kafka集群搭建
搭建参考
https://www.toutiao.com/article/6496743889053942286/?log_from=d5d6394cf75d_1687599146327
zk下载位置
国内:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
国外:Apache ZooKeeper
kafka位置
国内:Index of /apache/kafka
国外:Apache Kafka
spark集群搭建
搭建参考
https://www.toutiao.com/article/6690323260132819468/?log_from=b6bc7fd413909_1687599567164
Spark之三大集群模式—详解(3)-腾讯云开发者社区-腾讯云
下载位置
国内最新版本: Index of /apache/spark
国内历史版本:Index of /dist/spark
注意:历史版本下载位置如下
链接:Index of /apache

standalone集群模式搭建
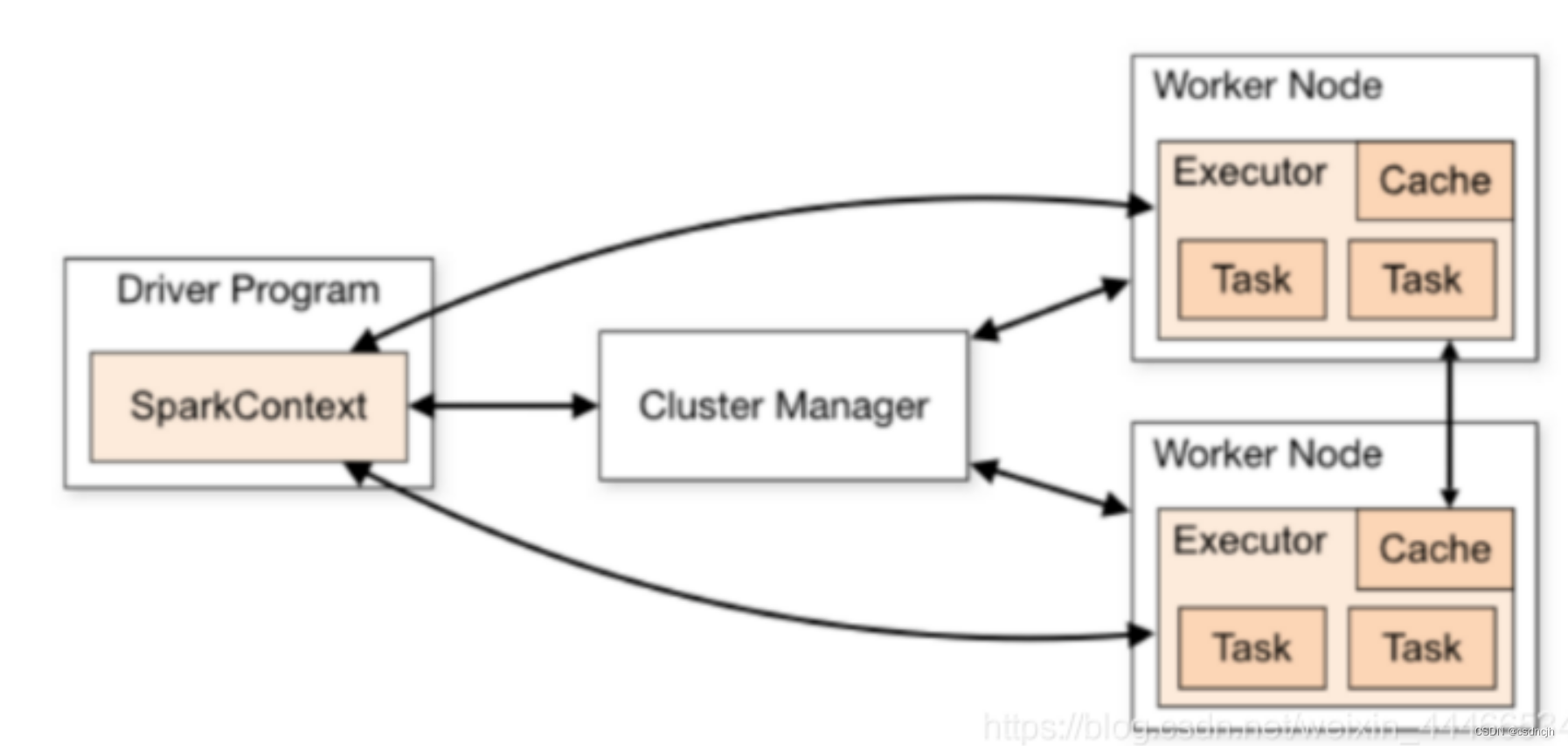
集群架构
排除防火墙干扰
注意先关闭防火墙(测试环境)
systemctl stop firewalld.service
systemctl disable firewalld.service集群规划
node01:master
node02:slave/worker /etc/hosts
192.168.10.159 node02
192.168.10.153 node01配置免密登录
需要配置master到slave节点的免密登录
node01中:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_dsa.pub root@node02:/optnode02中:
cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys安装java环境
如果选择在线安装可以使用
yum -y install java-1.8.0-openjdk*修改配置
cd /root/spark-3.4.0-bin-hadoop3-scala2.13/conf
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
#配置java环境变量(如果之前配置过了就不需要动了)
#指定spark Master的IP
export SPARK_MASTER_HOST=node01
#指定spark Master的端口
export SPARK_MASTER_PORT=7077vi slaves
node02配置spark环境变量
/etc/profile
export SPARK_HOME=/root/spark-3.4.0-bin-hadoop3-scala2.13
export PATH=$PATH:$SPARK_HOME/bin配置分发
scp -r /root/spark-3.4.0-bin-hadoop3-scala2.13 node02:/root/启动和停止
cd /root/spark-3.4.0-bin-hadoop3-scala2.13/sbin/
集群启动和停止
在主节点上启动spark集群
./start-all.sh
在主节点上停止spark集群
./stop-all.sh
单独启动和停止
在 master 安装节点上启动和停止 master:
start-master.sh
stop-master.sh
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)start-slaves.sh
stop-slaves.sh
集群检查
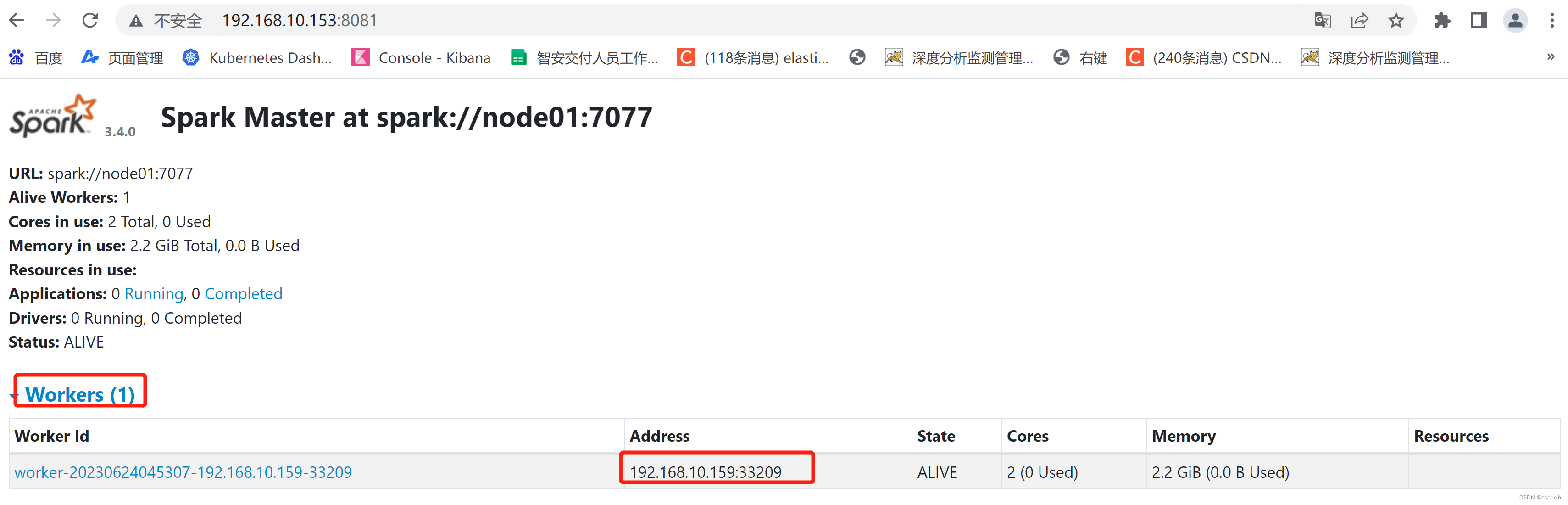
web界面查看
正常启动spark集群后,查看spark的web界面,查看相关信息。
注意也有可能是8081端口。
http://node01:8080/
jps查看
在master节点上jps可以看到Master进程,在slave节点上jps可以看到Worker进程,可以初步判定集群是否启动成功。
使用样例
官方首选推荐使用scala,也可以使用更加熟悉的java或者python
scala环境准备
下载安装scala
IDEA新建Scala+Maven工程步骤指南(2020.09.21)_idea创建scala maven项目_jing_zhong的博客-CSDN博客
maven依赖
注意:spark相关的依赖打包时候可以不用打入jar包
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.13</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.13</artifactId>
<version>3.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.4.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20210307</version>
</dependency>
</dependencies>scala读取kafka数据并打印结果
KafaDemo
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object KafaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("KafaDemo")
//刷新时间设置为1秒
val ssc = new StreamingContext(conf, Seconds(1))
//消费者配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.10.153:9092", //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group", //消费者组名
"auto.offset.reset" -> "latest", //latest自动重置偏移量为最新的偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)) //如果是true,则这个消费者的偏移量会在后台自动提交
val topics = Array("top1") //消费主题,可以同时消费多个
//创建DStream,返回接收到的输入数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
//打印获取到的数据,因为1秒刷新一次,所以数据长度大于0时才打印
stream.foreachRDD(f => {
if (f.count > 0)
f.foreach(f => println(f.value()))
})
ssc.start();
ssc.awaitTermination();
}
}
scala解析json并保存数据
scala读取kafka的json数据,处理以后添加字段,保存数据入一个新的topic
KafkaStreamingExample
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s.jackson.JsonMethods._
import org.json4s.JsonDSL._
import org.json4s._
object KafkaStreamingExample {
implicit val formats: Formats = DefaultFormats
def main(args: Array[String]): Unit = {
// 创建SparkConf对象
val sparkConf = new SparkConf().setAppName("KafkaStreamingExample").setMaster("local[*]")
// 创建StreamingContext对象
val ssc = new StreamingContext(sparkConf, Seconds(5))
// 设置Kafka参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.10.153:9092", // Kafka broker地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-consumer-group", // 消费者组ID
"auto.offset.reset" -> "latest", // 从最新的offset开始读取数据
"enable.auto.commit" -> (false: java.lang.Boolean) // 关闭自动提交offset
)
// 设置要读取的Kafka topic
val topics = Array("input_topic")
// 创建DStream,从Kafka读取数据
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
// 解析每条数据的value值为JSON对象
val parsedStream = kafkaStream.map(record => {
implicit val formats = DefaultFormats
parse(record.value)
})
// 过滤出age>20的数据
val filteredStream = parsedStream.filter(json => (json \ "age").extract[Int] > 20)
// 增加性别字段
val genderStream = filteredStream.map(json => {
val name = (json \ "name").extract[String]
val gender = if (name.endsWith("a")) "female" else "male"
json.asInstanceOf[JObject] ~ ("gender" -> JString(gender))
})
// 将新数据写入另一个Kafka topic中
genderStream.foreachRDD(rdd => {
rdd.foreachPartition(iter => {
val producer = createKafkaProducer() // 创建Kafka生产者
iter.foreach(json => {
val value = compact(render(json))
val record = new org.apache.kafka.clients.producer.ProducerRecord[String, String]("output_topic", value)
producer.send(record) // 发送数据到Kafka
})
producer.close() // 关闭Kafka生产者
})
})
// 启动StreamingContext
ssc.start()
ssc.awaitTermination()
}
def createKafkaProducer(): org.apache.kafka.clients.producer.KafkaProducer[String, String] = {
val props = new java.util.Properties()
props.put("bootstrap.servers", "192.168.10.153:9092") // Kafka broker地址
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
new org.apache.kafka.clients.producer.KafkaProducer[String, String](props)
}
}java解析json并打印结果
java读取kafka数据,处理以后添加字段打印结果
KafkaStreamingExample4
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.json.JSONObject;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class KafkaStreamingExample4 {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf()
// .set("spark.streaming.logLevel","ERROR")
.setAppName("Kafka Streaming Example")
.setMaster("local[*]");
JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(1000));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "192.168.10.153:9092");
kafkaParams.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaParams.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaParams.put("group.id", "spark-streaming");
kafkaParams.put("auto.offset.reset", "latest");
String topic = "input_topic";
JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(Collections.singleton(topic), kafkaParams)
);
stream.map(record -> record.value())
.map(val->{
JSONObject json = new JSONObject(val);
json.put("tag","tagxxxxx");
return json.toString();
})
.print();
jssc.start();
jssc.awaitTermination();
}
}java解析json并读取结果
java读取kafka的json数据,处理以后添加字段,保存数据入一个新的topic
KafkaSparkStreamingExample3
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.*;
import org.json.JSONException;
import org.json.JSONObject;
import java.util.*;
public class KafkaSparkStreamingExample3 {
public static void main(String[] args) throws InterruptedException {
// 设置 Spark Streaming 应用的名称和 master
SparkConf conf = new SparkConf().setAppName("KafkaSparkStreamingExample").setMaster("local[*]");
// 创建 Spark Streaming 上下文对象
JavaStreamingContext streamingContext = new JavaStreamingContext(conf, Durations.seconds(1));
// 设置 Kafka 相关参数
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "192.168.10.153:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "spark-streaming");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
// 设置要从 Kafka 读取的 topic
Collection<String> topics = Arrays.asList("input_topic");
// 创建 Kafka direct stream
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
// 解析 Kafka 中的数据
stream.foreachRDD(rdd -> {
// OffsetRange[] offsetRanges = ((CanCommitOffsets) rdd.rdd()).offsetRanges();
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
rdd.foreachPartition(records -> {
while (records.hasNext()) {
ConsumerRecord<String, String> record = records.next();
String data = record.value();
System.out.println("Received data: " + data);
// 解析 JSON 数据
try {
JSONObject json = new JSONObject(data);
String name = json.getString("name");
int age = json.getInt("age");
// 过滤年龄大于20的数据
if (age > 20) {
String gender = getGender(name);
json.put("gender", gender);
// 将结果写入新的 Kafka topic
writeToKafka(json.toString(), "output_topic");
}
} catch (JSONException e) {
e.printStackTrace();
}
}
});
// 提交消费的offset
((CanCommitOffsets) stream.inputDStream()).commitAsync(offsetRanges);
});
// 启动 Spark Streaming 应用程序
streamingContext.start();
// 等待程序运行结束
streamingContext.awaitTermination();
}
private static void writeToKafka(String data, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.153:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, data);
producer.send(record);
producer.flush();
System.out.println("Data written to Kafka: " + data);
}
private static String getGender(String name) {
// 根据名字判断性别
// 在此处添加你的逻辑判断代码
return "unknown";
}
}验证结果
./bin/kafka-console-producer.sh --bootstrap-server 192.168.10.153:9092 --topic input_topic测试数据
{"name":"bob","id":1,"age":23}
{"name":"tom","id":1,"age":21}
{"name":"bob","id":1,"age":5}
{"name":"jack","id":1,"age":45}查看结果
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic output_topic来源
spark中文文档:http://spark.apachecn.org/#/

![指针与数组--动态数组(2)[1、长度可变的一维动态数组 2、长度可变的二维动态数组]](https://img-blog.csdnimg.cn/7fb31292063940e4bdbe1d39a5bc8117.png)