欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131331049

NVIDIA A100 是一款基于 Ampere 架构的高性能 GPU,专为 AI、数据分析和高性能计算等应用场景设计。NVIDIA A100 具有以下特点:
- 支持 Tensor Float (TF32) 精度,可在不修改代码的情况下提供比前代 V100 高 20 倍的 AI 训练速度。
- 支持多实例 GPU (MIG) 技术,可将一个 A100 分割为最多七个独立的 GPU 实例,实现灵活的资源分配和利用率提升。
- 支持结构稀疏性,可在保持精度的同时将推理性能提升高达两倍。
- 提供 40GB 和 80GB 显存两种版本,可处理超大规模的模型和数据集。
- 配合 NVIDIA 的软件、网络和硬件解决方案,可构建强大的端到端 AI 和 HPC 数据中心平台。
当前张量占用:10000 * 10000 * 150 = 15 ^ 9,一个float占用4位,约60G。
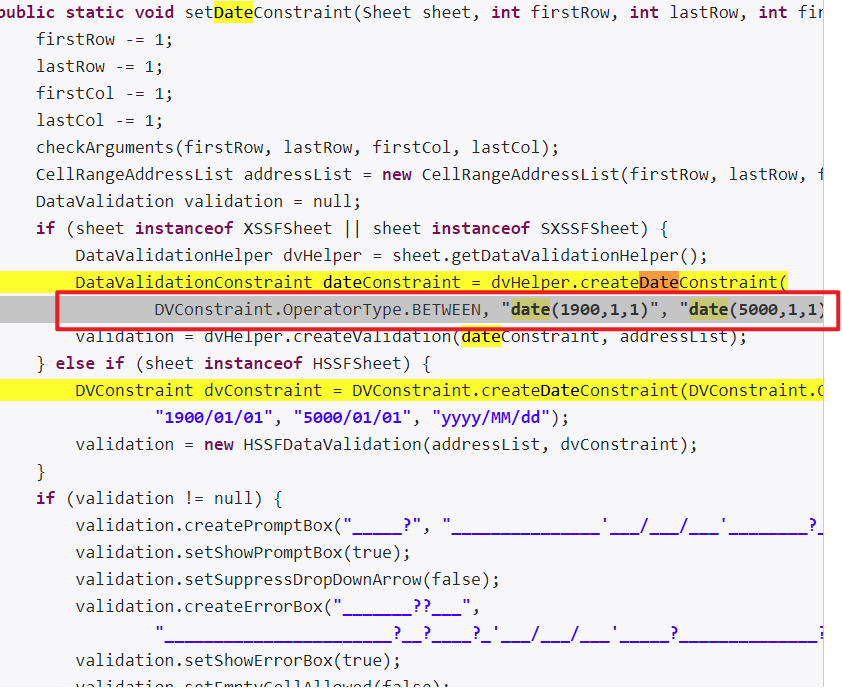
NVIDIA A100 实际占用 58169M = 58G,相差不多:
Wed Jun 21 08:55:41 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... On | 00000000:62:00.0 Off | 0 |
| N/A 32C P0 77W / 400W | 58169MiB / 81251MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
源码:
import torch
import time
# 获取可用的GPU数量
num_gpus = torch.cuda.device_count()
# 创建一个空的列表,用来存储分配给每个GPU的张量
tensors = []
x = 10000
y = 150
print("test start")
# 设置一个无限循环
while True:
# 对每个GPU进行循环
for i in range(num_gpus):
# 设置当前设备为第i个GPU
torch.cuda.set_device(i)
for j in range(y):
# 创建一个很大的随机张量,占用大量的显存
tensor = torch.randn(x, x).cuda()
# 将张量添加到列表中
tensors.append(tensor)
# 等待所有的张量计算完成
torch.cuda.synchronize()
# 清空列表,释放显存
tensors.clear()
# 等待一秒钟,防止过度占用CPU资源
time.sleep(1)