Python使用ORM框架peewee操作数据库
- 前言
- 1. 安装Peewee库并初始化数据库
- 2. 创建数据库连接
- 3. 定义数据表模型类
- 4. 连接数据库并创建表
- 5. 操作数据库
- 5.1 插入数据
- 5.2 查询数据
- 5.3 更新数据
- 5.4 删除数据
- 6. 聚合查询
前言
本文基于MySQL8.x版本的学习,python版本基于当前最新的3.x,windows操作系统下mysql的安装流程,可参考我之前的文章:
Windows MySQL8.0免安装版,配置多个安装实例
Peewee是一个简单而灵活的Python ORM(对象关系映射)框架,它提供了方便的接口和工具,用于在Python应用程序中进行数据库操作。Peewee支持多种数据库后端,包括MySQL、SQLite、PostgreSQL等,使得在不同数据库系统之间进行切换变得更加容易。
1. 安装Peewee库并初始化数据库
-
1.1 首先安装Peewee库,在terminal中输入命令:
pip install peewee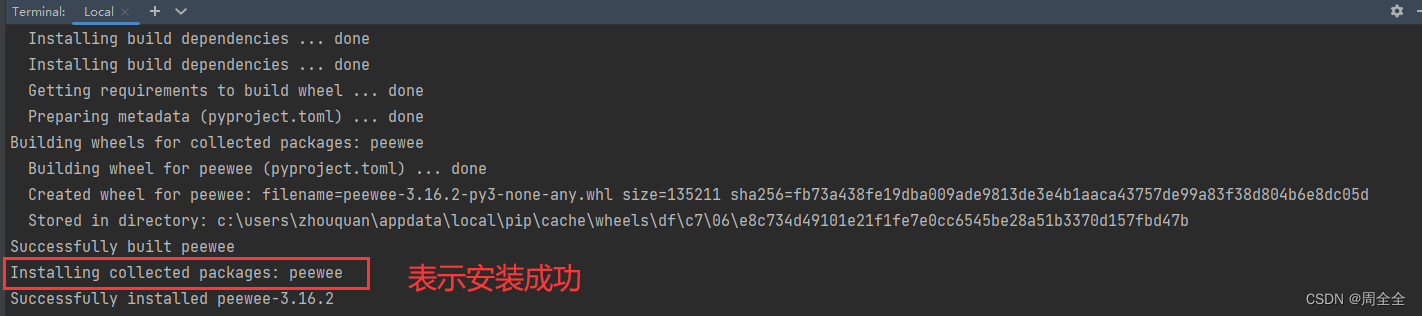
-
1.2 执行mysql脚本,创建mysql数据库和创建数据表
安装好mysql数据库后,执行创建数据库命令
CREATE DATABASE `py_conn_test` CHARACTER SET 'utf8mb4' COLLATE 'utf8mb4_general_ci';执行创建数据表操作
# 书目表 CREATE TABLE `py_conn_test`.`book` ( `id` int UNSIGNED NOT NULL AUTO_INCREMENT, `title` varchar(255) NULL COMMENT '书名', `author` varchar(255) NULL COMMENT '作者', `price` float(10, 2) NULL COMMENT '书名价格', `edition` int NULL COMMENT '版次', PRIMARY KEY (`id`) );
2. 创建数据库连接
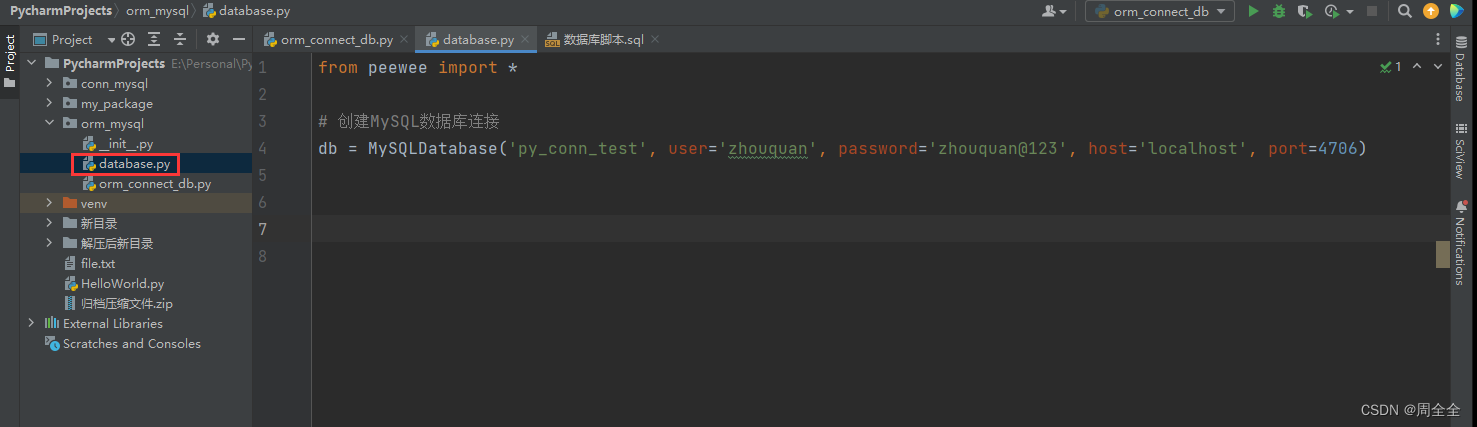
在使用Peewee进行数据库操作之前创建一个数据库连接。输入连接参数:数据库名称、用户名、密码、主机和端口
from peewee import *
# 创建MySQL数据库连接
db = MySQLDatabase('py_conn_test', user='zhouquan', password='zhouquan@123',host='localhost', port=4706)
更好地组织代码,并使代码更易于维护和扩展。我们将数据库连接和映射类集中在一个地方,并在需要的时候导入并使用
新建database.py文件,数据库连接的代码写入此文件
3. 定义数据表模型类
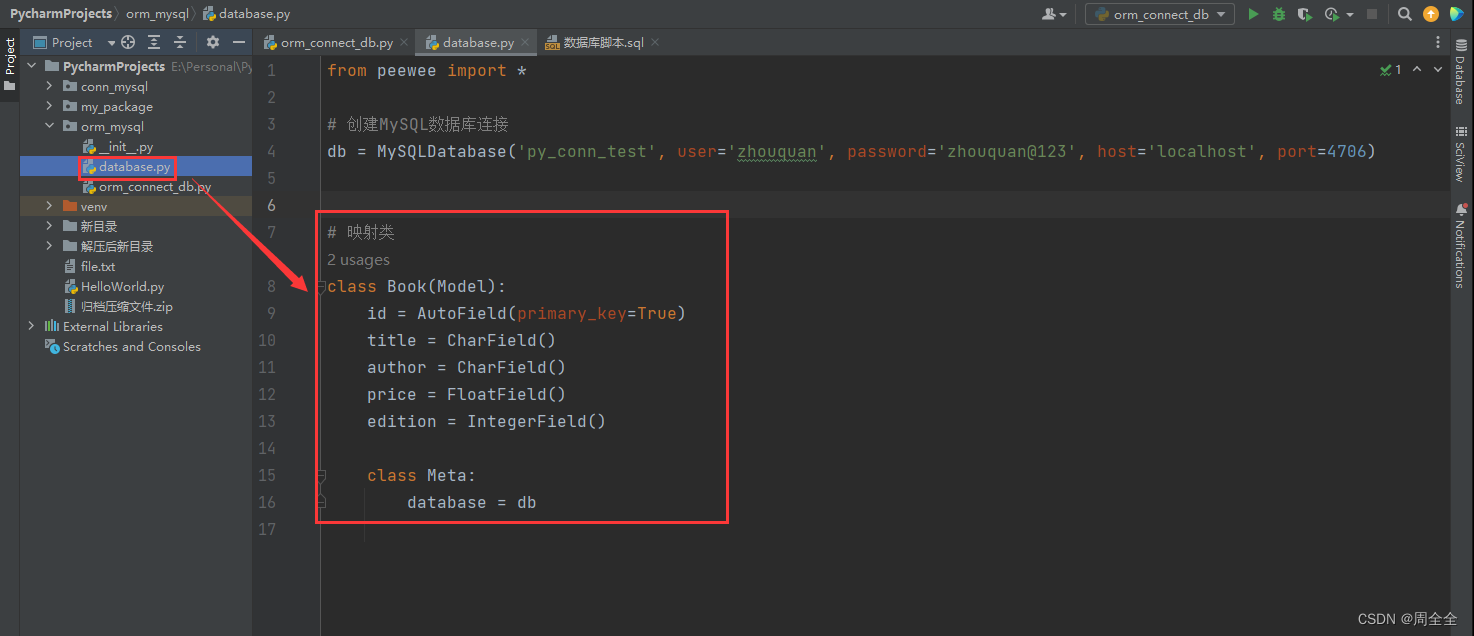
使用Peewee进行数据库操作,需要定义数据表的模型类。每个模型类对应数据库中的一张表,并定义表中的字段以及其他相关属性。
class Book(Model):
id = AutoField(primary_key=True)
title = CharField()
author = CharField()
price = FloatField()
edition = IntegerField()
class Meta:
database = db
在上述示例中,定义了一个名为User的模型类,它继承自Peewee的Model类。title 、author 、price 、edition是该数据表的字段。在Meta类中,指定了该模型类使用的数据库连接。
将映射类写入新建的database.py文件
4. 连接数据库并创建表
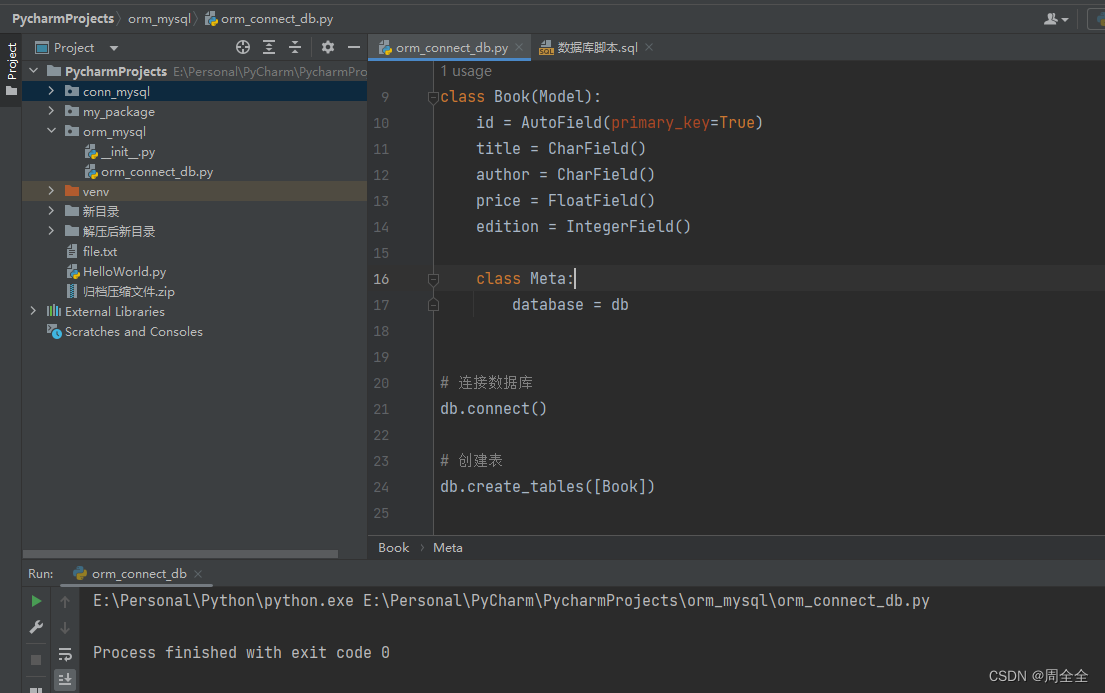
注意:这里仅做示例,在开发中数据表应该是创建好的!因此可以不执行此模块代码示例
在开始使用模型类进行数据库操作之前,需要先连接数据库并创建相关的表。
# 连接数据库
db.connect()
# 创建表
db.create_tables([Book])
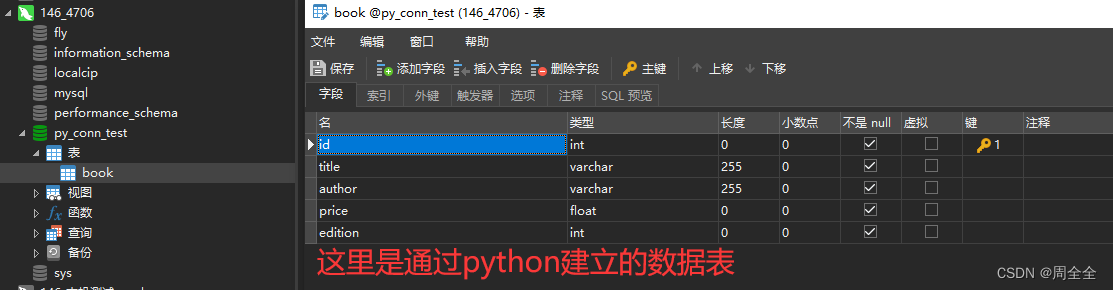
5. 操作数据库
5.1 插入数据
使用Peewee插入数据非常简单,只需创建模型类的实例,并设置相应的属性值,然后调用save()方法保存到数据库中。
# 引入数据库连接模块和Book映射类
from database import db, Book
# 连接数据库
db.connect()
# 插入数据
book = Book(title="三体一", author="刘慈欣", price=59.5, edition=6)
book.save()
book = Book(title="1984", author="乔治奥威尔", price=47.9, edition=2)
book.save()
book = Book(title="万历十五年", author="黄仁宇", price=125.5, edition=3)
book.save()
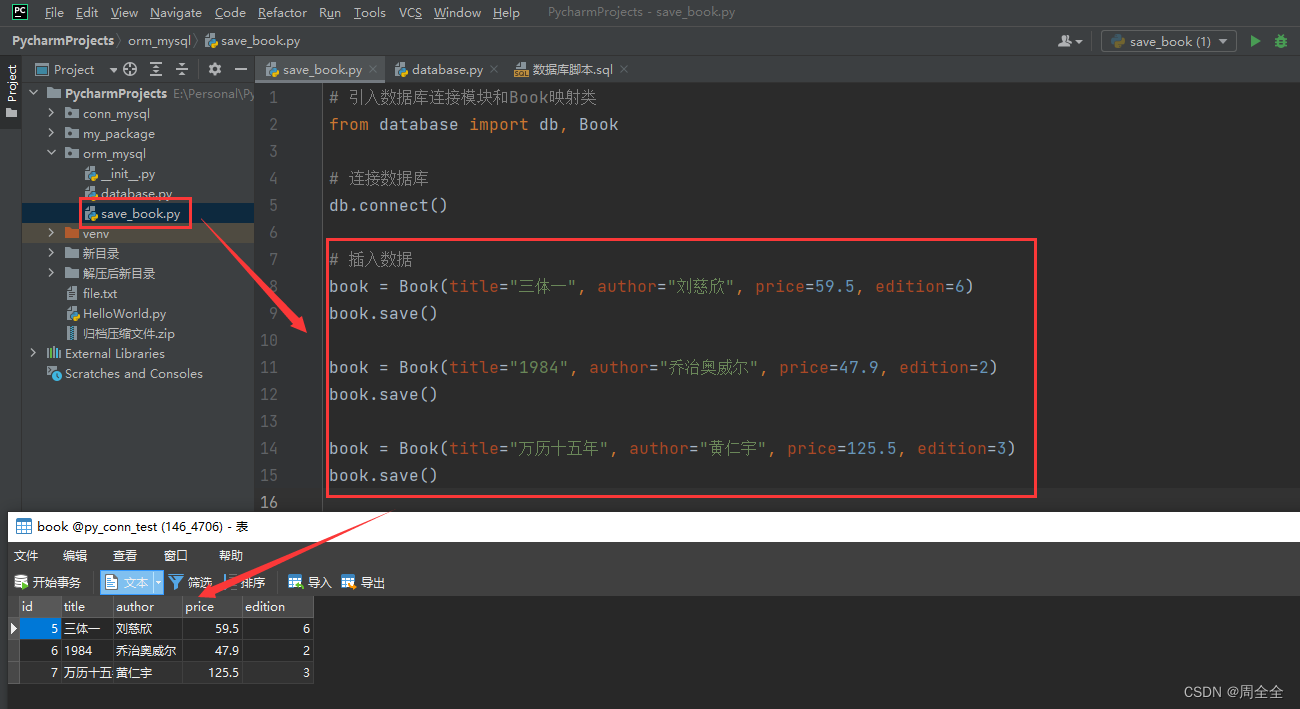
5.2 查询数据
Peewee提供了丰富的查询API,可以灵活地进行条件查询、排序、限制返回结果等操作。
# 引入数据库连接模块和Book映射类
from database import db, Book
# 连接数据库
db.connect()
books = Book.select()
for book in books:
print("全部查询:", book.to_string())
print("--------------------------------------------")
books = Book.select().where(Book.price < 100)
for book in books:
print("价格小于100:", book.to_string())
print("--------------------------------------------")
# 排序查询
books = Book.select().order_by(Book.price.asc())
for book in books:
print("价格升序排序:", book.to_string())
print("--------------------------------------------")
# 限制返回结果数量
books = Book.select().limit(2)
for book in books:
print("限制返回两条结果:", book.to_string())
查询结果如下:
全部查询: id=5,title=三体一,author=刘慈欣,price=59.5,edition=6
全部查询: id=6,title=1984,author=乔治奥威尔,price=47.9,edition=2
全部查询: id=7,title=万历十五年,author=黄仁宇,price=125.5,edition=3
--------------------------------------------
价格小于100: id=5,title=三体一,author=刘慈欣,price=59.5,edition=6
价格小于100: id=6,title=1984,author=乔治奥威尔,price=47.9,edition=2
--------------------------------------------
价格升序排序: id=6,title=1984,author=乔治奥威尔,price=47.9,edition=2
价格升序排序: id=5,title=三体一,author=刘慈欣,price=59.5,edition=6
价格升序排序: id=7,title=万历十五年,author=黄仁宇,price=125.5,edition=3
--------------------------------------------
限制返回两条结果: id=5,title=三体一,author=刘慈欣,price=59.5,edition=6
限制返回两条结果: id=6,title=1984,author=乔治奥威尔,price=47.9,edition=2
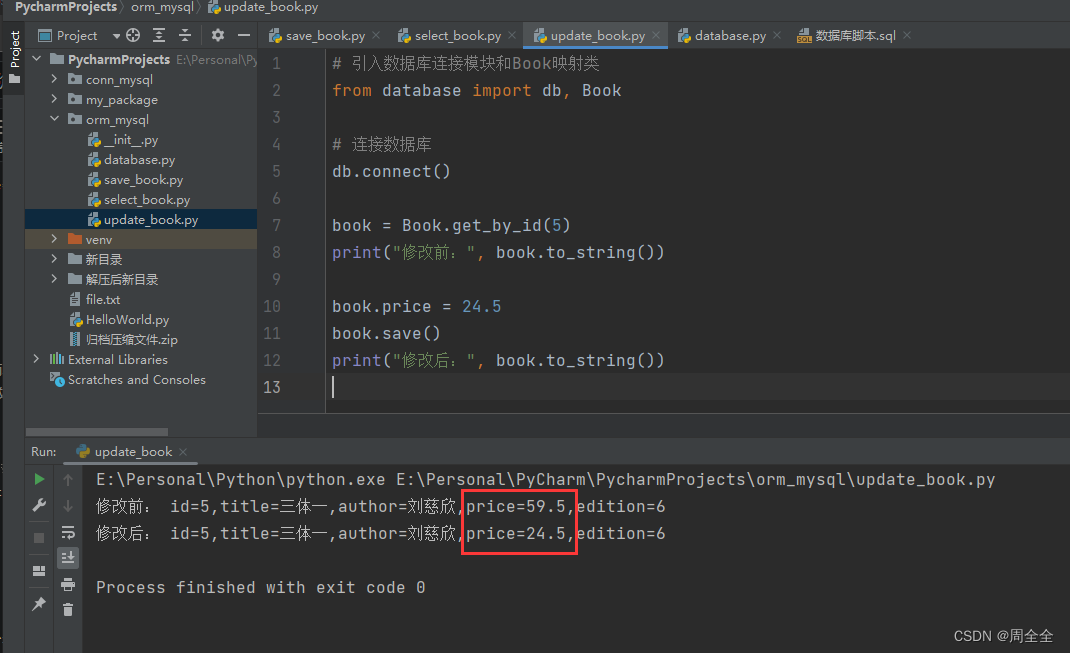
5.3 更新数据
使用Peewee更新数据也非常简单,可以直接修改模型实例的属性,并调用save()方法保存修改后的数据到数据库中。
# 引入数据库连接模块和Book映射类
from database import db, Book
# 连接数据库
db.connect()
book = Book.get_by_id(5)
print("修改前:", book.to_string())
book.price = 24.5
book.save()
print("修改后:", book.to_string())
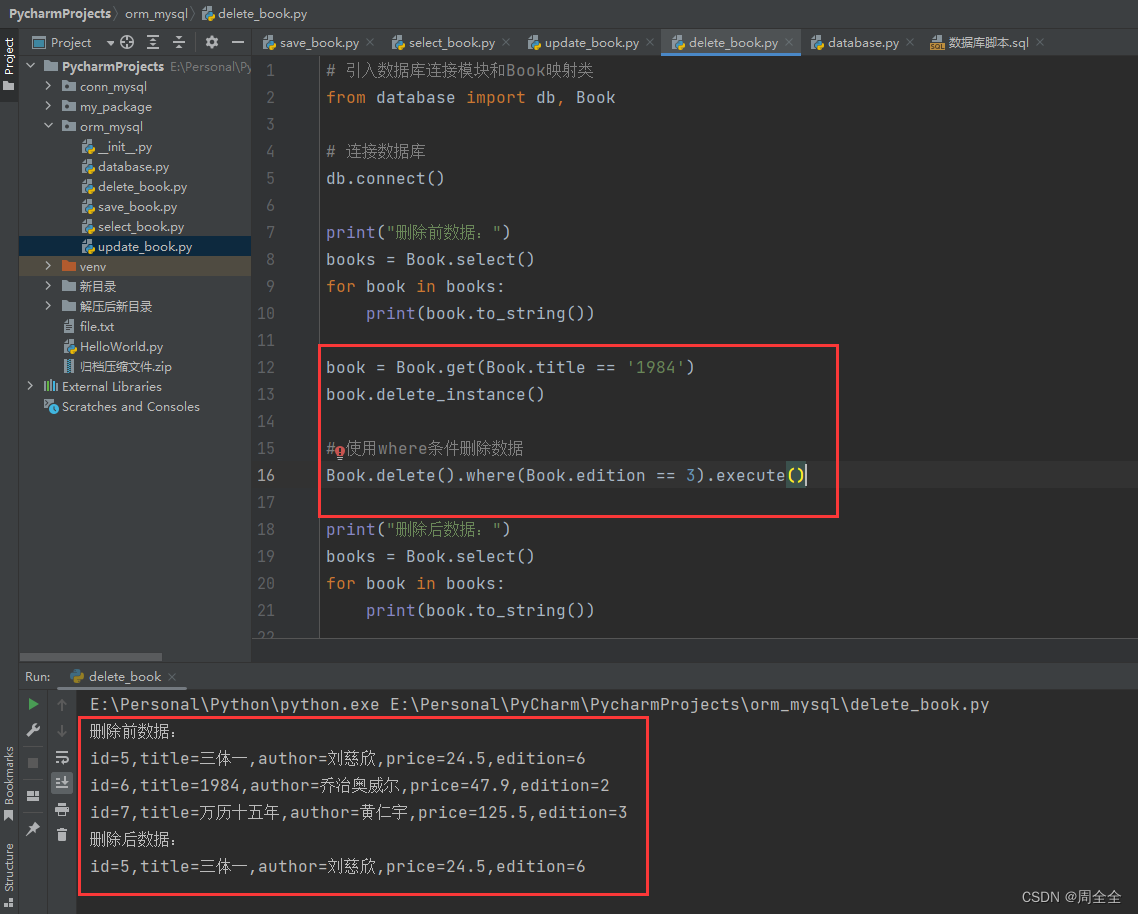
5.4 删除数据
使用Peewee删除数据可以通过调用模型实例
的delete_instance()方法或使用delete()方法进行删除操作。
# 引入数据库连接模块和Book映射类
from database import db, Book
# 连接数据库
db.connect()
print("删除前数据:")
books = Book.select()
for book in books:
print(book.to_string())
book = Book.get(Book.title == '1984')
book.delete_instance()
# 使用where条件删除数据
Book.delete().where(Book.edition == 3).execute()
print("删除后数据:")
books = Book.select()
for book in books:
print(book.to_string())
6. 聚合查询
# 引入数据库连接模块和Book映射类
from peewee import fn
from database import db, Book
# 连接数据库
db.connect()
'''
# 清空book表
delete from book;
# 执行聚合前先进行mysql的插入,插入数据用于聚合
INSERT INTO `py_conn_test`.`book`( `title`, `author`, `price`, `edition`) VALUES ( '三体二', '刘慈欣', 24.5, 6);
INSERT INTO `py_conn_test`.`book`( `title`, `author`, `price`, `edition`) VALUES ( '三体三', '刘慈欣', 24.5, 6);
INSERT INTO `py_conn_test`.`book`( `title`, `author`, `price`, `edition`) VALUES ( '1984', '乔治奥威尔', 47.9, 2);
INSERT INTO `py_conn_test`.`book`( `title`, `author`, `price`, `edition`) VALUES ( '动物农场', '乔治奥威尔', 47.9, 2);
INSERT INTO `py_conn_test`.`book`( `title`, `author`, `price`, `edition`) VALUES ( '伊豆舞女', '川端康成', 47.9, 2);
'''
# 聚合出数据库中书目大于等于2的作者信息
group_query = (Book
.select(Book.author, fn.Count(Book.id).alias('count'))
.group_by(Book.author)
.having(fn.Count(Book.id) >= 2))
print("查询SQL打印:", group_query)
# 打印聚合结果
for book in group_query:
print(f"标题: {book.author}, 计数: {book.count}")
查询结果:
查询SQL打印: SELECT `t1`.`author`, Count(`t1`.`id`) AS `count` FROM `book` AS `t1` GROUP BY `t1`.`author` HAVING (Count(`t1`.`id`) >= 2)
标题: 刘慈欣, 计数: 2
标题: 乔治奥威尔, 计数: 2
示例中展示了一些Peewee的基本用法和常见操作,但Peewee还有更多的功能和选项可供探索,例如事务管理、连接池、复杂查询等。可以参考Peewee的官方文档(http://docs.peewee-orm.com/)以了解更多详细信息和示例。
以上为使用Peewee对mysql的基础的应用,至于复杂的语句查询如果有人需要或者看的话再写吧