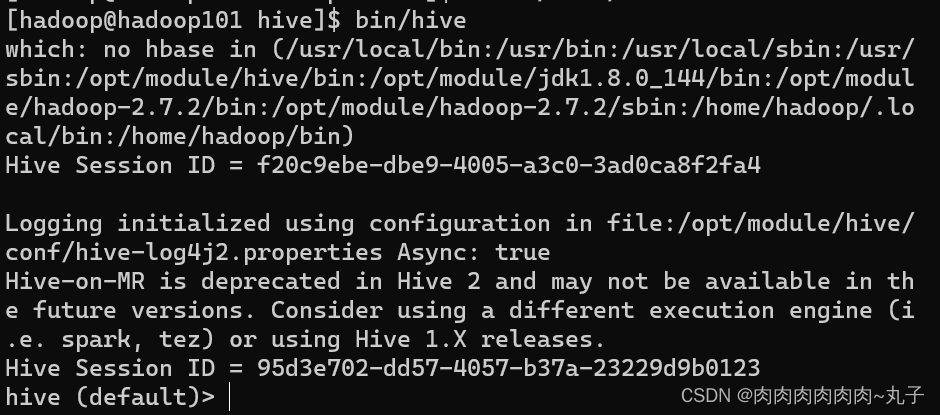
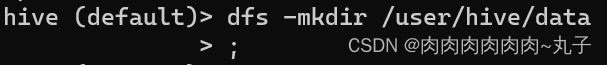| 任务一:完成Hive内嵌模式部署 1.1 Hive部署 官网下载Hive安装包 (1)官网地址:Apache Hive (2)文档查看地址: https://cwili.apache.org/confluence/display/Hive/GettingStarted (2)下载地址:Index of /dist/hive (3)github地址:GitHub - apache/hive: Apache Hive 1.2 安装Hive 1. 上传安装包到Linux系统下并解压到指定目录 [hadoop@hadoop101 software]$ tar -zxvf /opt/software/apache-hi ve-3.1.2- bin.tar.gz -C /opt/module/ 2. 修改/etc/profile.d/my_env.sh,添加环境变量 3. 解决日志Jar包冲突 [atguigu@hadoop101 hive]$ mv lib/log4j-slf4j-impl-2.10.0.jar lib /log4j-slf4j-impl-2.10.0.bak 4. 初始化元数据库 [hadoop@hadoop101 hive]$ bin/schematool -dbType derby -initS Schema 5. 启动Hive (1)启动hadoop集群 (2)启动Hive [hadoop@hadoop101 hive]$bin/hive
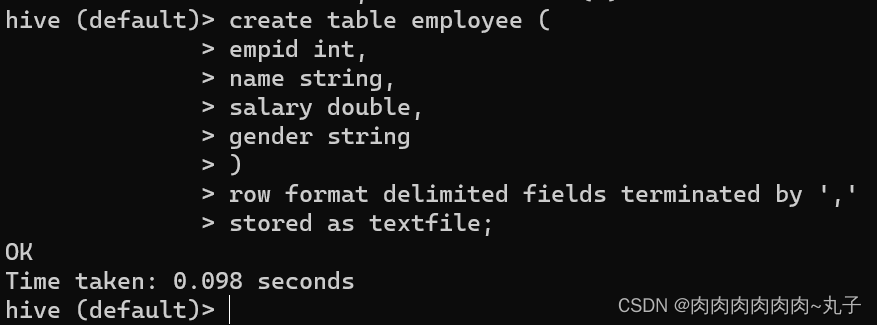
1.3 Hive属性配置 1. 修改/opt/module/hive/conf/hive-log4j2.properties.tem plate 文件名称为 hive-log4j2.properties 2. 在 hive-log4j2.properties 文件中修改 log 存放位置 hive.log.dir=/opt/module/hive/logs hive-site.xml中添加打印当前库和表头的配置 任务二:能够将Hive数据存储在HDFS上 1. 建立Hive表 首先,创建一个Hive表,用于存储数据,示例表结构为:
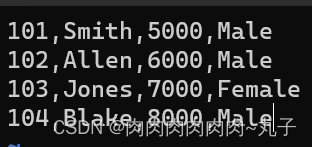
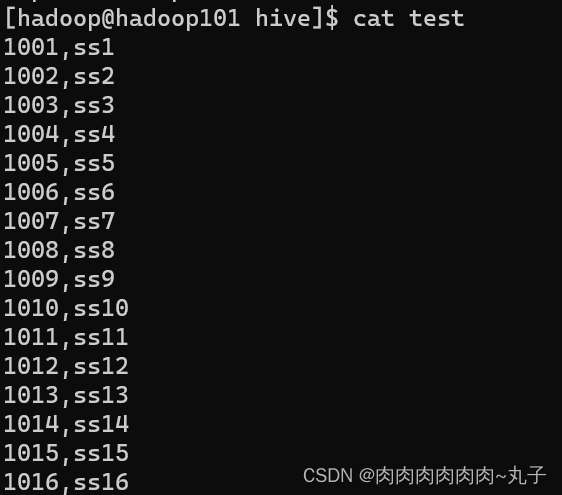
上述语句创建了一个名为employee的表,表中包含empid、name、salary和gender四个字段,字段类型分别为整型、字符串类型、浮点型和字符串类型。表中的数据将以逗号分隔的文本文件的形式进行存储,文件的存储格式为TEXTFILE。 2. 将数据存储到HDFS上 接下来将数据存储到HDFS上。在本地文件系统中创建文本文件employee.txt,该文件包含了一些雇员信息,例如:
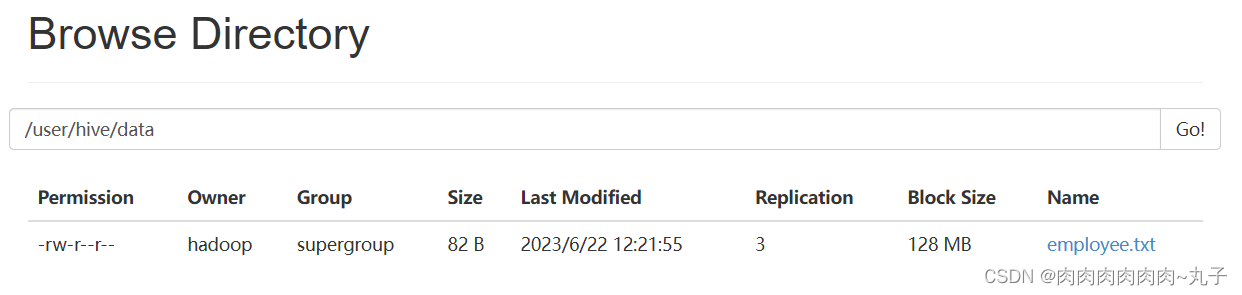
将该文本文件上传到HDFS上,例如:
将数据导入到Hive表中,例如:
该语句将HDFS上的employee.txt文件中的数据加载到Hive表employee中。
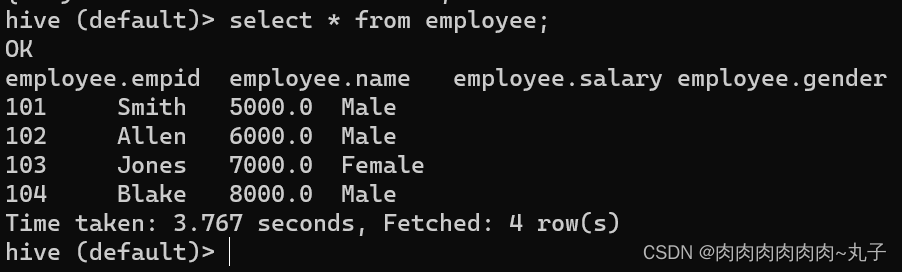
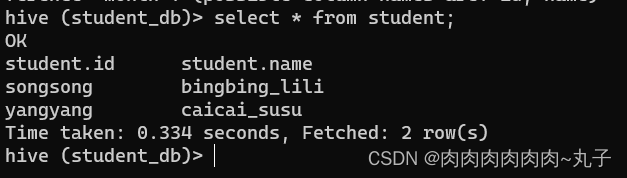
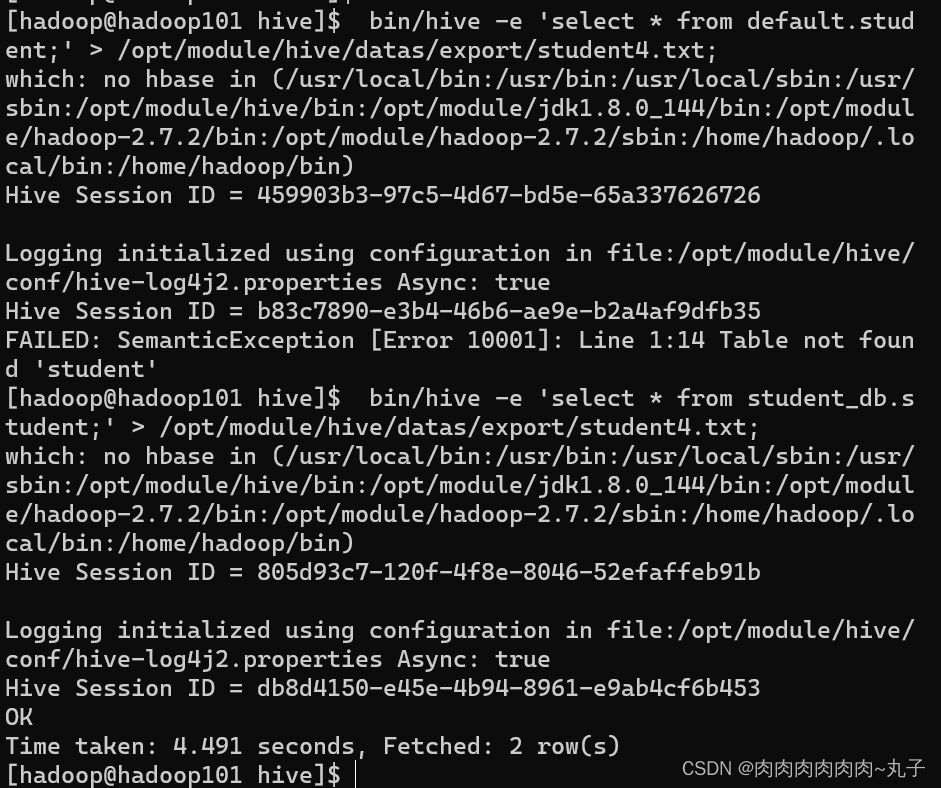
当数据存储在Hive表中后,我们可以通过Hive提供的SQL语句来查询和操作数据。同时,我们也可以通过HDFS命令来处理Hive表所存储的数据。 例如,我们可以使用以下命令查看HDFS上employee.txt文件的内容:
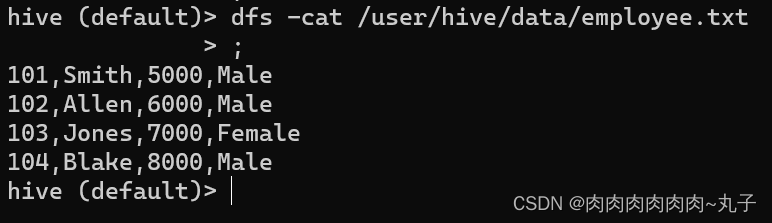
也可以使用以下命令将HDFS上的employee.txt文件导出到本地文件系统中:
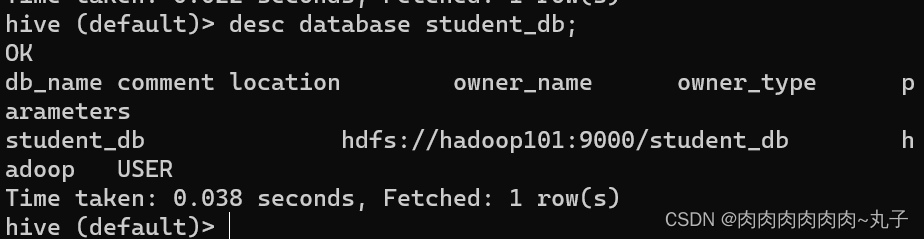
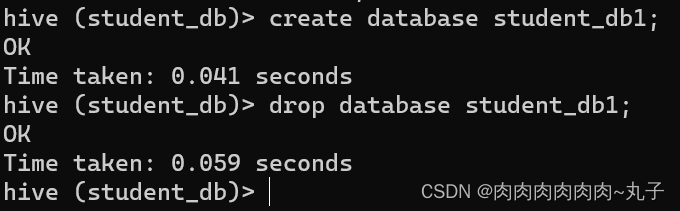
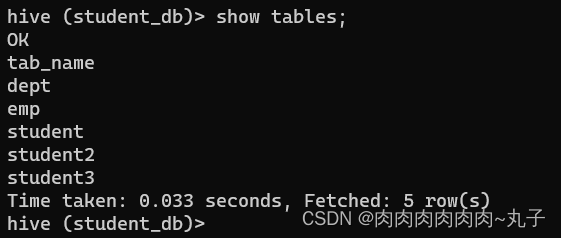
任务三:进入Hive Shell,自行设计Hive表,完成常见的DDL操作和DML操作 3.1 DDL操作 1. 创建数据库 CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)];
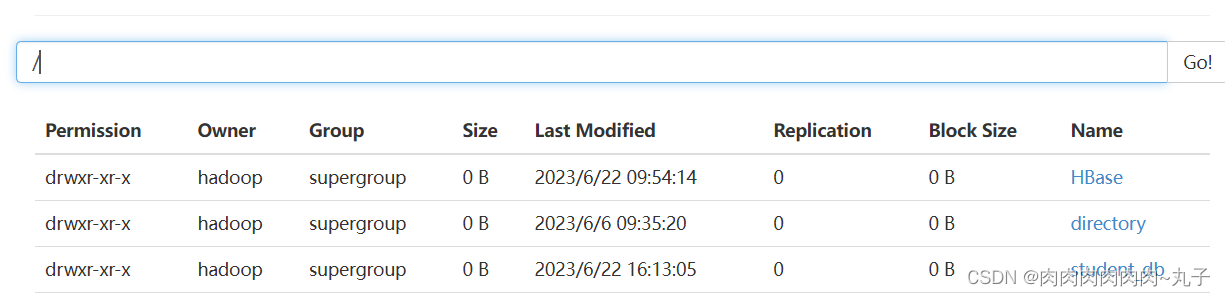
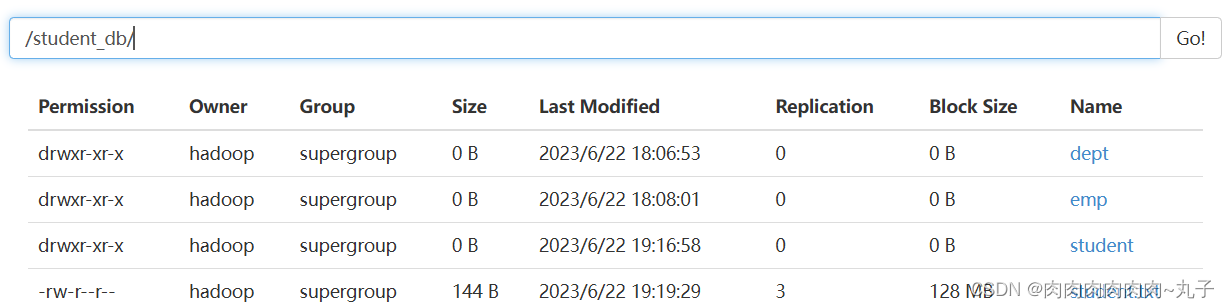
径是/user/hive/warehouse/student_db.db。
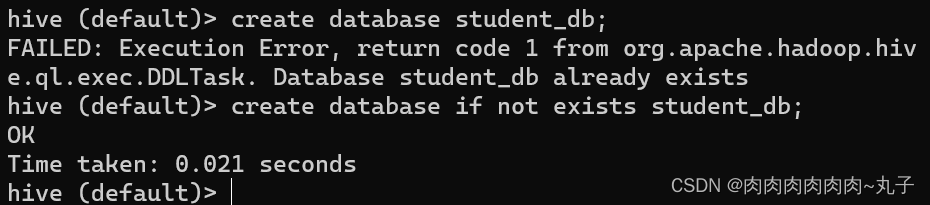
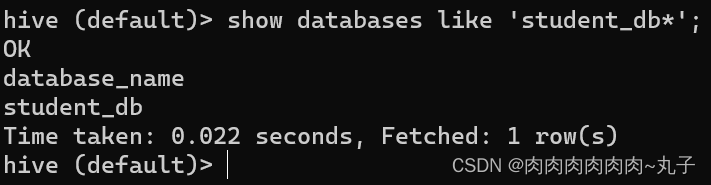
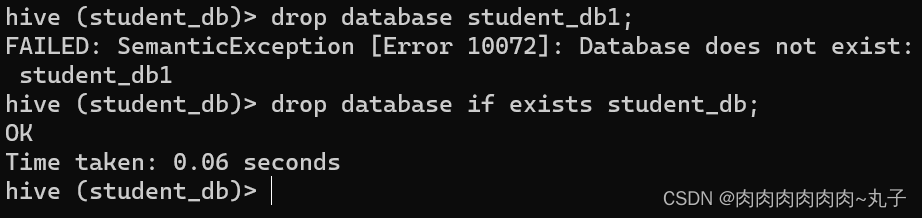
(2)避免要创建的数据库已经存在错误,增加if not exists判断。 hive (default)> create database if not exists student_db;
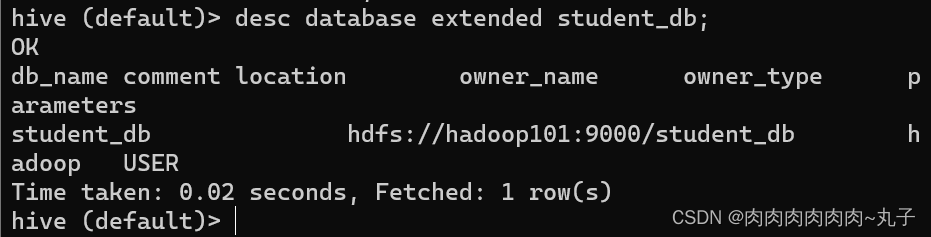
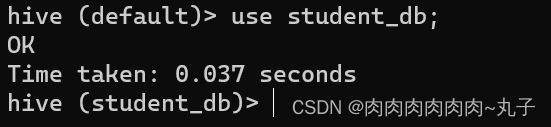
(3)创建一个数据库,指定数据库在HDFS上存放的位置 hive (default)> create database student_db location '/student_db';
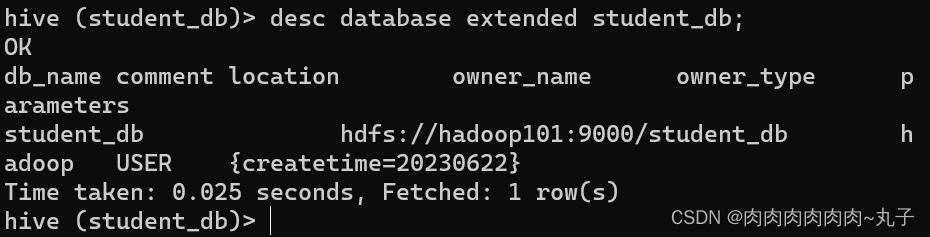
hive (default)> alter database student_db set dbpro perties('createtime'='20230622');
据库是否存在
除
(1)建表语法 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
中)
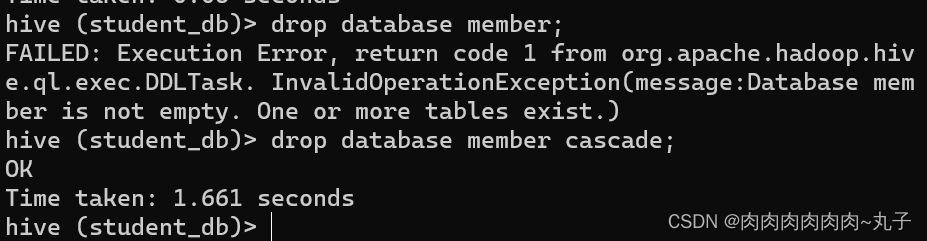
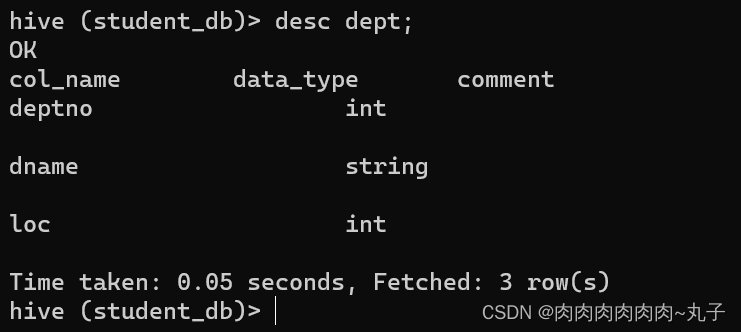
因为表是外部表,所以 Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
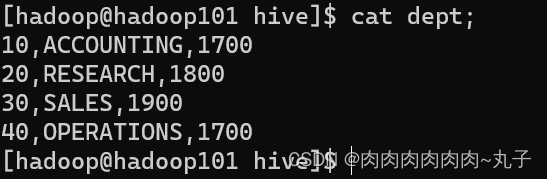
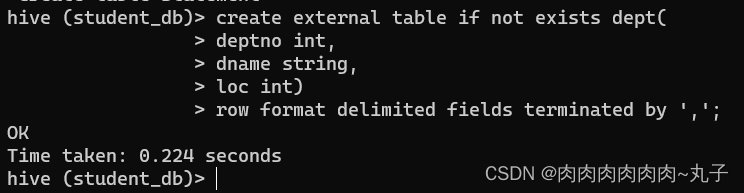
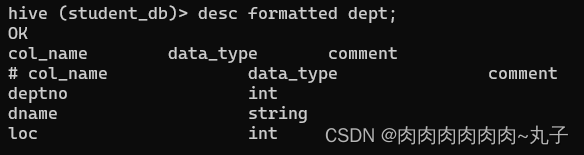
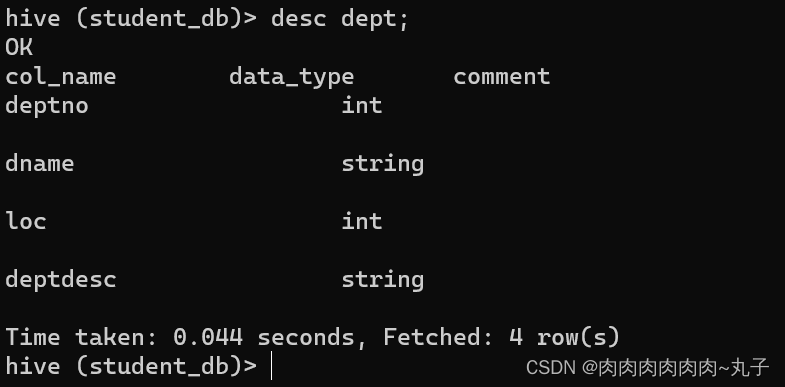
创建部门表
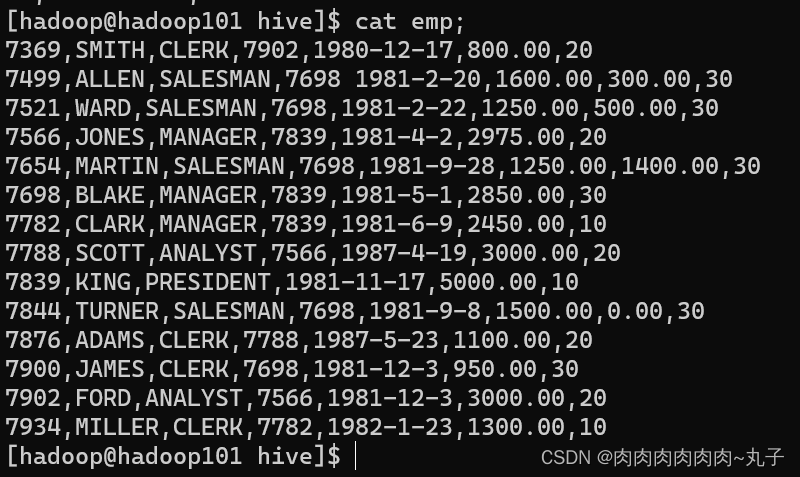
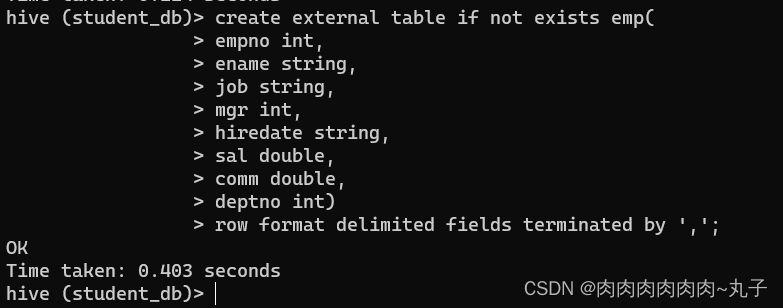
创建员工表
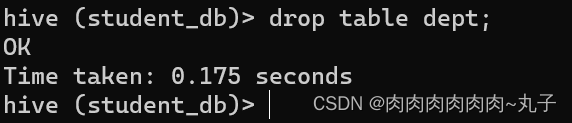
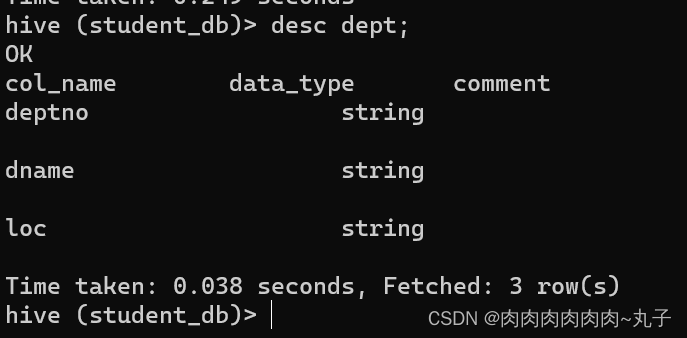
外部表删除后,hdfs 中的数据还在,但是 metadata 中 dept 的元数据已被删除
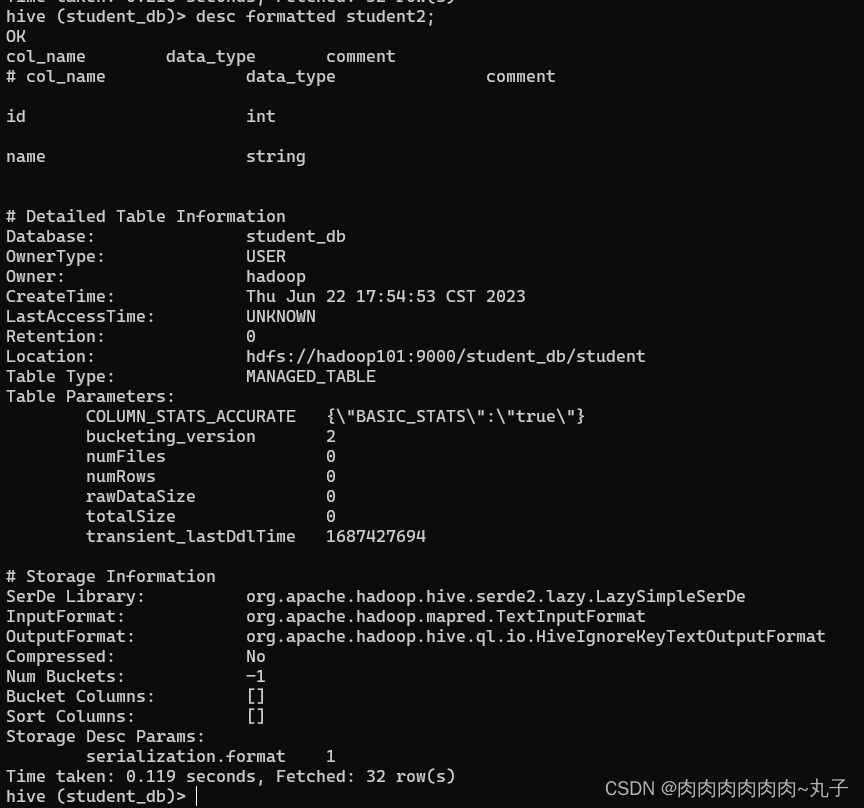
hive (default)> desc formatted student2;
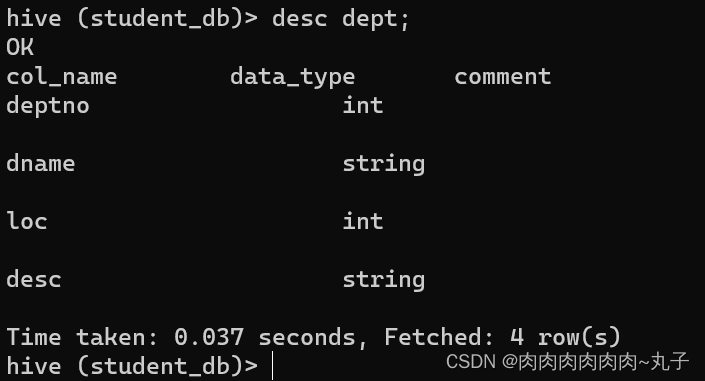
重命名表
ALTER TABLE table_name RENAME TO new_table_na me
3.2 DML操作 1. 数据导入 (1)向表中装载数据(Load) hive> load data [local] inpath '数据的 path' [overwrite] into table student [partition (partcol1=val1,…)];
上传文件到HDFS
加载HDFS上数据
上传文件到HDFS
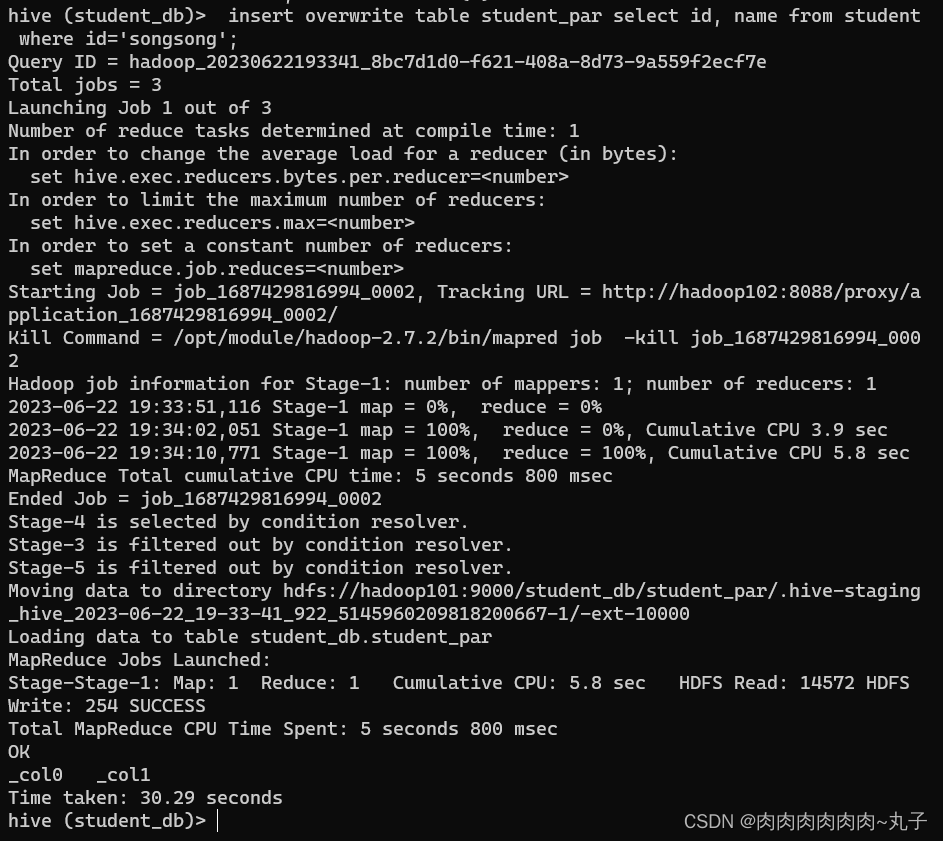
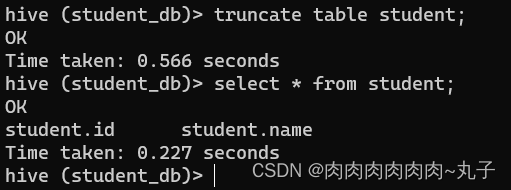
加载数据覆盖表中已有数据
(2)通过查询语句向表中插入数据(Insert) A. 创建一张表
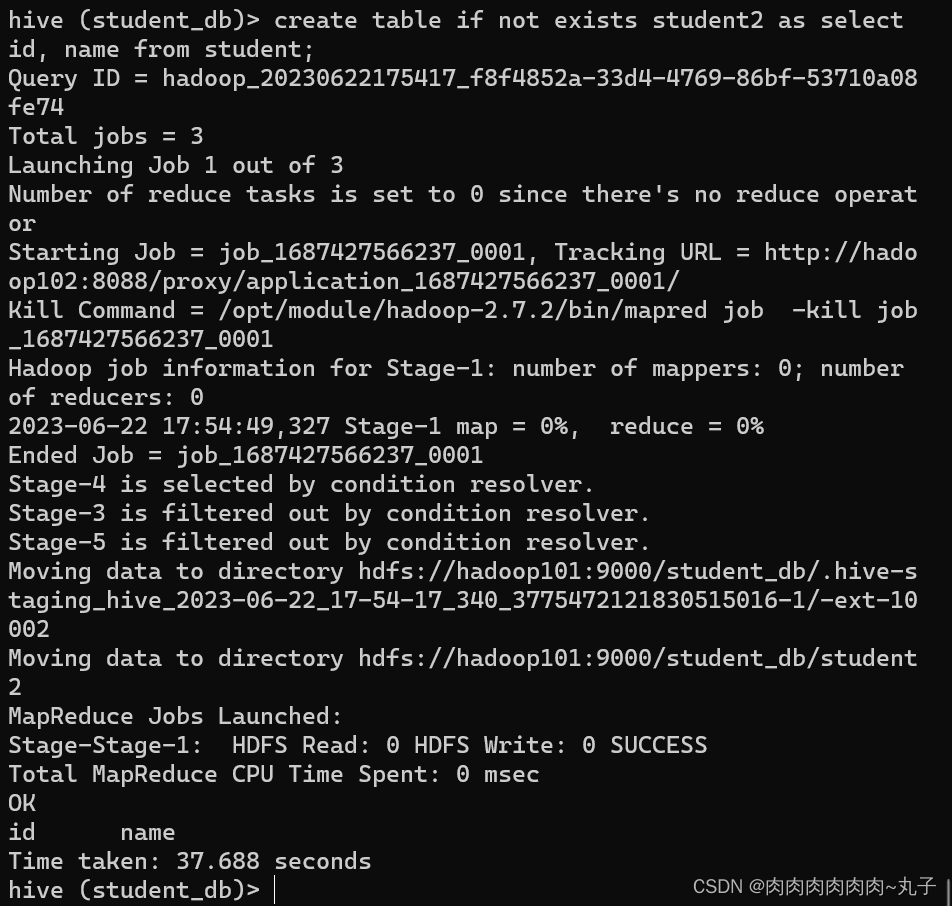
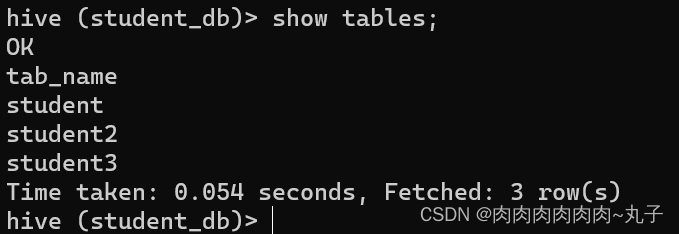
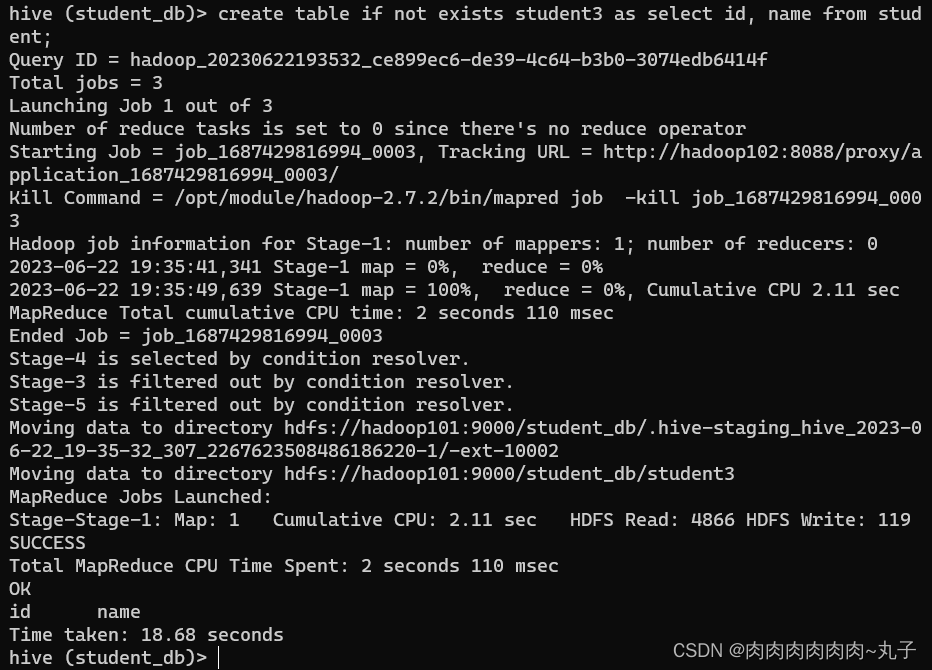
(3)查询语句中创建表并加载数据(As Select) 根据查询结果创建表(查询结果会添加到新创建的表中)
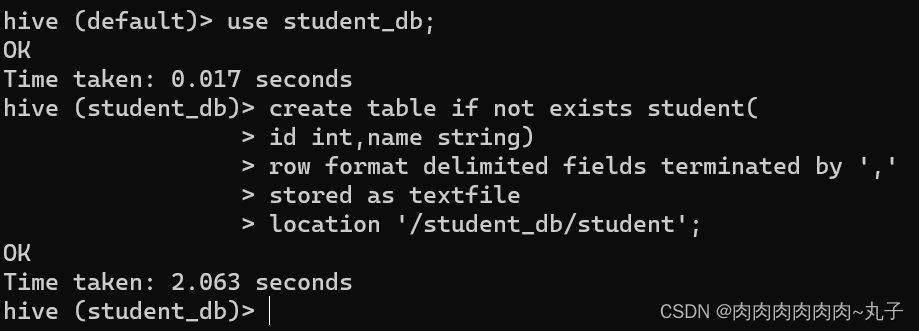
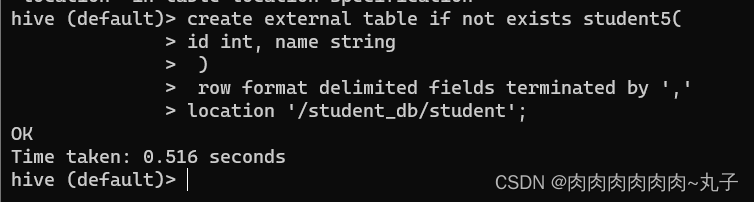
(4)创建表时通过Location指定加载数据路径 A. 创建表,并指定在HDFS上的位置
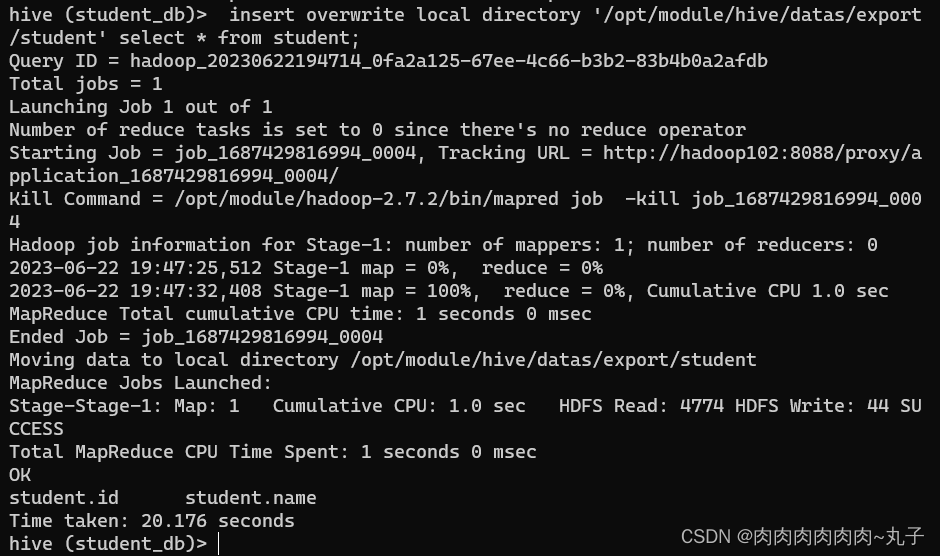
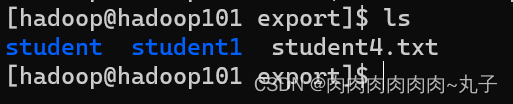
hive(default)>insert overwrite local directory '/opt/module/hi ve/datas/export/student1' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from student;
hive(default)>insert overwrite directory '/student_db/studen T2' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from student;
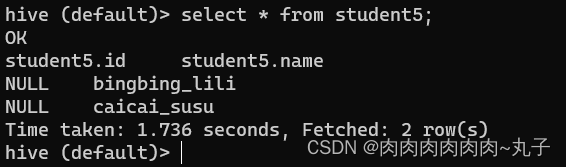
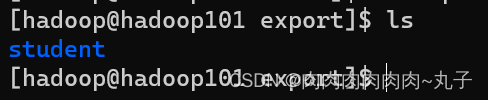
hive (default)> dfs -get /student_db/student/student.txt / /opt/module/datas/export/student3.txt;
|
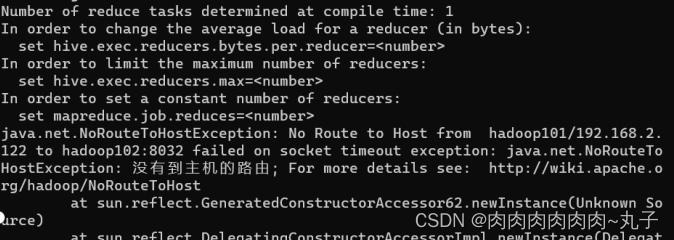
| 出现问题:hive进行插入操作时报错:NO Route To HostException:No Route to host
问题原因:由于Hive插入操作需要在YARN上提交MapReduce任务时无法访问YARN ResourceManager引起的。 解决方案:关闭防火墙,开启Hadoop集群 |
| 无 |
| 在进行Hive实验的过程中,得出如下结论: 熟悉Hive架构:在进行Hive实验之前,先要了解Hive的架构和工作原理,比如表的存储格式、元数据管理、查询优化等,这样可以更好地理解实验内容。 注意配置参数设置:在进行Hive实验时,需要根据实时的需求设置相关的配置参数,例如HDFS存储路径、JVM内存大小、任务队列等等,这些设置直接影响到实验的性能和稳定性。 数据源准备:在进行Hive实验前,需要对数据源进行准备和清理,以保证实验的有效性和正确性,常见的做法包括数据清洗、数据转换、数据格式设置等。 SQL语句调优:在进行Hive实验的时候,需要进行SQL语句的优化,以提高查询性能和效率。常见的调优手段包括剪枝优化、索引优化、加速器优化等。 实验结果分析:在进行Hive实验之后,需要对实验结果进行分析和总结,主要包括查询性能、资源占用、任务执行时间等指标,以便对实验过程进行改进。 总之,进行Hive实验需要具备扎实的Hadoop基础和SQL语言基础,并且需要有良好的数据分析能力和实验操作技巧。只有不断地积累经验和思考,才能够在Hive实验中取得更好的表现。 |