目录
- 1 redis线程模型
- 1.1 线程组成
- 1.2 redis命令处理是单线程
- 2 redis db 存储分析
- 2.1 先了解代码
- server.h
- dict.h
- 2.2 从kv存储分析
- 2.3 负载因子
- 2.4 渐进式rehash机制
- 数据访问scan
- 3 数据模型分析
- 以zset为例
- 跳表
1 redis线程模型
1.1 线程组成
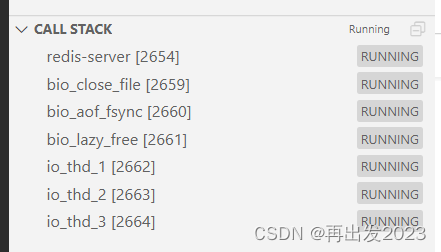
redis-server
命令处理
网络事件的监听
bio close file 异步关闭大文件
bio aof fsync 异步 aof 刷盘
bio lazy free 异步清理大块内存
io thd * io 多线程
emalloc bg thd jemalloc 后台线程
1.2 redis命令处理是单线程
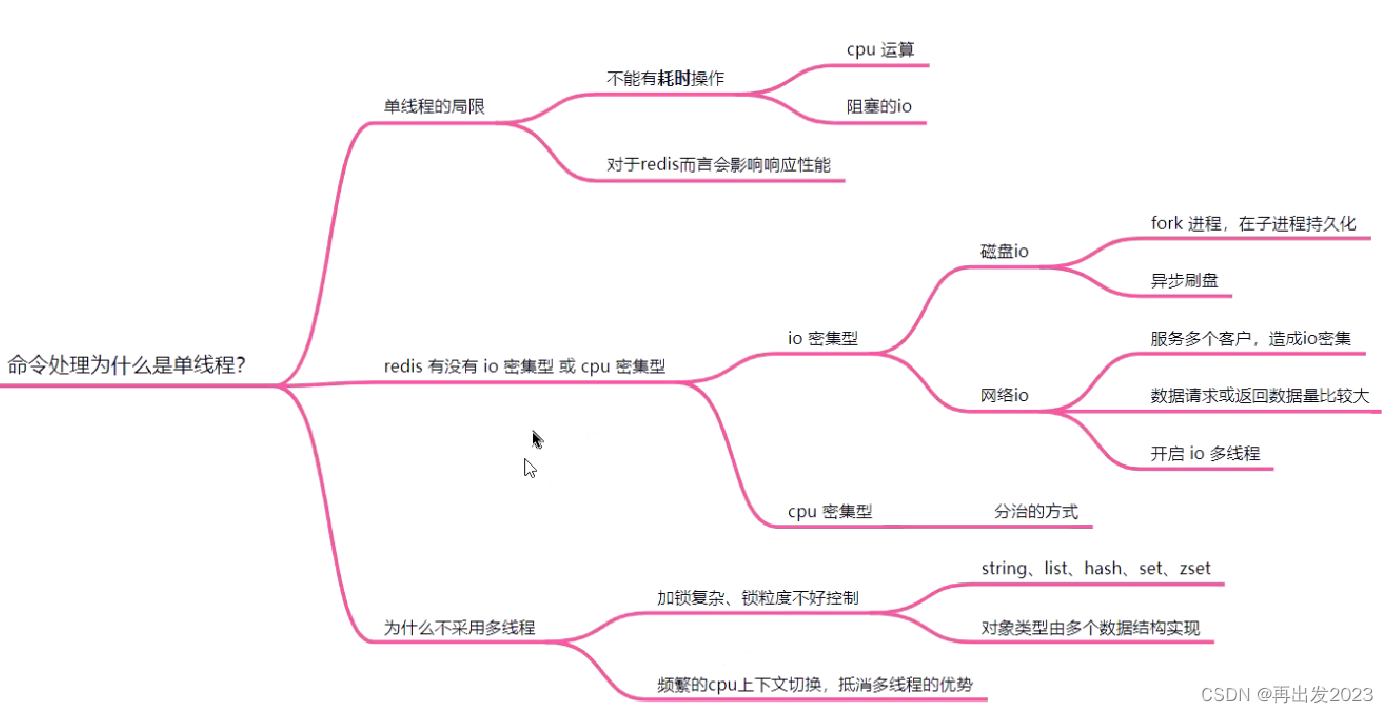
单线程为什么快?
2 redis db 存储分析
2.1 先了解代码
server.h
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */ ----> 自动过期的key
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ ----> 事物操作时有用到的 watch
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
clusterSlotToKeyMapping *slots_to_keys; /* Array of slots to keys. Only used in cluster mode (db 0). */
} redisDb;
dict *dict:指向字典对象的指针,用于存储键值对数据。字典是Redis中的核心数据结构,用于快速查找和访问键值对。
dict *expires:指向字典对象的指针,用于存储键的过期时间。当键设置了过期时间时,会将键和其对应的过期时间存储在这个字典中。
dict *blocking_keys:指向字典对象的指针,用于存储被阻塞的键。当某个客户端在执行阻塞操作时,将被阻塞的键存储在这个字典中。
dict *ready_keys:指向字典对象的指针,用于存储状态已改变的键。当某个键的值在被其他操作修改后,将把该键存储在这个字典中。
dict *watched_keys:指向字典对象的指针,用于存储被监视的键。当某个事务中的键被监视时,将被监视的键存储在这个字典中。
int id:表示数据库的ID。
long long avg_ttl:表示数据库中所有键的平均过期时间。
unsigned long expires_cursor:用于过期键的迭代游标。
list *defrag_later:指向链表对象的指针,用于存储需要碎片整理的键。
clusterSlotToKeyMapping *slots_to_keys:用于集群模式下的槽位和键的映射。
dict.h
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
注意 dictEntry **ht_table[2];
2.2 从kv存储分析
怎么从key定位到value?
哈希原理:
数组 + hash(key) % 数组长度 ===>确定value存储位置 参考https://blog.csdn.net/qq43645149/article/details/131242533 的3.3节
- 字符串key经过 hash 函数运算得到 64 位整数;
- 相同字符串key多次通过 hash 函数得到相同的 64 位整数;
- 整数对 取余可以转化为位运算;
- 抽屉原理 n+1个苹果放在 n 个抽屉中,苹果最多的那个抽屉至少有 2 个苹果;
64位整数远大于数组的长度,比如数组长度为 4,那么 1、5、9、1+4n 都是映射到1号位数组;所以大概率会发生冲突;
ht_table二维指针,这里可以理解为指针数组,对应哈希存储数组 ht 的每一个槽位ht[i] 挂的是一个链表
ht_table[2]中的2,怎么理解?ht的槽位成对出现,ht[1]是为扩容备用的。
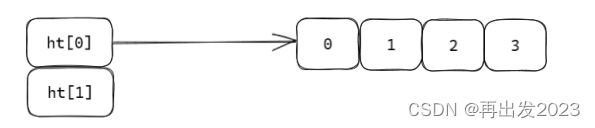
避免冲突,使用强随机函数siphash, 然后就是 扩容
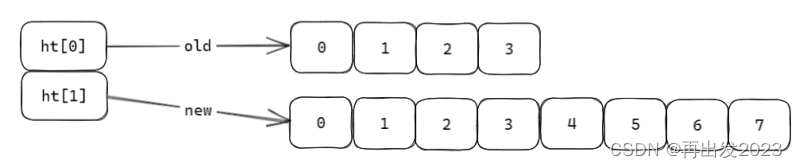
unsigned long ht_used[2]; 用来保存ht[0], ht[1]的长度,用2的n次幂表示size,
这样hash(key) % size 取余运算就可以优化为位运算:hash(key) & (2^-1) 。
怎么判断扩容呢?
2.3 负载因子
负载因子 = used / size;used 是数组存储元素的个数,
size 是数组的长度;
负载因子越小,冲突越小;负载因子越大,冲突越大;
redis 的负载因子是 1;
如果负载因子 > 1,则会发生扩容;扩容的规则是翻倍;
如果正在 fork (在 rdb、aof 复写以及 rdb-aof 混用情况下)时,会阻止扩容;但是此时若负载因子 > 5,
索引效率大大降低, 则马上扩容;这里涉及到写时复制原理;
如果负载因子 < 0.1,则会发生缩容;缩容的规则是恰好包含used 的 ;
恰好的理解:假如此时数组存储元素个数为 9,恰好包含该元素的就是 ,也就是 16;
这里有一个问题,当执行scan命令的时候,突然发生扩容或者缩容怎么办?
127.0.0.1:6379> SET key1 "value1"
OK
127.0.0.1:6379> SET key2 "value2"
OK
127.0.0.1:6379> SET key3 "value3"
OK
127.0.0.1:6379> SCAN 0 MATCH key* COUNT 100
1) "13" // 游标值
2)
1) "key3"
2) "key2"
3) "key1" // 匹配模式为key*,返回所有以key开头的键
2.4 渐进式rehash机制
源码位置:
./redis-main/src/dict.c:211:int dictRehash(dict *d, int n)
当 hashtable 中的元素过多的时候,不能一次性 rehash 到ht[1];这样会长期占用 redis,其他命令得不到响应;所以需
要使用渐进式 rehash;
rehash步骤:
将 ht[0] 中的元素重新经过 hash 函数生成 64 位整数,再对ht[1] 长度进行取余,从而映射到 ht[1];
渐进式规则:
- 分治的思想,将 rehash 分步到之后的每步“增、删、查”的操作当中;
- 在定时器中,最大执行一毫秒 rehash ;每次步长 100 个数组槽位; (避免命令单线程阻塞)
处于渐进式rehash阶段不会发生扩容缩容。
对应源码:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree)
dictEntry *dictFind(dict *d, const void *key)
dictEntry *dictGetRandomKey(dict *d)
/* Rehash in ms+"delta" milliseconds. The value of "delta" is larger
* than 0, and is smaller than 1 in most cases. The exact upper bound
* depends on the running time of dictRehash(d,100).*/
int dictRehashMilliseconds(dict *d, int ms) {
if (d->pauserehash > 0) return 0;
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
数据访问scan
通过往高位加1,往低位进1的方式遍历,如下图

为什么2对应2和6?因为6%4=2, 6%8=6, 当key时2,6的时候,size=4, key%size = 2。
为什么要用这种访问方式呢?==> 可以确保“扩容”或"缩容的时候“ 可以访问正确遍历完所有的数据(两次缩容或扩容处理不了)。
27.0.0.1:6379> set aa 1
OK
127.0.0.1:6379> set bbb 2
OK
127.0.0.1:6379> set ccccc 3
OK
127.0.0.1:6379> set ddddddddddddd 4
OK
127.0.0.1:6379> keys *
1) "ddddddddddddd"
2) "ccccc"
3) "aa"
4) "bbb"
127.0.0.1:6379> scan 0 match * count 1
1) "2" # 这里提示下一个是2
2) 1) "ddddddddddddd"
# 这个时候,在另外一个终端 执行:127.0.0.1:6379> set ffffffffffffffffff 5
# OK
127.0.0.1:6379> scan 2 match * count 1
1) "6" # 这里提示下一个是6,假装扩容了
2) 1) "ffffffffffffffffff"
127.0.0.1:6379> scan 6 match * count 1
1) "1"
2) 1) "bbb"
127.0.0.1:6379> scan 1 match * count 1
1) "5" # ? aa ccccc 一起出来了?
2) 1) "aa"
2) "ccccc"
127.0.0.1:6379> scan 5 match * count 1
1) "0"
2) (empty array)
aa 与 ccccc 一起出来,aa, ccccc这里是什么存储结构呢?
127.0.0.1:6379> keys *
1) "aa"
2) "ccccc"
3) "ffffffffffffffffff"
4) "ddddddddddddd"
5) "bbb"
3 数据模型分析
数据量小或少的时候,用简单的数据结构,反之用较为复杂的数据结构。
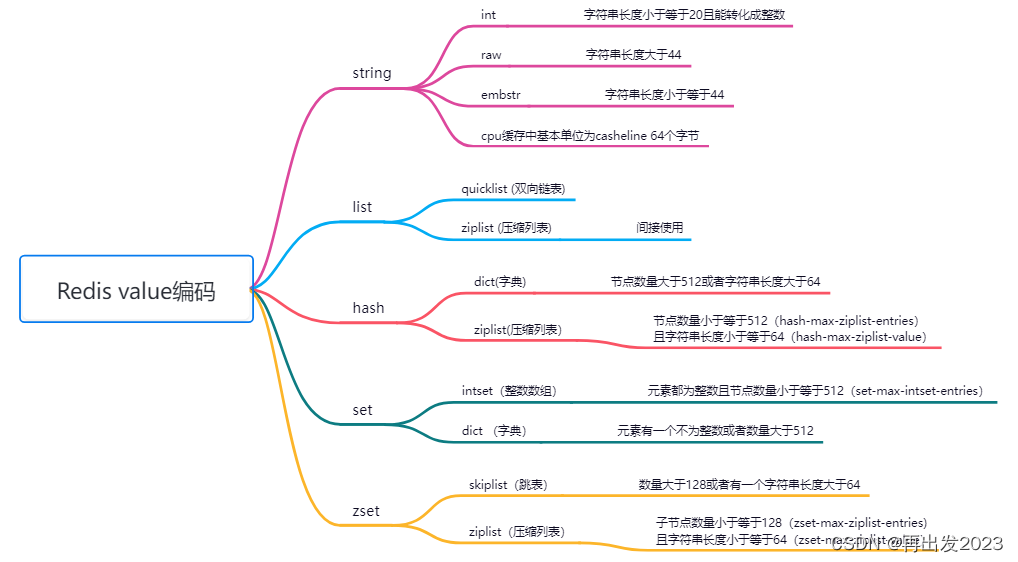
以zset为例

在 redis.conf 可以查找到相关的定义:
zset-max-listpack-entries 128
zset-max-listpack-value 64
然后在t_zset.c中找到 createZsetObject 与 createZsetListpackObject,可加断点调试。
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_listpack_entries == 0 ||
server.zset_max_listpack_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject(); // OBJ_ENCODING_SKIPLIST
} else {
zobj = createZsetListpackObject(); // OBJ_ENCODING_LISTPACK
}
dbAdd(c->db,key,zobj);
}
当元素过大,或者list过长,转换为跳表。
/* check if the element is too large or the list
* becomes too long *before* executing zzlInsert. */
if (zzlLength(zobj->ptr)+1 > server.zset_max_listpack_entries ||
sdslen(ele) > server.zset_max_listpack_value ||
!lpSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST); // 转换为跳表
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
对应1.2节中的:

跳表
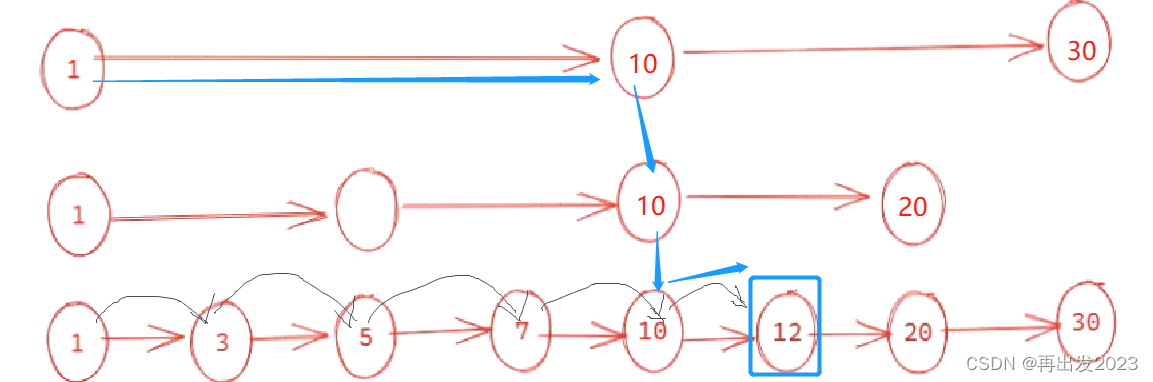
方便范围查询,多层级有序链表,让其实现二分查找的效率,缺点占用的内存空间会多50%。
这里用一个比较特殊的例子(完美跳表,第二层是从第一层每隔一个元素取一个,第三层也是从第二层每隔一个元素取一个。。。)理解一下,如下图,要访问节点12,第一层常规的遍历方法用的次数明显比蓝色箭头用的次数要多。
但是优势不明显,但如果是找节点10,跳表只需比较一次。平均下来接算法复杂度接近于
O
(
log
2
n
)
O(\log_2n)
O(log2n)
注意第一层是有序链表,跳表是从最高层往底层跳,从而找到目标。
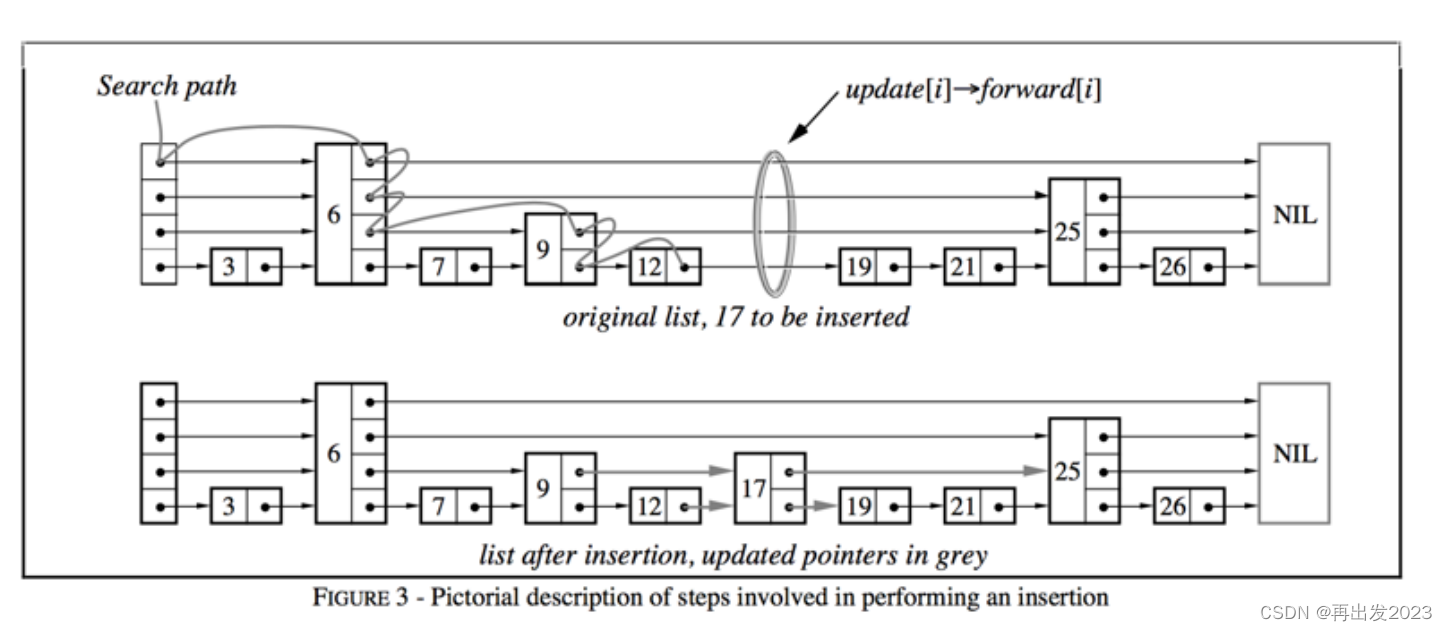
上面的跳表在增加或删除元素时,需要重新构建跳表,效率比较低。
非完美跳表,插入节点会用随机层数的方式,这样第二层对于第三层就可能不会是“每隔一个节点提取一个元素了”,相邻的元素可能会被直接提取到上一层,更高层也是。
另外一个例子:插入17
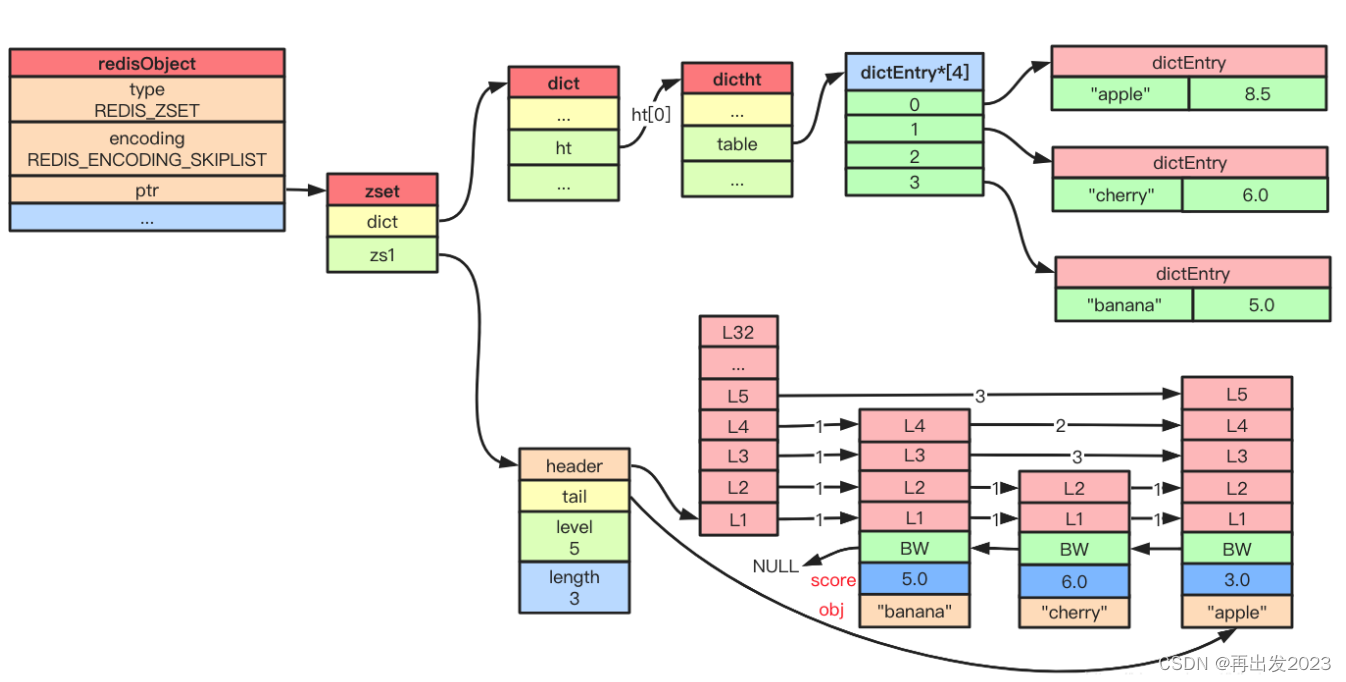
另外,为了快速的索引到某个节点,zset还引入了字典功能,帮助快速的索引到节点。结构图如下:




![数据结构07:查找[C++][朴素二叉排序树BST]](https://img-blog.csdnimg.cn/bee9c8852b0241bbbb517307232303b7.png)