基础篇
第一课、一条 SQL 查询语句是如何执行的?
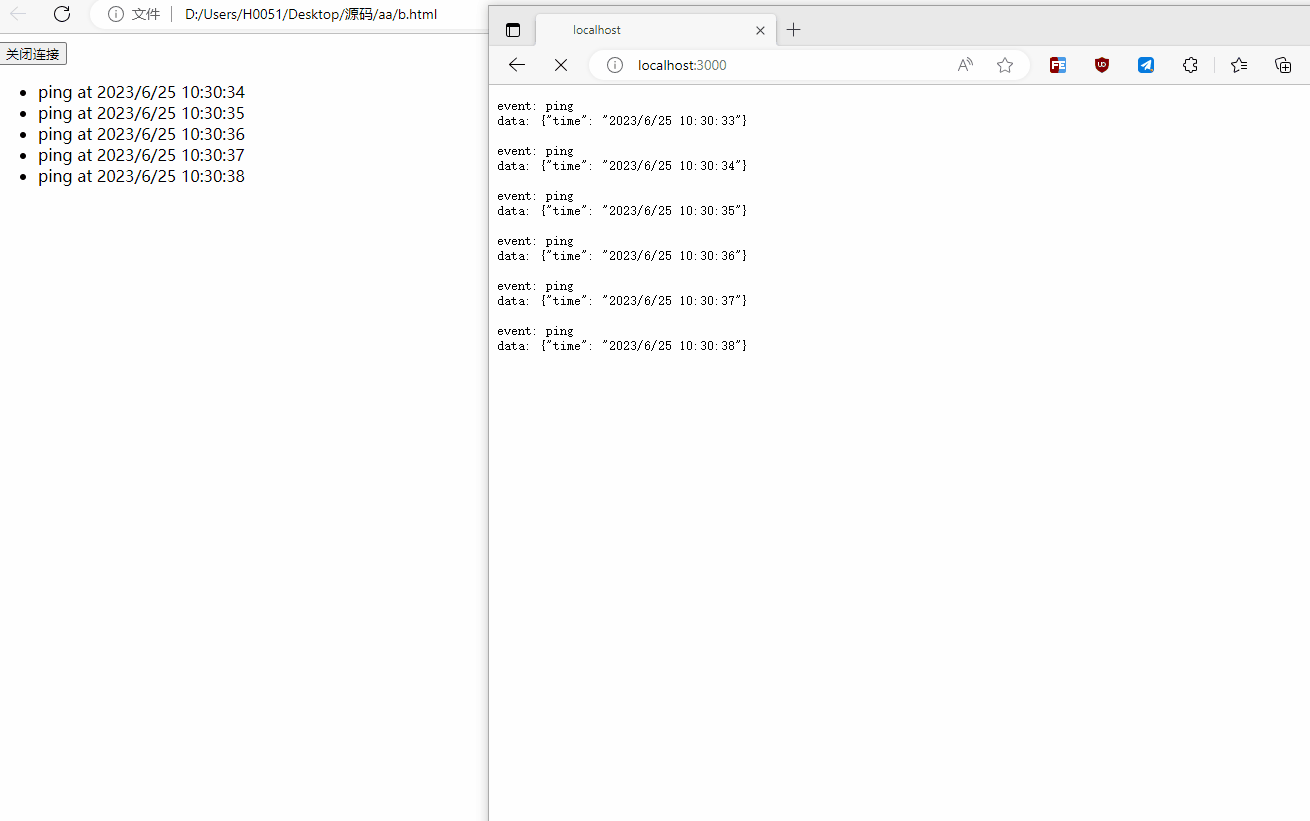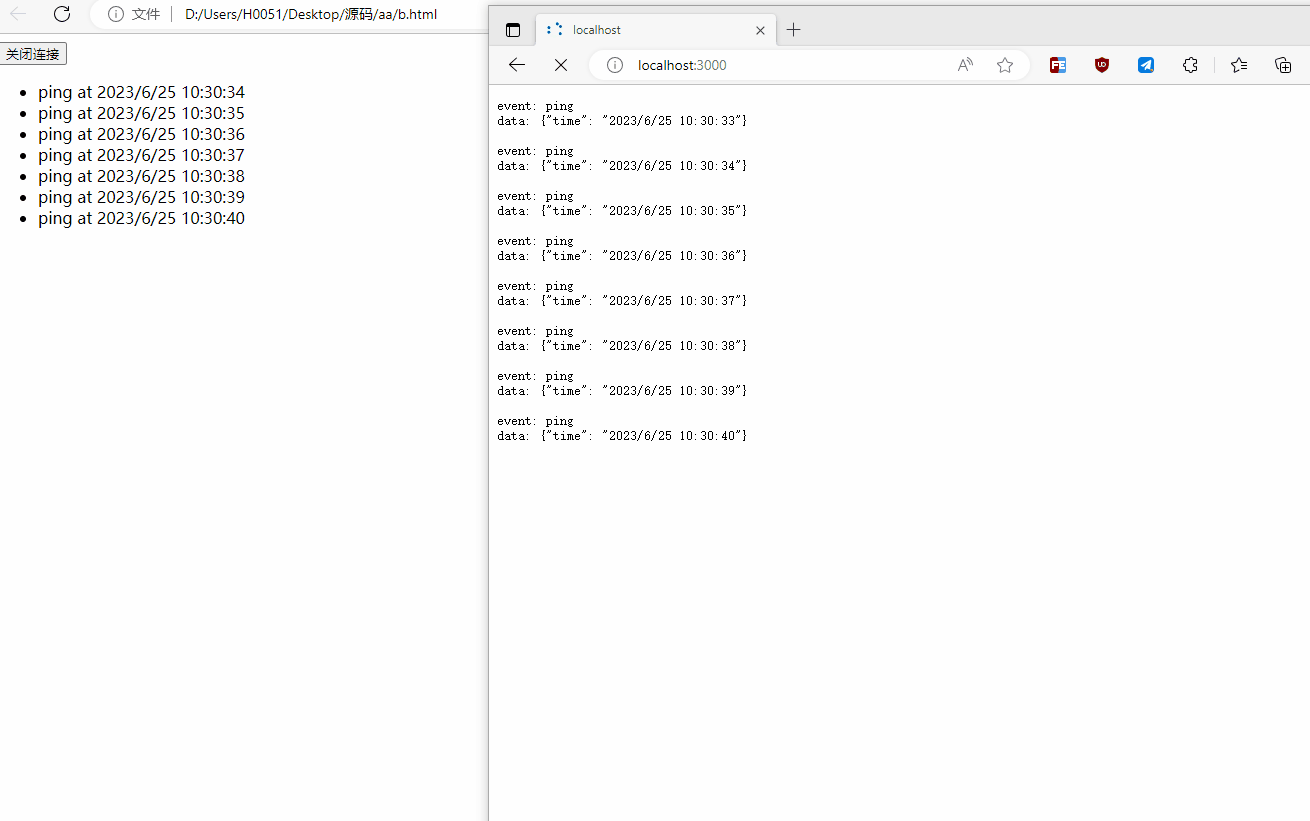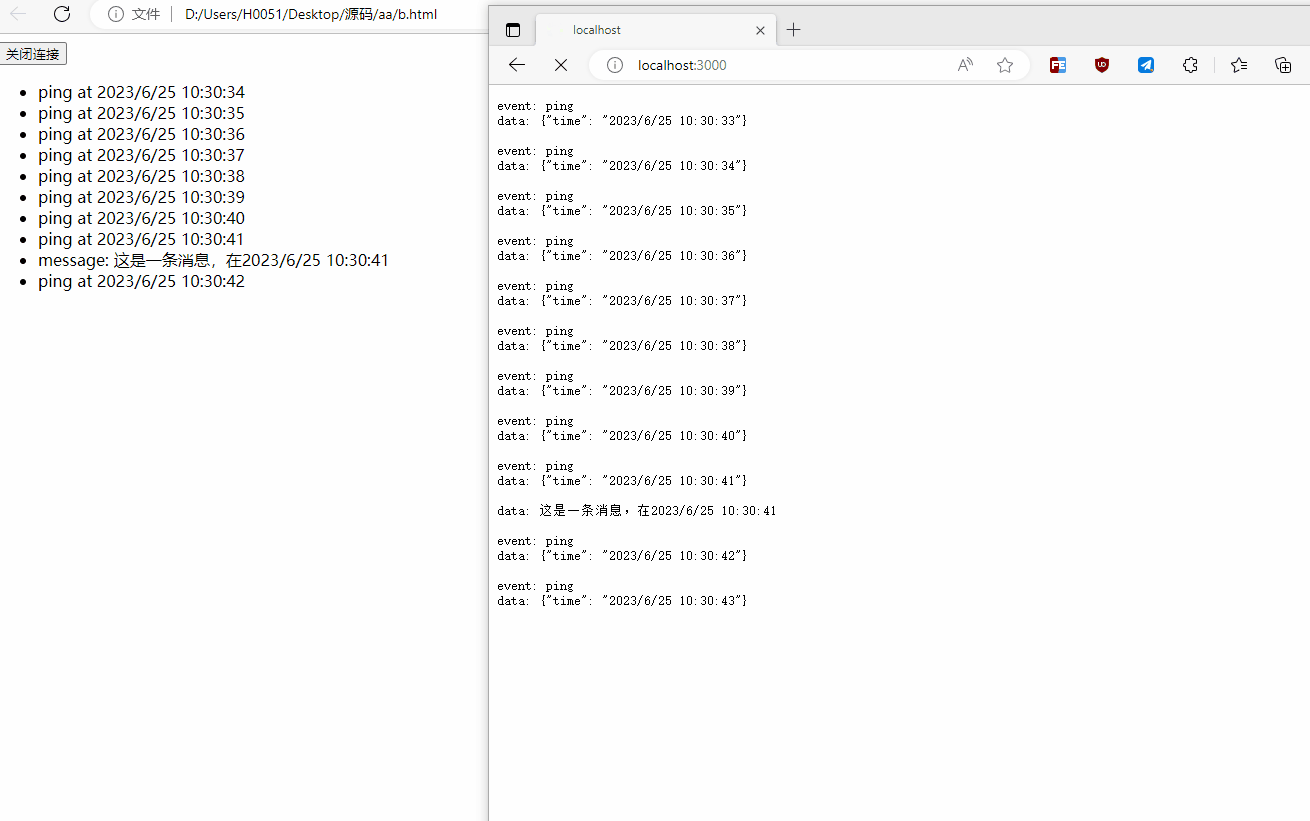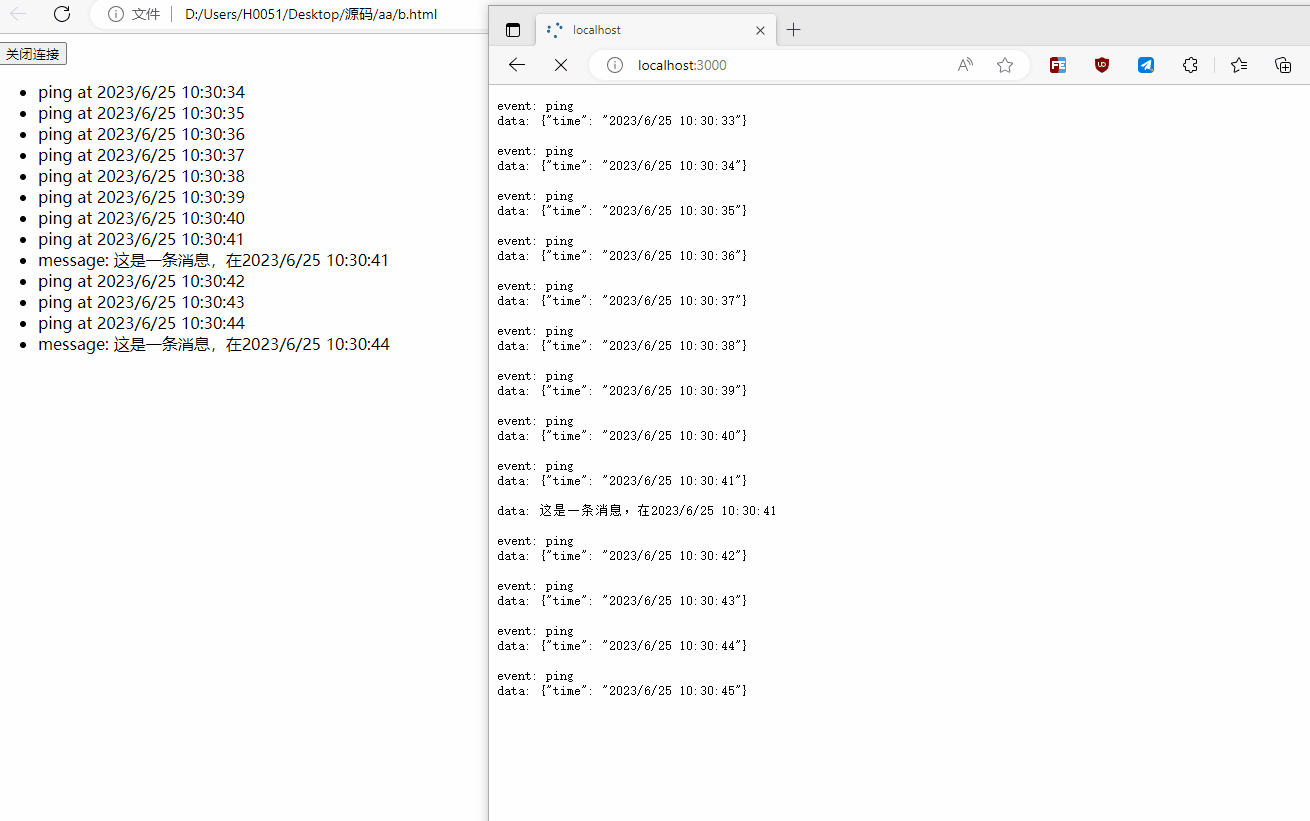
下面是 MySQL 的基本架构示意图,从中可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
- Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 存储引擎层负责 数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
InnoDB 和 MyISAM 区别:
1、InnoDB 支持事务,而 MyISAM 不支持事务
2、InnoDB 支持行级锁,而 MyISAM 支持表级锁
3、InnoDB 支持 MVCC, 而 MyISAM 不支持
4、InnoDB 支持外键,而 MyISAM 不支持
5、InnoDB 不支持全文索引,而 MyISAM 支持。(MySQL5.6 以后,InnoDB 已经可以支持全文索引了)
连接器
连接器负责跟客户端建立连接、获取权限、维持和管理连接。
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。
客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时(28800 秒)。
show variables like 'wait_timeout';数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以建议在使用中要尽量减少建立连接的动作,也就是 尽量使用长连接(通过数据库连接池维护一些长连接)。
但是全部使用长连接后,可能会出现有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的 内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启 了。
解决方法:
1、定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
2、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
MySQL :: MySQL 8.0 C API Developer Guide :: 5.4.62 mysql_reset_connection()
mysql_reset_connection() 影响以下与会话状态相关的信息:
- 回滚活跃事务并重新设置自动提交模式
- 释放所有的表锁
- 关闭或删除所有的临时表
- 重新初始化会话的系统变量值
- 丢失用户定义的变量设置
- 释放 prepared 语句
- 关闭 handler 变量
- 将 last_insert_id() 的值设置为 0
- 释放 get_lock() 获取的锁
- 清空通过 mysql_bind_param() 调用定义的当前查询属性 返回值: 0 表示成功,非 0 表示发生了错误。
查询缓存
连接建立完成后,执行逻辑就会来到第二步:查询缓存。
建立连接后,语句会同时传给查询缓存和分析器,如果能在缓存中匹配到该语句,则会直接返回其 value,执行器里的该语句停止运行,如果缓存中没有匹配到,则分析器继续执行,到执行器才会真正被执行。(看上图连接器往下走的两个箭头)
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
多数情况下,不建议使用查询缓存,因为查询缓存往往弊大于利。
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。对于更新频繁的数据来说,查询缓存的命中率会非常低。
MySQL 也提供了按需使用的方式,可以将参数 query_cache_type 设置为 DEMAND ,这样对默认的 SQL 语句都不使用查询缓存。对于确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定。
mysql> select SQL_CACHE * from T where ID=10;- query_cache_type=0/OFF:关闭查询缓存。
- query_cache_type=1/ON:开启查询缓存。
- query_cache_type=2/DEMAND: 当使用 SELECT SQL_CACHE会开启缓存
have_query_cache 表示这个mysql版本是否支持查询缓存。
query_cache_limit 表示单个结果集所被允许缓存的最大值。
query_cache_min_res_unit 每个被缓存的结果集要占用的最小内存。
query_cache_size 用于查询缓存的内存大小。
Qcache_free_memory 查询缓存目前剩余空间大小。
Qcache_hits 查询缓存的命中次数。
Qcache_inserts 查询缓存插入的次数(未命中数)
The query cache is deprecated as of MySQL 5.7.20, and is removed in MySQL 8.0.
MySQL :: MySQL 8.0: Retiring Support for the Query Cache
1.命中率比较低
2.要进行多一次hash计算,key是sql语句的hash值(查询条件位置变动都可能导致hash值不一致)
3.内存消耗比较大
分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
执行器
MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
权限验证不仅仅在执行器这部分会做,在分析器之后,也就是知道了该语句要“干什么”之后,也会先做一次权限验证。叫做 precheck。而 precheck 是无法对运行时涉及到的表进行权限验证的,比如使用了触发器的情况。因此在执行器这里也要做一次执行时的权限验证。
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
你会在数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。