大数据企业开发基础流程
Linux命令
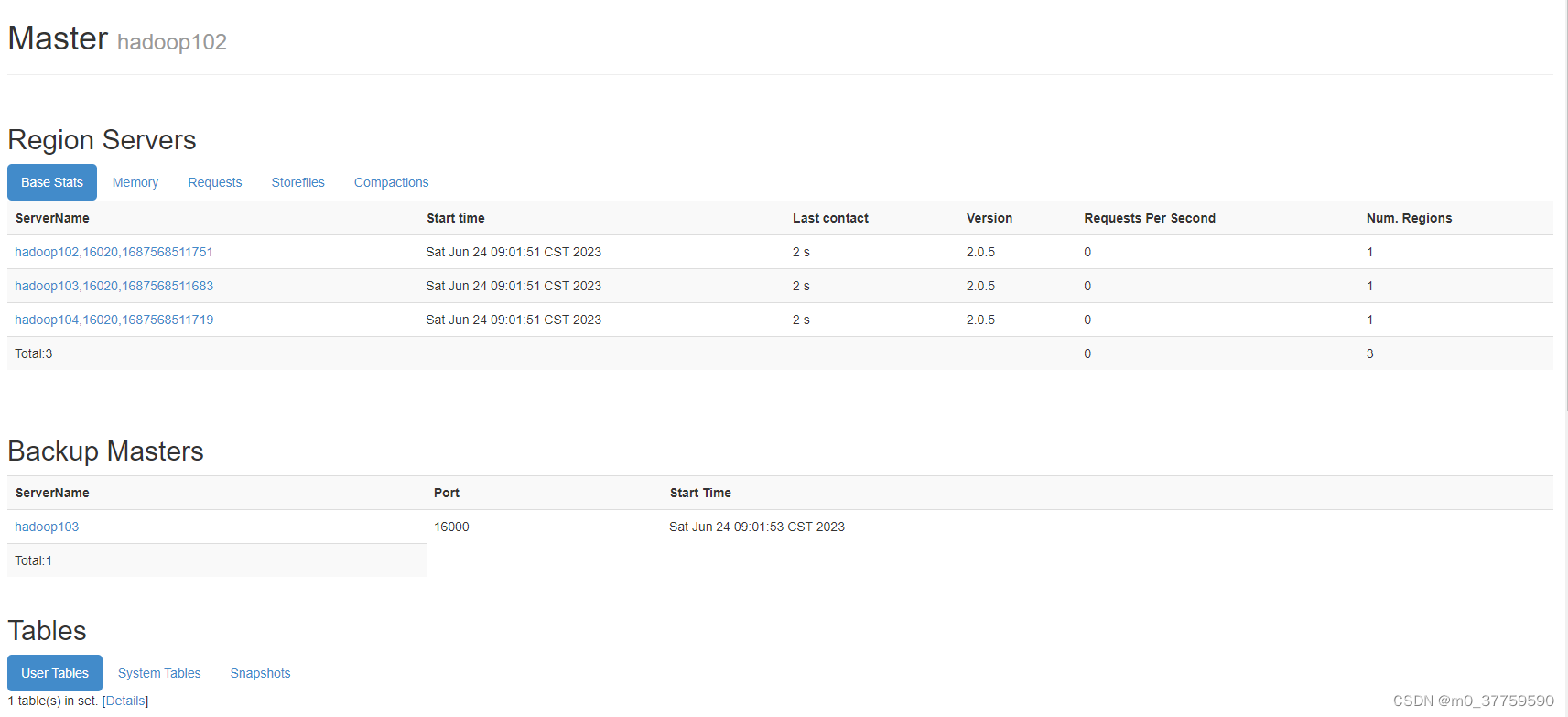
1 Hadoop(HDFS+Yarn)单机版环境搭建
- Hadoop 是一个开源的分布式计算框架,由 HDFS(Hadoop Distributed File System)和 YARN(Yet Another Resource Negotiator)两个核心组件组成。
- HDFS 是 Hadoop 的分布式文件系统,用于存储大规模数据集,并提供高容错性和高吞吐量。它将数据划分为多个块,并将这些块分布在集群中的多个计算节点上。HDFS 提供了数据冗余和自动故障恢复的机制,确保数据的可靠性和可用性。
- YARN 是 Hadoop 的集群资源管理系统,用于分配和管理集群中的计算资源。它负责接收来自用户提交的作业,并将作业的不同任务分配给集群中的不同计算节点执行。YARN 还负责监控和管理集群资源的使用情况,以便进行资源调度和优化。
- HDFS 和 YARN 是 Hadoop 的两个核心组件,它们密切合作以实现分布式计算和存储。HDFS 提供了可靠的数据存储,而 YARN 则负责管理计算资源并执行作业。用户可以将数据存储在 HDFS 上,并使用 YARN 提交和执行作业,从而实现分布式数据处理和分析。
- 总结起来,HDFS 提供了分布式存储,而 YARN 提供了分布式计算和资源管理。它们共同构成了 Hadoop 的分布式计算框架,为用户提供了处理大规模数据集的能力。
Hadoop基于Java开发的,因此需要有jdk环境
本文环境:
- hadoop == 3.1.0
- CentOS == 7.3
- jdk == 1.8
说明:上面环境,大家可以直接去对应官网上下载然后上传到linux即可,本文主要讲解概念,不再单独提供安装包
①配置java环境
# 创建tools目录,用于存放文件
mkdir /opt/tools
# 切换至tools目录,上传JDK安装包
# 创建server目录,用于存放JDK解压后的文件
mkdir /opt/server
# 解压JDK至server目录
tar -zvxf jdk-8u131-linux-x64.tar.gz -C /opt/server
# 配置环境变量
vim /etc/profile
# 文件末尾增加
export JAVA_HOME=/opt/server/jdk1.8.0_131
export PATH=${JAVA_HOME}/bin:$PATH
# 使配置生效
source /etc/profile
# 检查是否安装成功
java -version
注意:Hadoop 组件之间需要基于 SSH 进行通讯,配置免密登录后不需要每次都输入密码。
# 配置映射,配置 ip 地址和主机名映射
vim /etc/hosts
# 文件末尾增加
192.168.80.100 server
# 生成公钥私钥
ssh-keygen -t rsa
# 授权,进入 ~/.ssh 目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
②配置hadoop
- 下载并解压hadoop
访问http://archive.apache.org/dist/hadoop/core/hadoop-3.1.0/ 下载Hadoop(.tar.gz包)
# 切换至tools目录,上传Hadoop安装包
# 解压Hadoop至server目录
tar -zvxf hadoop-3.1.0.tar.gz -C /opt/server/
- 修改hadoop配置文件,配置java路径
# 进入/opt/server/hadoop-3.1.0/etc/hadoop 目录下,修改以下配置
# 修改hadoop-env.sh文件,设置JDK的安装路径
vim hadoop-env.sh
export JAVA_HOME=/opt/server/jdk1.8.0_131
修改core-site.xml文件,分别指定hdfs 协议文件系统的通信地址及hadoop 存储
临时文件的目录(此目录不需要手动创建)
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://server:8020</value>
</property>
<property>
<!--指定 hadoop 数据文件存储目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
</configuration>
- 修改副本数
修改hdfs-site.xml,指定 dfs 的副本系数
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 修改workers文件,配置所有从属节点
vim workers
# 配置所有从属节点的主机名或 IP 地址,由于是单机版本,所以指定本机即可:
server
③初始化并启动HDFS
# 关闭防火墙,不关闭防火墙可能导致无法访问 Hadoop 的 Web UI 界面
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld
# 禁止开机启动
sudo systemctl disable firewalld
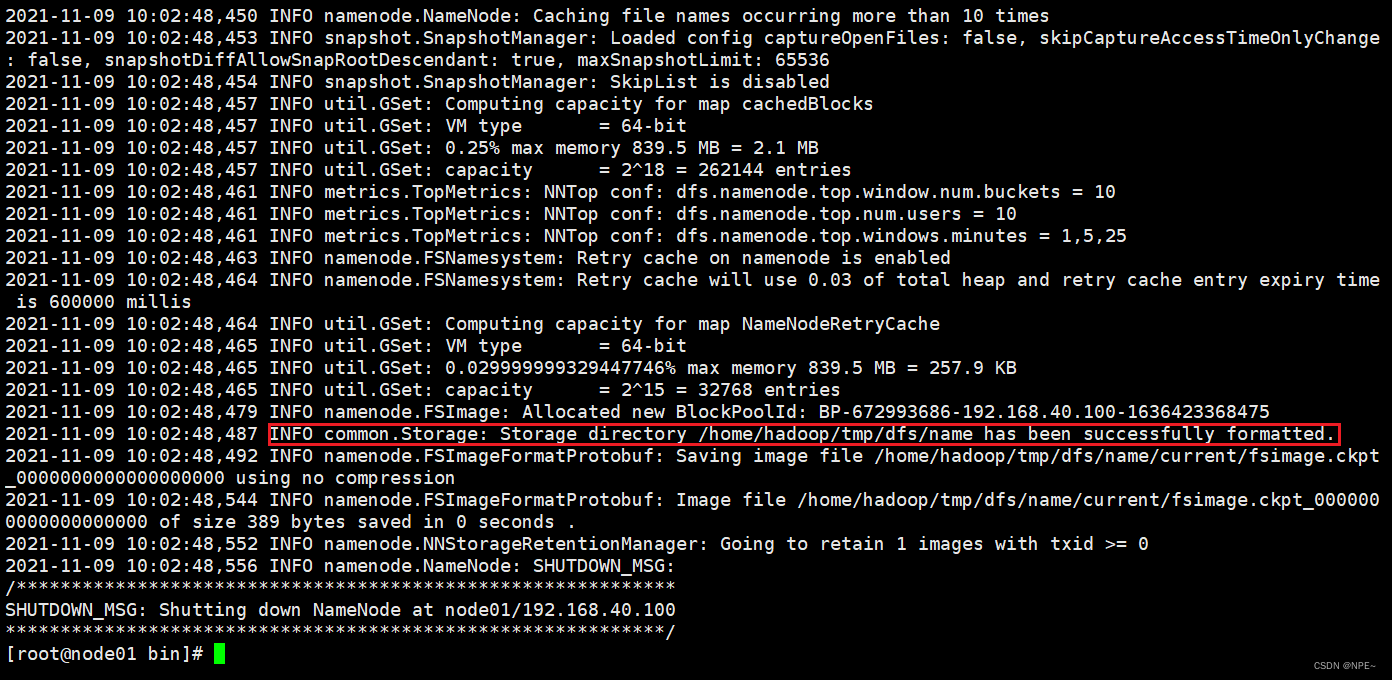
# 初始化,第一次启动 Hadoop 时需要进行初始化,进入 /opt/server/hadoop-3.1.0/bin目录下,执行以下命令:
cd /opt/server/hadoop-3.1.0/bin
./hdfs namenode -format
效果:
Hadoop 3中不允许使用root用户来一键启动集群,需要配置启动用户
cd /opt/server/hadoop-3.1.0/sbin/
# 编辑start-dfs.sh、stop-dfs.sh,在顶部加入以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
启动HDFS,进入/opt/server/hadoop-3.1.0/sbin/ 目录下,启动 HDFS:
cd /opt/server/hadoop-3.1.0/sbin/
./start-dfs.sh
验证是否启动:
- 执行 jps 查看 NameNode 和 DataNode 服务是否已经启动
[root@server bin]# jsp
41032 DataNode
41368 Jps
40862 NameNode
41246 SecondaryNameNode
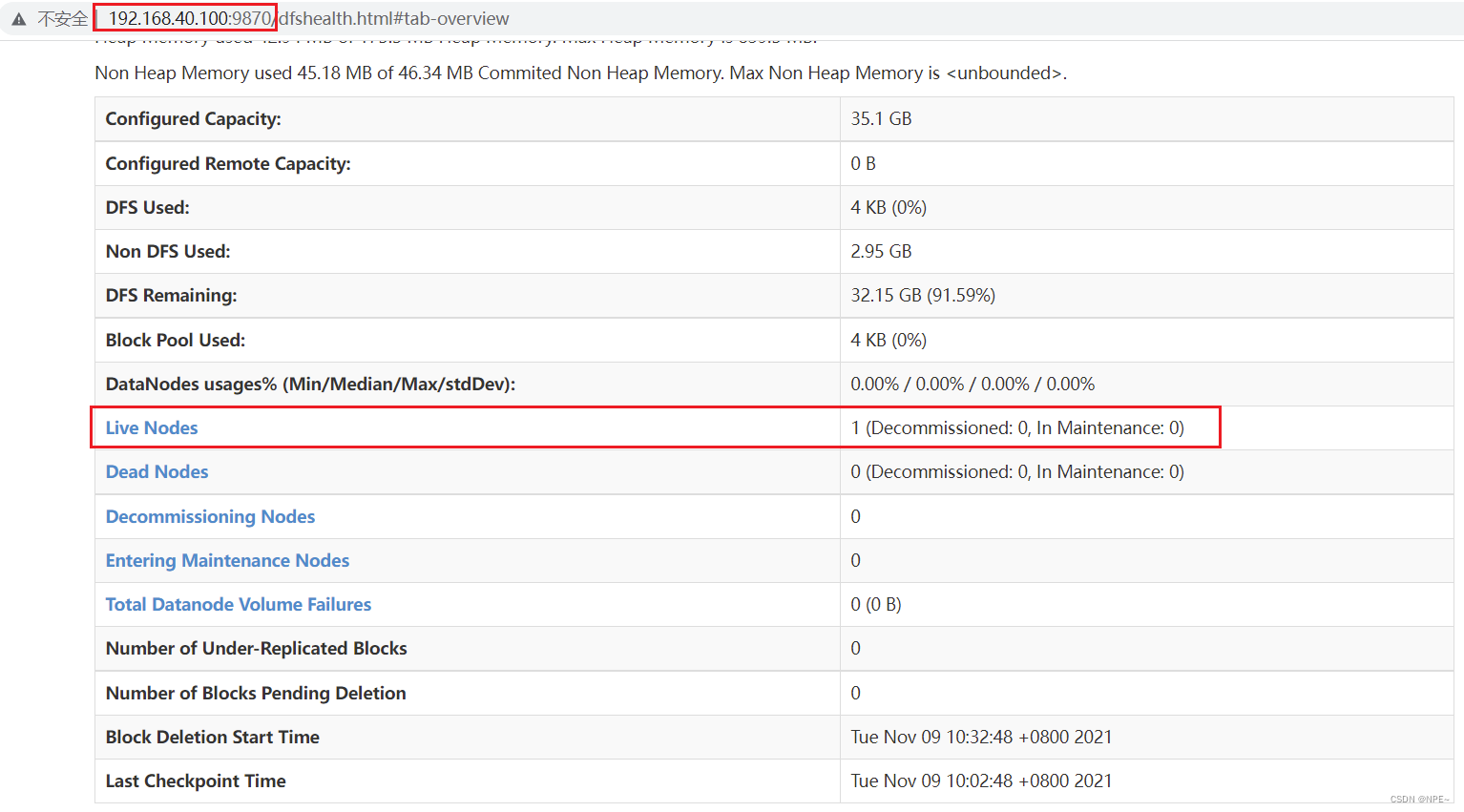
- 查看 Web UI 界面,端口为 9870:
# 可选:配置环境变量,方便以后直接启动
export HADOOP_HOME=/opt/server/hadoop-3.1.0
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
④Hadoop(YARN)环境搭建
- 进入/opt/server/hadoop-3.1.0/etc/hadoop 目录下,修改以下配置:
修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
修改yarn-site.xml文件,配置 NodeManager 上运行的附属服务
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可
以在
Yarn 上运行 MapRedvimuce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 启动服务
Hadoop 3中不允许使用root用户来一键启动集群,需要配置启动用户
# start-yarn.sh stop-yarn.sh在两个文件顶部添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
进入 ${HADOOP_HOME}/sbin/ 目录下,启动 YARN:
./start-yarn.sh
- 验证是否启动成功
- 执行 jps 命令查看 NodeManager 和 ResourceManager 服务是否已经启动
- 查看 Web UI 界面,端口为 8088
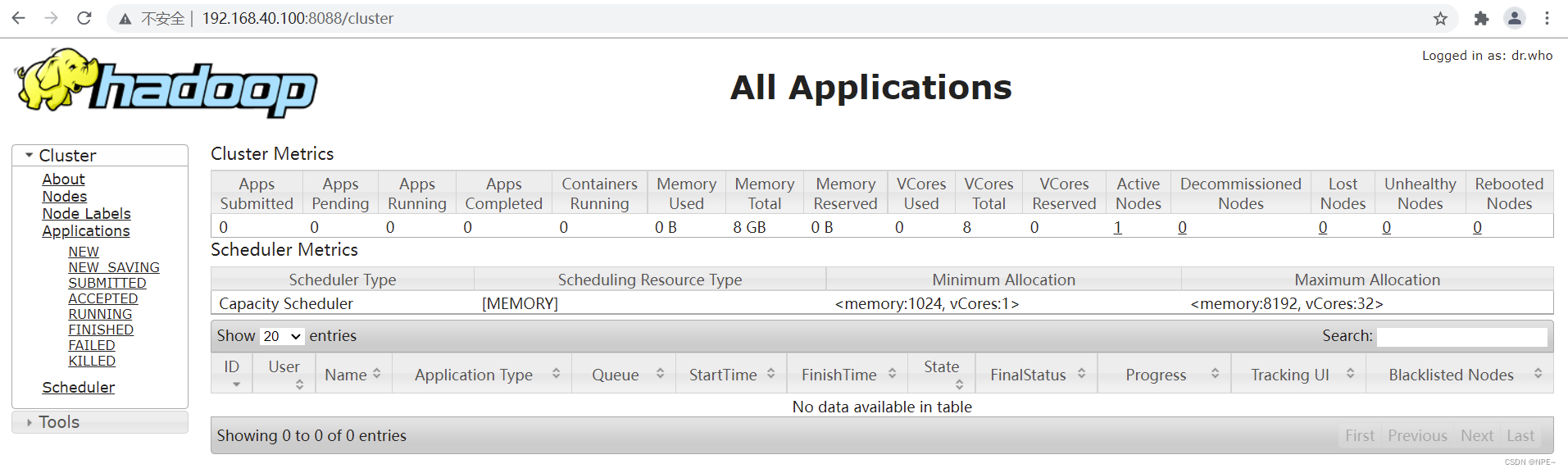
- Hadoop自带的hadoop-mapreduce-examples-x.jar中包含一些示例程序,位于
${HADOOP_HOME}/share/hadoop/mapreduce 目录。
# 进入 ${HADOOP_HOME}/bin/ 目录下,执行以下命令
hadoop jar /opt/server/hadoop-3.1.0/share/hadoop/mapreduce/hadoop-mapreduce-
examples-3.1.0.jar pi 2 10
查看结果:

2 Hive(基于hadoop的数仓)安装及使用
由于Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此必须要先保证服务器的基础环境正常,Hadoop环境正常运行,Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hive允许将元数据存储于本地或远程的外部数据库中,这种设置可以支持Hive的多会话生产环 境,在本案例中采用MySQL作为Hive的元数据存储库。
2.1 Hive安装
由于Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此必须要先保证服务器的基础环境正常,Hadoop环境正常运行,Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
# 创建服务端目录用于存放Hive安装文件
# 用于存放安装包
mkdir /opt/tools
# 用于存放解压后的文件
mkdir /opt/server
# 切换到/opt/tools目录,上传hive安装包
cd /opt/tools
共涉及到两个安装包,分别是apache-hive-3.1.2-bin.tar.gz与mysql-5.7.34-1.el7.x86_64.rpm-
bundle.tar
2.1.1 安装MySQL
- 卸载centos7自带的mariadb(mysql的一个分支)
# 查找
rpm -qa|grep mariadb
# mariadb-libs-5.5.52-1.el7.x86_64
# 卸载
rpm -e mariadb-libs-5.5.52-1.el7.x86_64 --nodeps
- 解压mysql
# 创建mysql安装包存放点
mkdir /opt/server/mysql
# 解压
tar xvf mysql-5.7.34-1.el7.x86_64.rpm-bundle.tar -C /opt/server/mysql/
- 执行安装
# 安装依赖
yum -y install libaio
yum -y install libncurses*
yum -y install perl perl-devel
# 切换到安装目录
cd /opt/server/mysql/
# 安装
rpm -ivh mysql-community-common-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.34-1.el7.x86_64.rpm
- 启动mysql
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码
cat /var/log/mysqld.log | grep password

- 修改初始密码
# 登录mysql
mysql -u root -p
Enter password: #输入在日志中生成的临时密码
# 更新root密码 设置为root
set global validate_password_policy=0;
set global validate_password_length=1;
set password=password('root');
- 运行MySQL远程连接
grant all privileges on *.* to 'root' @'%' identified by 'root';
# 刷新
flush privileges;
- 设置mysql服务开机自启
#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files | grep mysqld
2.1.2 Hive的安装配置
- 解压安装包
# 切换到安装包目录
cd /opt/tools
# 解压到/root/server目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/server/
- 添加mysql驱动到hive安装目录的lib目录下
根据自己mysql版本选择对应驱动即可,同时观察hive/lib目录下是否有驱动,如果没有才添加
# 上传mysql-connector-java-5.1.38.jar
cd /opt/server/apache-hive-3.1.2-bin/lib
- 配置hive环境变量
cd /opt/server/apache-hive-3.1.2-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 加入以下内容
HADOOP_HOME=/opt/server/hadoop-3.1.0
- 新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 存储元数据mysql相关配置 /etc/hosts -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://server:3306/hive?
createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&chara
cterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
注意:
- 初始化元数据库,当使用的 hive 是 1.x 版本时,可以不进行初始化操作,Hive 会在第一次启动的时候会自动进行初始化,但不会生成所有的元数据信息表,只会初始化必要的一部分,在之后的使用中用到其余表时会自动创建;
- 当使用的 hive 是 2以上版本时,必须手动初始化元数据库,初始化命令:
cd /opt/server/apache-hive-3.1.2-bin/bin ./schematool -dbType mysql -initSchema
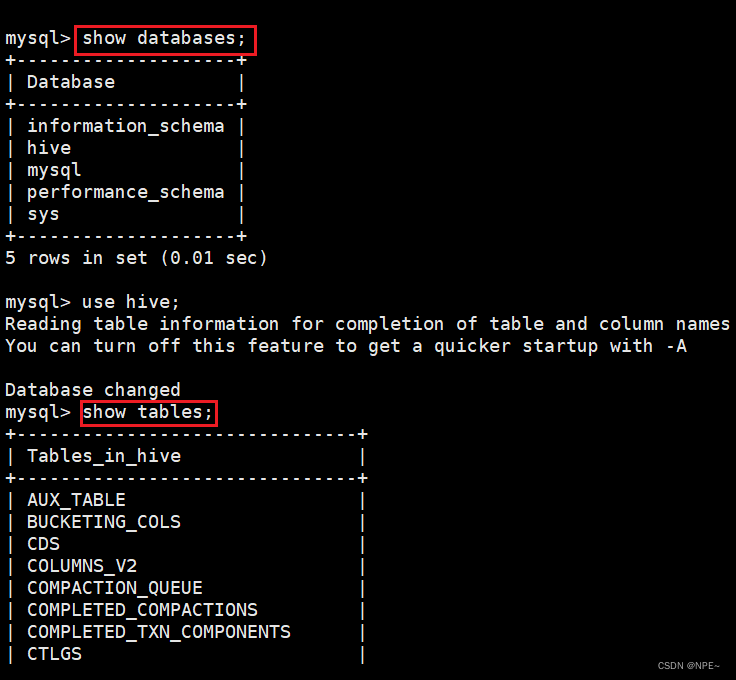
初始化成功后会在MySQL中创建74张表:
- 启动Hive
# 为方便后续使用可以将hive命令添加到环境变量中
vim /etc/profile
export HIVE_HOME=/opt/server/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
# 使得环境变量生效
source /etc/profile
# 启动hive
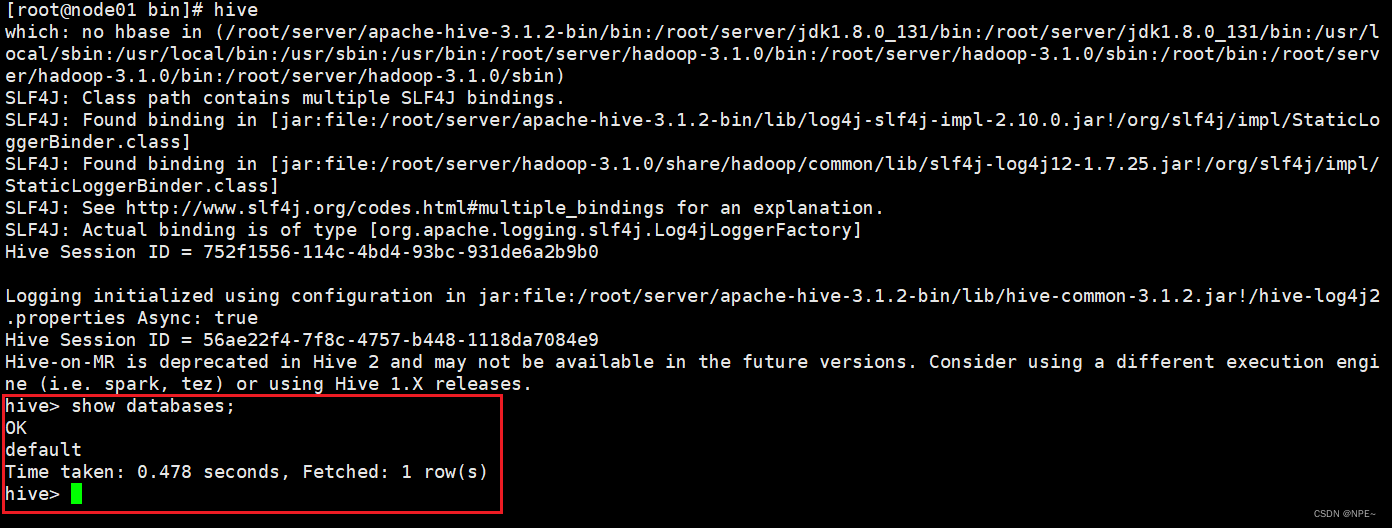
hive
输入show databases命令可以看到默认的数据库,则代表搭建成功
- Hive-Cli的一些简单命令
直接使用 Hive 命令,不加任何参数,即可进入交互式命令行。
- 执行SQL命令
hive -e 'select * from emp';
- 执行本地sql脚本(用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。)
# 本地文件系统
hive -f /usr/file/simple.sql;
# HDFS文件系统
hive -f hdfs://node01:8020/tmp/simple.sql;
- 简单使用
在hive中创建、切换数据库,创建表并执行插入数据操作,最后查询是否插入成功。
# 连接hive
hive
# 数据库操作
create database test;--创建数据库
show databases;--列出所有数据库
use test;--切换数据库
# 表操作
-- 建表
create table t_student(id int,name varchar(255));
-- 插入一条数据
insert into table t_student values(1,"potter");
-- 查询表数据
select * from t_student;
在执行插入数据的时候,发现插入速度极慢,sql执行时间很长,花费了26秒,并且显示了MapReduce程序的进度
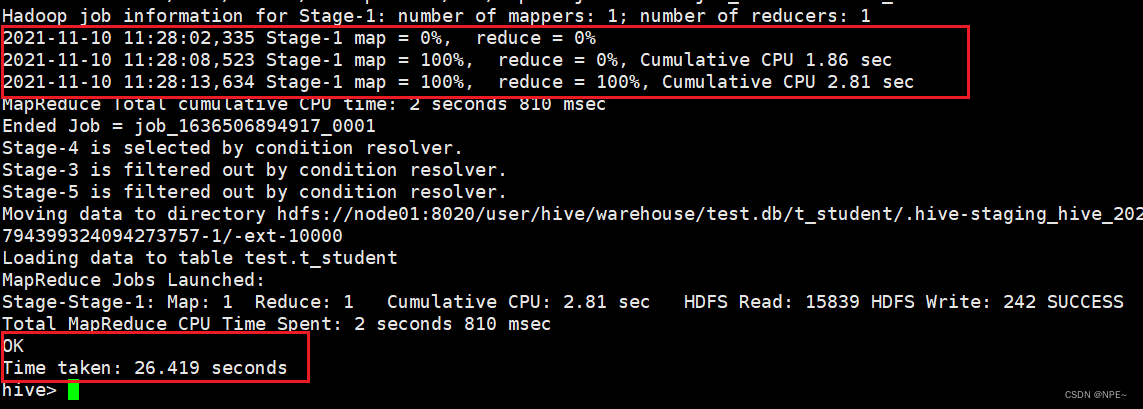
查看yarn及hdfs
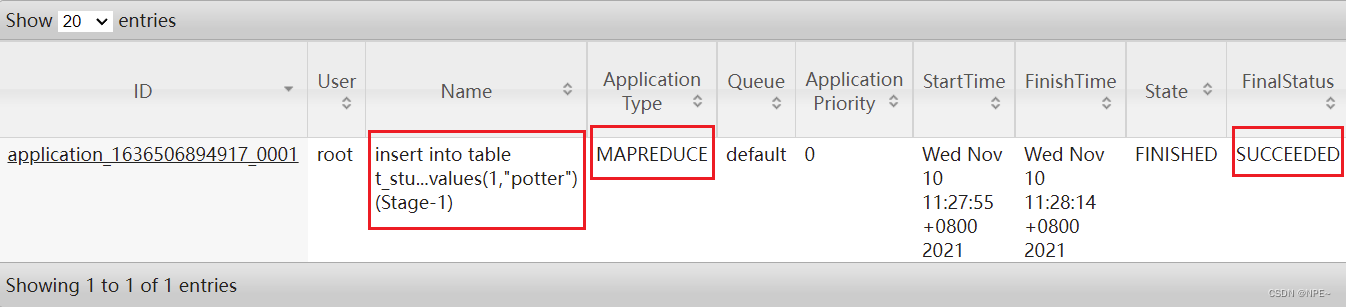
- 登录Hadoop YARN观察是否有MapReduce程序执行,地址:http://192.168.40.100:8088,需要根据自己的服务器IP进行更换
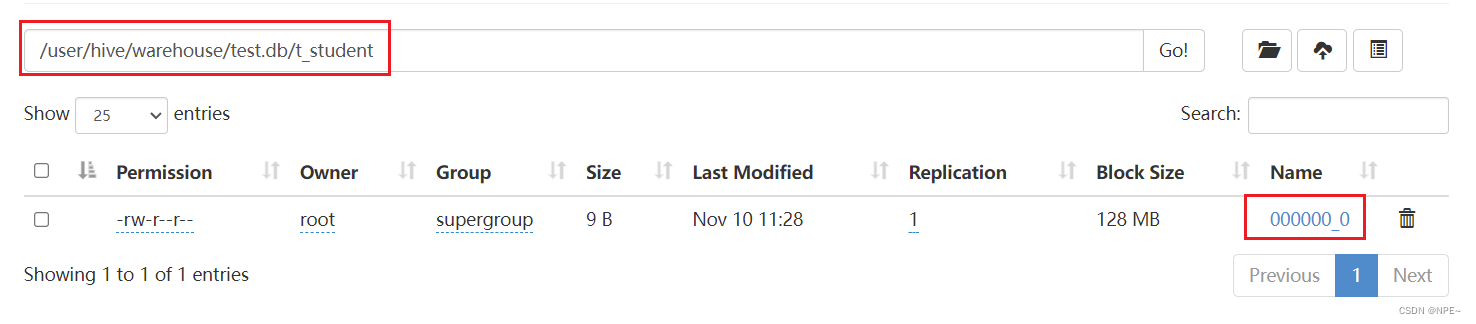
- 发现运行的任务名称就是所执行的SQL语句,任务的类型为MapReduce,最终状态为SUCCEEDED。登录Hadoop HDFS浏览文件系统,根据Hive的数据模型,表的数据最终是存储在HDFS和表对应的文件夹下的。
地址:http://192.168.40.100:9870/,需要根据自己的服务器IP进行更换
小总结:
- Hive SQL语法和标准SQL很类似,使得学习成本降低不少。
- Hive底层是通过MapReduce执行的数据插入动作,所以速度慢。
- 如果大数据集这么一条一条插入的话是非常不现实的,成本极高。
- Hive应该具有自己特有的数据插入表方式,结构化文件映射成为表。
2. 2 Hive常用操作(基本语法部分,暂时省略)
可以参考官网,此部分暂时省略
- Hive:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
3 Flume日志采集工具
3.1 概述
3.1.1 介绍及运行机制
①介绍:
- Flume是一个高可用,高可靠的分布式的海量日志采集、聚合和传输的软件。
- Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
- Flume支持定制各类数据发送方,用于收集各类型数据;同时,Flume支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景
②运行机制:
Flume系统中核心的角色是
agent,agent本身是一个Java进程,一般运行在日志收集节点
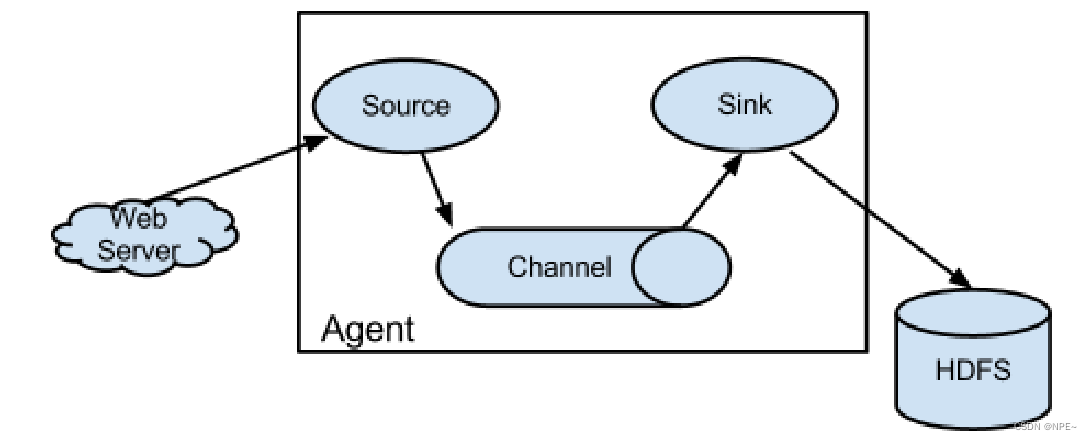
每一个agent相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据;
- Sink:下沉地,采集数据的传送目的地,用于往下一级agent传递数据或者往最终存储系统传递数据;
- Channel:agent内部的数据传输通道,用于从source将数据传递到sink;
- 在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
- 一个完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日记记录。
3.2.2 常见的采集结构
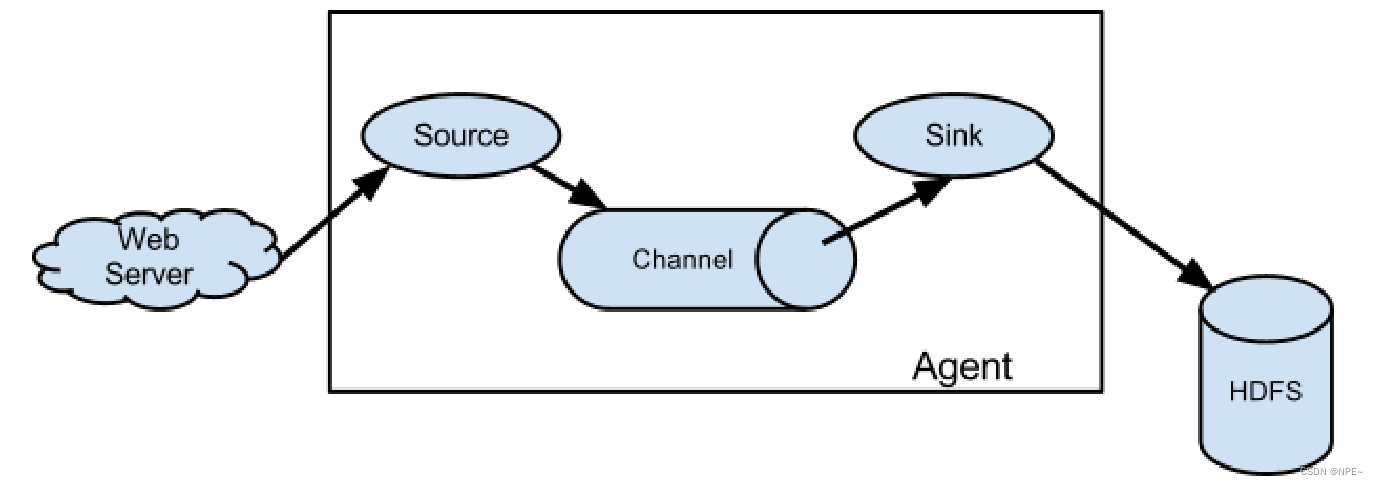
- 简单结构
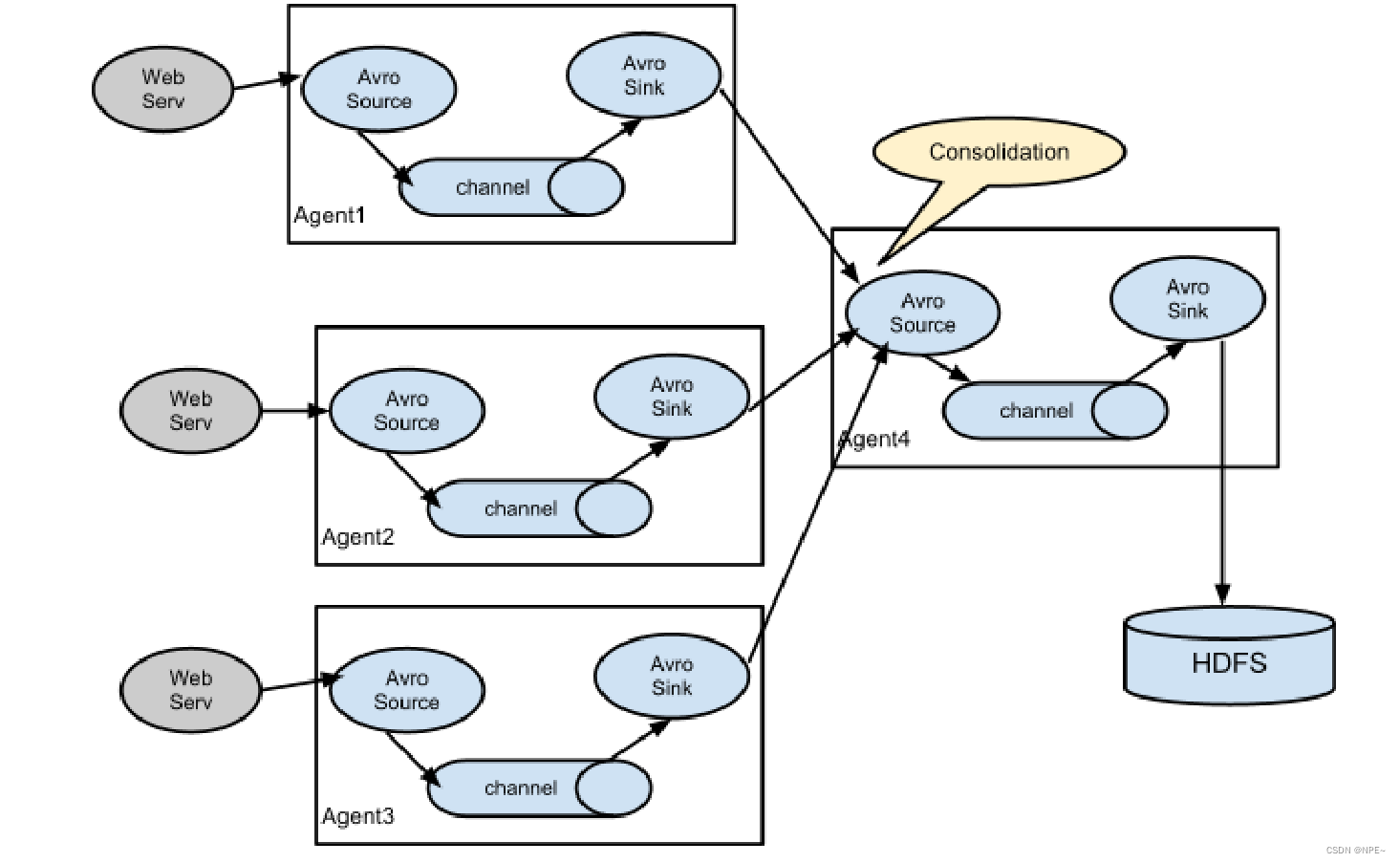
- 多级agent之间串联

3.2.3 安装部署flume
- 上传安装包到linux对应目录
- 解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/server
- 进入flume的目录,修改conf下的flume-env.sh,配置JAVA_HOME
cd /opt/server/apache-flume-1.9.0-bin/conf
# 先复制一份flume-env.sh.template文件
cp flume-env.sh.template flume-env.sh
# 修改
vim flume-env.sh
export JAVA_HOME=/opt/server/jdk1.8.0_131
3.2 使用(采集Nginx日志到HDFS)
3.2.1 安装Nginx
# 安装nginx
yum install epel-release
yum update
yum -y install nginx
#启动nginx
systemctl start nginx #开启nginx服务
systemctl stop nginx #停止nginx服务
systemctl restart nginx #重启nginx服务
网站日志文件位置:
cd /var/log/nginx
3.2.2 编写配置文件并启动Flume
- 编写配置文件
将 lib 文件夹下的 guava-11.0.2.jar 删除以兼容 Hadoop 3.1.0 flume1.9
cp /opt/server/hadoop-3.1.0/share/hadoop/common/*.jar /opt/server/apache-flume-
1.9.0-bin/lib
cp /opt/server/hadoop-3.1.0/share/hadoop/common/lib/*.jar /opt/server/apache-
flume-1.9.0-bin/lib
cp /opt/server/hadoop-3.1.0/share/hadoop/hdfs/*.jar /opt/server/apache-flume-
1.9.0-bin/lib
- 创建配置文件,taildir-hdfs.conf
监控 /var/log/nginx 目录下的日志文件
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.filegroups = f1
# 此处支持正则
a3.sources.r3.filegroups.f1 = /var/log/nginx/access.log
# 用于记录文件读取的位置信息
a3.sources.r3.positionFile = /opt/server/apache-flume-1.9.0-bin/tail_dir.json
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://server:8020/user/tailDir
a3.sinks.k3.hdfs.fileType = DataStream
# 设置每个文件的滚动大小大概是 128M,默认值:1024,当临时文件达到该大小(单位:bytes)时,滚动成目标文件。如果设置成0,则表示不根据临时文件大小来滚动文件。
a3.sinks.k3.hdfs.rollSize = 134217700
# 默认值:10,当events数据达到该数量时候,将临时文件滚动成目标文件,如果设置成0,则表示不根据events数据来滚动文件。
a3.sinks.k3.hdfs.rollCount = 0
# 不随时间滚动,默认为30秒
a3.sinks.k3.hdfs.rollInterval = 10
# flume检测到hdfs在复制块时会自动滚动文件,导致roll参数不生效,要将该参数设置为1;否则HFDS文件所在块的复制会引起文件滚动
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
- 启动flume
bin/flume-ng agent -c ./conf -f ./conf/taildir-hdfs.conf -n a3 -
Dflume.root.logger=INFO,console
4 Sqoop迁移工具(关系型数据库-hive数仓)
4.1 介绍及安装
①介绍
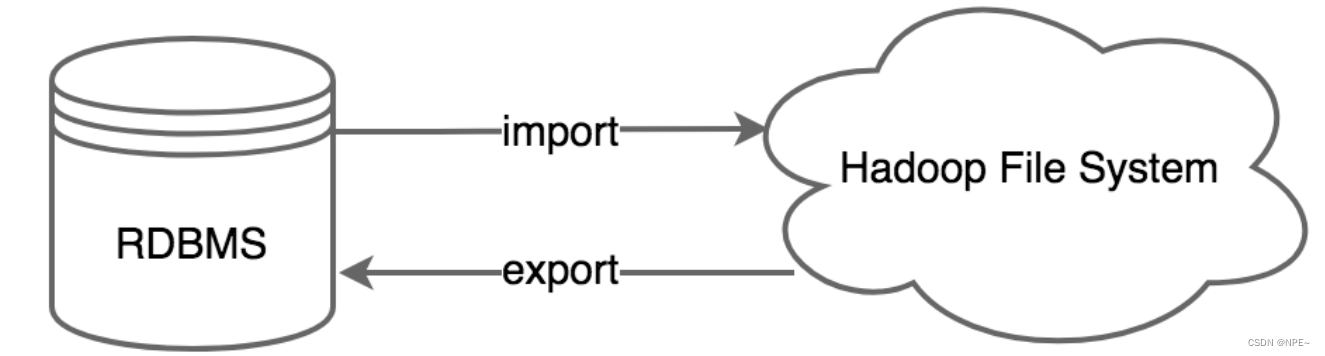
sqoop是apache旗下,用于关系型数据库和hadoop之间传输数据的工具,sqoop可以用在离线分析中,将保存在mysql的业务数据传输到hive数仓,数仓分析完得到结果,再通过sqoop传输到mysql,最后通过web+echart来进行图表展示,更加直观的展示数据指标。
- 如下图所示,sqoop中有导入和导出的概念,参照物都是hadoop文件系统,其中关系型数据库可以是mysql、oracle和db2,hadoop文件系统中可以是hdfs、hive和hbase等。执行sqoop导入和导出,其本质都是转化成了mr任务去执行。
②安装
安装sqoop的前提是已经具备java和hadoop的环境。
- 上传sqoop安装包至服务端 sqoop1.xxx sqoop1.99xx
- 解压
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/server/
- 编辑配置文件
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
# 加入以下内容
export HADOOP_COMMON_HOME=/opt/server/hadoop-3.1.0
export HADOOP_MAPRED_HOME=/opt/server/hadoop-3.1.0
export HIVE_HOME=/opt/server/apache-hive-3.1.2-bin
- 加入MySQL的jdbc驱动包
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/lib
# mysql-connector-java-5.1.38.jar
4.2 导入数据
# 用于将数据导入HDFS
sqoop import (generic-args) (import-args)
在mysql中创建数据库mydb,执行mydb.sql脚本创建表。
4.2.1 全量导入
①全量导入MySQL数据到HDFS
# 下面的命令用于从MySQL数据库服务器中的emp表导入HDFS:
# 其中--target-dir可以用来指定导出数据存放至HDFS的目录;
./sqoop import \
--connect jdbc:mysql://192.168.80.100:3306/mydb \
--username root \
--password root \
--delete-target-dir \
--target-dir /sqoopresult \
--table emp --m 1
查看导入的数据:
cd /root/server/hadoop-3.1.0/bin
hadoop dfs -cat /sqoopresult/part-m-00000
②使用where导入数据子集
# --where参数可以指定从关系数据库导入数据时的查询条件,根据条件将数据库结果抽取到HDFS中。
bin/sqoop import \
--connect jdbc:mysql://node-1:3306/sqoopdb \
--username root \
--password hadoop \
--where "city ='sec-bad'" \
--target-dir /wherequery \
--table emp_add
--m 1
③使用select导入数据子集
bin/sqoop import \
--connect jdbc:mysql://node-1:3306/userdb \
--username root \
--password hadoop \
--target-dir /wherequery12 \
--query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\t' \
--m 2
–split-by id通常配合-m参数配合使用,用于指定根据哪个字段进行划分并启动多少个maptask,上述语句使用时有以下注意事项:
- 使用query sql语句时不能使用参数 --table
- 语句中必须有where条件
- where条件后面必须有$CONDITIONS 字符串
- 查询字符串必须使用单引号
4.2.2 增量导入
在实际工作当中,数据的导入往往只需要导入新增数据即,sqoop支持根据某些字段进行增量数据导入。
- –check-column (col):用于指定增量导入数据时所依赖的列,一般指定自增字段或时间戳,同时支持指定多列。
- –incremental (mode):用于指定根据何种模式导入增量数据:
- append:配合–last-value参数使用,对大于last-value的值进行增量导入
- lastmodified:配合–last-value参数使用,追加last-value指定的日期之后的记录
- –last-value (value):指定自从上次导入数据后列的最大值,此值在Sqoop作业中会自动进行更新
①Append模式增量导入
增量导入empno为7934后的数据:
./sqoop import \
--connect jdbc:mysql://192.168.80.100:3306/mydb \
--username root --password root \
--table emp --m 1 \
--target-dir /appendresult \
--incremental append \
--check-column empno \
--last-value 7934
②LastModified模式增量导入
创建示例表:
create table test(
id int,
name varchar(20),
last_mod timestamp default current_timestamp on update current_timestamp
);
-- last_mod为时间戳类型,并设置为在数据更新时都会记录当前时间,同时默认值为当前时间
使用incremental的方式进行增量的导入:
bin/sqoop import \
--connect jdbc:mysql://node-1:3306/userdb \
--username root \
--password hadoop \
--table customertest \
--target-dir /lastmodifiedresult \
--check-column last_mod \
--incremental lastmodified \
--last-value "2021-09-28 18:55:12" \
--m 1 \
--append
注意:采用lastmodified模式去处理增量时,会将大于等于last-value值的数据当做增量插入
- 使用lastmodified模式进行增量导入时,需要指定增量数据是以append模式(附加)还是merge-key(合并)模式导入
bin/sqoop import \
--connect jdbc:mysql://node-1:3306/userdb \
--username root \
--password hadoop \
--table customertest \
--target-dir /lastmodifiedresult \
--check-column last_mod \
--incremental lastmodified \
--last-value "2021-09-28 18:55:12" \
--m 1 \
--merge-key id
merge-key,如果之前旧的数据发生了变化,则不会再以追加形式导入,而是会以更新的形式导入
4.3 导出数据
- 将数据从Hadoop生态体系导出到数据库时,数据库表必须已经创建。
- 默认的导出操作是使用INSERT语句将数据插入到目标表中,也可以指定为更新模式,sqoop则会使用update语句更新目标数据。
4.3.1 默认方式导出
因为默认是使用insert语句导出到目标表,如果数据库中的表具有约束条件,例如主键不能重复,如果违反了违反了约束条件,则会导致导出失败。
- 导出时,可以指定全部字段或部分字段导出到目标表。
./sqoop export \
--connect jdbc:mysql://server:3306/userdb \
--username root \
--password root \
--table employee \
--export-dir /emp/emp_data
# 将HDFS/emp/emp_data文件中的数据导出到mysql的employee表中
导出时,还可以指定以下参数;
- –input-fields-terminated-by ‘\t’:指定HDFS文件的分隔符
- –columns:如果不使用 column 参数,就要默认Hive 表中的字段顺序和个数和MySQL表保持一致,如果字段顺序或个数不一致可以加 columns 参数进行导出控制,没有被包含在–columns后面列名或字段要么具备默认值,要么就允许插入空值。否则数据库会拒绝接受sqoop导出的数据,导致Sqoop作业
失败、 - –export-dir:导出目录,在执行导出的时候,必须指定此参数
4.3.2 updateonly模式
- – update-key,更新标识,即指定根据某个字段进行更新,例如id,可以指定多个更新标识的字段,多
个字段之间用逗号分隔。 - – updatemod,指定updateonly(默认模式),指仅仅更新已存在的数据记录,不会插入新纪录。
bin/sqoop export \
--connect jdbc:mysql://node-1:3306/userdb \
--username root --password hadoop \
--table updateonly \
--export-dir /updateonly_2/ \
--update-key id \
--update-mode updateonly
# 根据id对已经存在的数据进行更新操作,新增的数据会被忽略
4.3.3 allowinsert模式
–updatemod,指定allowinsert,更新已存在的数据记录,同时插入新纪录。实质上是一个insert &update的操作。
bin/sqoop export \
--connect jdbc:mysql://node-1:3306/userdb \
--username root --password hadoop \
--table allowinsert \
--export-dir /allowinsert_2/ \
--update-key id \
--update-mode allowinsert
# 根据id对已经存在的数据进行更新操作,同时导出新增的数据
4.4 Sqoop Job
- 创建作业(–create):
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业。下面的命令用于创建一个从DB数据库的emp表导入到HDFS文件的作业。
./sqoop job --create job_test1 \
-- import \
--connect jdbc:mysql://192.168.80.100:3306/mydb \
--username root \
--password root \
--target-dir /sqoopresult333 \
--table emp --m 1
# import前要有空格
- 验证job
–list参数是用来查看保存的作业:
bin/sqoop job --list
bin/sqoop job --delete job_test6
- 执行job
–exec选项用于执行保存的作业
bin/sqoop job --exec myjob
5 Azkaban调度器

Azkaban是由linkedin(领英)公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
5.1 介绍及安装
5.1.1 介绍
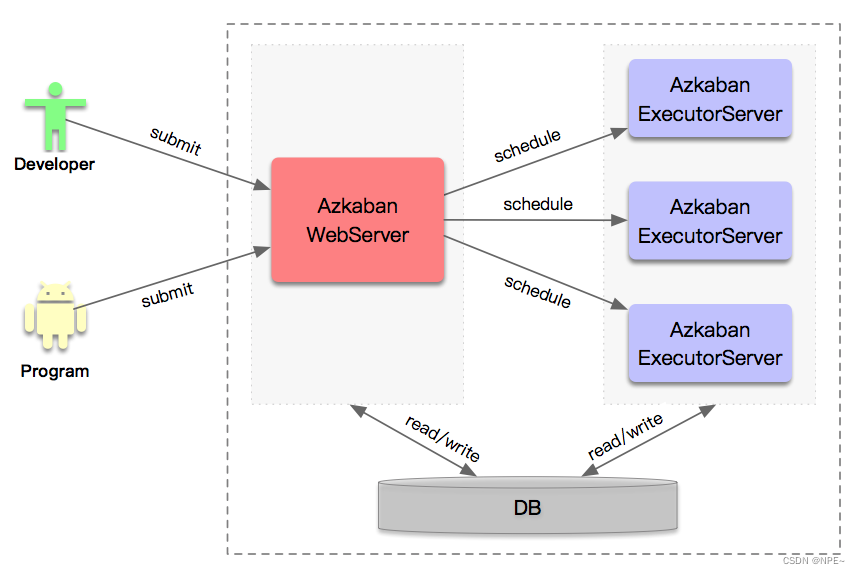
- mysql服务器: 存储元数据,如项目名称、项目描述、项目权限、任务状态、SLA规则等
- AzkabanWebServer:对外提供web服务,使用户可以通过web页面管理。职责包括项目管理、权限授权、任务调度、监控executor。
- AzkabanExecutorServer:负责具体的工作流的提交、执行。
5.1.2 安装
# 上传安装包到指定目录后解压
tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C /opt/server
# 修改conf目录中的azkaban.properties文件,修改时区为Asia/Shanghai
vim conf/azkaban.properties
default.timezone.id=Asia/Shanghai
修改plugins/jobtypes目录中的commonprivate.properties文件,关闭内存检查,azkaban默认需要3G的内存,剩余内存不足则会报异常。
vim plugins/jobtypes/commonprivate.properties
# 添加
memCheck.enabled=false
启动验证,启动/关闭必须进到azkaban-solo-server-0.1.0-SNAPSHOT/目录下
bin/start-solo.sh
AzkabanSingleServer(对于Azkaban solo‐server模式,Exec Server和Web Server在同一个进程中)

登录web页面,通过浏览器访问控制台,http://server:8081, 默认用户名密码azkaban
5.2 使用
5.2.1 执行单任务
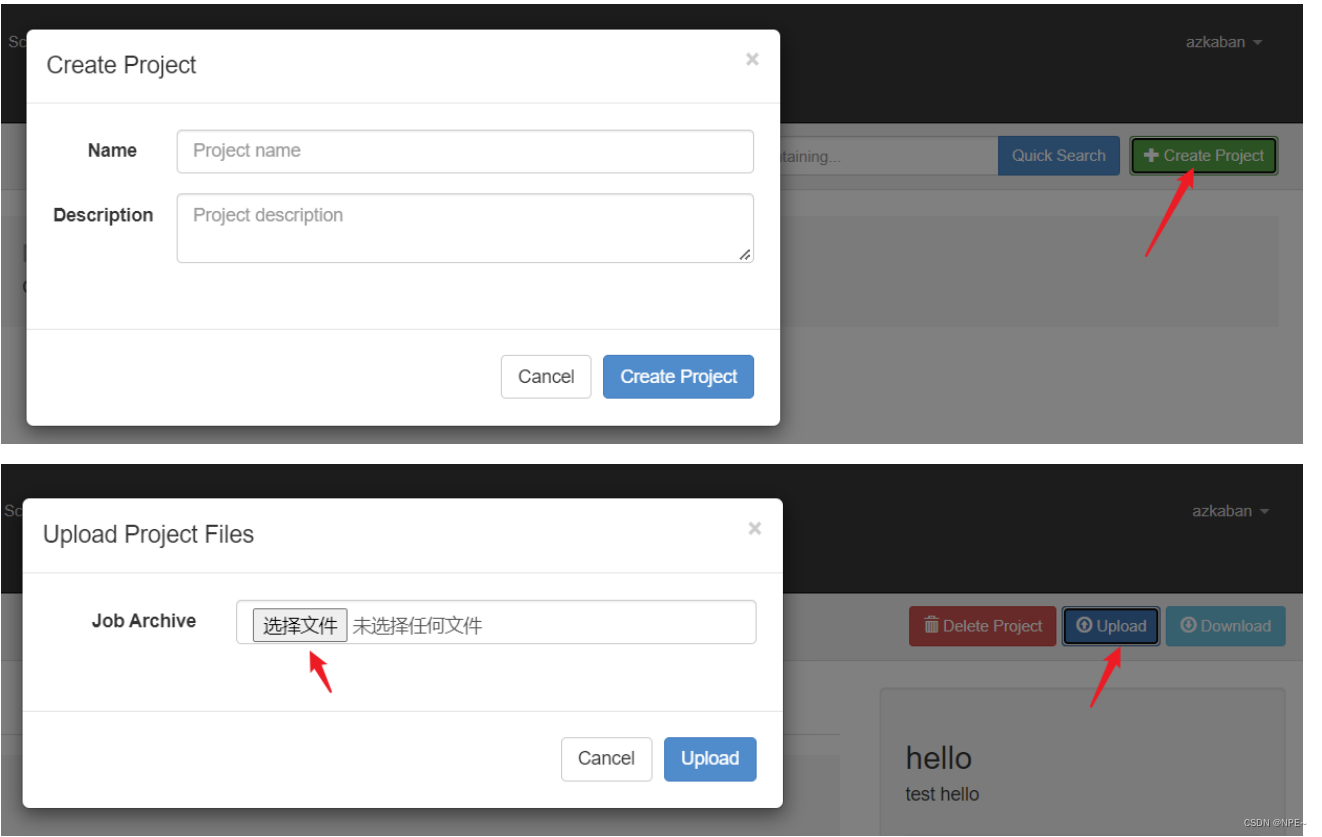
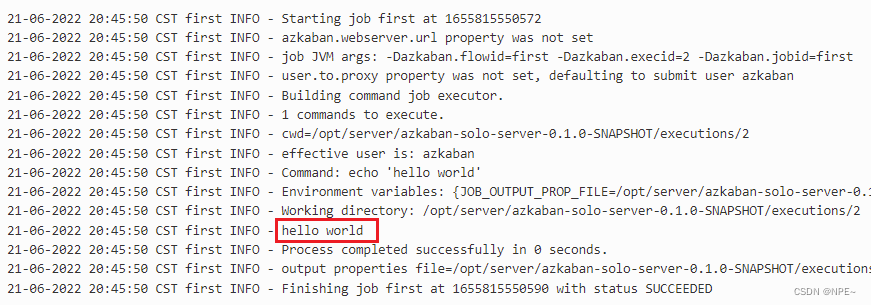
创建 job 描述文件,命名为first.job,加入以下内容:
#first.job
type=command
command=echo 'hello world'
将 job 资源文件打包成 zip 文件,Azkaban 上传的工作流文件只支持 zip 文件。zip 应包含 .job 运行作业所需的文件,作业名称在项目中必须是唯一的。
注意:zip包中不应该包含层级目录等,应该只有一个或多个xx.job文件
- 通过 azkaban 的 web 管理平台创建 project 并上传 job 的 zip 包
- 点击执行工作流
- 查看执行结果
- 点击右侧的Details可以查看执行结果


5.2.2 执行多任务
- 创建有依赖关系的多个任务,首先创建start.job
#start.job
type=command
command=touch /opt/server/web.log
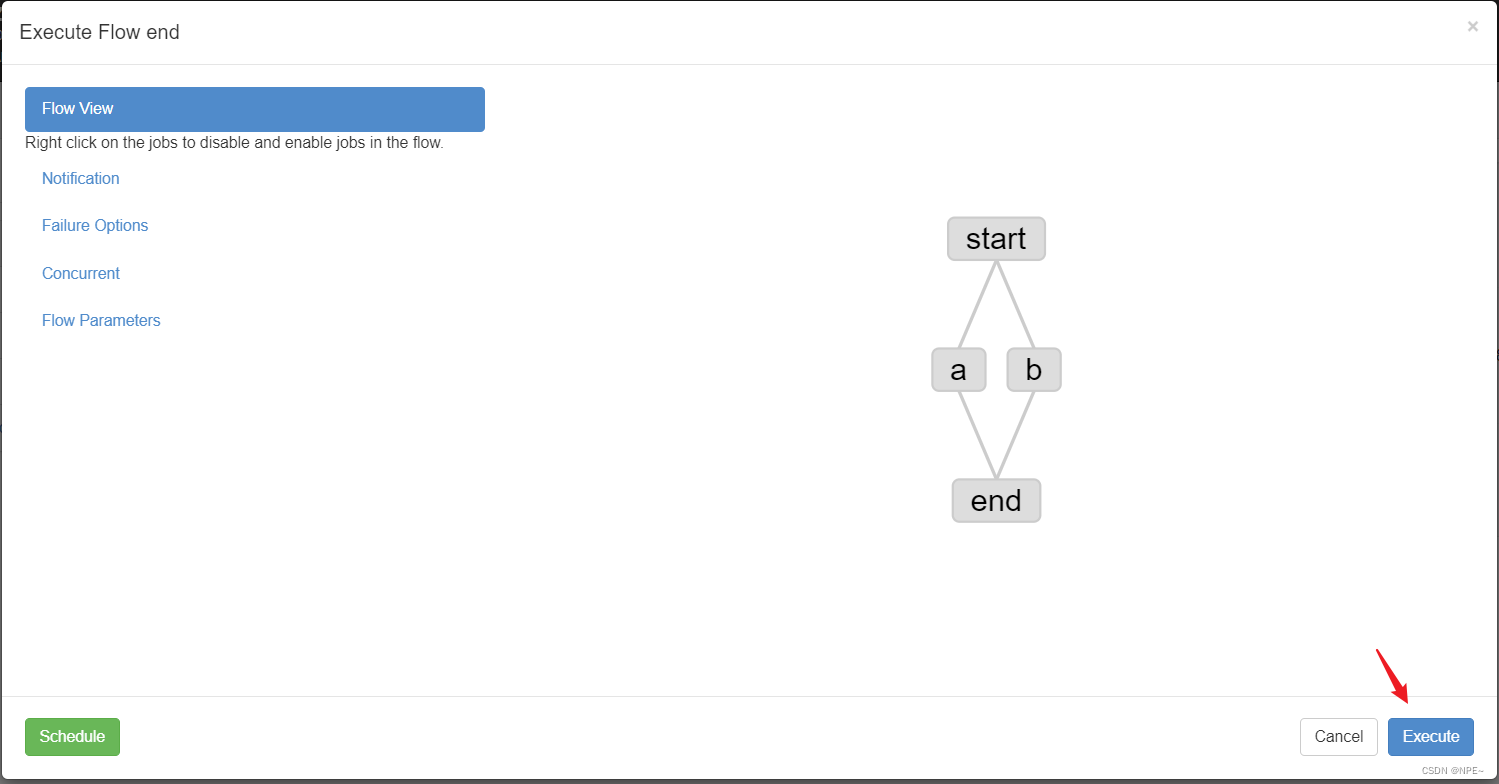
- 然后创建a.job,依赖start.job
#a.job
type=command
dependencies=start
command=echo "hello a job"
- 创建end.job,依赖a.job和b.job
#end.job
type=command
dependencies=a,b
command=echo "end job"
将所有 job 资源文件打到一个 zip 包中,在 azkaban 的 web 管理界面创建工程并上传 zip 包
执行:
查看运行结果:

Azkaban还能用于:
- 调度Java程序
- 调度HDFS、MR任务
- 定时任务调度,如:Sqoop作业等
6 实战:商品销售数据分析
6.1 准备工作
实验环境:
Hadoop == 3.1.0
CentOS == 8
Hive == 3.1.2
- 现有商品销售订单如下:

字段从左致右分别为:订单编号,销售日期,省份,城市,商品编号,销量,销售额
- 商品详细表如下:
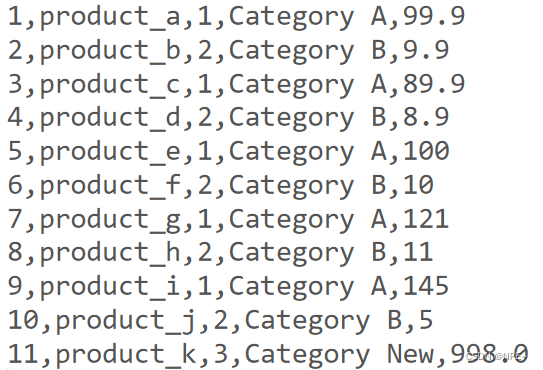
字段从左致右分别为:商品编号,商品名称,分类编号,分类名称,商品价格
6.2 表创建及数据加载
①创建表
销售订单表:
create table t_dml (
detail_id bigint,
sale_date date,
province string,
city string,
product_id bigint,
cnt bigint,
amt double
)row format delimited
fields terminated by ',';
商品详细表:
create table t_product (
product_id bigint,
product_name string,
category_id bigint,
category_name string,
price double
)row format delimited
fields terminated by ',';
②加载数据
load data local inpath '/opt/data/t_dml.csv' into table t_dml;
load data local inpath '/opt/data/t_product.csv' into table t_product;
6.3 销售数据分析
①查询t_dml中的销售记录的时间段:
select max(sale_date), min(sale_date) from t_dml;
②查询各商品类别的总销售额
select t.category_name, sum(t.amt) as total_money
from
( select a.product_id, a.amt, b.category_name
from t_dml a
join t_product b
on a.product_id=b.product_id
) t
group by t.category_name;
③查询销量排行榜
店主想知道哪个商品最畅销以及销量排行榜,请查询销量前10的商品,显示商品名称,销量,排名。
select a.product_name , t.cnt_total,
rank() over (order by t.cnt_total desc) as rk
from
( select product_id, sum(cnt) as cnt_total
from t_dml
group by product_id
order by cnt_total desc
limit 10
) t
join t_product a
on t.product_id=a.product_id;
6.4 创建中间表
店主想知道各个市县的购买力,同时也想知道自己的哪个商品在该地区最热卖,通过创建中间表,优化查询。
①创建存放结果的中间表
create table t_city_amt
( province string,
city string,
total_money double
);
create table t_city_prod
( province string,
city string,
product_id bigint,
product_name string,
cnt bigint
);
②插入数据
insert into t_city_amt
select province,city,sum(amt)
from t_dml group by province,city
insert into t_city_prod
select t.province,t.city,t.product_id,t.product_name,sum(t.cnt) from
(
select a.product_id,b.product_name,a.cnt,a.province,a.city
from t_dml a join t_product b
on a.product_id = b.product_id
) t
group by t.province,t.city,t.product_id,t.product_name
③优化
from
( select a.*, b.product_name
from t_dml a
join t_product b
on a.product_id=b.product_id
) t
insert overwrite table t_city_amt
select province, city, sum(amt)
group by province, city
insert overwrite table t_city_prod
select province, city, product_id, product_name, sum(cnt)
group by province, city, product_id, product_name;
6.5 统计指标
①统计各省最强购买力地区
select province, city, total_money
from
(
select province, city, total_money,
dense_rank() over (partition by province order by total_money desc) as rk
from t_city_amt
) t
where t.rk=1
order by total_money desc;
②统计各地区畅销商品
select province, city, product_id, product_name
from
( select province, city, product_id, product_name,
dense_rank() over (partition by province order by cnt desc) as rk
from t_city_prod
) t
where t.rk=1
order by province, city;
6.6 配合e-charts等图表展示数据
省略,大致步骤:前端通过e-charts或其他图表工具,将从后端数据库查询到的数据展示在页面。
例:
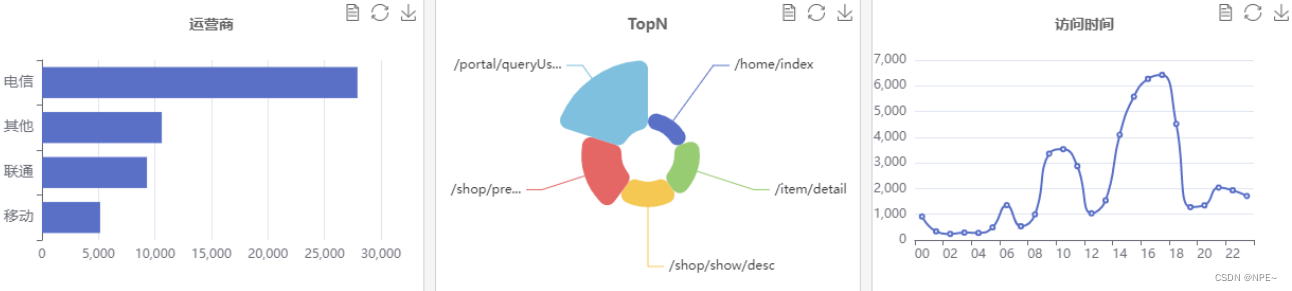
实战:网站访问日志分析
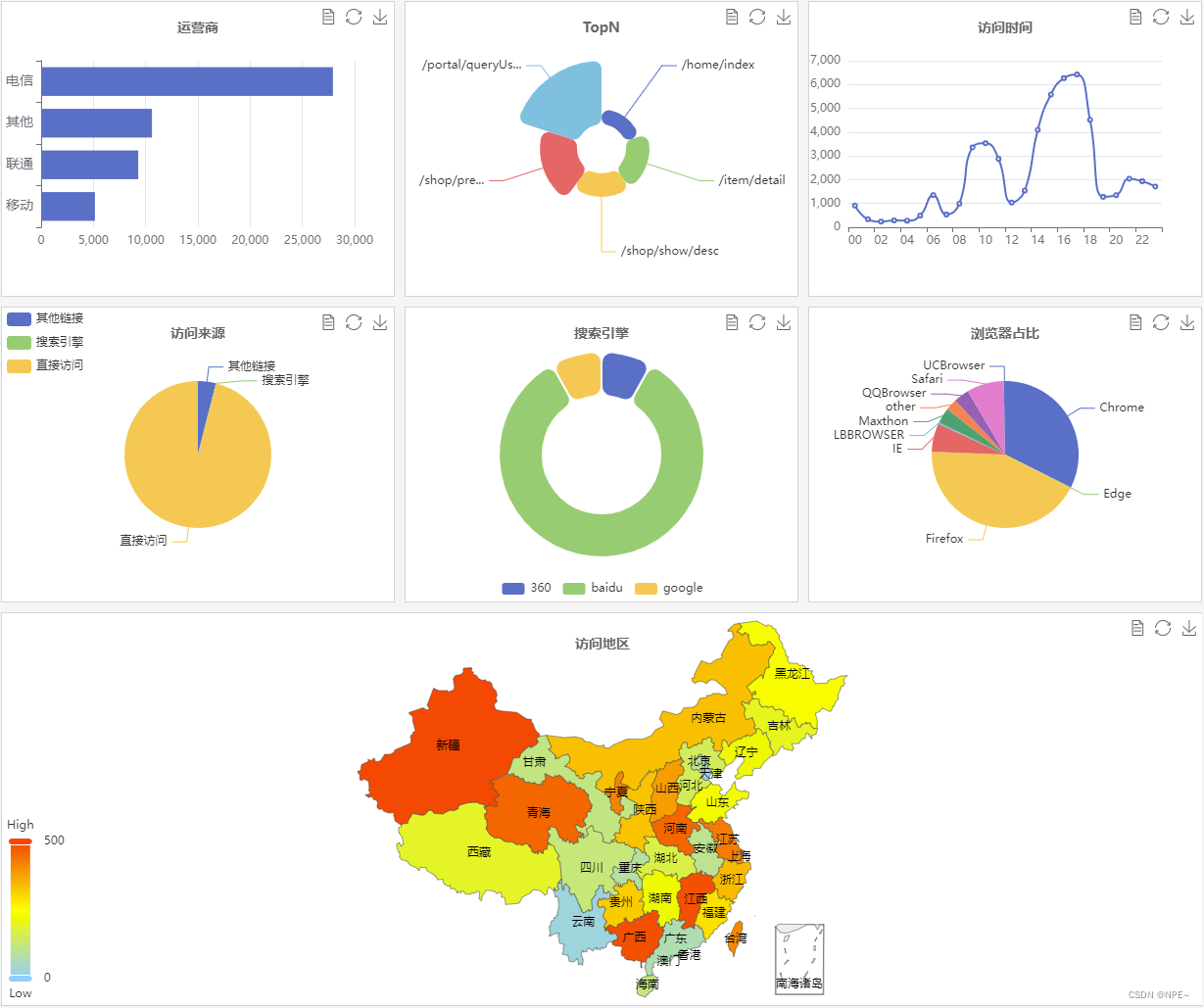
暂时省略,给出步骤:

最终效果:










![[Arduino] ESP32开发 - 基础入门与原理分析](https://img-blog.csdnimg.cn/f630c63d1a4a4f34b834b745b640f139.png)