0.相关概念
1.什么是NameNode?
NameNode是整个文件系统的管理节点,它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。并接收用户的操作请求。
2.SecondaryNameNode的主要作用?
SecondaryNameNode定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。
1.HDFS写入流程(hdfs dfs -put /a.avi /aaa/bbb)
- (0)HDFS的客户端可以创建FileSystem对象实例,该类中封装了HDFS文件系统操作的相关操作。
- (1)客户端Client通过调用FileSystem对象的create()方法,通过RPC向NameNode发起文件上传请求,NameNode执行各种检查判断:目标文件是否存在,父目录是否存在以及客户端是否具有创建文件的权限,并返回是否可以上传,可以则会返回FSDataOutputStream输出流对象给客户端用于写数据。
- (2)客户端Client将文件进行切分,切分为几个数据块
- (3)客户端请求第一个数据块block该传到哪些DataNode服务器上。
- (4)NameNode会返回可用的DataNode的地址
- (5)客户端通过FSDataOutputStream开始请求向第一个DataNode上传数据,第一个DataNode收到请求后会向第二个DataNode请求,直到整个通信管道pipeline的建立。
- (6)通信管道pipeline建立后,客户端开始向第一个DataNode上传第一个数据块,在上传的过程中会将数据拆分为一个个数据包packet,默认大小为64k,第一个DataNode收到packet后会传给第二个DataNode,再传给第三个DataNode。
- (7)数据以packet大小在通信管道上传输着,在传输的反方向上,会通过ACK应答机制校验数据包是否传输成功,最后由pipeline第一个DataNode结点将ack消息发送给客户端Client。
- (8)当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个 block 到服务器,待所有的数据块传输完成后,FSDataOutputStream调用close()方法关闭输出流。

1.HDFS读取流程(hdfs dfs -get /aaa/bbb/a.avi /)
- (1)Client会向NameNode发起RPC请求,NameNode接收读取的请求,然后检查用户是否具有读取数据的权限以及判断在指定路径下是否存在这个文件。
- (2)NameNode会视情况返回文件的部分或者全部的block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址,这些返回的DataNode地址会按照集群拓扑结构计算出DataNode与客户端的距离,然后进行排序。
- (3)客户端Client选取排序靠前的DataNode读取block,底层本质上是通过类FSDataInputStream建立Socket Stream,重复地调用父类DataInputStream的read方法,直到这个块上的数据读取完毕。
- (4)最终读取来的所有的block会合并成一个完整的文件。

2.NameNode和SecondaryNameNode工作机制
2.1 名词熟悉:
1、元数据
·元数据必须存储在内存当中(保证快速检索);
·元数据必须持久化(保证数据的安全持久);
·将元数据信息保存在fsimage镜像文件当中
2.fsimage文件
·保存元数据信息的文件
·是NameNode中关于元数据的镜像
·包含了NameNode管理下的所有DataNode中文件以及文件Block以及block所在的DataNode的元数据信息
3.Edits文件
·edits编辑日志文件记录了客户端操作元数据的信息
2.2 NameNode端的工作流程
- (0)首先得明白:Namenode始终在内存中保存metadata元数据,用于处理客户端对元数据的增删改查的请求,而Hadoop会维护一个fsimage文件,也就是NameNode中元数据metadata的镜像,但是fsimage并不会随时都与NameNode内存中的元数据metadata保持一致,而是每隔一段时间通过合并edits文件来更新内容。
- (1)第一次启动NameNode格式化后,会创建fsimage镜像文件和edits编辑日志文件(若不是第一次启动,则直接加载fsimage镜像文件和edits编辑日志文件到内存)。
- (2)客户端对元数据发起增删改查的请求。
- (3)NameNode记录操作日志,更新滚动日志
- (4)NameNode对内存中的数据进行增删改查操作。
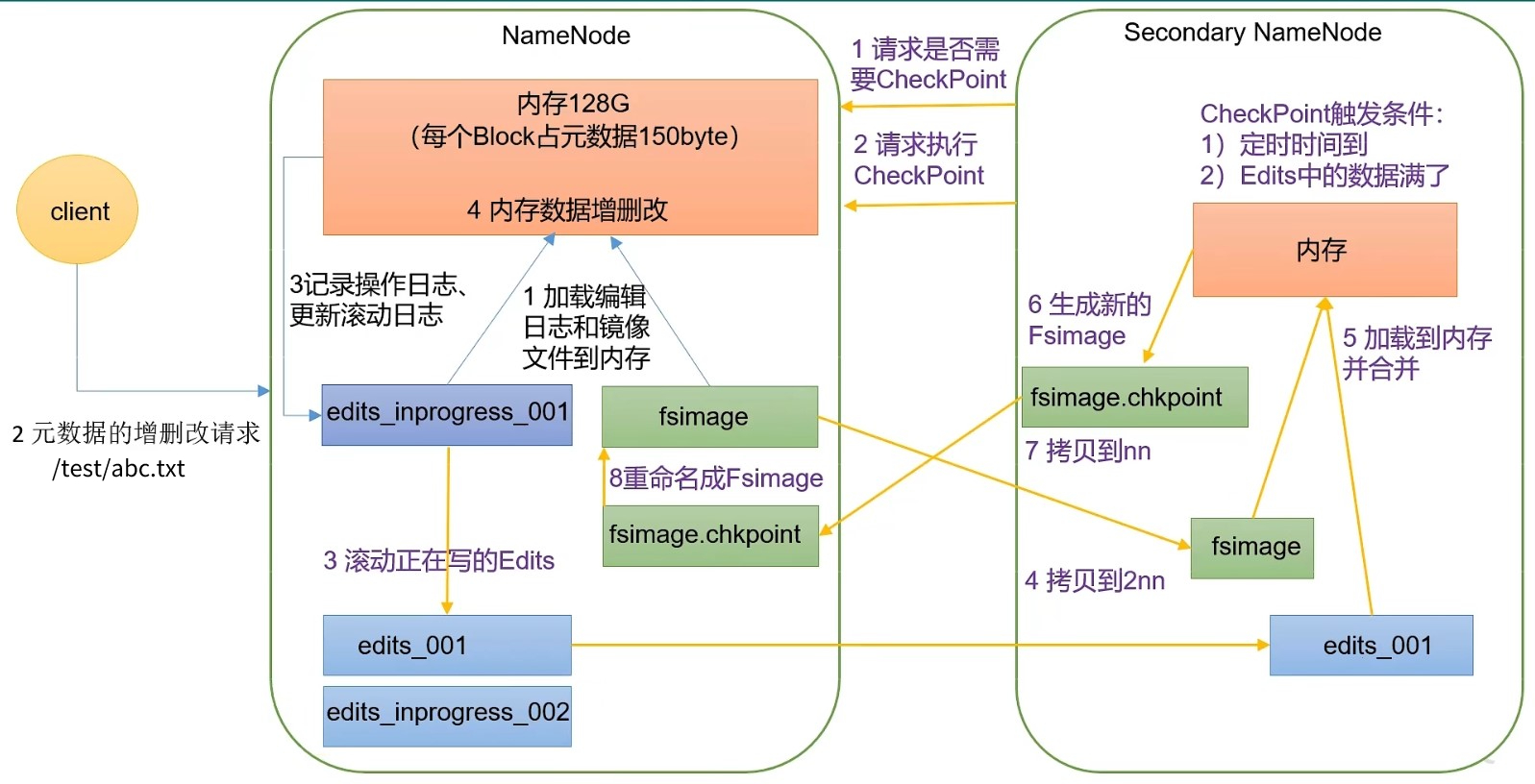
2.3 Secondary NameNode工作流程
- (1)Secondary NameNode询问NameNode是否需要执行checkpoint检查点(默认Edits记录的修改次数达到一定值,或者距离上个checkpoint时间间隔了一定时间)
- Secondary NameNode请求执行check point
- NameNode的edit_inprogress_001(
edits_inprogress_xxx存储的是还没有更新到edits中的数据)中存储的改变向量滚动写入到Edits,如果客户端此时有向NameNode发出改变元数据的请求,那么新的改变向量会被暂时写入到edit_inprogress_002中。 - 将NameNode中的Edits和fsimage拷贝到SecondaryNameNode
- Secondary NameNode将Edits、fsimage信息加载到自己的内存当中,在fsimage基础上顺序执行Edits中改变向量。
- 将内存中的计算结果生成新的镜像文件fsimage.checkpoint
- 将fsimage.checkpoint拷贝给NameNode
- NameNode将fsimage.checkpoint重命名为fsimage,覆盖原有的fsimage
-