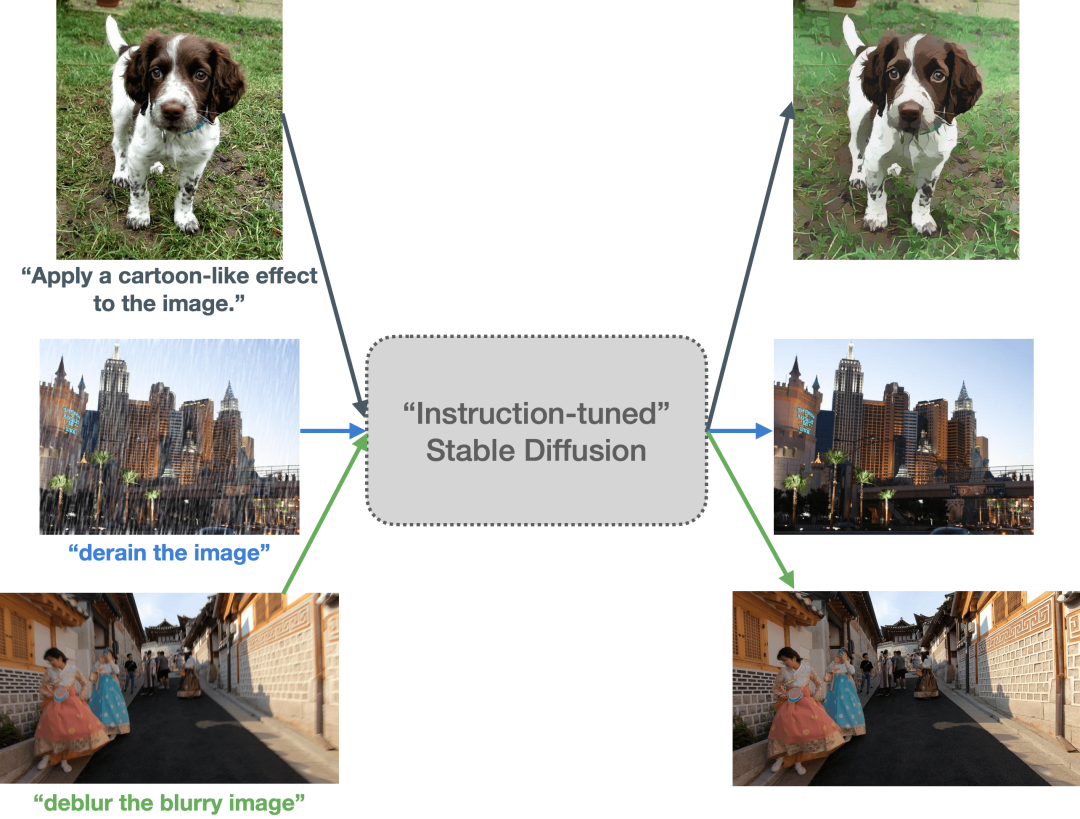
本文主要探讨如何使用指令微调的方法教会 Stable Diffusion 按照指令 PS 图像。这样,我们 Stable Diffusion 就能听得懂人话,并根据要求对输入图像进行相应操作,如: 将输入的自然图像卡通化 。
 |
|---|
| 图 1:我们探索了 Stable Diffusion 的指令微调能力。这里,我们使用不同的图像和提示对一个指令微调后的 Stable Diffusion 模型进行了测试。微调后的模型似乎能够理解输入中的图像操作指令。(建议放大并以彩色显示,以获得最佳视觉效果) |
InstructPix2Pix: Learning to Follow Image Editing Instructions 一文首次提出了这种教 Stable Diffusion 按照用户指令 编辑 输入图像的想法。本文我们将讨论如何拓展 InstructPix2Pix 的训练策略以使其能够理解并执行更特定的指令任务,如图像翻译 (如卡通化) 、底层图像处理 (如图像除雨) 等。本文接下来的部分安排如下:
指令微调简介
本工作的灵感来源
数据集准备
训练实验及结果
潜在的应用及其限制
开放性问题
你可在原文找到我们的代码、预训练模型及数据集。
引言与动机
指令微调是一种有监督训练方法,用于教授语言模型按照指令完成任务的能力。该方法最早由谷歌在 Fine-tuned Language Models Are Zero-Shot Learners (FLAN) 一文中提出。最近大家耳熟能详的 Alpaca、FLAN V2 等工作都充分证明了指令微调对很多任务都有助益。
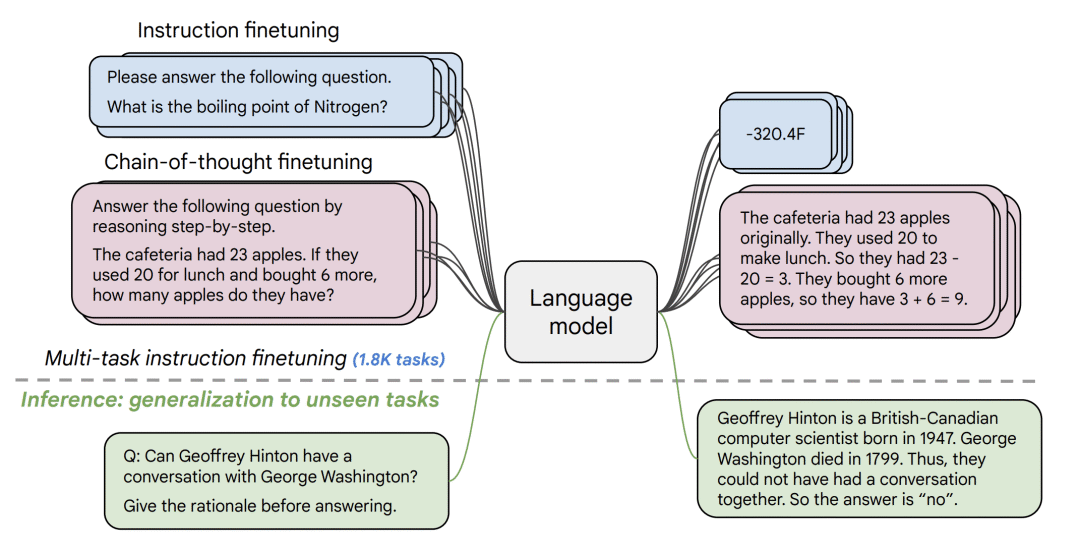
下图展示了指令微调的一种形式。在 FLAN V2 论文 中,作者在一个样本集上对预训练语言模型 (如 T5) 进行了微调,如下图所示。
 |
|---|
| 图 2: FLAN V2 示意图 (摘自 FLAN V2 论文)。 |
使用这种方法,我们可以创建一个涵盖多种不同任务的训练集,并在此数据集上进行微调,因此指令微调可用于多任务场景:
| 输入 | 标签 | 任务 |
|---|---|---|
| Predict the sentiment of the following sentence: “The movie was pretty amazing. I could not turn around my eyes even for a second.” | Positive | Sentiment analysis / Sequence classification |
| Please answer the following question. What is the boiling point of Nitrogen? | 320.4F | Question answering |
| Translate the following English sentence into German: “I have a cat.” | Ich habe eine Katze. | Machine translation |
| … | … | … |
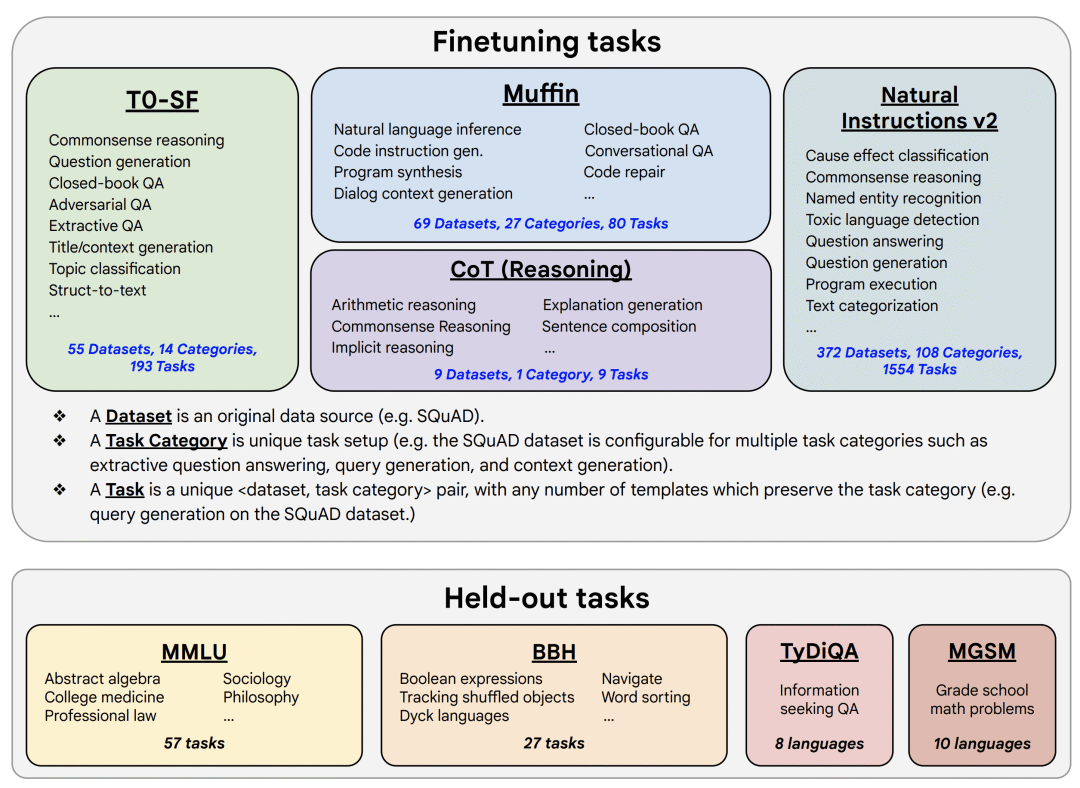
在该理念的指导下,FLAN V2 的作者对含有数千个任务的混合数据集进行了指令微调,以达成对未见任务的零样本泛化:
 |
|---|
| 图 3: FLAN V2 用于训练与测试的混合任务集 (图来自 FLAN V2 论文)。 |
我们这项工作背后的灵感,部分来自于 FLAN,部分来自 InstructPix2Pix。我们想探索能否通过特定指令来提示 Stable Diffusion,使其根据我们的要求处理输入图像。
预训练的 InstructPix2Pix 模型 擅长领会并执行一般性指令,对图像操作之类的特定指令可能并不擅长:
 |
|---|
| 图 4: 我们可以看到,对同一幅输入图像(左列),与预训练的 InstructPix2Pix 模型(中间列)相比,我们的模型(右列)能更忠实地执行“卡通化”指令。第一行结果很有意思,这里,预训练的 InstructPix2Pix 模型很显然失败了。建议放大并以彩色显示,以获得最佳视觉效果。 |
但我们仍然可以利用在 InstructPix2Pix 上的一些经验和观察来帮助我们做得更好。
另外,卡通化、图像去噪 以及 图像除雨 等任务的公开数据集比较容易获取,所以我们能比较轻松地基于它们构建指令提示数据集 (该做法的灵感来自于 FLAN V2)。这样,我们就能够将 FLAN V2 中提出的指令模板思想迁移到本工作中。
数据集准备
卡通化
刚开始,我们对 InstructPix2Pix 进行了实验,提示其对输入图像进行卡通化,效果不及预期。我们尝试了各种推理超参数组合 (如图像引导比 (image guidance scale) 以及推理步数),但结果始终不理想。这促使我们开始寻求不同的处理这个问题的方式。
正如上一节所述,我们希望结合以下两个工作的优势:
(1) InstructPix2Pix 的训练方法,以及
(2) FLAN 的超灵活的创建指令提示数据集模板的方法。
首先我们需要为卡通化任务创建一个指令提示数据集。图 5 展示了我们创建数据集的流水线:
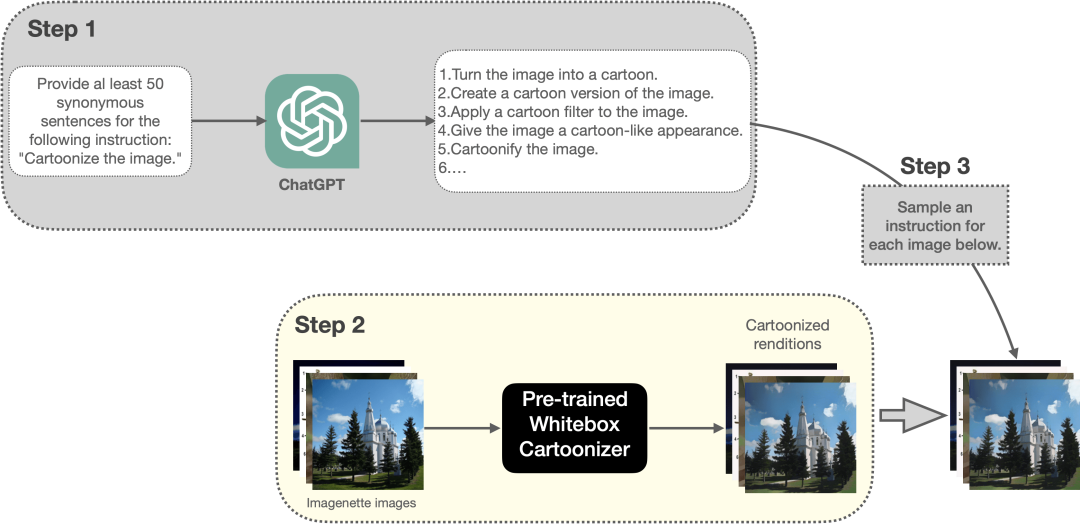 |
|---|
| 图 5: 本文用于创建卡通化训练数据集的流水线(建议放大并以彩色显示,以获得最佳视觉效果)。 |
其主要步骤如下:
请 ChatGPT 为 “Cartoonize the image.” 这一指令生成 50 个同义表述。
然后利用预训练的 Whitebox CartoonGAN 模型对 Imagenette 数据集 的一个随机子集 (5000 个样本) 中的每幅图像生成对应的卡通化图像。在训练时,这些卡通化的图像将作为标签使用。因此,在某种程度上,这其实相当于将 Whitebox CartoonGAN 模型学到的技能迁移到我们的模型中。
然后我们按照如下格式组织训练样本:
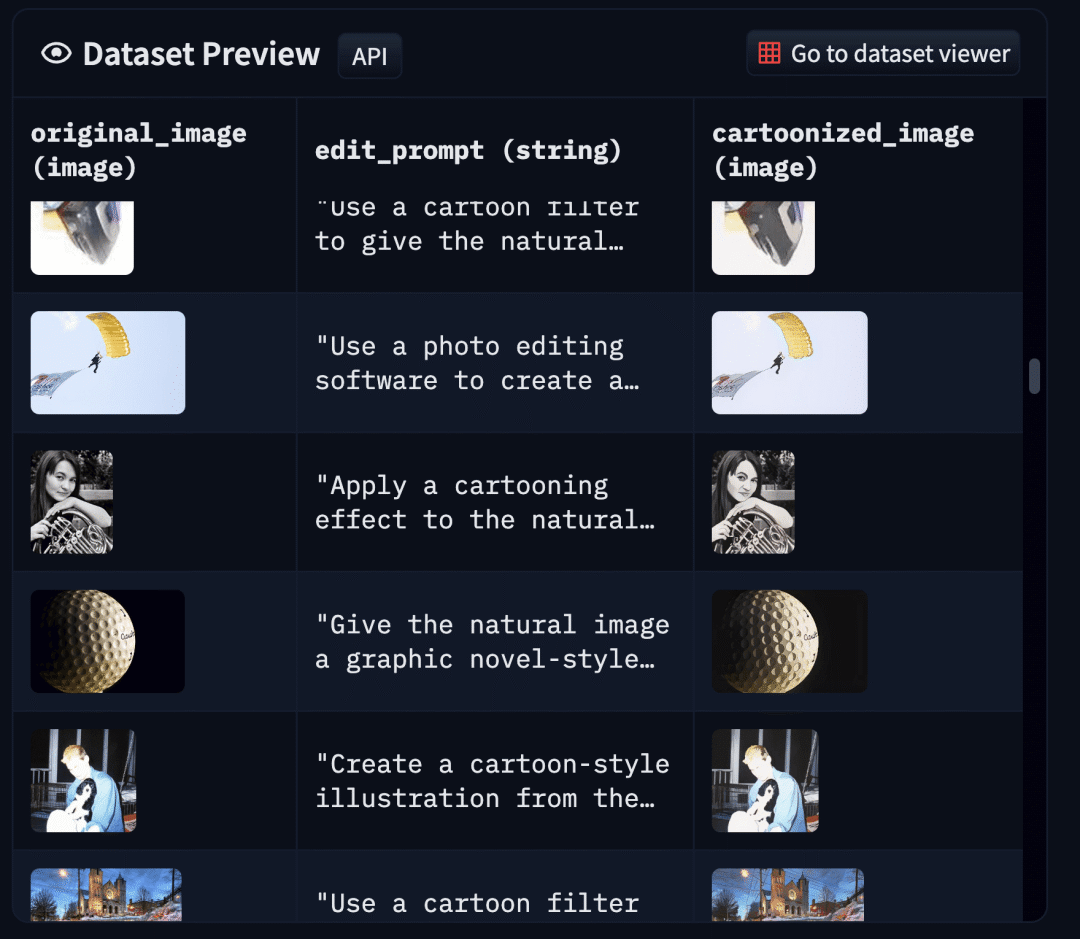 |
|---|
| 图 6: 卡通化数据集的样本格式(建议放大并以彩色显示,以获得最佳视觉效果)。 |
你可以在原文找到我们生成的卡通化数据集。有关如何准备数据集的更多详细信息,请参阅原文。我们将该数据集用于微调 InstructPix2Pix 模型,并获得了相当不错的结果 (更多细节参见“训练实验及结果”部分)。
下面,我们继续看看这种方法是否可以推广至底层图像处理任务,例如图像除雨、图像去噪以及图像去模糊。
底层图像处理 (Low-level image processing)
我们主要专注 MAXIM 论文中的那些常见的底层图像处理任务。特别地,我们针对以下任务进行了实验: 除雨、去噪、低照度图像增强以及去模糊。
我们为每个任务从以下数据集中抽取了数量不等的样本,构建了一个单独的数据集,并为其添加了提示,如下所示: 任务 提示 数据集 抽取样本数
| 任务 | 提示 | 数据集 | 抽取样本数 |
|---|---|---|---|
| 去模糊 | “deblur the blurry image” | REDS (train_blur及 train_sharp) | 1200 |
| 除雨 | “derain the image” | Rain13k | 686 |
| 去噪 | “denoise the noisy image” | SIDD | 8 |
| 低照度图像增强 | "enhance the low-light image” | LOL | 23 |
上表中的数据集通常以 输入输出对的形式出现,因此我们不必担心没有真值 (ground-truth)。你可以从原文找到我们的最终数据集。最终数据集如下所示:
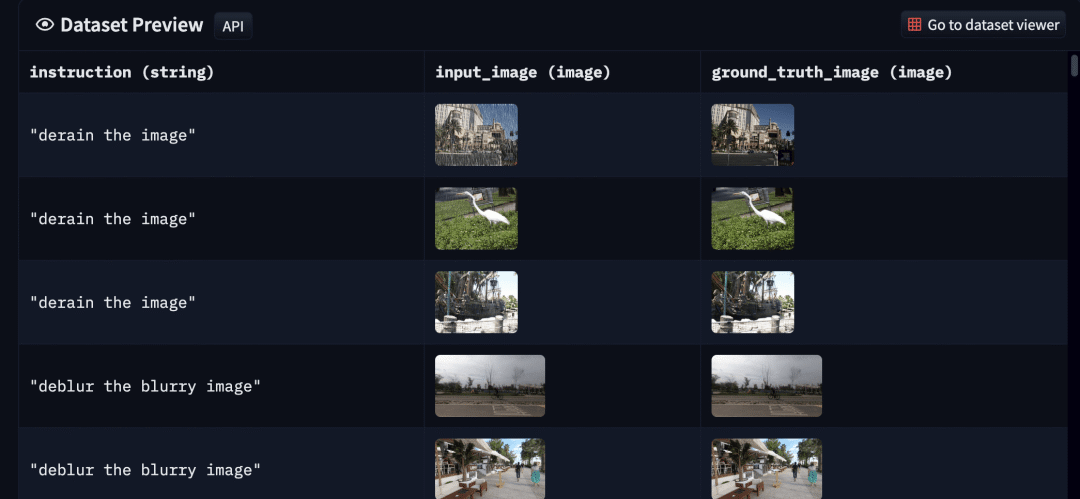 |
|---|
| 图 7: 我们生成的底层图像处理数据集的样本(建议放大并以彩色显示,以获得最佳视觉效果)。 |
总的来说,这种数据集的组织方式来源于 FLAN。在 FLAN 中我们创建了一个混合了各种不同任务的数据集,这一做法有助于我们一次性在多任务上训练单个模型,使其在能够较好地适用于含有不同任务的场景。这与底层图像处理领域的典型做法有很大不同。像 MAXIM 这样的工作虽然使用了一个单一的模型架构,其能对不同的底层图像处理任务进行建模,但这些模型的训练是在各个数据集上分别独立进行的,即它是“单架构,多模型”,但我们的做法是“单架构,单模型”。
训练实验及结果
这 是我们的训练实验的脚本。你也可以在 Weight and Biases 上找到我们的训练日志 (包括验证集和训练超参):
卡通化 (超参)
底层图像处理 (超参)
在训练时,我们探索了两种方法:
对 InstructPix2Pix 的 checkpoint 进行微调
使用 InstructPix2Pix 训练方法对 Stable Diffusion 的 checkpoint 进行微调
通过实验,我们发现第一个方法从数据集中学得更快,最终训得的模型生成质量也更好。
有关训练和超参的更多详细信息,可查看 我们的代码 及相应的 Weights and Biases 页面。
卡通化结果
为了测试 指令微调的卡通化模型 的性能,我们进行了如下比较:
 |
|---|
| 图 8: 我们将指令微调的卡通化模型(最后一列)的结果与 CartoonGAN 模型(第二列)以及预训练的 InstructPix2Pix 模型(第三列)的结果进行比较。显然,指令微调的模型的结果与 CartoonGAN 模型的输出更一致(建议放大并以彩色显示,以获得最佳视觉效果)。 |
测试图像是从 ImageNette 的验证集中采样而得。在使用我们的模型和预训练 InstructPix2Pix 模型时,我们使用了以下提示: “Generate a cartoonized version of the image”,并将 image_guidance_scale、 guidance_scale、推理步数分别设为 1.5、7.0 以及 20。这只是初步效果,后续还需要对超参进行更多实验,并研究各参数对各模型效果的影响,尤其是对预训练 InstructPix2Pix 模型效果的影响。
源地址提供了更多的对比结果。你也可以在原文找到我们用于比较模型效果的代码。
然而,我们的模型对 ImageNette 中的目标对象 (如降落伞等) 的处理效果 不及预期,这是因为模型在训练期间没有见到足够多的这类样本。这在某种程度上是意料之中的,我们相信可以通过增加训练数据来缓解。
底层图像处理结果
对于底层图像处理 (模型),我们使用了与上文相同的推理超参:
推理步数: 20
image_guidance_scale: 1.5guidance_scale: 7.0
在除雨任务中,经过与真值 (ground-truth) 和预训练 InstructPix2Pix 模型的输出相比较,我们发现我们模型的结果相当不错:
 |
|---|
| 图 9: 除雨结果(建议放大并以彩色显示,以获得最佳视觉效果)。提示为 “derain the image”(与训练集相同)。 |
但低照度图像增强的效果不尽如意:
 |
|---|
| 图 10: 低照度图像增强结果(建议放大并以彩色显示,以获得最佳视觉效果)。提示为 “enhance the low-light image”(与训练集相同)。 |
这种情况或许可以归因于训练样本不足,此外训练方法也尚有改进余地。我们在去模糊任务上也有类似发现:
 |
|---|
| 图 11: 去模糊结果(建议放大并以彩色显示,以获得最佳视觉效果)。提示为 “deblur the image”(与训练集相同)。 |
我们相信对社区而言,底层图像处理的任务不同组合如何影响最终结果 这一问题非常值得探索。在训练样本集中增加更多的任务种类并增加更多具代表性的样本是否有助于改善最终结果? 这个问题,我们希望留给社区进一步探索。
你可以试试下面的交互式演示,看看 Stable Diffusion 能不能领会并执行你的特定指令:
体验地址:https://instruction-tuning-sd-instruction-tuned-sd.hf.space
潜在的应用及其限制
在图像编辑领域,领域专家的想法 (想要执行的任务) 与编辑工具 (例如 Lightroom) 最终需要执行的操作之间存在着脱节。如果我们有一种将自然语言的需求转换为底层图像编辑原语的简单方法的话,那么用户体验将十分丝滑。随着 InstructPix2Pix 之类的机制的引入,可以肯定,我们正在接近那个理想的用户体验。
但同时,我们仍需要解决不少挑战:
这些系统需要能够处理高分辨率的原始高清图像。
扩散模型经常会曲解指令,并依照这种曲解修改图像。对于实际的图像编辑应用程序,这是不可接受的。
开放性问题
目前的实验仍然相当初步,我们尚未对实验中的很多重要因素作深入的消融实验。在此,我们列出实验过程中出现的开放性问题:
如果扩大数据集会怎样? 扩大数据集对生成样本的质量有何影响?目前我们实验中,训练样本只有不到 2000 个,而 InstructPix2Pix 用了 30000 多个训练样本。
延长训练时间有什么影响,尤其是当训练集中任务种类更多时会怎样? 在目前的实验中,我们没有进行超参调优,更不用说对训练步数进行消融实验了。
如何将这种方法推广至更广泛的任务集?历史数据表明,“指令微调”似乎比较擅长多任务微调。 目前,我们只涉及了四个底层图像处理任务: 除雨、去模糊、去噪和低照度图像增强。将更多任务以及更多有代表性的样本添加到训练集中是否有助于模型对未见任务的泛化能力,或者有助于对复合型任务 (例如: “Deblur the image and denoise it”) 的泛化能力?
使用同一指令的不同变体即时组装训练样本是否有助于提高性能? 在卡通化任务中,我们的方法是在 数据集创建期间 从 ChatGPT 生成的同义指令集中随机抽取一条指令组装训练样本。如果我们在训练期间随机抽样,即时组装训练样本会如何?对于底层图像处理任务,目前我们使用了固定的指令。如果我们按照类似于卡通化任务的方法对每个任务和输入图像从同义指令集中采样一条指令会如何?
如果我们用 ControlNet 的训练方法会如何? ControlNet 允许对预训练文生图扩散模型进行微调,使其能以图像 (如语义分割图、Canny 边缘图等) 为条件生成新的图像。如果你有兴趣,你可以使用本文中提供的数据集并参考 这篇文章 进行 ControlNet 训练。
总结
通过本文,我们介绍了我们对“指令微调” Stable Diffusion 的一些探索。虽然预训练的 InstructPix2Pix 擅长领会执行一般的图像编辑指令,但当出现更专门的指令时,它可能就没法用了。为了缓解这种情况,我们讨论了如何准备数据集以进一步微调 InstructPix2Pix,同时我们展示了我们的结果。如上所述,我们的结果仍然很初步。但我们希望为研究类似问题的研究人员提供一个基础,并激励他们进一步对本领域的开放性问题进行探索。
链接
训练和推理代码
演示
InstructPix2Pix
本文中的数据集和模型
感谢 Alara Dirik 和 Zhengzhong Tu 的讨论,这些讨论对本文很有帮助。感谢 Pedro Cuenca 和 Kashif Rasul 对文章的审阅。
引用
如需引用本文,请使用如下格式:
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}英文原文: https://hf.co/blog/instruction-tuning-sd
原文作者: Sayak Paul
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)