文章目录
- 前言
- 泛读
- 相关知识
- GPT
- BERT
- T5
- 小结
- 背景介绍
- 主要贡献和创新点
- GLM 6B
- 精读
- 自定义Mask
- 模型量化
- 1TB 的中英双语指令微调
- RLHF
- PEFT
- 训练策略
- 实验分析与讨论
- 模型参数
- 六个指标
- 其他测评结果
- 代码复现(6B)
- 环境准备
- 运行调用
- 代码调用
- 网页服务
- 命令行调用
- 模型微调
前言
首发公众号:学姐带你学AI
本课程来自深度之眼《大模型——前沿论文带读训练营》公开课,部分截图来自课程视频。
文章标题:GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL
Glm-130B:开放的双语预训练模型
作者:Hugo Touvron等
单位:清华大学
发表时间:ICLR 2023
项目地址:https://github.com/THUDM/GLM-130B
这个模型有个轻量化版本GLM-6B
泛读
这个模型是清华大学KEG实验室+智谱AI提出来的,因此对中文的支持效果比较明显。
相关知识
要get这个模型的创新要了解三个(类)模型的优缺点。
GPT
GPT堆叠了12个解码器层。由于在这种设置中没有编码器,这些解码器层将不会有普通transformer解码器层所具有的编码器-解码器注意力子层。但是,它仍具有自注意力层。
属于自回归模型,主要优点是可用来做生成任务。
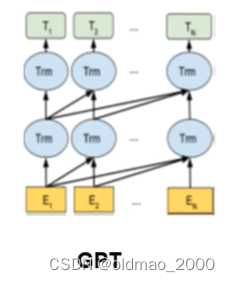
从其模型结构图可以看到,模型只能看到当前token以及之前的token,然后预测后面的token。
简单的说就是吃一句话(输入):
u
=
{
u
1
,
⋯
,
u
n
}
u=\{u_1,\cdots ,u_n\}
u={u1,⋯,un}
转化为词向量:
h
0
=
U
W
e
+
W
p
h_0 = UW_e+W_p
h0=UWe+Wp
循环经过若干个Decoder(就是Transformer_block):
h
l
=
transformer_block
(
h
l
−
1
)
∀
i
∈
[
1
,
n
]
h_l=\text{transformer\_block}(h_{l-1})\quad \forall i\in [1,n]
hl=transformer_block(hl−1)∀i∈[1,n]
最后经过softmax得到下一个词的概率:
P
(
u
)
=
softmax
(
h
n
W
e
T
)
P(u)=\text{softmax}(h_nW_e^T)
P(u)=softmax(hnWeT)
以上步骤中
U
=
(
u
−
k
,
⋯
,
u
−
1
)
U=(u_{-k},\cdots,u_{-1})
U=(u−k,⋯,u−1)是token的上下文向量表示;
n
n
n是模型的Decoder层数;
W
e
W_e
We是token的表征矩阵;
W
p
W_p
Wp是位置表征矩阵。
生成方式不合适做并行。
这里为什么GPT不用Transformer的Encoder进行训练?
因为BERT类模型属于深层双向预测语言模型,在预测中存在自己看见自己问题(要预测的下一个词在给定的序列中已经出现)达不到预期效果。
例如,模型的输入是ABCD四个token,这里以B这个token为视角,进入第二层后:
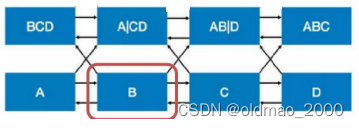
由于双向的关系,消息传播后(看箭头),在第二层对应位置可以看到信息如上图所示。
进入第三层后,红框对应的位置从边上得到了B自身这个token的信息,失去了让模型去学习预测B的意义。
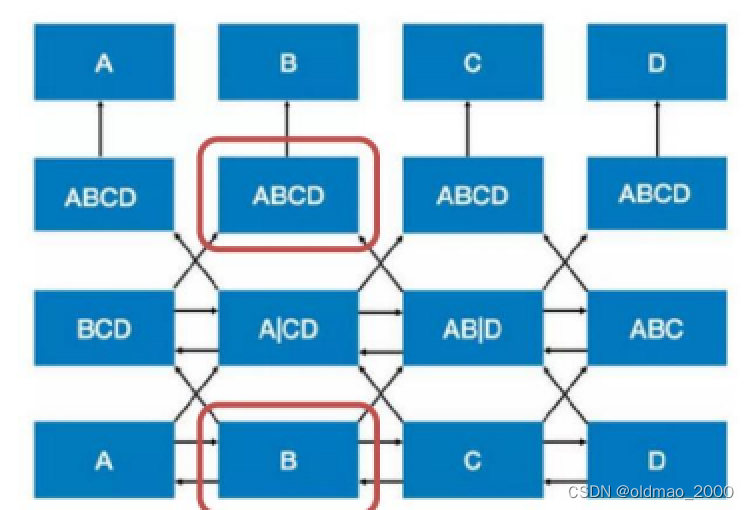
Bert提出采用Masked Language Model(MLM)的方式来进行训练。
BERT
从上面的推理可以看到,自编码类的BERT使用堆叠的双向Transformer Encoder,在所有层中共同依赖于左右上下文。
■基础版是12个Encoder (12层 );
■高级版24个Encoder (24层 )
由于MLM的训练方式,BERT模型更加擅长做完形填空,也就是对语言的理解。
T5
T5是一个完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,
常用于有条件的生成任务 (conditional generation),以下就示例就包含了:翻译,问答,推理,摘要。
也就是说这类模型既可以做生成式任务,也可以做理解式任务。
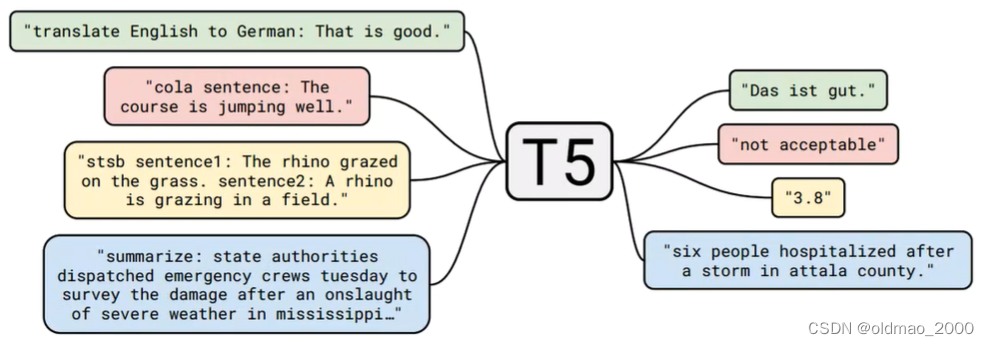
这样的结构虽然结合了上面两种模型的优点(要达到RoBERTa的指标),但是带来的问题也是显而易见的,就是参数量增大,往小的说是训练成本高、往大了说是不环保,不利于实现碳中和。这个也是GLM解决的一个痛点之一。
小结
时下主流的预训练框架可以分为三种:
■autoregressive 自回归模型的代表是GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation)。
■autoencoding 自编码模型是通过某个降噪目标(如掩码语言模型)训练的语言编码器,如BERT、ALBERT、DeBERTa、RoBERTa。自编码模型擅长自然语言理解任务(NLU,natural language understanding tasks),常被用来生成句子的上下文表示。
■encoder-decoder 则是一个完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,常用于有条件的生成任务 (conditional generation)
GLM的思想就是想要结合以上几种模型的优点,又不增加太多的参数量。
当下的ChatGPT表现出来的不单单可以生成,还能做问答和理解,其原因是大模型的涌现现象,吃数据到一定程度,生成的答案可以达到问答和理解的效果。
背景介绍
GLM-130B是一个双语(英语和汉语)预训练的语言模型,具有1300亿个参数,使用了General Language Model (GLM)的算法。
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。
GLM-130B可以支持多种自然语言处理任务,如文本生成、文本理解、文本分类、文本摘要等,应用场景宽泛,如机器翻译、对话系统、知识图谱、搜索引擎、内容生成等。
GLM-130B在多个英语和汉语的基准测试中优于其他模型,如GPT-3 175B、OPT-175B、BLOOM-176B、ERNIE TITAN 3.0 260B等。
重点:开源模型
ChatGLM内测申请:https://chatglm.cn/
问:为什么要使用英文?
有研究发现,使用代码作为语料喂给预训练模型能提高模型的推理能力,代码语料通常是英文的。
主要贡献和创新点
■GLM-130B是目前较大的开源双语预训练模型,而GLM-6B也是可以在单个服务器上单张GPU上支持推理的大模型。
■GLM-130B使用了GLM算法,实现了双向密集连接的模型结构,提高了模型的表达能力和泛化能力。
■GLM-130B在训练过程中遇到了多种技术和工程挑战,如损失波动和不收敛等,提出了有效的解决方案,并开源了训练代码和日志(48页的论文里面有很大部分是这块内容)。
■GLM-130B利用了一种独特的缩放性质,实现了INT4量化,几乎没有精度损失,并且支持多种硬件平台(国产平台可用,不一定要英伟达)。
GLM 6B
ChatGLM-6B参数量是62亿,支持中英双语,可在单张 2080Ti 上进行inference。FP16半精度浮点模式下需要13GB显存,如果使用INT4模式,大概只需要7GB即可。生成序列长度达到2048,并做了人类意图对齐训练。
精读
先回顾前面讲的三个模型以及GLM的改进
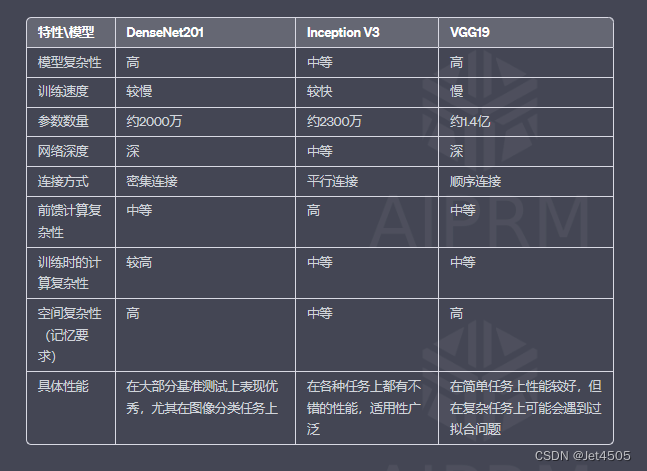
| 模型名称 | 训练目标 | 模型结构 |
|---|---|---|
| GPT | 是从左到右的文本生成,无条件生成 | 单向注意力,无法利用下文信息 |
| BERT | 是对文本进行随机掩码,然后预测被掩码的词 | 双向注意力,可同时感知上下文(理解任务强,但不适合生成任务) |
| T5 | 是接受一段文本,从左到右的生成另一段文本,有条件生成(输入文本就是限制) | 编码器带双向注意力,解码器带单向注意力,可以同时胜任理解和生成任务,但参数量大 |
| GLM | 通过自由组合 MASK 和文本来兼容三种任务(无条件生成,自回归,有条件生成) | 自定义Mask矩阵 |
可以看到GLM要把三个模型优点结合起来,靠的就是自定义的MASK,其主要思想如下表:
| 等价模型 | MASK形式 |
|---|---|
| GPT | 当全部的文本都被掩码时,空格填充任务就等价于无条件语言生成任务。 |
| BERT | 当被掩码的片段长度为1的时候,空格填充任务等价于掩码语言建模 |
| T5 | 当将文本1和文本2拼接在一起,然后将文本2整体掩码掉,空格填充任务就等价于条件语言生成任务。 |
自定义Mask
假定有一句话表示为:
x
1
x
2
x
3
x
4
x
5
x
6
x_1\quad x_2\quad x_3\quad x_4\quad x_5\quad x_6
x1x2x3x4x5x6
对这句话随机采样得到一些片段(span),注意是随机采样,假设结果是2个片段,分别用绿色和黄色标记:
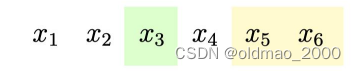
将采样后的片段拿出来后原来一句话就分成了两耙:
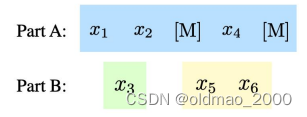
然后用以下方式进行训练:
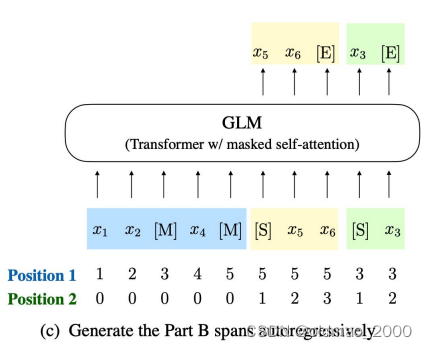
下面蓝色部分是GLM中Encoder的输入,后面黄色和绿色部分对应的是Decoder的输入。
学过NLP的都知道MSE几个字母分别代表mask、start、end。
上面输出中,由于黄色部分是根据前面蓝色部分(相当于条件)生成的,因此这个部分相当于T5模型的生成结果;绿色部分只遮挡了一个词,前面的信息都可以看见,因此相当于BERT模型的生成结果,整个自注意力掩码如下图所示:
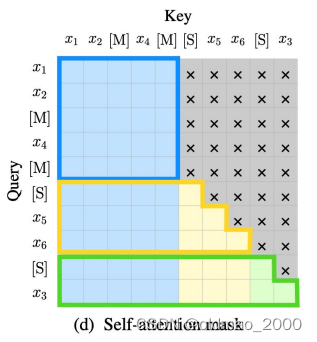
蓝色方框部分所有token都是可以看到上下文的;
黄色部分能看到蓝色所有token以及黄色的上文部分;
绿色部分可以看到蓝色和黄色所有token。
更准确的说:
Part A中的词彼此可见(图(d)中蓝色框中的区域)
Part B中的词单向可见(图(d)淡黄色的区域,绿色其实也是,但是绿色部分只有一个词)
Part B可见Part A(图(d)中红色框中的区域)
其余不可见(图(d)中灰色的区域)
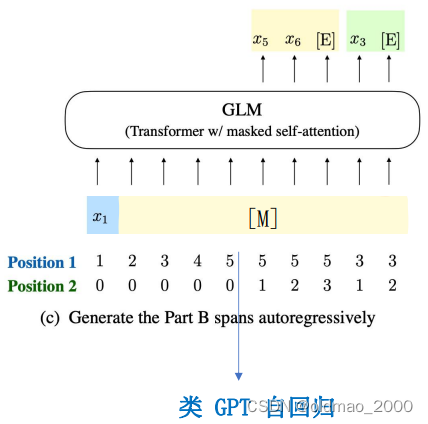
以上是GLM模拟T5和BERT的方法,如果将所有token都mask掉,那么就模拟了GPT模型:
模型量化
这个的技术的贡献是减少了显存的使用。主要做法就是使用低精度的INT4类型来保存模型,当然这样做的前提是保证不降低大幅度模型性能为代价。
现实生活中也有对应的例子:MP3
一首320kbps的MP3大概会有8-12M,而一首192kbps的MP3体积会缩小一倍,对于普通人(木耳)而言,并不太能分辨出后者在音质上有所降低。
这里我也深有体会,之前做数据处理,读取数据进内存的时候由于数据较大,内存直接爆了,请教大佬后才明白,默认读取到内存的数据类型是FLOAT型,占的位置较大,解决方案就是读取到内存之前将类型转化为INT后就好了,由于数据本来就是整数,没有必要保存为类似1.000000的格式。
1TB 的中英双语指令微调
实际上就是让模型看各种类型的输入,就好比和chatGPT进行聊天时的输入,同一个问题有各种问法,难的是如何让模型去理解问题。如何(半)自动化的构造输入指令,对于提升模型的泛化性能非常有帮助。
RLHF
根据人类反馈进行强化学习。
reinforcement learning from human feedback
该技术可以减少语料标注成本,并让模型逼近人类表现(或者说模型会变成人类期待的样子)
PEFT
Parameter Efficient Fine-Tuning
是一种可以在显存较少的情况下进行微调的技术。
具体介绍可以参考:https://zhuanlan.zhihu.com/p/618894319?utm_id=0
训练策略
具体看论文附录。
GLM-130B在一个由96个NVIDIA DGX-A100(8 * 40G)GPU节点组成的集群上进行训练,每个节点有8张A100 GPU,每张GPU负责1.35亿个参数;
GLM-130B使用了ZeRO (Rajbhandari et al., 2020)作为优化器,它可以有效地减少显存占用和通信开销,提高训练效率;
GLM-130B使用了混合精度训练(Mixed Precision Training)(Micikevicius et al.,2018)和梯度累积(Gradient Accumulation)(Chen et al., 2016)来提高训练速度和稳定。
实验分析与讨论
模型参数
GLM-130B的编码器和解码器都有96层,每层有64个注意力头,每个头的维度是128,隐藏层的维度是8192(
64
×
128
64\times 128
64×128);
GLM-130B的总参数量是1300亿(130B的由来),其中编码器占了60%,解码器占了40%;
GLM-130B使用了字节对编码(BPE)(Sennrich et al., 2016)作为词表,共有50万个词,其中25万个是英语词,25万个是汉语词。
六个指标
准确性,鲁棒性,公平性,数字越大越好:
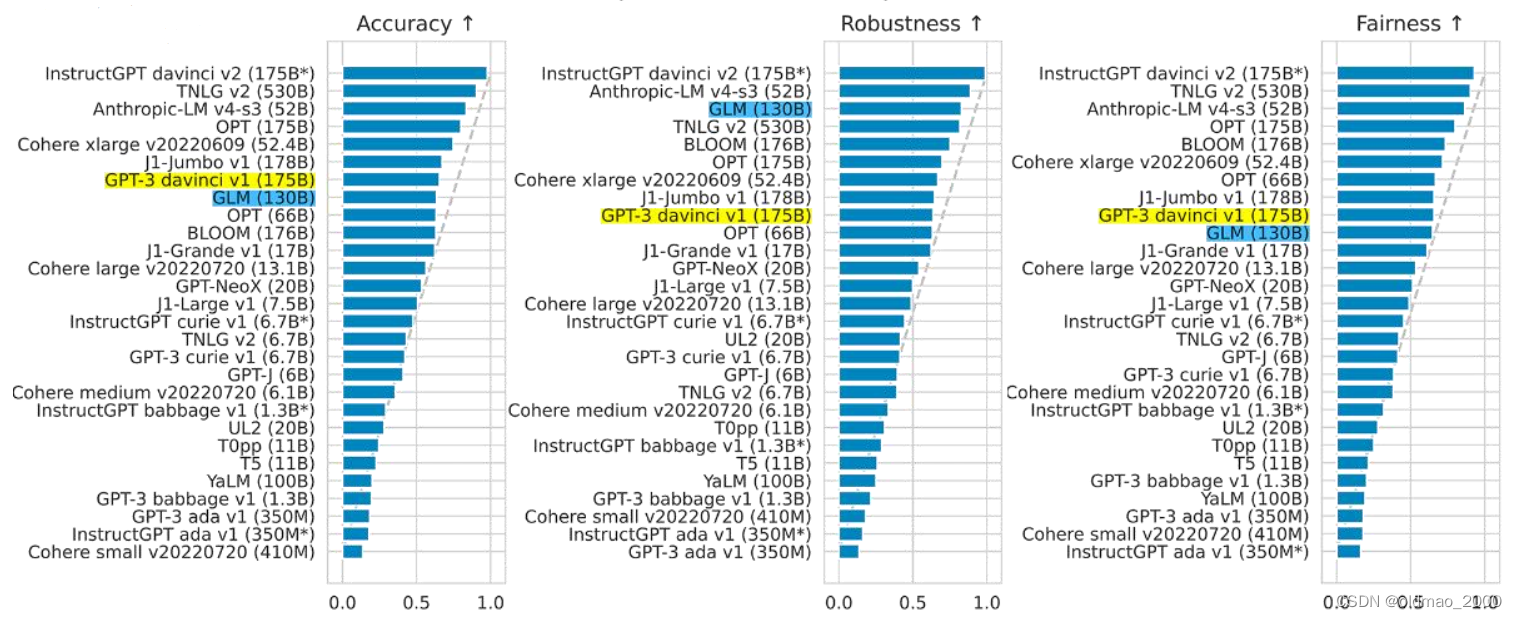
以上几个指标里面有一个Cohere开头的模型貌似表示也很亮眼。
校准误差、偏见性、有毒性(涉及黄赌毒言论),数字越小越好,最后一个指标GPT大概是由于语料上占优,因此性能较好
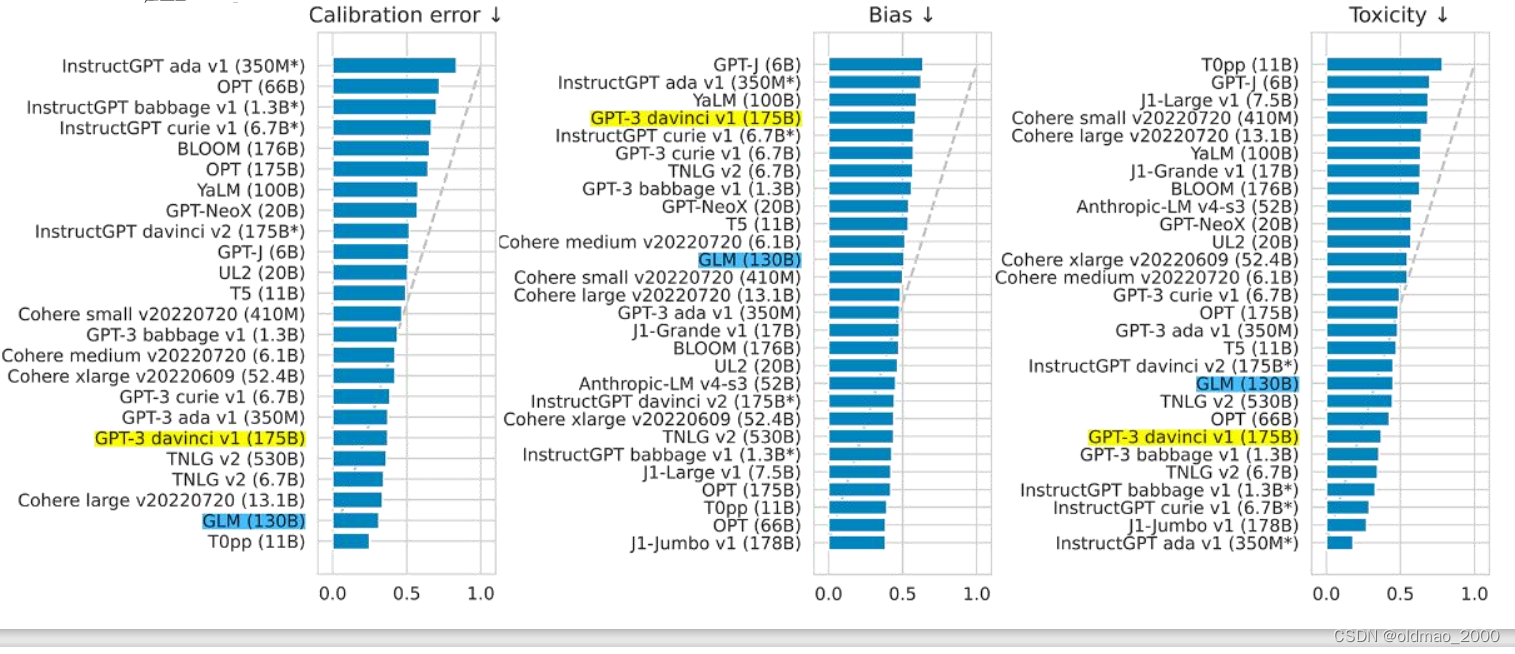
以上结果来自斯坦福世界主流导向评测:https://arxiv.org/pdf/2211.09110.pdf
其中的图26(p55)
GLM是这个报告中,中国唯一入选模型,准确性、恶意性与GPT-3持平,鲁棒性和校准误差在所有模型中表现最佳。
其他测评结果
某第三方基金开放评测结果,具备70%ChatGPT能力水平
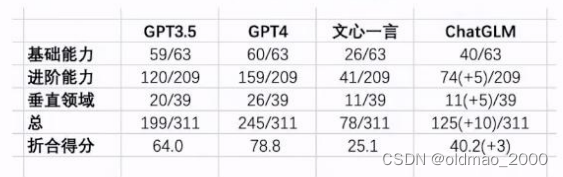
国内大模型能力评测
1)在中文语境下对古诗文理解、成语等理解更准确
2)在命题写作(续写、语言风格模仿等)中表现明显较优
3)答案更正能力更强
4)上下文理解能力明显较
5)代码输出附加了解释说明
6)暂无明显无法回答的客观问题
7)数学计算和逻辑推理能力略优
代码复现(6B)
环境准备
https://github.com/pengwei-iie/ChatGLM-6B
服务器安装配置见上一篇大模型论文复现笔记
打开终端,创建一个项目文件夹:
mkdir GLM6B
使用cd进入该文件夹后,clone项目:
git clone https://github.com/pengwei-iie/ChatGLM-6B.git
其中ptuning目录是模型微调代码,但是微调数据集需要单独另外下载,具体后面讲。
cli_demo.py
web_demo.py
这两个是用来做预测的代码。
从hugging face(https://huggingface.co/THUDM/chatglm-6b)下载模型到本地,下载地址:https://huggingface.co/THUDM/chatglm-6b/tree/main,可下载到另外一个目录,文件比较大,务必确认下载是否文件是否完整,否则会出现加载失败的错误。
安装依赖包:
pip install -r requirement.txt
运行调用
代码调用
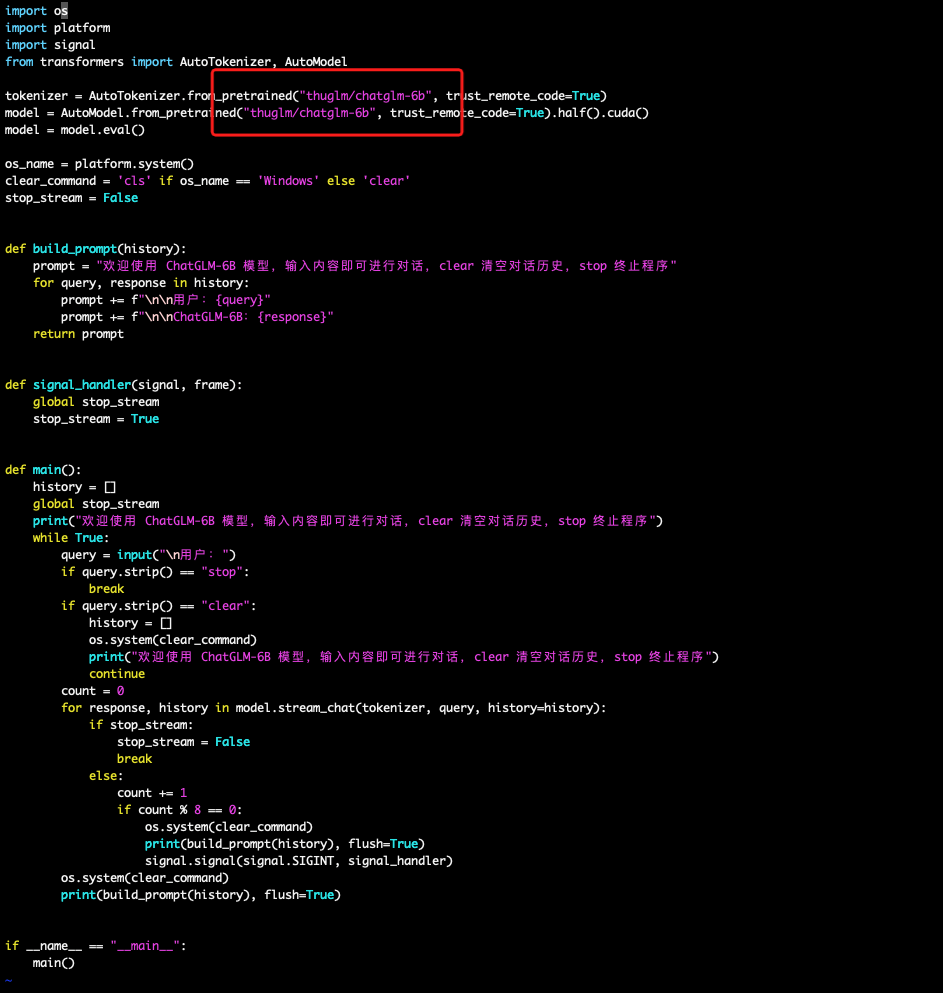
代码中加载分词器和模型的部分可替换成为本地文件路径,否则会自动从hugging face远程下载。
history是历史对话信息
from transformers import AutoTokenizer,AutoModel
#
tokenizer=AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model AutoModel.from_pretrained("THUDM/chatglm-6b",trust_remote_code=True).half().cuda()
modelmodel.eval()
response,history=model.chat(tokenizer,"你好",history=[])
>>print(response)
网页服务
网页服务基于Gradio,因此需要先安装
pip install gradio
然后就可以启动网页服务
python web_demo.py
会得到一个网址,复制到浏览器中即可进行对话。
命令行调用
主要是运行cli_demo.py,也是需要改里面路径。
python cli_demo.py
显示加载模型后会显示:
“欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序”
这里默认只能提问英文。
模型还可以使用API 进行调用,具体看github说明,这里不赘述。
模型微调
原说明文件地址为:https://github.com/pengwei-iie/ChatGLM-6B/blob/main/ptuning/README.md
微调数据集下载地址为:
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
下载的文件名称为:
AdvertiseGen.tar.gz
大小约16M,里面是两个json文件
该数据集字典包含两个字段:content、summary。
任务是根据content字段,生成一段广告词summary。
以下为单个样本格式,星号可以看做分隔符,井号可看做冒号。
{
"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞",
"summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。"
}
也可以根据以上格式准备个性化领域数据来微调模型。
将下载后的AdvertiseGen.tar.gz解压缩到模型所在ptuning文件夹下的AdvertiseGen文件夹内。
打开train.sh
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
| 关键字 | 含义 |
|---|---|
| PRE_SEQ_LEN | 训练序列的长度设置,越长需要内存越大 |
| LR | 学习率 |
| train_file | 训练数据集的位置 |
| validation_file | 验证数据集的位置 |
| prompt_column | prompt字段对应输入,与json中关键字对应 |
| response_column | 输出字段,与json中关键字对应 |
| model_name_or_path | 模型存放路径 |
| output_dir | 输出路径 |
| per_device_train_batch_size | 设置越大内存需要越大,训练识别可以尝试改小点,这里用的1 |
然后运行:
bash train.sh
如果要根据对话语料进行训练,可使用
bash train_chat.sh
这个命令相对于上面的train.sh多了一个history_column参数用来指定保存对话历史的字段名,另外一些参数的数字会有变化,例如max_source_length 会设置的大些,因为包含历史记录的对话序列会比较长。