目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
为什么要使用分布式?
做性能测试时,如果被测系统性能比较好,或者系统项目比较大,那么一般都会要求能支持比较高的并发用户数。而我们做性能测试时,发起请求的机器,硬件资源是一定的,不可能配置无限大。
所以,它能发起的并发用户数是有限的,而当我们发起方一台电脑能发起的并发用户数小于我们性能测试期望的并发用户数时,我们就会自然而然想到增加发起方的电脑。增加发起方电脑数量,那么,发起的并发用户数累加,就增大了。
发起方一台电脑,不管是 windows 系统还是 Linux 系统,一般而言,大概能支持 1.5k 左右并发用户,更多并发用户就要采用分布式。
如何配置分布式?
助攻机配置:
①修改 jmeter.properties 文件:
②首先,我们准备多台机器,作为助攻机器;
③然后,检查每台机器上是否安装了 JDK,并且 JDK 版本是否都一致;
④然后,在助攻机器上放置相同版本的 jmeter;
⑤接下来,配置 jmeter.properties 文件;
⑥修改 server_port 端口,自定义一个端口;
⑦修改 server.rmi.ssl.disable=true;
⑧修改 server.rmi.port 端口 ---- 可选;
⑨启动服务:jmeter-server -Djava.rmi.server.hostname=ip_address;
⑩检查防火墙,关闭或开放 自定义的 server_port 端口
主控机器配置:
①修改 jmeter.properties 文件
②修改 remote_hosts,值为助攻机器 ip;
③修改 server.rmi.ssl.disable=true;
④修改 mode=Standard;
分布式机配置注意事项(重要)
分布式的配置,是不是很简单呢?
是的,这个配置实际上一点都不难,如果你要自己练手,按照上面的操作,就能很简单配置成功。但是,当你在企业项目中实战时,还会这么简单吗?
如果你企业的项目,需要支持大几万的并发,要使用几十台助攻机器,是不是就简单重复上面的操作就可以了呢?
答案是否定的。
现在有几十台 Linux 机器,放在你面前,供你去配置为助攻机。数量比较大,完全无法保证每一台都一模一样,所以,我们先要检查机器配置。
1、硬件资源
CPU、内存是一台电脑的核心, 几十台机器,我们完全无法保证每一台都一样,在助攻机的要求中,虽然,没有对 CPU 和内存做要求,但是,如果每台机器能提供的资源不一样,那么能产生的并发用户数量肯定也会不相等。
所以,我们需要找出有机器中,最低配置的机器,然后,以最低配置机器为参考配置 jmeter 的堆栈信息。
通过 top 命令,查看下每个系统的 CPU 和内存信息。
修改 jmeter 的 bin 文件夹中 jmeter 文件 HEAP:=“-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m” 修改堆栈信息中的大小。
不配置,在执行高并发用户数时,jmeter 可能会出现 OOM 问题。
2、系统环境
JDK:
机器多了,每台机器的 JDK 大版本是否一致,可能就是个问题。如果,机器上没有安装,那可以直接去安装指定版本即可,但是,如果机器上已经安装了其他版本的 JDK,并且正运行其他 Java 项目,这个时候怎么办呢?
指定 jmeter 的运行 JDK 版本:
下载解压指定 JDK 版本到 Linux 的 /usr/local 文件夹下, 不要去配置改动系统环境变量。
在 jmeter 的 jmeter 文件中,添加 JAVA_HOME=/usr/local/jdk版本/ 指定 jmeter 运行的 JDK 版本,这样,就不用改动操作系统的 JDK,不影响系统中其他 Java 项目。
Jmeter:
Jmeter 版本;
所有助攻机器上 jmeter 的版本都必须一致;
jmeter.properties 要修改 ssl.disable=true, 端口可以不相同;
如果代码中使用了第三方插件,助攻机器上,也必须有这些插件包;
3、环境变量
jmeter 运行,本身可以不配置 JMETER_HOME 环境变量,但是,当机器多了时,还是建议在所有机器上配置 JMETER_HOME 环境变量。
4、HEAP 配置
机器多了,可能每台机器的内存都不一样, 我们期望助攻机器能产生更大的并发用户数,所以,建议修改每台机器的 HEAP 配置信息,设置为相同。
5、CSV 文件
如果写的 jmeter 脚本中,使用了 CSV 数据文件设置,那么文件的路径,请使用相对路径写法。
jmeter-server 助攻服务在哪个路径下启动,就要在所有的机器上,上传 CSV 文件到该路径下的相对位置。
6、os 操作系统
os 版本:没有要求,可以是不同版本。
7、端口区间
操作系统的端口数量是有限的,不同系统,默认情况下,打开的端口数量可能不相等,这就需要我们去配置一下每台机器上打开的端口范围。
sysctl -a | grep net.ipv4.ip_local_port_range
这个命令可以查看当前机器上,开启的端口范围。
sysctl -w net.ipv4.ip_local_port_range="1024 65534"
然后再执行 sysctl -p 生效。这样,设置每台机器上,开启的端口范围。
sysctl -a | grep net.ipv4.ip_local_port_range
这个命令可以查看当前机器上,开启的端口范围。
8、打开文件数量
操作系统对每个程序能打开的文件数量是有限制的,这个是系统限制,我们可以通过 ulimit -n 看到, 也可以通过 cat /proc/进程id/limit 查看某个进程今天能打开的文件数量限制。
因为性能测试助攻机,也是要发起大量请求的,这有可能要打开大量的文件,如果文件数量限制过小,也会导致问题,所以,我们可以通过 ulimit -n 数量 来修改进程可以打开的文件数量。然后,重启动 jmeter-server 助攻服务,这样,就会以你修改后的数量来做限制了。
9、网络环境
几十台机器,网络配置可能会不一样,如果这些助攻机器到被测服务器之间的网络存在问题,那么,可能就会导致请求压力上不会,甚至出现网络错误。
我们可以在每台助攻机器上,使用 tracepath 被测服务器 来查看助攻机到被测服务器之间的网络情况。如果发现,网络延迟时间很长,那就说明,当前机器,可能网络配置有问题。在使用时,可能就要剔除这台助攻机器。
10、启动服务
在每台助攻机器上执行:
jmeter-server -Djava.rmi.server.hostname=ipaddr
因为每台的 ip 地址都不一样,所以,这个命令必须一个一个的敲。同时,我们可以加个’&‘ 符号,把命令转换为后台运行。
在主控机器上执行:
java -Xms48g -Xmx48g -XX:MaxMetaspaceSize=2g -jar $JMETER_HOME/bin/ApacheJMeter.jar -n -R xxx:port,xxx:port -t xxx.jmx -l xxxx.jtl -e -o xxdirect
-Xms48g -Xmx48g -XX:MaxMetaspaceSize=2g
这个是设置主控机器 jmeter 的堆栈信息,这个大小,可以根据自己机器的内存大小灵活修改,但是,这个一定要设置的比较大。如果小了,生成报告的时间就会很长。
$JMETER_HOME/bin/ApacheJMeter.jar
上面表示自己的 jmeter 路径。
-R xxx:port,xxx:port
指定助攻机器。可以根据自己的需要指定。如果,不需要采用分布式,就不用这一段,如果要用分布式,就要使用这一段,多台时,就用逗号分隔。
-t xxx.jmx
你放在主控机器上的 jmeter 脚本文件。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
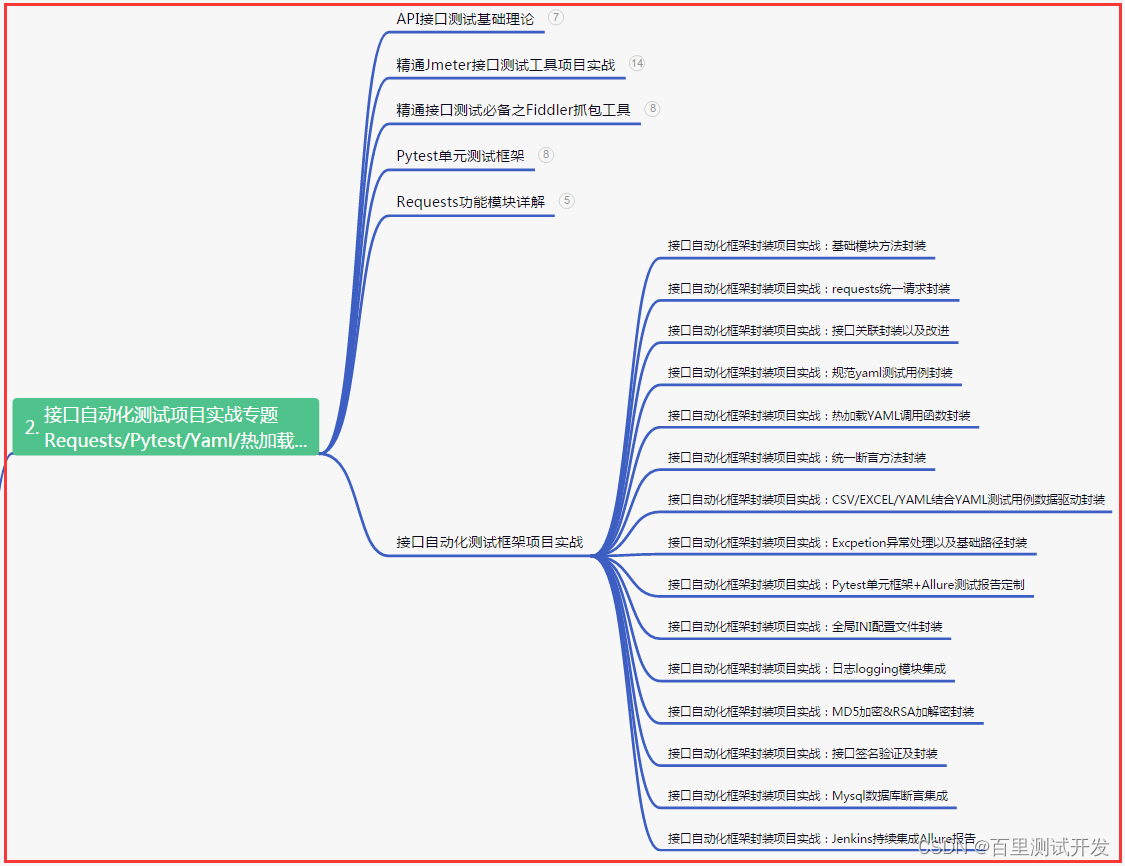
二、接口自动化项目实战
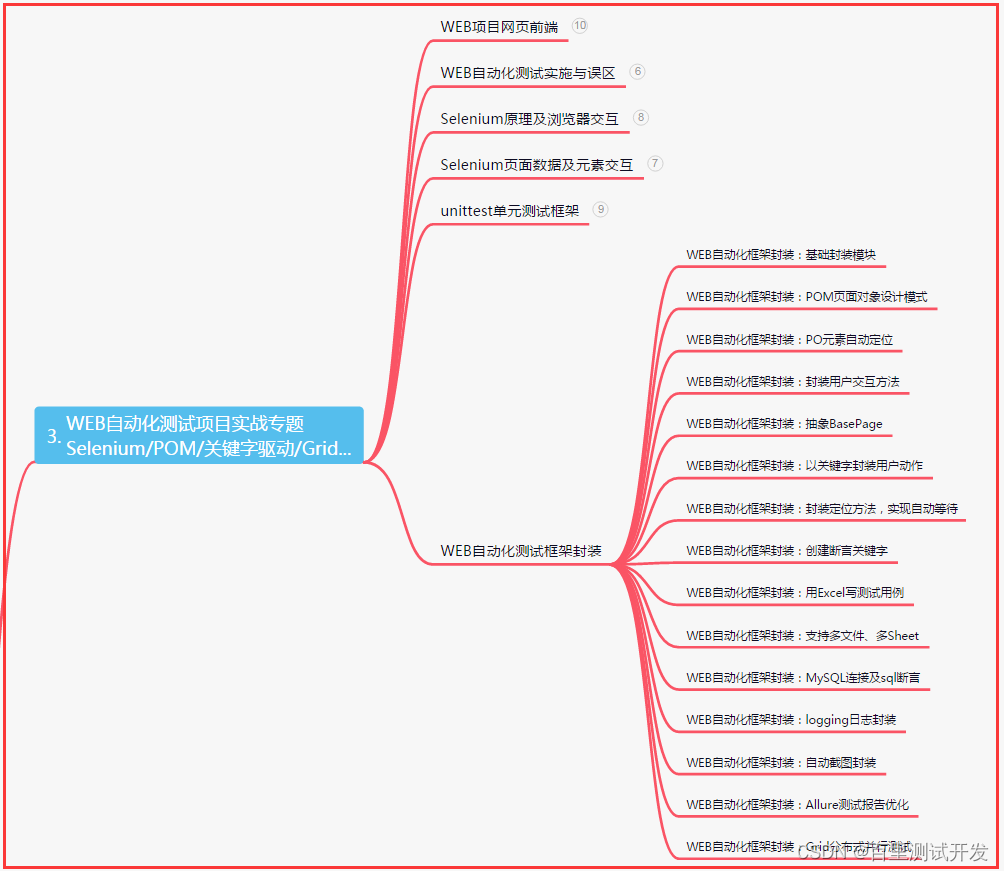
三、Web自动化项目实战
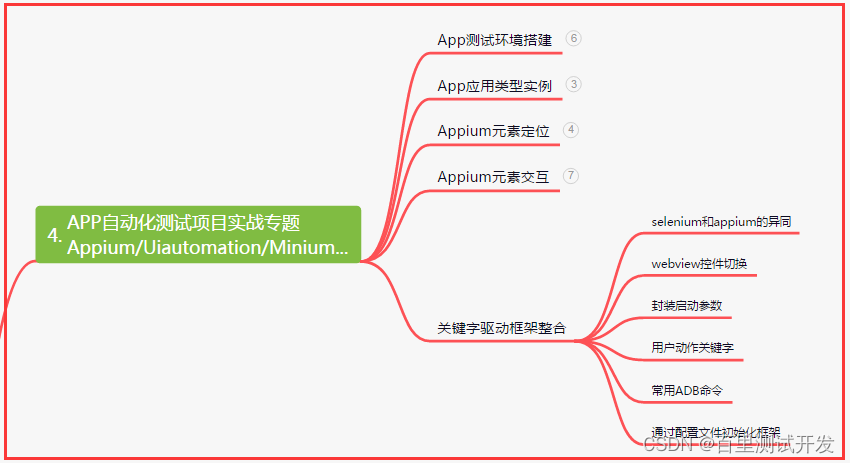
四、App自动化项目实战
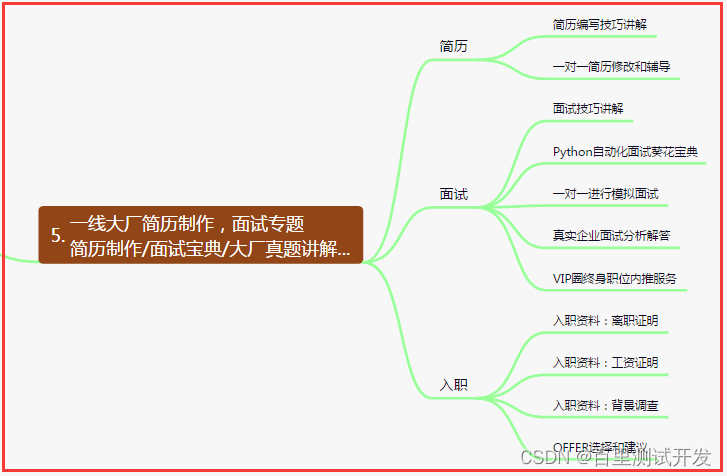
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试

九、总结(尾部小惊喜)
成功不是偶然,而是必然。只有坚持不懈地努力奋斗,才能实现自己的梦想。不要害怕失败,因为失败是通向成功的必经之路。要相信自己,充满信心和勇气去迎接挑战。相信你一定可以成为更好的自己!
每一天都是崭新的开始,不要被过去束缚,不要被未来迷惑,把握当下,脚踏实地,坚持奋斗。只有不断努力,才能在生命的舞台上演绎出最精彩的人生。
每一天都是一个崭新的开始,不管你昨天做得好不好,今天都有机会做得更好。奋斗不止于拼搏和坚持,更在于对未来的期待和追求。不要停下脚步,让自己成为一个充满活力和激情的人!







![【进阶]Java:线程通信(了解)](https://img-blog.csdnimg.cn/85806098b96c417aa2ac4587a45d292f.png)