10分钟快速了解Open Graph Benchmark
- Open Graph Benchmark (OGB)
- 安装OGB
- 简单使用
- 节点分类任务数据集
- 链路预测任务数据集
- 图属性预测任务数据集
- Large-Scale Graph ML Datasets
- 内容来源
Open Graph Benchmark (OGB)
Open Graph Benchmark(OGB)是用于图机器学习的基准数据集、数据加载器和评估器的集合。数据集涵盖了各种图机器学习任务和现实世界中的应用程序。OGB数据加载器与流行的图深度学习框架完全兼容,包括PyTorch Geometric和Deep Graph Library(DGL)。它们提供自动数据集下载、标准化数据集拆分和统一的性能评估。

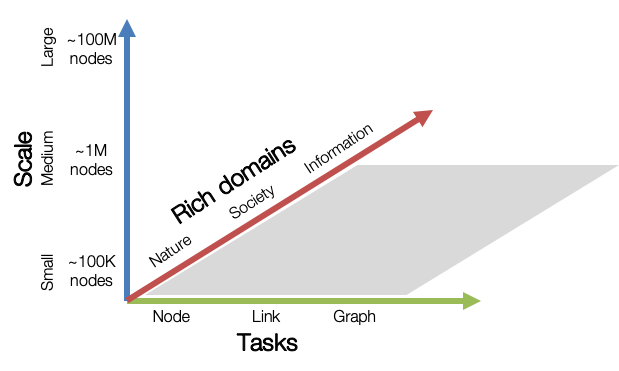
OGB旨在提供涵盖重要的图机器学习任务、不同数据集规模和丰富领域的图数据集。
- Graph ML任务:涵盖了三个基本的图机器学习任务:节点、链接和图级别的预测。
- 规模多样化:小型图数据集可以在单个GPU内处理,而中大型图可能需要多个GPU或巧妙的采样/分区技术。
- 丰富的领域:图数据集来自从科学网络到社会/信息网络的不同领域,也包括异构知识图。
安装OGB
可以使用Python包管理器pip安装。
pip install ogb
检查ogb的版本:
python -c "import ogb; print(ogb.__version__)"
# This should print "1.3.6". Otherwise, please update the version by
pip install -U ogb
其他相关的依赖包 是:
- Python>=3.6
- PyTorch>=1.6
- DGL>=0.5.0 or torch-geometric>=2.0.2
- Numpy>=1.16.0
- pandas>=0.24.0
- urllib3>=1.24.0
- scikit-learn>=0.20.0
- outdated>=0.2.0
简单使用
主要强调了OGB的两个关键特性,即(1)易于使用的数据加载器和(2)标准化的评估器。
(1)Data loaders
OGB有易于使用的PyTorch Geometric和DGLdata loaders。可以处理数据集下载以及标准化的数据集拆分。下面的示例是在PyTorch Geometric上数据准备和拆分数据集!当然对于DGL也是非常方便的!
from ogb.graphproppred import PygGraphPropPredDataset
from torch_geometric.loader import DataLoader
# Download and process data at './dataset/ogbg_molhiv/'
dataset = PygGraphPropPredDataset(name = 'ogbg-molhiv')
split_idx = dataset.get_idx_split()
train_loader = DataLoader(dataset[split_idx['train']], batch_size=32, shuffle=True)
valid_loader = DataLoader(dataset[split_idx['valid']], batch_size=32, shuffle=False)
test_loader = DataLoader(dataset[split_idx['test']], batch_size=32, shuffle=False)
(2)Evaluators
OGB还准备了标准化的评估器,以便于评估和比较不同的方法。evaluator将input_dict(格式在evaluator.expected_input_format中指定的字典)作为输入,并返回一个存储适用于给定数据集的性能度量的字典。标准化的评估协议使研究人员能够可靠地比较他们的方法。
from ogb.graphproppred import Evaluator
evaluator = Evaluator(name = 'ogbg-molhiv')
# You can learn the input and output format specification of the evaluator as follows.
# print(evaluator.expected_input_format)
# print(evaluator.expected_output_format)
input_dict = {'y_true': y_true, 'y_pred': y_pred}
result_dict = evaluator.eval(input_dict) # E.g., {'rocauc': 0.7321}
节点分类任务数据集
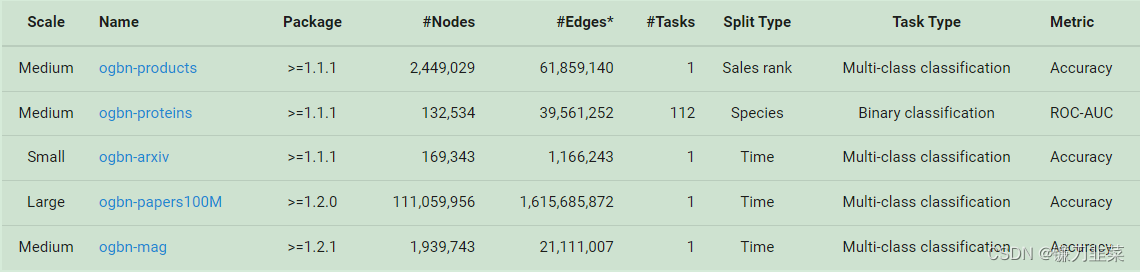
注意:对于无向图,加载的图将具有双倍的边数,因为OGB会自动添加双向边。
链路预测任务数据集
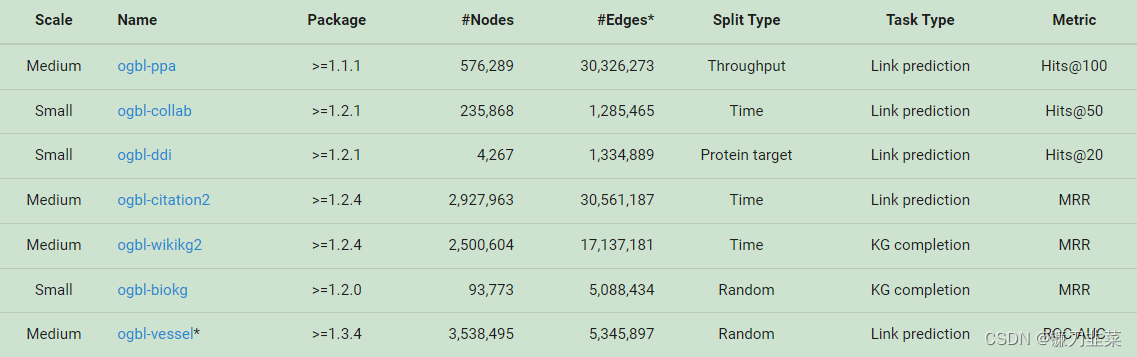
注意:对于无向图,加载的图将具有双倍的边数,因为OGB会自动添加双向边。*表示外部提供的数据集。
图属性预测任务数据集

注意:对于无向图,加载的图将具有双倍的边数,因为OGB会自动添加双向边。
Large-Scale Graph ML Datasets
有三个OGB-LSC数据集:MAG240M、WikiKG90Mv2和PCQM4Mv2,它们分别在节点、链接和图的级别上具有前所未有的规模和覆盖预测。下面提供了三个OGB-LSC数据集的说明性概述。
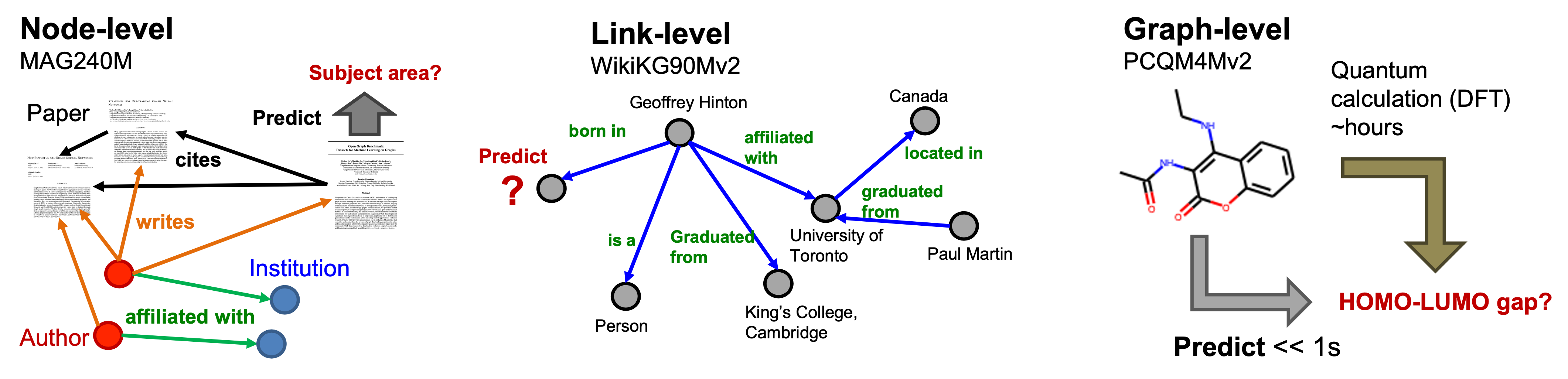
- MAG240M是一个异质的学术图,其任务是预测位于异质图中的论文的主题领域(节点分类)。
- WikiKG90Mv2是一个知识图,其任务是估算缺失的三元组(链接预测)。
- PCQM4Mv2是一个量子化学数据集,其任务是预测给定分子的一个重要分子性质,即HOMO-LUMO间隙(图回归)。
对于每个数据集,OGB仔细设计其预测任务和数据分割,以便在任务上实现高预测性能将直接影响相应的应用。在每个数据集页面中提供了进一步的详细信息。数据集统计数据和基本信息总结如下,表明OGB的数据集非常大。

†:PCQM4Mv2数据集在SMILES字符串中提供。将它们处理成图形对象后,最终的文件大小将在8GB左右。
内容来源
OGB home