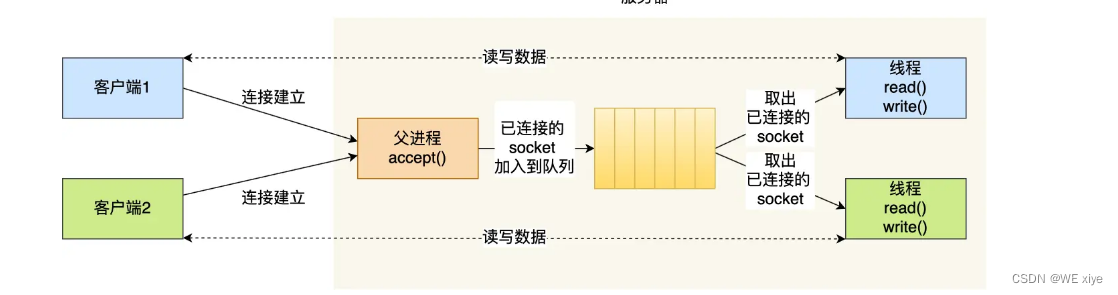
看看CHATGPT在最近几个月的发展趋势
https://blog.csdn.net/csdnnews/article/details/130878125?spm=1000.2115.3001.5927
这是属于 AI 开发者的好时代,有什么理由不多去做一些尝试呢。
北大教授陈钟谈 AI 未来:逼近 AGI、融进元宇宙,开源是重中之重!
https://blog.csdn.net/csdnnews/article/details/130838259?spm=1000.2115.3001.5927
去年 11 月底 ChatGPT 横空出世时,可能谁也没想到,一场规模庞大的变革将由此开启。
凭借其强大的语言理解和生成能力,ChatGPT 上线 2 个月突破 1 亿月活,吸引了工业界和学术界的广泛关注,以 ChatGPT 为代表的大模型技术更被认为开启了 AI 2.0 时代:
▶ 比尔 · 盖茨:ChatGPT 有着重大的历史意义,不亚于互联网或个人电脑的诞生;
▶ 微软 CEO 萨蒂亚 · 纳德拉:对于知识型工作者来说,ChatGPT 是一场革命;
▶ OpenAI 创始人 Sam Altman:多模态的 AI 大模型有望成为继移动互联网之后的技术平台;
▶ ……
与此同时,AI 2.0 时代的突然降临也在业界引发了诸多探讨:大模型技术究竟将触发一场怎样的技术变革?身处其中的开发者和企业要如何顺利搭上这趟“车”?我们距离真正的 AGI(artificial general intelligence,通用人工智能)又还有多远?
————————————————
版权声明:本文为CSDN博主「CSDN资讯」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csdnnews/article/details/130838259
“可能一开始做预训练大模型的人也没多大信心,没将目标定得很高,但它所涌现出来的结果超出人们的意料,因此在第三次人工智能浪潮中起到了震撼性作用。”
英特尔官宣 1 万亿参数 AI 大模型,计划 2024 年完成
据了解,英特尔 Aurora genAI 模型将以两个框架为基础:NVIDIA 的 Megatron 和微软的 DeepSpeed。
▶ Megatron:用于分布式训练大规模语言模型的架构,专门针对 Transformer 进行了优化,不仅支持传统分布式训练的数据并行,也支持模型并行。
▶ DeepSpeed:专注于优化大型深度学习模型的训练,通过提高规模、速度、成本和可用性,释放了训练 1000 亿参数模型的能力,极大促进大型模型的训练。
除了这两个框架,Aurora genAI 模型还将由 Aurora 超级计算机来提供算力——这台英特尔为阿贡国家实验室设计的超级计算机,在经历了各种推迟后,如今终于成型了。
根据目前公开的资料显示,Aurora 超级计算机由英特尔 Xeon CPU Max 和 Xeon GPU Max 系列芯片提供支持,总共有 10624 个节点,拥有 63744 个 Ponte Vecchio GPU、21248 个 Sapphire Rapids 至强 CPU、1024 个分布式异步对象存储 (DAOS) 存储节点以及 10.9 PB 的 DDR5 傲腾持久内存。
新职业|我用GPT给电子厂带货
https://t.cj.sina.com.cn/articles/view/6286736254/176b7fb7e01901df3u?sudaref=www.ruanyifeng.com&display=0&retcode=0
言论
以后不再有《教父》,也不再有《绿野仙踪》,只有15秒的人类愚蠢片段。
– 一位好莱坞编剧,谈他怎么看待 TikTok
科技爱好者周刊(第 160 期):中年码农的困境
2008年,哈工大研究生毕业后,我和同宿舍的同学一起来了上海。他在盛大游戏工作几年后,回了广州老家,我们就很少联系了。
前一段时间,我有事找他,就聊了一下近况。他本科和硕士都是计算机专业,现在广州的一家游戏公司上班,还在写代码。我们都已经35岁了,我也想知道,这个年龄段的中年码农,现在的行情怎么样?
他跟我说了几个情况。首先,跟大家想的一样,加班非常厉害。周一到周五,每天基本是晚上十点下班,如果遇到项目上线或者重大更新,那肯定是凌晨两三点下班,通宵也是有的。周六还要正常上班。
他现在的这家公司比较坑。游戏公司给研发人员的基本工资不会太高,你的很大一部分收入来自项目奖金。去年他们公司有一个项目上线,就在上线之前,把整个项目组解散了,要么辞退,要么分配到其他的项目组。公司这是为了节省成本,少发奖金。很多公司都这么干,没有办法的,员工永远是处在弱势的地位。
然后,我很好奇,也是很多人好奇的,985高校的计算机硕士,工作到现在有12年了,收入是多少呢?他跟我说,他的月薪是每月税后三万多,具体多少他没说,奖金我也没问。
我是自由职业者,会担心下个月的收入,我觉得他在公司上班,可能相对稳定一点。他说自由职业者的所有担心,他作为上班族都有,担心会被裁员。裁员是所有中年码农,或者说所有中年职场人士,都避不开的一个话题。35岁到40岁的这些职场人士,如果职位做不到中层,你的人力成本是很贵的。把你优化掉,雇佣那些刚毕业的年轻人,对公司是更优的选择。他们更有体力,也更听话,执行力也更强。很多公司裁员时,第一考虑的就是中年的中低层职员。作为中年人,如果你平时不加班,万一绩效评得不好,那就可能被优化掉。
我刚毕业时,很多同学和同事可能心里想的是,写几年代码,代码写得好之后去转管理层。后来有一些人真的转了管理,但是更多的人是转行,不做码农了,因为年纪大了,各种体力都跟不上了。转管理层毕竟是少数,因为僧多粥少,只有那么几个位置,而且有些人就不适合做管理,喜欢写代码。就算成功晋升管理层,往上走就更难了,很多时候只能走到中层,很难走到高层。所以,对于中层管理者,前面说的那些中年危机,他同样都有。
现在已经有很多三四十岁的码农了,好消息是有一小撮人,像我同学那样,依然在写代码,坏消息是很多公司对于中年的码农比较苛刻,由于他们的综合人力成本比较高,很容易被优化掉。这就是现状。
下面对于那些年轻的码农,我给几个建议吧。
(1)要有积累。不管是文字、视频、项目、代码等等,一定要有积累,要在本职工作以外,有一个东西你可以慢慢的累积下来。最开始的几年,可能都没有什么收益,但你最好还是要坚持下去。我觉得,积累是一种很强大的力量,比学习能力更重要。因为随着年龄的增长,你的学习能力是在下降的,而且行业和技术迭代比较快,一直有新东西出现,你必须不断地保持学习,这很困难。
(2)要让自己不可或缺。公司制定了很多很完善的流程和制度,目的就是为了让每一位员工都可以被替代,一旦有人离职,都可以在短时间内找到替代他的人,这样才能保持公司的正常运转。个人的策略其实就是跟公司相反,让公司不容易找到替代你的人。如果公司需要花费较长时间或者较大的成本,才能找到合适的人来替换你,那么你就是不可或缺的。
(3)要保持开放的头脑,要善于接受。每个人的见识是有局限的,世界是多元的,每一次交流都是认知的碰撞。很多人就是不善于接受别人的观点,很固执。我并不是说,让你无脑地赞同别人,而是你愿意去尝试或者验证别人的观点。这样才会给自己带来更多的机会,蛮干是没有出路的。中国大部分码农的现状是不乐观的,如果你不多去思考的话,情况可能会更加的不乐观。
科技爱好者周刊(第 109 期):播客的价值
https://www.ruanyifeng.com/blog/2020/05/weekly-issue-109.html
Spotify 最近购买了乔·罗根(Joe Rogan)播客节目的独家播放权,价格据说达到了一亿美元。
"播客"是 podcast 的中文音译,指的是谈话类的互联网音频节目,主要供用户收听。乔·罗根的节目是美国最有影响力的播客之一,每期采访一个来宾,两人坐着谈话,单期的收听超过1000万人次。
播客的制作成本非常低,说话能有多少成本?一亿美元的天价前所未有,很难想象一个互联网谈话节目,值这么多钱。
这件事的启示就是,我们可能远远低估了播客的潜力。它是一种传播力很强的媒体,属于还没被充分认识的金矿。
相比其他媒体,播客最大的特点就是,你一个人收听(尤其戴着耳机)时,主持人就是对着你的耳朵在讲述,属于跟受众物理距离最近的媒体。 现实生活中,只有最亲近的朋友和亲人,才会一对一地跟你诉说。所以,播客很容易让听众产生亲切感,赢得长期的忠实订阅者。
这反过来也要求播客主持人必须非常真诚,否则就没有在耳边诉说的效果,反而容易产生反感。播客的另一个优势是走路、开车、躺着都能听,传播场合远远超过视频。
我觉得,播客可能是国内互联网的下一个热点。现在国内的热点是直播卖货,其实就是互联网版的电视购物,观众人数总是有限的,愿意看推销节目的人再多能有多少?精心制作的谈话节目会有多得多的听众。
有人会说,播客在国内不可行,因为国内对内容管理得很严格,谈话节目做不起来。但是反过来看,就是因为生产不足,国内听众对内容的需求特别大。以前,《读者》杂志一期可以发行1000万份,就说明这一点了。目前,国内好的谈话节目寥寥无几,这是不正常的,我们有14亿人口。播客有很多方面可以谈,一定有大量听众追着听,比如男女关系、生活感悟、家庭生活、球赛、电影、财经(或房地产/股票/彩票)分析等等。
不过,也不是每个人都能做播客。谈话节目对主持人的要求特别高,必须有亲切感和人生阅历,说话还要流利、通俗易懂、有吸引力和感染力。现在占据网络直播台的少男少女,都做不了播客。
独家对话Python之父:人类大脑才是软件开发效率的天花板
https://blog.csdn.net/programmer_editor/article/details/127083989?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%AF%B9%E8%AF%9Dpython%E4%B9%8B%E7%88%B6&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-127083989.142v88control_2,239v2insert_chatgpt&spm=1018.2226.3001.4187
Python 缘起与三十载风云发展史
邹欣:现在很多人的第一门编程语言就是 Python。你是怎么开始学习编程的?
Guido:我最早是1974与1975年在阿姆斯特丹开始学习编程。学的第一门语言是 ALGOL 60,后续还学过一些别的语言,但我最爱的是 Pascal,它是一门非常优雅的语言。在这个过程中,我逐渐了解一门编程语言应有的特性,以及它们在处理具体问题时各自的特点。例如,在 ALGOL 60 里是没有字符串类型的,如果想定义一个标识符就必须用一种魔法一般的方式来处理字符串,这种魔法在不同的输入硬件上的施展方式还不一样——要知道我们当时是通过穿孔卡片来输入代码的,每一种卡片机都是不同的。而 Pascal 在处理字符串上也很有一套,我认为 Pascal 非常优雅,能帮程序员高效率编程。
邹欣:上世纪 90 年代初,你在圣诞节假期作为个人兴趣项目创建了 Python,当时你有没有想过有一天 Python 会如此大放异彩?如何看待今天的 Python?
Guido:当时,我在工作中有个任务要完成:用C语言写一大批功能非常相似的小型工具。对于重复编写非常相似的C语言代码,我比较心烦,如果能有个比 C 语言更好的编程语言就好了,我就能非常快速地完成任务。后来,我索性自己发明了 Python。当时只是想创造一个“胶水语言”,把写过的 C 语言小程序粘贴在一起构成一个新的工具。
我对 Python 后来的发展其实根本没有什么预期,我觉得它就跟当时做过的许多失败的项目一样,没有什么特别之处。Python 最开始的发展其实非常缓慢。它后来之所以会得到大家的青睐,主要是在上世纪90年代末期,很多科学家开始在进行科学计算时,就像我一样用 Python 来作为“胶水语言”,调用原来由Fortran 或 C++ 编写的代码。对于这些科学家来说,Python 是非常顺手的工具。
对比现在的 Python 和最早的版本,你也许会发现 Python 这门编程语言几乎没怎么变,只是类的声明有少许改变;print 从一开始到 Python 2 一直都是语句,直到在 Python 3 里才变成了函数;函数从最开始没有关键字和参数到后来有;以及 Python 3 才出现的双下划线魔法函数(Dunder/Magic Methods),等等。但总的来说,现在的 Python 跟最开始相比并没有特别大的差别,无论是语法、语义还是其本质精神都非常接近。
邹欣:大家刚接触 Python 这门语言时都会好奇的就是强制的代码缩进。如果重来一次,你是否会放弃缩进这个强制要求?
Guido:代码缩进(Indentation)其实并不是我发明的,当时的同事给了我启发。在 Python 中要求进行代码缩进的原因是 30 年前的代码编辑器都不能很好地对代码进行缩进排版,所以我就想鼓励程序员自己来对代码进行正确的排版,从而确保程序员从视觉上对代码的理解与编译器对代码的解析是一致的。这其实非常重要,几年前苹果公司就发生过一次非常严重的代码安全漏洞事故,就是由于代码中一个语句与程序员实际设想的 if-else 语法逻辑没有匹配而引起的,如图 1 。其实,严格要求代码缩进确实有点夸张,改用花括号,也不是不可以。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ddN1U8Yu-1687517699817)(2023-06-03-20-03-41.png)]
————————————————
版权声明:本文为CSDN博主「《新程序员》编辑部」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/programmer_editor/article/details/127083989

邹欣:什么才是软件开发最核心的东西?是使用“创造工具的工具”来极大提高效率么?
Guido:我认为对编程来说真正酷的事情,是将新软件构建于先前软件的基础之上,现在的程序员编写代码可以借鉴前人的代码。举例来说,假设我需要用Python 编写一个程序以对推特消息进行情感分析(Sentiment analysis)。虽然从未做过类似的事情,但我相信可以通过谷歌搜索引擎和Copilot就能在一个下午完成这项工作,因为我一定不是第一个去做这件事的人。可以看到我们现在构建软件的方式跟二三十年前很不一样。
软件实际上是由多层结构组成的。这有点像生物的进化。一方面 DNA 的编码方式已经有十亿年没有发生变化了,这就像计算机体系里的比特、字节、指针和内存一样。数亿年前隐生代的水藻细胞就已经有着自己独特的 DNA 编码,一个水藻细胞就像一个小型计算机。另一方面从水藻化石中发现的隐生代细胞跟现代的细胞,例如人类的组织细胞,没有太大的形态变化。不同类的多细胞可以组成不同的器官,各种不同的器官最终又组成了人类,人类自己又构成了人类社会。软件也像是这样,我认为软件开发领域最重要的事件就是通过网络把计算机都联系在了一起,从而能基于简单的细小结构构建出多层次的大型复杂体系。在简单当中蕴含着高层次的结构,这里面具有超乎想象的灵活性和可能性。
在软件当中其实最终都是指针、内存和计算,作为程序员了解这些最底层的概念非常重要。至少在学习编程的时候,要对此有所了解。这就像做加减乘除一样,你可以通过计算器来算出结果,但如果你不懂算术原理,当你在用计算器计算时不小心按错了,得到了错误的最终结果,你自己甚至都不知道错在哪里了。如果你懂一点基本算术原理,你就能对计算器的最终显示结果是否正确有一个大致的判断。如果还懂得更多一点的数学知识,就可以将一个原本无法直接用算术来进行解答的问题拆分成若干个小的算术问题,解决了这些小问题,就能算出最终答案。因此我们不能把计算机当作是一个魔法盒子,而要去了解它是如何运作的。这样虽然不一定能成为最厉害的程序员,但会比那些完全不懂基本概念的程序员更了解软件和计算机的弱点和约束,从而更好地运用各种软件工具,避免愚蠢的错误。
“我不是个未来主义者,更专注当下”
对话MySQL之父Monty:代码要写到100岁
代码要写到100岁
在程序员的世界似乎存在着年龄之墙,比如大家经常讨论的35岁危机问题,要么走上管理岗位,要么离开,这给很多开发者带来焦虑和压力。有人介绍实际上35岁即便没有走上管理岗位也不太可能失业,但是如果到了45岁还在一线写代码,可能会面临失业。
Monty认为现在关于程序员的职业发展有一个很大的错误,随着年龄增长,很多程序员可以去选择成为管理层或者经理,但是他认为在企业里开发经理很容易被取代。而成为一个优秀的程序员,其难度和对企业的贡献价值会更大。MariaDB愿意赋予程序员更多责任,并提供更高的薪水,让他们在技术道路上有更好的发展。
在MariaDB社区,有个开发者已经80多岁,还在写代码,相信这能鼓舞很多开发者。但是Monty指出,在芬兰大部分创业公司的开发人员都是年轻人。MariaDB可能是个例外,MariaDB服务器端的团队,80%的开发人员都在40岁左右或者更大的年龄,“能够留住这些很有经验的年纪大的人,这本来就是一件做得非常棒的事。”
Monty深受全球开发者的尊敬与热爱,这不仅是因为他在开源和数据库领域取得了举世瞩目的成就,更是由于他对开源以及对技术的热爱与热情,影响并改变了很多人。在采访过程中很容易被他对技术的热情感染,在谈论MariaDB性能和响应速度时,他非常自信地笑着说:“像火箭一样快。”
每个人生命中都有很多跳动的音符,对于Monty而言,或许写代码的键盘敲击声就是那跳动的音符,也是他“最擅长的事情”,他说写代码是难得的事情,要一直写下去,写到100岁。

AI 正在变革软件工程
2021 年,一篇发表于 ASE 2007 的经典论文,让 ASE 将「最有影响力论文」奖项颁给了北京大学讲席教授谢涛和当时的博士生 Suresh Thummalapenta。ASE 与 ICSE、ESEC/FSE 并列为软件工程三大国际顶会,在 ASE 历年最有影响力论文奖获奖作者中,谢涛是首批华人作者。
这篇论文中,谢涛与学生提出用机器学习提高软件研发效能的方法,将大规模的代码搜索、机器学习和数据挖掘结合。这也让他成为最早开展智能化软件工程研究的学者之一。
海外求学与执教的 14 年后,谢涛寻得契机回到北大任讲席教授,继续高水平科研工作。作为最早开展智能化软件工程研究的学者之一,他对 AI 及其应用的认知深入底层,对于 AI 新秀 ChatGPT,他表示:“ChatGPT 是模式上的大进步。它可以不停地对话,让用户把真正想要的东西表达清楚,仅仅是把需求搞清楚这一个点,就能让 AI 的效果和可用性往前迈一大步。”他相信未来中国也能够做出自己的 ChatGPT。
近两三年在智能化软件工程领域,大模型得到了极大关注。Copilot 的惊艳首发,让大家看到大模型在代码生成、代码审查、代码缺陷检测等方面的巨大潜力。再加上 ChatGPT 的拿手交互式对话,AI 技术为基础软件的发展提供了哪些新的方向和机会?对国产基础软件行业的发展有着怎样的展望?我们将从 CSDN 创始人&董事长蒋涛与北京大学讲席教授谢涛的深度对话中为大家悉数呈现。
蒋涛:人工智能不仅是程序员的帮手,还会干掉一部分人重复性的工作。一些数据分析的工作,可能会逐渐被机器人取代,研发基础软件的工程师则不必过于担忧。什么是基础软件?国内发展现状如何?
谢涛:业界对基础软件的定义范围不尽相同,但基本共识是包括操作系统、编程语言、编译器、数据库管理系统、办公软件以及浏览器在内。广义的基础软件还包括一些开发工具、测试运维工具等。办公软件因为太常用了,且在工作中处于关键位置,因此也成为了底座之一,现在被认为是基础软件重要部分。此外,一些工业软件支撑着工业应用的底座,也被包含在特定行业的基础软件里。
国产基础软件有很多子领域存在卡脖子的情况,比如操作系统,广义的工业软件 MATLAB 等等。也许大家要问 Linux、Android 等很多操作系统都是开源,怎么就被卡脖子了?很大一部分原因在于生态上的限制,导致其话语权不在我方。
国产操作系统近几十年发展良好,国家也一直在支持。但现在主流国产操作系统的“心”(内核)还是 Linux,尽管我国程序员与企业在 Linux 内核的贡献比例很大,甚至国内大厂华为对 Linux 内核的贡献如今位列第一,但是回到上述关键词——话语权,还是呈现贡献者多但核心决策人员话语权少的状况。但我国在大数据、 AI、云原生等相关的开源新兴领域有一定话语权。中国新一代技术力量正迎头赶上,企业的发展常常等不及其他人来引领,就自得投入并孕育出不错的研发核心人才,也因此在新兴领域有些建树。
蒋涛:如何定义基础软件的核心人才?
谢涛:有这样一个例子。回北大之前,我曾在 UIUC(University of Illinois at Urbana-Champaign,缩写为 UIUC)计算机系任教。该系有个 2005 年毕业的博士名叫 Chris Lattner,他的博士生导师 Vikram Adve 也是我的前同事,他们推出的 LLVM 构架编译器与 GCC 并列为三大编译器之一。Chris Lattner 后来被称为 LLVM 之父。他的导师告诉我, Chris 在读博期间就研制了 LLVM 编译器的基础设施,毕业后他就打定主意要去产业界,并且展现了很强的能力,拿下很多 offer,最终进入了苹果。Chris 当时的想法是:“谁允许和支持我继续把 LLVM 发扬光大,我就去哪儿!”Apple 全力支持了此事,所以 LLVM 后面发展势头很好。这里我们可以看到基础软件核心人才身上的特点。
蒋涛:人工智能的应用如今也非常广泛,水能载舟亦能覆舟,AI 成为了一部分人的帮手,也成为了一些不法分子手里的利器。央视曾曝光诈骗集团利用人工智能技术让机器人打诈骗电话,拨出 1700 万通电话,最后有 80 多万人上当,总计骗取 1.8 亿,而被骗的人从电话里根本分辨不出是机器人的声音。有没有 AI 技术可以辅助识别机器人骚扰电话,保护普通群众?
谢涛:大数据、AI技术越来越多被诈骗团伙等犯罪分子利用,使广大用户受害的事件层出不穷,要对其进行绝对防治是很难的。就像安全领域的攻和防的关系,我们只能通过提高诈骗门槛来一定程度去防治。目前 AI 技术已经使得发动攻击、诈骗的行动变得门槛很低,也能做出很逼真的机器人合成声,以及非常逼真的交谈内容。对于普通大众用户来说确实挺难防这些 AI 诈骗的手段。
以我的亲身经历为例分享一下防骗心得。有骗子曾以短信询问我某个业内同行的电话号码。这种询问途径其实不太常见,一般人不会直接就发短信来询问另一个人的电话号码。我们可以认真分析,如果一件事情所发生的途径并不自然且不常见,那么很可能就会有问题,要多加小心。

开源 AI 面临的挑战
https://csdnnews.blog.csdn.net/article/details/131098681?spm=1000.2115.3001.5927
在不久的未来,我们将见证与人交往方式、劳动交换方式甚至社会组织方式的根本性变革。个性化的人工智能实体(称为“Ghosts”)有望成为每个人潜在的个性化存在,并将我们连接到全球其他 AI 系统的网络中。这些 AI 系统将为我们提供多种服务,我们可以将它们看作是扩展我们认知的工具,而不仅仅是助手。企业和组织很可能也会拥有自己的 “Ghosts”,以提高成员之间的协作效率。除了社交方面,具有循环连接的关联记忆网络可能使 AI 系统具备记忆能力。这些独立的 “Ghosts” 甚至可能形成独特身份。此外,可能会出现利用共识算法的 AI 系统,促使去中心化自主 AI 的发展。尽管这还尚未实现,但我们已经可以设想一些即将出现的经济变化和趋势。
突然之间就没有现实了,虚拟的世界如此逼真,这真的很令人担忧。我不知道我们该如何看待这个世界,谁知道它是真是假。
– 加州大学教授 Hany Farid,谈 AI 使得深度伪造变得多么容易
归根结底,博客、播客、短视频都是一个人表达自己的地方,是他们用数字形式说"这就是我"的方式。
– 《人工智能会扼杀博客吗?》
如果你有原创性,就可以回避竞争。基本上,如果你与别人发生竞争,那是因为你们在做同样的事情。如果每个人做的事情都有所不同,就可以减少竞争,或者不存在竞争。所以,不要模仿他人。
– Naval,美国著名风投家
一个人必须专攻一些事情才能赚钱。我总是告诉我的孩子:你需要学会某种技能,而且这种技能要强于别人,这样才会有人付钱给你。然后你再付钱请人,帮你做那些你觉得无聊或困难的事情。
– Hacker News 读者
英国科学家研究,什么因素会导致人类感到无聊。最后发现,世界上最无聊的人具有以下特征:职业是宗教数据录入,爱好是看电视,居住地是偏僻小镇。
– 《研究人员发现世界上最无聊的人》
人工智能会杀死博客吗?
有些人可能会觉得博客受到ChatGPT和其他大型语言模型的威胁。生成足够体面的写作非常容易,以至于许多专业作家很快就不得不改变他们的运作方式。最重要的是,我不得不更新Bear的审查流程,以捕捉越来越多的写得很好的垃圾邮件。尽管如此,我并不太担心。人工智能生成的内容肯定会威胁到内容营销和其他同类,但这种威胁不适用于个人博客。
首先,经济激励措施不一致。没有人为了好玩而阅读内容营销SEO粘液。然而,阅读博主的文章,尤其是你熟悉的文章,关于他们的个人经历是根本不同的。我们喜欢观察他人的经历,了解他们的想法,并与这些作家建立(有时是准社会的)关系。
在打击熊掌记上的垃圾邮件时,我发现生成内容的最简单方法是检查博客本身是否具有凝聚力并“得到照顾”。但最大的判断是他们是否在做任何广告(这是很明显的)。
此外,制作博客背后的创作过程对博主来说是一种有意义且有益的体验。通过这个过程,他们可以反思自己的想法,从他们的经验中学习,并以真正人性化的方式与观众互动。
归根结底,博客是一个人表达自己的地方。他们在数字领域插上了一面旗帜。这是他们对虚空的呐喊,是他们说“这是我”的方式。
Will AI kill blogging?
26 Apr, 2023
It may feel to some that blogging is under threat by the likes of ChatGPT and other large language models. It’s so easy to generate decent-enough writing that many professional writers are quickly having to change the way they operate. On top of that, I’ve had to update Bear’s review process to catch an increasing deluge of well-written spam. Despite this, I’m not too concerned. AI generated content certainly threatens content marketing and the rest of their ilk, but that threat doesn’t hold true for personal blogging.
First off, the economic incentives don’t line up. No-one reads content marketing SEO goop for fun. However, reading an essay by a blogger, especially one you’re familiar with, about their personal experience is fundamentally different. We like to see into the experience of others, understand how they think, and develop (sometimes para-social) relationships with these writers.
While fighting spam on Bear, the easiest way for me to spot generated content was to check whether the blog itself was cohesive and “taken care of”. But the biggest tell was whether they were advertising anything (which is pretty obvious).
Furthermore, the creative process behind crafting a blog is a meaningful and rewarding experience for the blogger. Through this process, they can reflect on their own thoughts, learn from their experiences, and engage with their audience in a way that is genuinely human.
Ultimately, blogs are a person’s place to express themselves. Their planting of a flag in the digital realm. It is their shout into the void, their way of saying “this is me”.
对计算机专业的思考
长忆观潮,满郭人争江上望。来疑沧海尽成空,万面鼓声中。
弄潮儿向涛头立,手把红旗旗不湿。别来几向梦中看,梦觉尚心寒。
IT 界每隔几年就有一波浪潮或者泡沫,新的一波大潮已经打过来了,躲?能跑多远?不如成为弄潮儿,勇向涛头立。
为什么说 AI 将拯救整个世界?
AI 会让我们失业吗?AI 会“杀”死人类吗?当一门重要的新技术横空出世的时候,人们总是会担心它给人们带来的种种威胁,基于此,本文作者认为,虽然 AI 风险很高,但也存在非常有影响力的机遇。
首先,我们来简单地介绍一下人工智能(AI)是什么。AI 是通过数学和软件代码教计算机如何以类似于人类的方式理解、综合和生成知识的应用程序。AI 是一种计算机程序,与其他计算机程序一样,AI可以运行、接受输入、处理并生成输出。AI的输出在广泛的领域都有应用,包括编程、医学、法律、创意艺术以及其他等等。与其他技术一样,AI也是归人所有并由人控制的。
至于 AI 不是什么,简单来说,AI不是杀手软件,也不是突然活过来并决定谋杀人类或以其他方式毁掉一切的机器人,与你在电影中看到的情节完全不同。
对于 AI 可以成为什么,简单的描述是:一种让我们关心的一切变得更好的方法。
为什么恐慌?
与上述积极的观点形成鲜明对比的是,目前公众对于AI充满了恐惧和偏执。
我们经常听到这样的说法:AI 会以各种方式杀死我们所有人,毁掉我们的社会,夺走我们的饭碗,造成严重的不平等,并助纣为虐。
如何解释这种从近乎乌托邦到可怕的反乌托邦的分歧?
从历史的角度来看,每一项重要的新技术出现都会引发道德恐慌,包括电灯、汽车、收音机以及互联网,人们认为这些新技术将摧毁世界、社会或者同时毁灭二者。几十年来,我们一次又一次地见证了这种悲观主义者。而事实上,目前我们看到的AI恐慌甚至都不是第一次。
诚然,许多新技术确实引发了不良后果,但通常同一种技术同样能在其他方面为我们带来巨大的好处。道德恐慌确实意味着一些担忧。
但道德恐慌本质上是非理性的,它会放大合理的担忧,甚至到歇斯底里的程度,具有讽刺意味的是,这使得人们更难面对真正严重的担忧。
那么,现在 AI 面临着全面的道德恐慌吗?
很多人利用这种道德恐慌提出采取政策行动的要求,包括新的 AI 限制、法规和法律。这些人就 AI 的危险发表了极其戏剧化的公开声明,这无疑进一步煽动了道德恐慌,而他们表现得就像是公共利益的无私捍卫者。
但他们真的是人类的捍卫者吗?
他们是对还是错?
经济学家观察到了这种改革运动的长期模式。这类运动的参与者分为两类:“浸信会”和“走私者”,这里我们借鉴了上个世纪20年代的美国禁酒令:
“浸信会”指的是社会改革的真正信徒,他们认为酒精正在破坏社会的道德结构,需要新的限制、法规和法律来防止社会灾难。
套用到 AI 的 风险,“浸信会”指的是相信 AI 真的会带来灾难的人群。
“走私者”指的是自私自利的机会主义者,他们利用新的限制、法规和法律打击竞争对手,从而在经济上获利。
在美国禁酒令期间,“走私者”就是私下贩卖酒精的投机分子,他们利用这个期间向美国人出售非法酒类而攫取巨额利润。
套用到 AI 的 风险,“走私者”可以利用这个风险建立监管壁垒,为自己谋求更多利益,这些壁垒形成了一个由政府支持的 AI 供应商组成的垄断联盟,保护他们免受创业公司和开源竞争的影响。
有人提出,一些人既是“浸信会”教徒,也是“走私者”,特别是那些被大学、智囊团、活动家团体和媒体机构收买攻击 AI 的人。如果你拿了钱或资助来助长 AI 恐慌,那么你就是“走私者”。
“走私者”的问题在于,他们会赢。“浸信会”只不过是天真的空想家,而“走私者”是经营者,所以像这样的改革运动的结果往往是“走私者”得到他们想要的东西,比如监管俘获、竞争隔离,以及垄断联盟的形成,只留下“浸信会”疑惑他们对于社会进步的推动究竟哪里出错了。
其实,不久前我们刚刚经历了一个令人震惊的例子,2008 年全球金融危机后的银行业改革。“浸信会”告诉我们,我们需要新的法律法规来拆分“太大而不能倒”的银行,以防止此类危机再次发生。所以,美国国会通过了 2010 年的多德-弗兰克法案,表面上该法案是“浸信会”如愿以偿,但实际上却为“走私者”所用。结果是,2008 年“太大而不能倒”的银行太多,而且规模过大。
所以在实践中,即使“浸信会”是正确的,也会被“走私者”所用,导致他们成为最后的受益方。
而如今,AI 监管的发展正在重演历史。
然而,仅确立每个人的身份,并质疑他们的动机是不够的。我们必须反思“浸信会”和“走私者”的论点。

AI 风险 #1:AI 会杀死我们所有人吗?
AI 风险 #2:AI 会毁掉我们的社会吗?
AI 风险 #3:AI 会抢走我们的饭碗吗?
AI 风险 #4:AI 会导致严重的不平等吗?
AI 风险 #5:AI 会助纣为虐吗?
AI 的发展始于 20 世纪 40 年代,与计算机的问世出于同一时期。首篇关于神经网络(如今 AI 的架构)的科学论文发表于 1943 年。在过去的 80 年里,整整几代 AI 科学家出生、上学、工作,直到离世,都没有看到如今我们获得的回报。他们每一个人都是传奇。
如今,越来越多的工程师都在努力让 AI 成为现实,其中许多人都很年轻,可能他们的祖父母甚至曾祖父母也曾参与 AI 的创建,而散布恐惧和末日的言论将他们描绘成了鲁莽的恶棍。不相信他们是鲁莽的恶棍。他们每一个人都是英雄。我和我们公司愿意尽可能多地支持他们,而且我们肯定会百分百支持他们以及他们的工作。
版权声明:本文为CSDN博主「CSDN资讯」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csdnnews/article/details/131218734
大脑将会代替开发者的键盘!人类和 AI 能够“双向奔赴”吗? | 近匠
《新程序员》:本期技术雷达加入了最新热点:ChatGPT(如图 2 所示)。它在技术雷达中被列为「评估」而不是更为成熟的「试验」级别。您认为它还面临着哪些风险和挑战?
Kristan:与其说风险和挑战,倒不如说全世界目前都缺乏充足的实际应用经验来对 ChatGPT 进行全面评估。人类从未有过和大语言模型进行对话式交互的体验,这需要更多的时间观察。我们的专家团队使用 ChatGPT 做过许多概念验证,但在日常生产环境中的使用还比较有限。
《新程序员》:在技术雷达中,领域特定的大语言模型同样被列为「评估」级的技术(如图 3 所示),它是否面临着与通用语言模型相同的伦理和法律问题?例如,它是否存在对特定社会群体的歧视性?像是把 “doctor” 和 “programmer” 这样的词语与男性联系在一起,或把 “nurse” 和 “homemaker” 与女性联系在一起。
Kristan:我认为任何语言模型、任何代码都有可能出现偏见。其中一些偏见可能是有意识的,但在大多数情况下,这些偏见其实是无意识产生的。你提到的例子里,人们无意识地将某个角色与特定性别相关联,这种偏见会自然地被构建到模型当中。
这是一个需要首先在文本中解决的问题。我们需要有人来质疑那些无意识的偏见,分析和处理带有偏见的文本资料,因为这些偏见往往是难以察觉的,且不同的人会有不同的无意识偏见。所以,如果工作团队具备多元化的思想,就更有可能发现并解决这些特定的偏见。
“GPT-N”一定更强吗?专家警告:当人类数据用完,AI大模型或将越来越笨
https://m.thepaper.cn/newsDetail_forward_23467960
他们通过研究文本到文本和图像到图像 AI 生成模型的概率分布,得出了这样一个结论:
“模型在训练中使用(其他)模型生成的内容,会出现不可逆转的缺陷。”
即“模型崩溃”(Model Collapse)。
什么是模型崩溃?
本质上,当 AI 大模型生成的数据最终污染了后续模型的训练集时,就会发生“模型崩溃”。
论文中写道,“模型崩溃指的是一个退化的学习过程,在这个过程中,随着时间的推移,模型开始遗忘不可能发生的事件,因为模型被它自己对现实的投射所毒化。”
一个假设的场景更有助于理解这一问题。机器学习(ML)模型在包含 100 只猫的图片的数据集上进行训练——其中 10 只猫的毛色为蓝色,90 只猫的毛色为黄色。该模型了解到黄猫更普遍,但也表示蓝猫比实际情况偏黄一点,当被要求生成新数据时,会返回一些代表“绿毛色的猫”的结果。随着时间的推移,蓝色毛色的初始特征会在连续的训练周期中逐渐消失,从逐渐变成绿色,最后变成黄色。这种渐进的扭曲和少数数据特征的最终丢失,就是“模型崩溃”。
CORDIC算法:一种高效计算三角函数值的方法
http://www.longluo.me/blog/2023/06/07/CORDIC-algorithm/
如何去制作图片二维码
https://stable-diffusion-art.com/qr-code/
这个世界日以继夜、竭尽全力让你成为其他人,如果你想做你自己,就意味着要打一场最艰难的仗。
– E·E·卡明斯(E. E. Cummings),20世纪美国著名诗人
人们依靠机器,希望这能带给他们更多自由,但这只会让拥有机器的人奴役他们。
– 弗兰克·赫伯特,科幻小说《沙丘》的作者
视觉信息理论
https://colah.github.io/posts/2015-09-Visual-Information/

提示工程指南
https://www.promptingguide.ai/zh
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计、研发强大的工程技术,实现和大语言模型或其他生态工具的高效接轨。
提示工程不仅仅是关于设计和研发提示词。它包含了与大语言模型交互和研发的各种技能和技术。提示工程在实现和大语言模型交互、对接,以及理解大语言模型能力方面都起着重要作用。用户可以通过提示工程来提高大语言模型的安全性,也可以赋能大语言模型,比如借助专业领域知识和外部工具来增强大语言模型能力。
基于对大语言模型的浓厚兴趣,我们编写了这份全新的提示工程指南,介绍了大语言模型相关的论文研究、学习指南、模型、讲座、参考资料、大语言模型能力以及与其他与提示工程相关的工具。
编译器和语言设计
https://www3.nd.edu/~dthain/compilerbook/
科技爱好者周刊(第 212 期):人生不短
人生很短,但是如果你知道,怎么利用好这些时间,它就不短。
人生刚好够实现自己的一个梦想,前提是你必须从一开始,就把所有精力专注于此。
如果你浪费时间,不够专注,那么你没做什么事,人生就结束了。
真正的问题不是人生短暂,而是我们浪费了太多时间。
最令人惊讶的是,人们并不重视自己的时间。你不会让别人偷走你的财产,但你却让别人偷走你的时间。
如果你听任自己为那些不重要的、随机出现的事情分心,那么即使你的寿命有一千年,你也会一事无成。
现代计算机的发明人冯·诺依曼,死于1957年,享年53岁。他一生都非常忙碌,各种事情都来找他。
他多次推迟自己想做的事情,总是说以后有时间再做,但又不说到底什么时候做。
举例来说,他曾经说,他想写一篇关于冯诺依曼代数的大论文,这是他自己开创的一个数学领域。但是,后来二战爆发了,他的兴趣发生了变化,他转而研究为战争服务的应用数学,还参与了政府的咨询和建议。
从二战爆发一直到1950年代,他的大部分时间都没有花在学术研究,而是花在为美国军方做政策咨询。
他的研究院和大学同事对此很惋惜。他们认为,他在浪费时间,浪费自己的才华,政策咨询完全可以交给别人做,他的数学天才应该用来完成别人做不到的学术研究。
他加入美国核能委员会不久,就被诊断出患有癌症。不到两年,他就死了。
起初他对自己的癌症还是乐观的,继续积极参与政府事务。但是治疗了一段时间,医生无能为力,明确告诉他剩下的时间不多了。
这时,他惊慌失措了,人生就要结束了,但是还有那么多没有做完的事情。他试图抓紧时间,集中精力完成正在研究的主题----自动机理论。但是太晚了,癌症的进展越来越快,他连这个研究也没有完成。
甚至就在这种时候,他还答应去耶鲁大学做一系列演讲,当然最后并没有实现。
他对于自动机理论有很大的抱负,认为这将是他一生最伟大的工作。这个领域也是完全由他创造的,结合了数理逻辑、信息论和生物学,对人类会产生重大影响。但是很可惜,他把其他事情放到了前面。
他去世后,同事们接受采访,再次发表评论,认为他的才华浪费了。他的一生中,真正用来工作的只有大约30年,但是最后10年的大部分时间,主要用于政府咨询项目,而没有花在那些只有他才能做的学术研究。
他本人并非不知道这一点,但就是这种性格,喜欢同时研究很多事情,一旦对某件事情产生了兴趣,就会放下手头的工作,推说稍后再回来接着做,可惜人生并没有为他留出"回过头再做"的时间。
我相信,人生也没有为你我留出这些时间。如果你听任时间浪费在各种琐碎的用途,那你就永久失去了这些时间。只有当你能够保护好自己的时间,专注于一个方向,人生才不会那么短暂。
有一句名言:编程是思考,而不是打字。多年编程后,我时常觉得自己打字太多,思考太少。
– 《如何控制编程的元认知?》
人类的语言就是用来描述问题的接口(interface)。你的语言越清晰准确,就越容易描述问题、解决问题。
– 《技术含量低一些》
我们创业失败的原因是,我们改变了自己的方针,从制造人们想要的产品转向制造我们希望人们想要的产品。
– Eric Migicovsky,智能手表 Pebble 的创始人
如何控制编程的元认知过程?
https://lambdaisland.com/blog/2022-02-17-the-fg-command
发布于 周四, 17 2022月 15 41:45:<>
作者:陈婷婷
有一句名言:编程是思考,而不是打字。在做这份工作足够长的时间后,有时,我觉得我打字太多了。无论人类是在思考还是打字,他们都会动脑筋,所以我相信“打字”这个词是一个隐喻:打字是指我们无意识地做的那种活动,通过我们的肌肉记忆,而不是通过我们刻意的注意力。我们中的许多人,有足够的经验,使用相当多的肌肉记忆。另一方面,我们在需要时是否使用了足够的思维?
我们人类在日常生活中会做出很多决定:像买车这样的决定,或者像命名一个函数这样的决定。进化使我们成为一种动物,我们可以将决策的某些部分委托给我们的潜意识,我们可以将其称为大脑中的背景过程。因此,我们可以将注意力集中在重要的事情上。问题是:如果潜意识做得不好怎么办?大多数时候,这没什么大不了的,将问题升级回前台思维可以解决它。例如,当您按下以评估表单,但错误地评估了错误的表单时。你检测到这一点,然后你用你的前景思维来决定下一步该做什么。然而,有时候,当你在开始工作之前就知道潜意识不能很好地处理工作时,你能做些什么来防止你的潜意识接管控制权?我们是否有任何类似于 linux命令 ,可以将进程从后台带到前台? e efg
我有些不好意思承认,虽然我已经编程了十年,但有时遇到一个bug,我的大脑先进入恐慌模式几个小时,然后又回到分析模式。为什么?我的理论是,当我发展了初级开发人员的技能时,我在恐慌模式下解决了我的问题:疯狂的搜索,反复试验等等。年复一年的经验训练我的行为和肌肉记忆在恐慌模式下进行调试。但是,现在我想解决这个问题。有两种方法可以帮助我控制我的潜意识:
向另一个人解释代码。(橡皮鸭法)
问自己一些预先准备好的问题。(德鲁克法)
远程工作教会了我橡皮鸭方法
与盖湾团队合作时,我们完全远程工作。有时,当我想找人讨论时,我需要等待。有几次,当我遇到一个错误并且我想寻求帮助时,我会写下有关代码、环境以及我如何尝试解决错误的所有细节。当我把我的错误报告粘贴到盖湾的通讯频道中并休息 15 分钟后,神奇的事情发生了:缪斯女神浮现在我的脑海中。我快速解决它并编辑我已经发布的消息。橡皮鸭方法真的有效!
实际上,我认为通过解释来思考的想法有不同的名称:橡皮鸭,识字编程,费曼技术等。它们都是相似的东西。
正确的问题就像你大脑上的fg命令
现在,当我遇到错误时,我会问自己三个问题:
我用科学的方法去追这个bug吗?
我是否对此问题范围有正确的系统视图?
我是否有必要的遥测工具?
当我编写函数、编写模块或准备部署时,我遇到了类似的问题:键入太多,思考太少。
以下是我为自己提出的一些问题,但仍然是alpha版本:
编写函数的问题:
我应该将命令和查询分开吗?
我是否为错误(如日志)编写条件设计?try/catch
我是否为条件或错误编写预防性设计?preassert
函数名称是否应该描述目的?
我是否在函数上添加一些合适的文档字符串?
编写模块的问题:
我是否应该显式指定此模块的 API,并使这些 API 明显不同于内部函数?
是否删除了所有不必要的死代码?
我是否设计或使用合适的 Clojure 记录来模拟域问题的一些不可变概念?
有关集成和部署的问题
我是否在域函数上添加适当的测试?
我是否在安装脚本上设计了适当的反馈消息?
某些手动设置步骤是否可以替换为自动化脚本?
使用记录的问题需要更多解释:对于一些不可变的概念,如 uri、date 或连接,用一些精心设计的记录来表示它们将使实现细节隐藏在适当的层中。这些不可变的概念往往具有一组固定的相关操作,可以使用 进行建模。Protocol
我发现解释或提问都可以有效地帮助我。它们帮助我训练我的潜意识,我使用的分析思维越多,我得到的发散思维就越好。您是否也在使用一些问题?告诉我们您的命令。