| 实验目的: 1.掌握聚类分析及判别分析的基本原理; 2.熟悉掌握SPSS软件进行聚类分析及判别分析的基本操作; 3.利用实验指导的实例数据,上机熟悉聚类分析及判别分析方法。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 实验前预习: 1.聚类分析及判别分析的基本原理; 2.SPSS软件进行聚类分析及判别分析的基本操作及结果解释。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 实验内容: 1. 为了研究世界各国森林、草原资源的分布规律,共抽取了21个国家的数据,每个国家4项指标,原始数据见下表。试用该原始数据对国别进行系统聚类和K-均值聚类(分3类)分析。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2. 从不同地区采集了七块花岗岩,测其部分化学成分如下表:
试作如下分析:
3. 研究团队调查了20个品牌的电视机,记录了它们的市场定位(G):1.高端市场;2.中端市场;3.低端市场;质量评估得分(Q),功能评估得分(C)和价格(P)。如果一个全新的品牌被推出,其中Q=8.0,C=7.5,P=65,它的市场定位应如何?试用判别分析解决这个问题。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 程序测试、运行结果及分析:
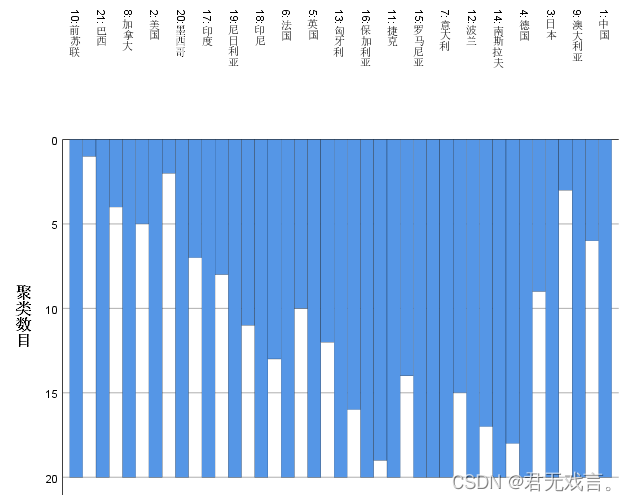
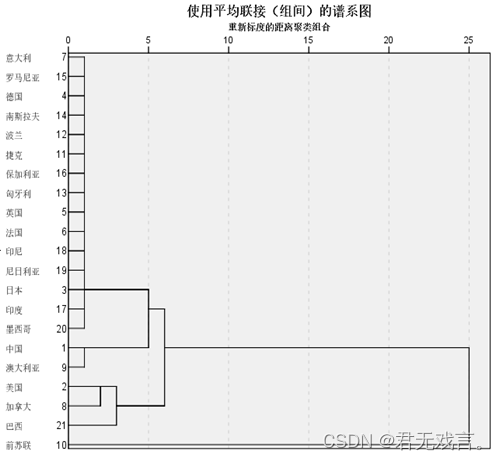
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据à 其余拖入变量框à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果:
结果分析: 对于冰柱图,自下而上的观察进行分类,美国和墨西哥之间的冰柱对应的分类数是三,所以分类为{前苏联},{美国,加拿大,巴西}其余为一类。 对于谱系图分成三类则为{前苏联},{美国,加拿大,巴西}其余的为一类。 聚类分析就是按照相似性把对象进行分类的方法。
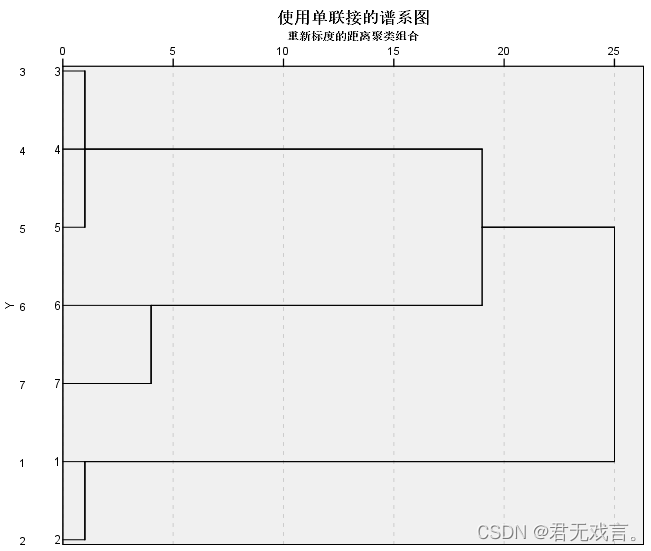
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据à 其余拖入变量框à点击“图” à勾选“谱系图”à点击“方法” à将聚类方法修改为“最近邻矩阵”或者“最远邻矩阵”à将区间框改为欧氏距离 à点击“继续”和“确定” 运行结果:
结果分析:同上一结果分析
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据, 其余拖入变量框à 将聚类改为变量à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果:
结果分析:略
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à选择“描述统计”并选择“描述” à 勾选“将标准化值另存为变量”à点击“确定” 选择“K-均值聚类” à 拖国别至个案标注依据à 标准化的数据拖入变量框à将聚类数改为3 à点击“选项”勾选统计框所有选项à 点击“继续”和“确定” 运行结果:
结果分析: 由方差分析表的p值可以判断出几个变量对分类的都是显著的,最后可以通过表可以知道三类则为{前苏联},{美国,加拿大,巴西}其余的为一类。
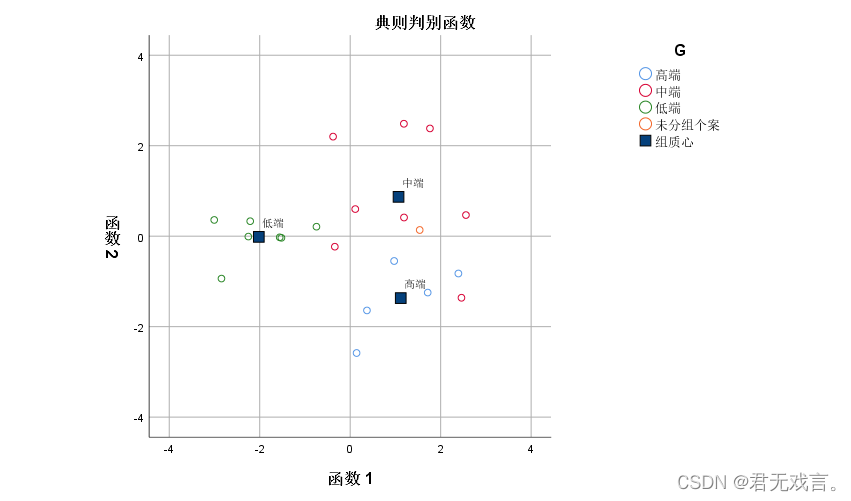
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“判别式” à 将分组变量拖入框中并且点击选择范围1到3 à 拖其余名称至自变量à 点击“统计”并勾选“费歇尔” à在“分类”中点击“合并组”和“个案结果” à勾选“谱系图”à 点击“继续”和“确定”其余拖入变量框à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果:
结果分析: 由第一个图可知,判定没有分组的数据为中端产品,即橙色的小圆圈离中端质心最近。 由第二个图可知,判别分析的正确率为百分之九十 由第三个图可知高端,中端,低端产品的分类函数分别为: Y1=13.022x1+4.367x2-0.332x3-60.635 Y2=11.004x1+3.886x2-0.136x3-52.853 Y3=9.279x1+2.115x2-0.165x3-29.854 代入数据Q,C,P分别为x1,x2,x3得到y2的绝对值最小,所以判别未知电视为中端产品 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 讨论: 1.判别分析与聚类分析的区别: (2)判别分析对(样本)个体进行分类,必须事先知道事物的类别,也知道应分几类,并已取得各类样品的观测数据,在此基础上根据某些准则建立判别式,然后对末知样品进行判别分类,它需要历史资料去建立判别函数。 (3)聚类分析可以对样本或指标进行分类,而判别分析只对样本进行分类。 (4)判别分析与聚类分析常常在一起使用:通过聚类分析首先确定出几个类型,对难以分类的样品再使用判别分析,确定其类别归属。 2.总结: 1.判别分析方法是按已知所属组的样本确定判别函数,制定判别规则,然后再判断每一个新样品应属于哪一类。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
基于spss的多元统计分析 之 聚类分析+判别分析(2/8)
news2026/2/13 2:38:29


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/670284.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
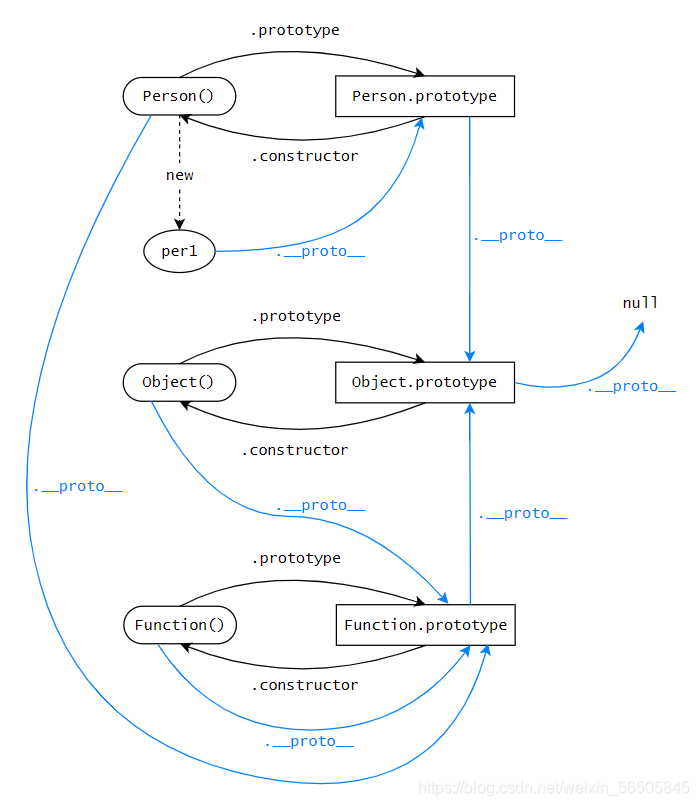
js中原型和原型链的理解(透彻)
js中原型、原型链、继承的理解(透彻) 1、前言1.1 什么是函数对象1.2 什么是实例对象1.3 什么是原型对象1.4 构造函数、原型对象、实例对象的关系 2、原型3、原型链4、原型的相关属性及方法5、总结 1、前言
1.1 什么是函数对象 函数对象就是我们平时称呼…
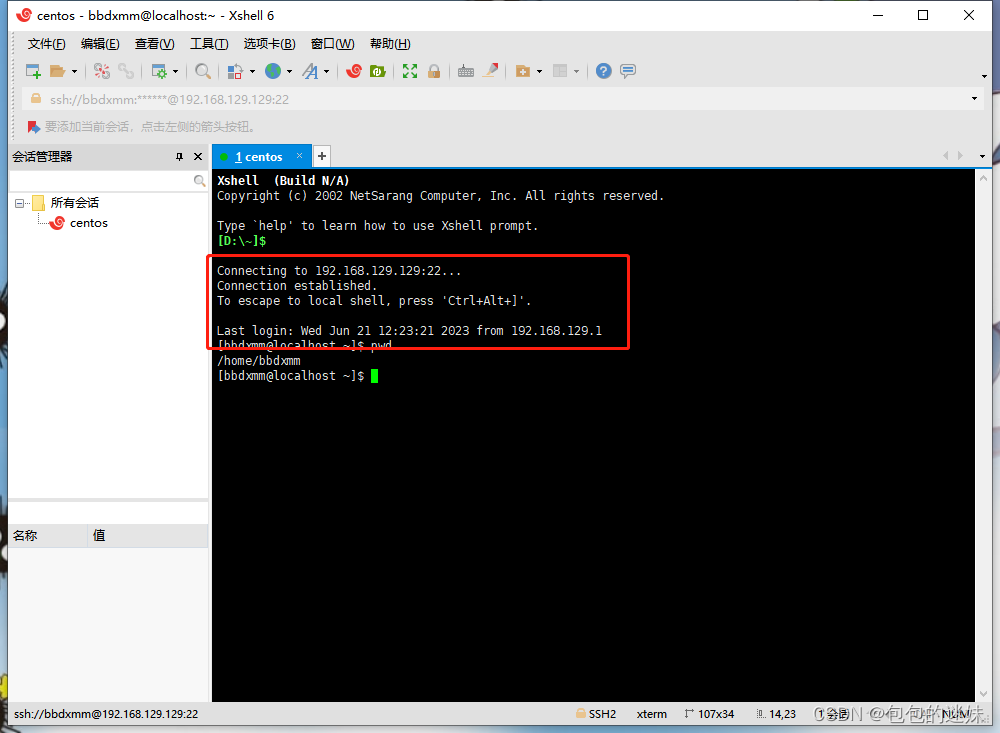
centos连接XShell
先设置网络自动连接,为Xshell 连接centos做准备
选择应用程序->系统工具->设置 选择网络,如果有线没有打开,选择打开,在点击设置 记住ipv4地址,选择自动连接,然后应用 最后鼠标右键点击桌面…

RabbitMQ入门案例之Topic模式
前言:
本文章将介绍RabbitMQ中的Topic(主题)模式,其中还会涉及 ‘#’ 和 ‘*’ 两个通配符在RabbitMQ中的区别。 官网文档地址:https://rabbitmq.com/getstarted.html 什么是Topic模式
RabbitMQ的Topic模式是一种基于…

SpringBoot 如何使用 Spring Integration 处理事件
SpringBoot 如何使用 Spring Integration 处理事件
Spring Integration 是 Spring Framework 的一个扩展,它提供了一种基于消息传递的集成模式。使用 Spring Integration,我们可以将不同的应用程序、系统和服务连接起来,从而实现数据的传递、…
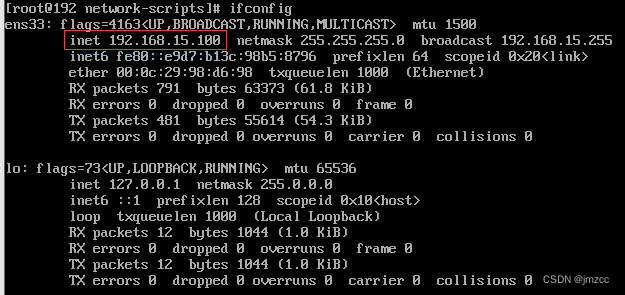
VMware中Linux虚拟机配置静态ip
一、输入ip addr查看ip地址 二、输入cd /etc/sysconfig/network-scripts进入centos网络配置文件夹
三、接着输入ls查看目录 四、 输入vi ifcfg-ens33进入网卡配置 五、 进入以后是这个界面,红色方框里的内容是需要手动修改的,下面图片里已经修改过了。 …

【C】分支和循环语句的简单介绍
语句 分支语句if语句语法结构代码演示 switch语句语法结构代码演示 循环语句while循环语法结构代码分析 for循环语法结构代码演示 do...while循环语法结构代码分析 什么是语句呢? 在C语言中由分号(;)隔开的就是一条语句。 分支语句
if语句
…
【算法设计与分析】期末考试知识总结(知识超浓缩版)
目录
简要介绍
复杂度 迭代
插入排序
二分查找
快排划分
选择排序
计数排序
基数排序
桶排序
递归
递归式的计算-四种方法 欧几里得算法
汉诺塔问题
快速排序 归并排序 堆排序
分治
二维极大点问题
一维最邻近点对
二维最邻近点对 逆序对的数目 凸包
最大字段…

RecyclerView 低耦合单选、多选模块实现
作者:丨小夕 前言
需求很简单也很常见,比如有一个数据列表RecyclerView,需要用户去点击选择一个或多个数据。
实现单选的时候往往简单下标记录了事,实现多选的时候就稍微复杂去处理集合和选中。随着项目选中需求增多,…
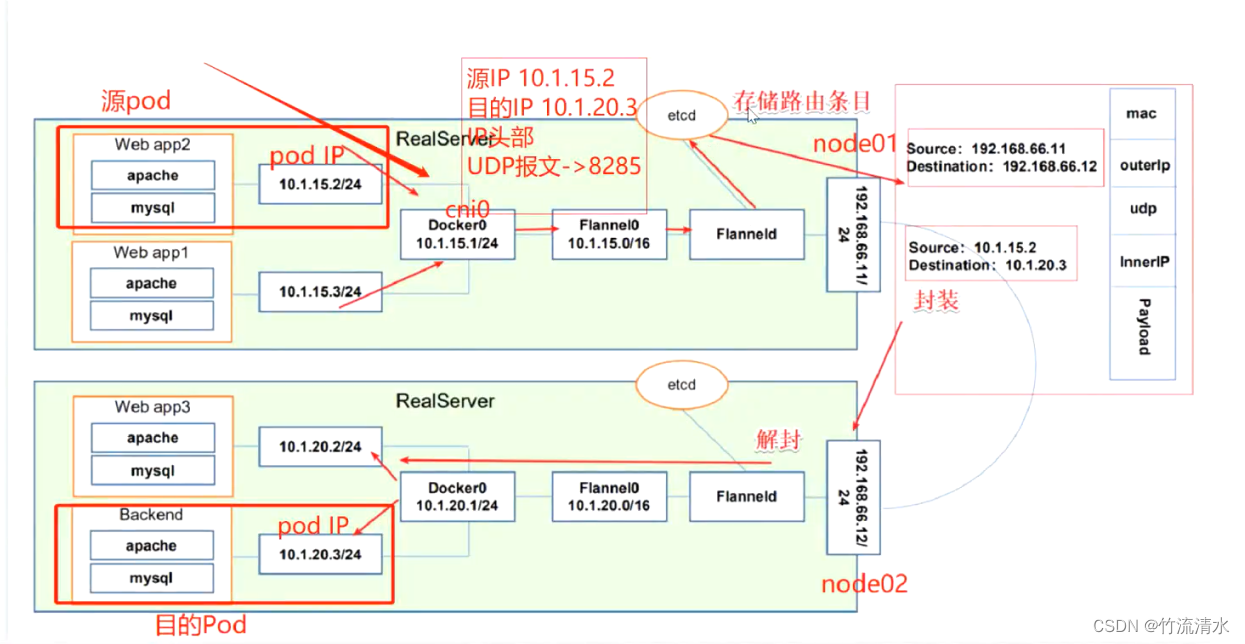
阿里云热修复打补丁包注意事件
1、每次发布app到应用市场前,注意保存没有加固前的apk文件和mapping.txt
2、修复好bug,打包app前,要做的事情
(1)先把有问题的apk的mapping.txt文件复制到/app路径下 (2)修改混淆配置:将-printmapping mapping.txt使…

Android蓝牙协议知识汇总
蓝牙协议下载
蓝牙技术联盟网址:https://www.bluetooth.com/ 在这个网址搜索,比如:
在搜索结果中找到蓝牙协议规范:
点击上面网址:
蓝牙手册里包含了部分核心协议,比如L2CAP、SDP、ATT、GATT&#x…

Python 100%解析svg-captcha验证码
前言
前段时间接到一个需求,登陆某一个网站,然后录入数据;本来以为是一个很简单的需求,结果遇到几个难点:
登陆的时候需要有验证码验证码是一个请求路径,每请求一次验证码都不一样 本来一开始以为是常用的…
探究 CoreData 使用索引(Index)机制加速查表究竟如何实现?
问题现象
在 App 的开发中,CoreData 到底能不能用索引机制(Index)来加速查表?如果可以,又该如何创建和使用索引呢?
这是一个连 官方文档都模棱两可,Stackoverflow 里诸多大神都闪烁其词的话题。
在本篇博文中,您将学到如下内容: 什么是 CoreData 索引(Index…

SpringBoot + Ant Design Vue实现数据导出功能
SpringBoot Ant Design Vue实现数据导出功能 一、需求二、前端代码实现2.1 显示实现2.2 代码逻辑 三、后端代码实现3.1 实体类3.2 接收参数和打印模板3.3 正式的逻辑3.4 Contorller 一、需求
以xlsx格式导出所选表格中的内容要求进行分级设置表头颜色。
二、前端代码实现
2…

UE中创建异步任务编辑器工具(Editor Utility Tasks)
在UE中我们往往需要执行一些编辑器下的异步任务,例如批量生成AO贴图、批量合并静态模型等,又不想阻碍主线程,因此可以使用Editor Utility Tasks直接创建UE编辑器下的异步任务。
如果你不太了解UE编辑器工具,可以参考这篇文章&…

Spring Boot 中自定义数据校验注解
Spring Boot 中自定义数据校验注解
在 Spring Boot 中,我们可以使用 JSR-303 数据校验规范来校验表单数据的合法性。JSR-303 提供了一些常用的数据校验注解,例如 NotNull、NotBlank、Size 等。但是,在实际开发中,我们可能需要自定…

2023年6月24日(星期六):骑行明郎
2023年6月24日(星期六):骑行明郎,早8:30到9:00, 大观公园门囗集合,9:30点准时出发 【因迟到者,骑行速度快者,可自行追赶偶遇。】 偶遇地点: 大观公园门囗集合,家住南,东,…
(二叉树) 100. 相同的树 ——【Leetcode每日一题】
❓100. 相同的树
难度:简单
给你两棵二叉树的根节点 p 和 q,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1: 输入:p [1,2,3], q …

使用代理ip做网页抓取需要注意什么
现在,很多公司为达成目标,都需要抓取大量数据。企业需要根据数据来作出重大决定,因此掌握准确信息至关重要。互联网上有许多宝贵的公共数据。问题是如何轻松采集这些数据,而无需让团队整天手动复制粘贴所需信息?网页抓取的定义越…