前言
终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点
- 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开
- 去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇ChatGPT原理文章下面留言:“点赞,十年前看你的svm懂了,但感觉之后好多年没写了,还有最近的AI绘画 stable diffusion 相关也可以写一下以及相关的采样加速算法
我当时回复到:哈,十年之前了啊,欢迎回来,感谢老读者、老朋友
确实非常非常多的朋友都看过我那篇SVM笔记,影响力巨大,但SVM笔记之后,也还是写了很多新的博客/文章滴,包括但不限于:xgboost、CNN、RNN、LSTM、BERT等
今后基本每季度都有更新的计划,欢迎常来
关于Stable Diffusion,可以先看下这篇图解Stable Diffusion的文章”(此篇文章也是本文的重要参考之一) - 今年3月中旬,当OpenAI宣称GPT4具备了CV多模态的能力之后,让我对AI绘画和CV多模态有了更强的动力去研究探索,并把背后的技术细节写出来
其实当时就想写了,但当时因为写各种开源平替模型的原理、部署、微调去了,所以一直没来得及写,包括之前计划的100篇论文也因此耽搁
4.23,我所讲的ChatGPT原理课开课之后,终于有时间开写这篇多模态博客,然想写清楚stable diffusion和midjourney背后的技术细节,不得不先从扩散模型开始,于此便有了上一篇《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer》
援引上一篇文章的这段话“AI绘画随着去年stable diffusion和Midjourney的推出,使得文生图火爆异常,各种游戏的角色设计、网上店铺的商品/页面设计都用上了AI绘画这样的工具,更有不少朋友利用AI绘画取得了不少的创收,省时省力还能赚钱,真香”
沿着上文之后,本文将写清楚下面表格中带下划线的模型
| 1月 | 3月 | 4月 | 5月 | 6月 | 8月 | 10月 | 11月 | |
| 2020 | DETR | DDPM | DDIM VisionTransformer | |||||
| 2021 | CLIP DALL·E | SwinTransformer | MAE SwinTransformerV2 | |||||
| 2022 | BLIP | DALL·E 2 | StableDiffusion BEiT-3 Midjourney V3 | |||||
| 2023 | BLIP2 | VisualChatGPT GPT4 Midjourney V5 | SAM(Segment Anything Model) |
且过程中会顺带介绍MiniGPT-4、VisualGPT到HuggingGPT、AutoGPT这几个模型
第一部分 从CLIP到BLIP1/BLIP2、DALLE/DALLE 2
1.1 CLIP:基于对比文本-图像对的预训练方法
我第一次见识到CLIP这个论文的时候,当时的第一反应是,特么也太强悍了..
CLIP由OpenAI在2021年1月发布
- 通过超大规模模型预训练提取视觉特征,进行图片和文本之间的对比学习(简单粗暴理解就是发微博/朋友圈时,人喜欢发一段文字然后再配一张或几张图,CLIP便是学习这种对应关系)
- 且预训练好之后不微调直接推理(即zero-shot,用见过的图片特征去判断没见过的图片的类别,而不用下游任务训练集进行微调),使得在ImageNet数据集上,CLIP模型在不使用ImageNet数据集的任何一张图片进行训练的的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手(在ImageNet上zero-shot精度为76.2%,这在之前一度被认为是不可能的)
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text。WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一(后续在WIT上还孕育出了DALL-E模型)
其训练过程为:
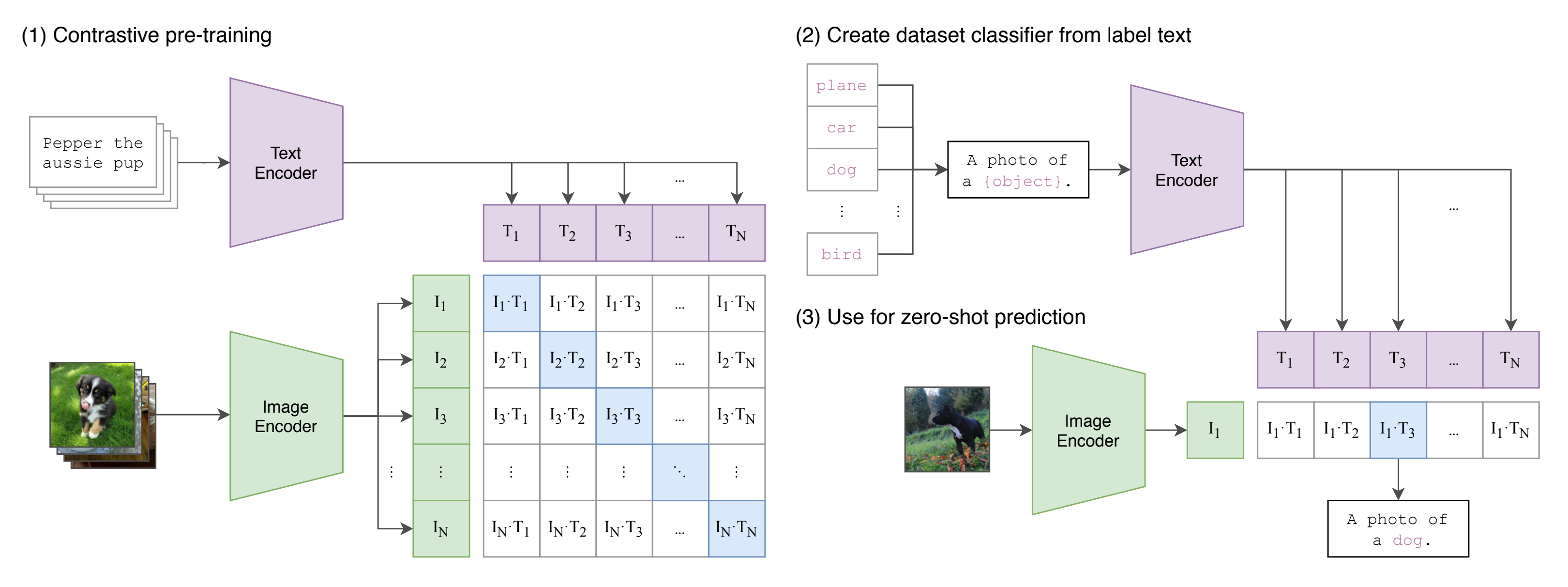
- 如下图的第一步所示,CLIP的输入是一对对配对好的的图片-文本对(比如输入是一张狗的图片,对应文本也表示这是一只狗),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征。然后在这些输出的文字特征和图片特征上进行对比学习
假如模型输入的是n对图片-文本对,那么这n对互相配对的图像–文本对是正样本(下图输出特征矩阵对角线上标识蓝色的部位),其它对样本都是负样本,这样模型的训练过程就是最大化n个正样本的相似度,同时最小化
Text Encoder可以采用NLP中常用的text transformer模型
而Image Encoder可以采用常用CNN模型或者vision transformer等模型
相似度是计算文本特征和图像特征的余弦相似性cosine similarity
之后,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练和微调,其实现zero-shot分类只需要简单的两步,如下第2、3点所示 - 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为n,那么将得到n个文本特征
- 将要预测的图像送入Image Encoder得到图像特征,然后与n个文本特征计算缩放的余弦相似度(和训练过程保持一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果
进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率
以下是对应的伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - 输入图片维度
# T[n, l] - 输入文本维度,l表示序列长度
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征d_e,并进行l2归一化,保持数据尺度的一致性
# 多模态embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss
loss = (loss_i + loss_t)/2 # 对称式的目标函数2021年10月,Accomplice发布的disco diffusion,便是第一个结合CLIP模型和diffusion模型的AI开源绘画工具,其内核便是采用的CLIP引导扩散模型(CLIP-Guided diffusion model)
且后续有很多基于CLIP的一系列改进模型,比如Lseg、GroupViT、ViLD、GLIP
1.2 从BLIP1、BLIP2到miniGPT4
1.2.1 BLIP1:通过encoder-decoder统一理解与生成任务
简单来讲,BLIP的主要特点是结合了encoder和decoder,形成了统一的理解和生成多模态模型。再利用BLIP进行后续工作的时候,既可以使用其理解的能力(encoder),又可以利用其生成的能力(decoder),拓展了多模态模型的应用

// 待更
1.2.2 BLIP2
// 待更
1.2.3 MiniGPT4
模型架构:基于LLaMA微调的Vicuna + BLIP2 + 线性投影层
MiniGPT-4具有许多类似于GPT-4所展示的功能,如详细的图像描述生成和从手写草稿创建网站,以及根据给定图像编写灵感的故事和诗歌,为图像中显示的问题提供解决方案,比如教用户如何根据食物照片烹饪等
miniGPT4的模型架构由一个语言模型拼接一个视觉模型,最后加一个线性投影层来对齐,具体而言

-
它先是使用基于LLaMA微调的小羊驼Vicuna,作为语言解码器
-
在视觉感知方面,采用了与BLIP-2相同的预训练视觉组件(该组件由EVA-CLIP[13]的ViT- G/14和Q-Former组成)
-
再之后,增加了一个单一的投影层,将编码的视觉特征与语言模型小羊驼对齐,并冻结所有其他视觉和语言组件
模型训练:预训练(500万图像文本对)-微调
训练上,还是经典的预训练-微调模式
- 在整个预训练过程中,无论是预训练的视觉编码器还是LLM都保持冻结状态,只有线性投影层被预训练。具体是使用Conceptual Caption、SBU和LAION的组合数据集来训练我们的模型,历经2万个训练步骤,批大小为256,覆盖了大约500万对图像-文本,整个过程花费大约10小时,且使用的4个A100 (80GB) gpu
- 然而,简单地将视觉特征与LLM对齐不足以训练出像聊天机器人那样具有视觉会话能力的高性能模型,并且原始图像-文本对背后的噪声可能导致语言输出不连贯。因此,我们收集了另外3500个高质量对齐的图像-文本对,用设计好的会话模板进一步微调模型(只需要400个训练步骤,批量大小为12,使用单个A100 GPU最终7分钟即可完成),以提高生成语言的自然度及其可用性
1.3 从DALLE到DALLE 2
1.3.1 DALL-E
// 待更
1.3.2 DALL-E 2
DALL-E 2主要由两部分组成
- 第一部分是Prior:将用户输入转换为图像的表示,接受文本标签并创建CLIP图像嵌入
其中使用到的文本和图像嵌入来自此前介绍过的CLIP(对比语言-图像预训练)的网络,为输入的图像返回最佳的标题。它所做的事情与DALL-E 2所做的相反——它是将图像转换为文本,而DALL-E 2是将文本转换为图像。引入CLIP的目的是为了学习物体的视觉和文字表示之间的联系 - 第二部分是将这种表示转换为实际的照片(称为Decoder):其接受CLIP图像嵌入并生成图像

模型训练完成之后,推理的流程如下:
- 输入的文本被转化为使用神经网络的CLIP文本嵌入。
- 使用主成分分析(Principal Component Analysis)降低文本嵌入的维度。
- 使用文本嵌入创建图像嵌入。
- 进入Decoder步骤后,扩散模型被用来将图像嵌入转化为图像。
- 图像被从64×64放大到256×256,最后使用卷积神经网络放大到1024×1024
// 待更..
第二部分 通俗理解stable diffusion
// 待更
参考文献与推荐阅读
- Learning Transferable Visual Models From Natural Language Supervision
CLIP原始论文 - CLIP 论文逐段精读,这是针对该视频解读的笔记之一:CLIP和改进工作串讲
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP原始论文 - 理解DALL·E 2, Stable Diffusion和 Midjourney工作原理
首发之后的创作、修改、新增记录
- 端午假期三天,持续完善BLIP/BLIP2、DALLE/DALLE 2等相关的内容