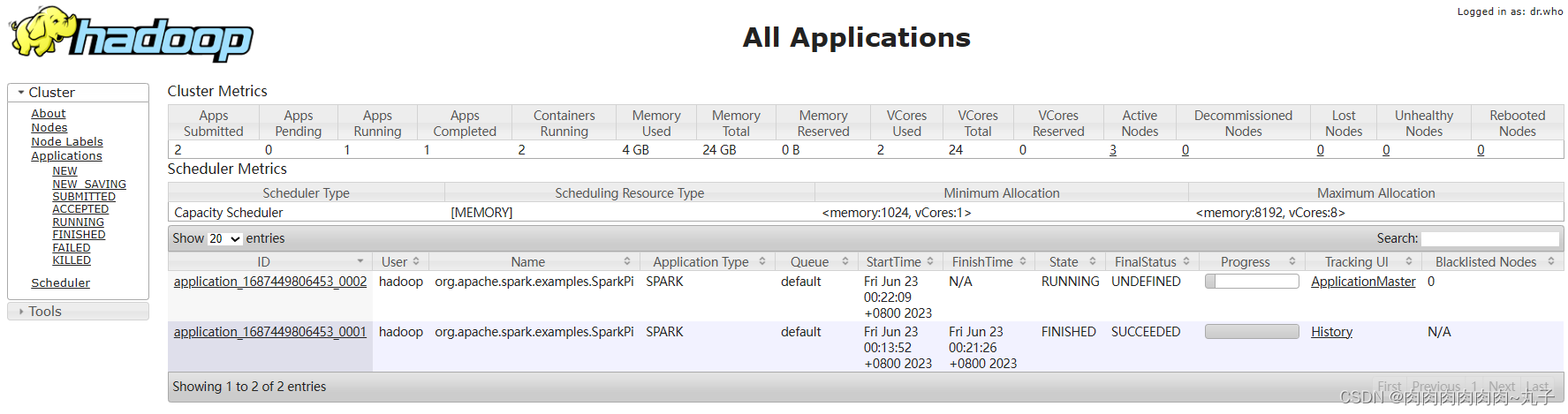
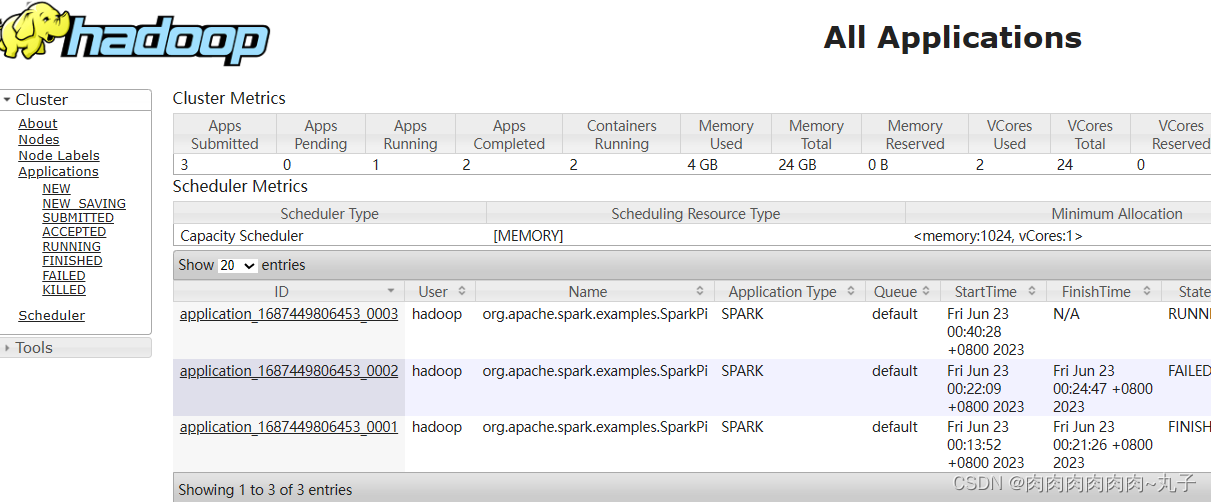
3.3 Yarn模式 1. 提交应用 查看http://hadoop102:8088页面,点击History,查看历史页面
Web页面查看日志:http://hadoop102:8088
| ||||||||||||||||
| 出现问题:Yarn模式提交时出错 问题原因:应用程序所需依赖项(Spark,Hadoop或其他库)不正确地配置,或文件系统出现故障或正在清理文件。 Diagnostics: File file:/home/hadoop/.sparkStaging/application_1687449806453_0002/__spark_libs__8216860835614806039.zip does not exist java.io.FileNotFoundException: File file:/home/hadoop/.sparkStaging/application_1687449806453_0002/__spark_libs__8216860835614806039.zip does not exist
解决方案:暂无 | ||||||||||||||||
| Yarn提交任务时出错 | ||||||||||||||||
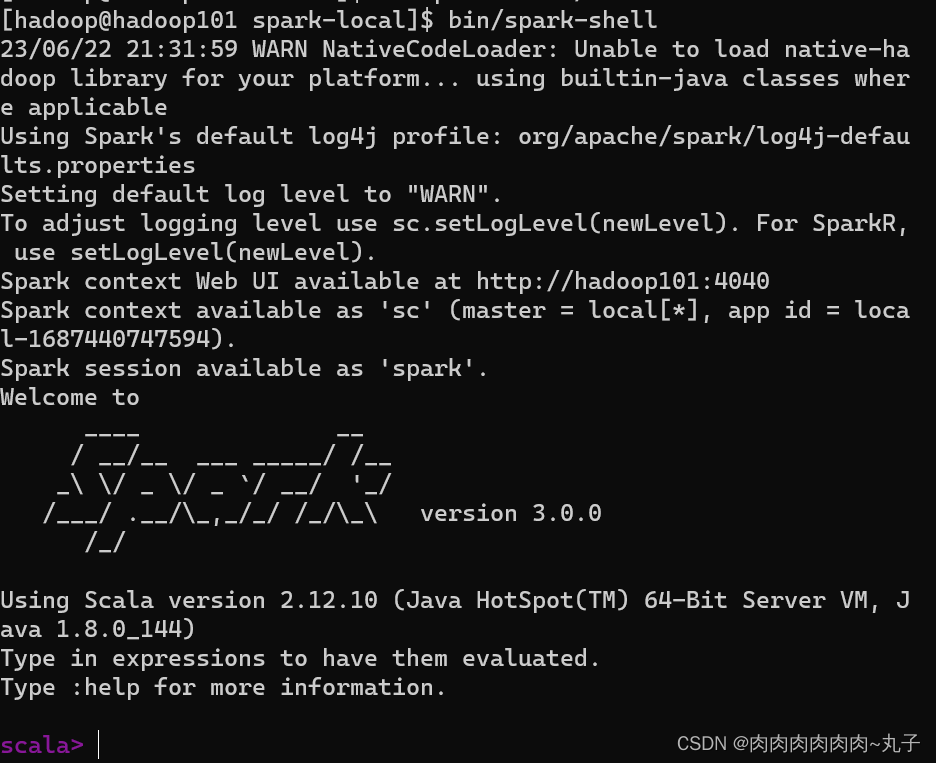
| Spark 实验的过程中,我积累了一些心得和体会: 安装Java、Scala和Spark:在CentOS 7中安装Spark SQL和Spark Core之前,需要先安装Java和Scala环境,并下载Spark的安装包,可以参考官方文档进行安装和配置,确保环境配置正确。 熟悉Spark架构:在进行Spark实验之前,先要了解Spark的架构和工作原理,包括RDD的概念、Spark Application架构、任务调度等,这样可以更好地理解实验内容。 启动Spark Shell。 编写Spark SQL和Spark Core代码:在编写Spark SQL和Spark Core程序代码时,需要注意代码的结构和语法,以及RDD与DataFrame之间的转换方法和函数调用。 实验结果分析:在进行Spark实验之后,需要对实验结果进行分析和总结,主要包括查询性能、资源占用、任务执行时间等指标,以便对实验过程进行改进。 总之,进行Spark SQL和Spark Core实验需要具备良好的编程能力和数据分析能力,同时需要对Spark的架构和工作原理有深刻的理解,才能够在实验中取得更好的表现。 |