当我们需要大致知道表行数,但又不需要很精确时,可以采用以下方法
一、 统计信息 pg_class.reltuples
最简便的方法是利用pg_class.reltuples,类似oracle的num_rows
postgres=# select reltuples::numeric from pg_class where relname='pgbench_accounts';
reltuples
-----------
20000000
(1 row)加::numeric是为了防止数字太大,变成科学计数法
postgres=# select reltuples from pg_class where relname='pgbench_accounts';
reltuples
-----------
2e+07
(1 row)但是这个字段的值需要收集统计信息后才有,如果统计信息过旧,也会不准确
create table tmp001(aid integer) WITH (autovacuum_enabled = off);
insert into tmp001 select aid from pgbench_accounts;
-- pg 14版本没有收集统计信息时,reltuples=-1
select reltuples::numeric from pg_class where relname='tmp001';
reltuples
-----------
0
(1 row)二、 执行计划 rows
如果没有统计信息或者比较旧了,又不想收集,可以使用explain
1. 用法测试
postgres=# EXPLAIN SELECT 1 FROM tmp001 limit 1;
QUERY PLAN
------------------------------------------------------------------------
Limit (cost=0.00..0.01 rows=1 width=4)
-> Seq Scan on tmp001 (cost=0.00..314160.80 rows=22566480 width=4)
(2 rows)看到在完全没有统计信息的情况下,偏差大概在10%左右
收集之后,偏差明显减少
postgres=# analyze tmp001;
ANALYZE
postgres=# EXPLAIN SELECT 1 FROM tmp001 limit 1;
QUERY PLAN
------------------------------------------------------------------------
Limit (cost=0.00..0.01 rows=1 width=4)
-> Seq Scan on tmp001 (cost=0.00..288496.96 rows=20000096 width=4)
(2 rows)但是注意不要EXPLAIN SELECT count(*),相差很大
postgres=# EXPLAIN SELECT count(*) FROM tmp001;
QUERY PLAN
--------------------------------------------------------------------------------------------
Finalize Aggregate (cost=193663.38..193663.39 rows=1 width=8)
-> Gather (cost=193663.17..193663.38 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=192663.17..192663.18 rows=1 width=8)
-> Parallel Seq Scan on tmp001 (cost=0.00..171829.73 rows=8333373 width=0)
(5 rows)为了方便获取预估值,可以将执行计划输出转为json格式
postgres=# EXPLAIN (FORMAT JSON) SELECT 1 FROM tmp001 limit 1;
QUERY PLAN
-------------------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Limit", +
"Parallel Aware": false, +
"Startup Cost": 0.00, +
"Total Cost": 0.01, +
"Plan Rows": 1, +
"Plan Width": 4, +
"Plans": [ +
{ +
"Node Type": "Seq Scan", +
"Parent Relationship": "Outer",+
"Parallel Aware": false, +
"Relation Name": "tmp001", +
"Alias": "tmp001", +
"Startup Cost": 0.00, +
"Total Cost": 288496.96, +
"Plan Rows": 20000096, +
"Plan Width": 4 +
} +
] +
} +
} +
]
(1 row)2. 按表名统计
创建函数,将Plan Rows转换成输出:
CREATE OR REPLACE FUNCTION countit(name,name)
RETURNS float4
LANGUAGE plpgsql AS
$$DECLARE
v_plan json;
BEGIN
EXECUTE format('EXPLAIN (FORMAT JSON) SELECT 1 FROM %I.%I', $1,$2)
INTO v_plan;
RETURN v_plan #>> '{0,Plan,"Plan Rows"}';
END;
$$;执行函数
postgres=# select countit('public','tmp001')::numeric;
countit
----------
20011000
(1 row)
3. 查询所有表
SELECT
relname AS table,
CASE WHEN relkind = 'r'
THEN reltuples::numeric
ELSE countit(n.nspname,relname)::numeric
END AS approximate_count
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON (c.relkind IN ('r','v') AND c.relnamespace = n.oid)
ORDER BY 2 DESC;
table | approximate_count
---------------------------------------+-------------------
tmp001 | 20000000
test | 1608000
pgbench_branches | 57184. 按SQL语句统计
CREATE OR REPLACE FUNCTION countit(text)
RETURNS float4
LANGUAGE plpgsql AS
$$DECLARE
v_plan json;
BEGIN
EXECUTE 'EXPLAIN (FORMAT JSON) '||$1
INTO v_plan;
RETURN v_plan #>> '{0,Plan,"Plan Rows"}';
END;
$$; 用法测试
postgres=# create table t1234(id int, info text);
CREATE TABLE
postgres=# insert into t1234 select generate_series(1,1000000),'test';
INSERT 0 1000000
postgres=# analyze t1234;
ANALYZE
postgres=# select countit('select * from t1234 where id<1000');
countit
---------
954
(1 row)
postgres=# select countit('select * from t1234 where id between 1 and 1000 or (id between 100000 and 101000)');
countit
---------
1931
(1 row) 三、 源码学习
做完前面测试之后有个疑问:explain中的rows是怎么估算的,在表没有和有统计信息时是否有区别?
1. explain中rows的估算位于哪个函数
通过Dtrace打印出所有调用的函数,可以参考:postgresql源码学习(50)—— 小白学习Dtrace追踪源码函数调用_Hehuyi_In的博客-CSDN博客
vi function.c
// 内容如下
probe process("/data/postgres/base/14.0/bin/postgres").function("*") {
printf("%s: %s\n", execname(), ppfunc());
}执行脚本
stap function.c > mylog_02.txt虽然不知道预估行数的函数确切叫什么,但可以猜会带有row或者estimate,试一试
[root@linux01 ~]# cat mylog_02.txt |grep row
postgres: get_row_security_policies
postgres: preprocess_rowmarks
postgres: distribute_row_identity_vars
postgres: clamp_row_est
postgres: command_tag_display_rowcount
这里看名字clamp_row_est有点像,但看内容会发现它不是。它的作用主要是避免rows出现过大或者过小的值,限在一个范围内。
同时可以看到当rows<=1时,都设置=1,所以当rows=1,也有可能这个表是空表或者预估的行数有问题,这里跟oracle有点像。
/*
* clamp_row_est
* Force a row-count estimate to a sane value.
*/
double
clamp_row_est(double nrows)
{
/*
* Avoid infinite and NaN row estimates. Costs derived from such values
* are going to be useless. Also force the estimate to be at least one
* row, to make explain output look better and to avoid possible
* divide-by-zero when interpolating costs. Make it an integer, too.
*/
if (nrows > MAXIMUM_ROWCOUNT || isnan(nrows))
nrows = MAXIMUM_ROWCOUNT;
else if (nrows <= 1.0)
nrows = 1.0;
else
nrows = rint(nrows);
return nrows;
}[root@linux01 ~]# cat mylog_02.txt |grep estimate
postgres: estimate_rel_size
postgres: table_relation_estimate_size
postgres: heapam_estimate_rel_size
postgres: table_block_relation_estimate_size
postgres: set_baserel_size_estimates
这个看起来就比较像了,最终看主要是在table_block_relation_estimate_size函数中
void
table_block_relation_estimate_size(Relation rel, int32 *attr_widths,
BlockNumber *pages, double *tuples,
double *allvisfrac,
Size overhead_bytes_per_tuple,
Size usable_bytes_per_page)
{
BlockNumber curpages;
BlockNumber relpages;
double reltuples;
BlockNumber relallvisible;
double density;
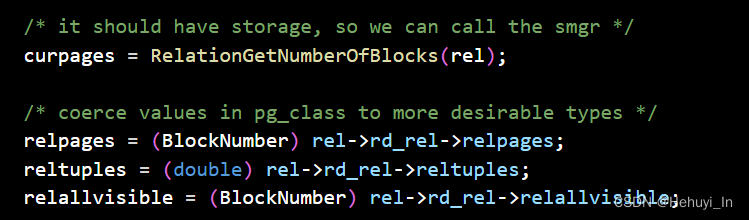
/* 从存储管理器smgr中获取表实际页数(例如根据表大小估算) */
curpages = RelationGetNumberOfBlocks(rel);
/* 从pg_class中获取页数、行数、可见页数等 */
relpages = (BlockNumber) rel->rd_rel->relpages;
reltuples = (double) rel->rd_rel->reltuples;
relallvisible = (BlockNumber) rel->rd_rel->relallvisible;
/*
* 如果表从未执行过vacuumed(包括统计信息收集),使用最小预估值为10 pages,因为通常这种表是新建的,非常小。
*/
if (curpages < 10 &&
reltuples < 0 &&
!rel->rd_rel->relhassubclass)
curpages = 10;
/* report estimated # pages,预估的页数 */
*pages = curpages;
/* quick exit if rel is clearly empty,若为空表,直接记为0退出 */
if (curpages == 0)
{
*tuples = 0;
*allvisfrac = 0;
return;
}
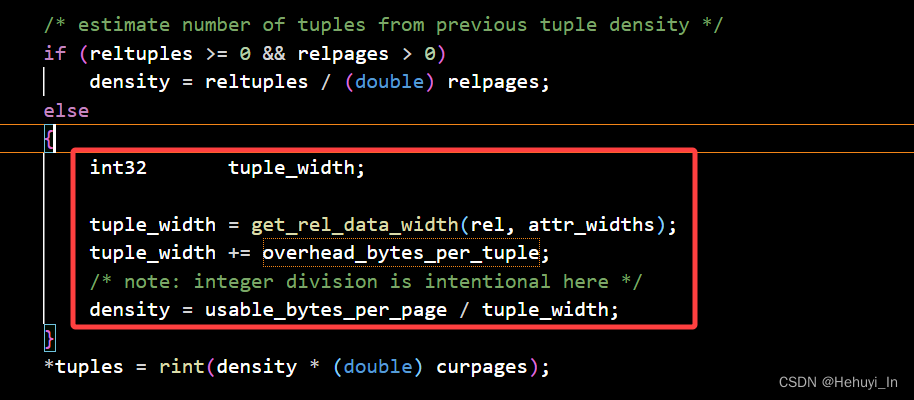
/* estimate number of tuples from previous tuple density,计算元组密度。若统计信息中行数与页数均不为0,则密度=行数/页数,即每页有多少行 */
if (reltuples >= 0 && relpages > 0)
density = reltuples / (double) relpages;
else
{
/*
* 如果没有统计信息数据,则根据数据类型和列宽度来估算
*/
int32 tuple_width;
// 先根据数据类型算列宽度,例如int就是4
tuple_width = get_rel_data_width(rel, attr_widths);
// overhead_bytes_per_tuple包括tuple header和item pointer
// 其定义为 #define HEAP_OVERHEAD_BYTES_PER_TUPLE (MAXALIGN(SizeofHeapTupleHeader) + sizeof(ItemIdData))
tuple_width += overhead_bytes_per_tuple;
/* usable_bytes_per_page是为每行元组预估的每页已用大小(不包括页头及特殊空间) */
density = usable_bytes_per_page / tuple_width;
}
// 最后行数预估均为 密度(每页有多少行)*当前页数
*tuples = rint(density * (double) curpages);
...
}2. 没有统计信息时的估算
下面的测试是后面补的,版本和数据量跟前面不一致,可以忽略,主要看原理。
create table tmp001(aid integer) WITH (autovacuum_enabled = off);
insert into tmp001 select aid from pgbench_accounts; -- 1000000行
-- pg 14版本没有收集统计信息时,reltuples=-1
select reltuples::numeric from pg_class where relname='tmp001';
reltuples
-----------
-1
(1 row)gdb跟踪一把
postgres=# EXPLAIN SELECT 1 FROM tmp001;
QUERY PLAN
----------------------------------------------------------------
Seq Scan on tmp001 (cost=0.00..25730.40 rows=1848240 width=4)
(gdb) p curpages
$2 = 7248
(gdb) p reltuples
$3 = -1
(gdb) p tuple_width
$4 = 4
(gdb) p overhead_bytes_per_tuple
$6 = 28
(gdb) p tuple_width
$5 = 32
(gdb) p density (density = usable_bytes_per_page / tuple_width;)
$7 = 255
(gdb) p usable_bytes_per_page
$8 = 8168
(gdb) p *tuples
$11 = 1848240
*tuples = rint(density * (double) curpages); 1848240即255*7248
3. 有统计信息时的估算
postgres=# analyze tmp001;
ANALYZE
postgres=# EXPLAIN SELECT 1 FROM tmp001;
QUERY PLAN
----------------------------------------------------------------
Seq Scan on tmp001 (cost=0.00..17248.00 rows=1000000 width=4)
(1 row)
(gdb) p curpages
$2 = 7248
(gdb) p relpages
$4 = 7248
(gdb) p reltuples
$6 = 1000000

(gdb) p *tuples
$9 = 1000000
tuples=density*curpages=(reltuples/relpages)*curpages,而这里relpages=curpages,因此这里执行计划预估的行数跟reltuples是一致的。
但是对于大表,由于统计信息也是抽样的,因此relpages与curpages可能一致,因此执行计划预估的行数并不总是等于reltuples(比如最前面2000万行那个例子它们就是不相等的)。
参考
https://github.com/digoal/blog/blob/master/201509/20150919_02.md
还有个遗留的问题:为什么explain select count(*) 差距会特别大,暂时没找到答案,留待发现。