对UNet进行Pytorch QAT量化感知训练研究了一周,终于跑通了,中间踩了不少坑,特此把正常操作记录一下,以备后续参考。
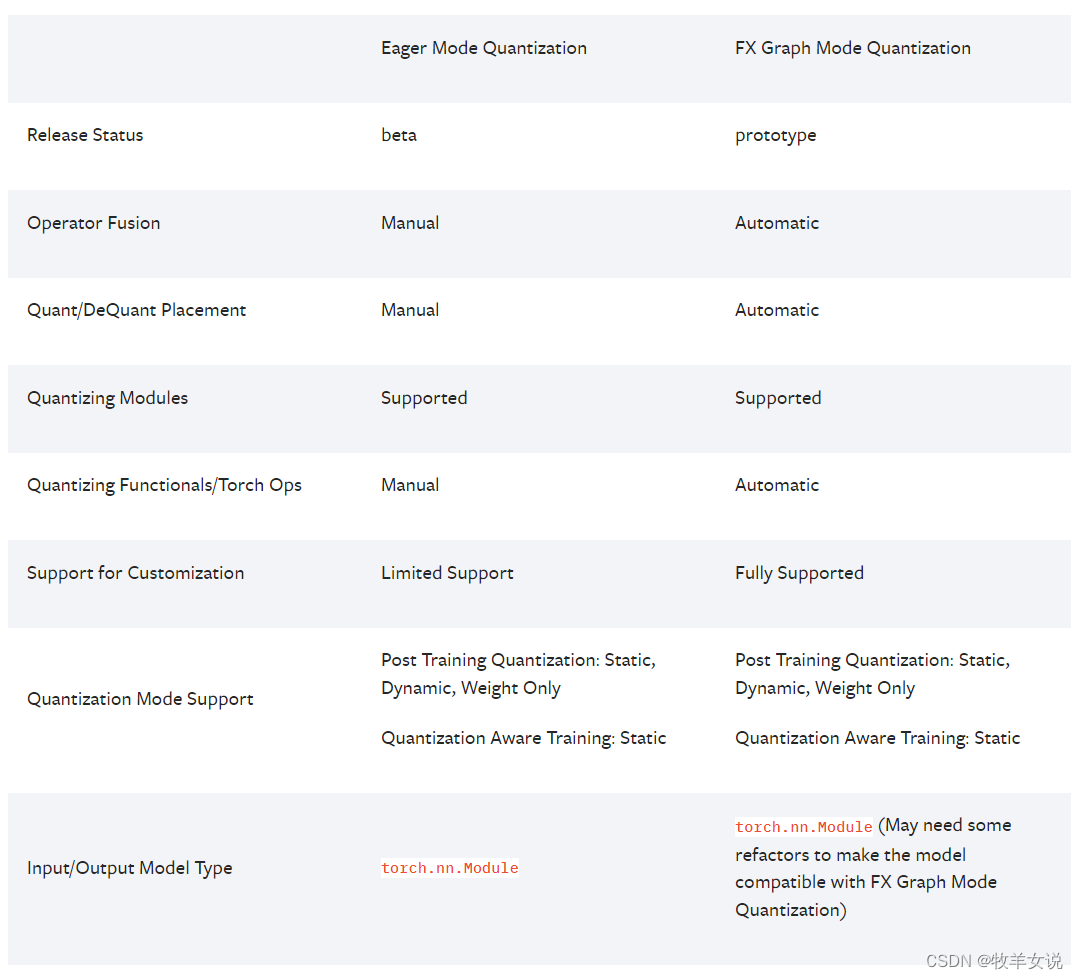
Pytorch提供了两种量化模式:Eager Mode 和FX Graph Mode.
Eager Mode需要手动指定需要融合(Fusion)的层,以及量化和反量化的位置,非常不好用,最开始我就是用的这种方式,踩了很多坑之后,虽然QAT训练完成了,但是在转换成int8模型的时候又报错,后来索性放弃该模式,直接使用FX Graph模式了。
FX Graph Mode虽然也没那么好用,但是它已经比Eager Mode方便多了,毕竟是一个自动化的量化框架。
下图给出了两种模式的比较:
好了,废话不多说,直接上代码说明网络的QAT过程吧。
1. 训练浮点模型—>QAT训练—>转换成int8模型
首先,需要包含我们使用到的相关量化库:
import torch
import copy
from torch.quantization import quantize_fx接下来,创建一个Float32的新模型,并训练:
# 根据自己的机器配置选择合适的device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#Create a new model and train from scratch
model = unet(4, 4) # unet是提前定义好的模型,输入和输出都为4通道数据
model.to(device) # 将模型拷贝到Device
train_model(model, 10) # train_model是提前定义的模型训练函数,本例中为了验证简单,先进行了10个epoch的训练
torch.save(model.state_dict(), 'model_fp32.pth') # 保存state_dict
print('Train over.')接下来,我们需要进行一些QAT设置:
print('Begin QAT...')
model_to_quantize = copy.deepcopy(model)
model_to_quantize.train() # Set model mode to train
# Get default qconfig
qconfig_dict = {"": torch.quantization.get_default_qconfig('qnnpack')}
# Prepare model
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_dict)
model_prepared.to(device) # 模型拷贝至用于训练的device
train_model(model_prepared, 5) # 使用与Float32模型同样的训练函数,对prepared模型继续训练若干轮,这里为了方便,我只设置了5轮
torch.save(model_prepared.state_dict(), 'model_prepared.pth') # 保存prepared模型
# Convert model to int8
print('Converting model to int8...')
model_quantized = quantize_fx.convert_fx(model_prepared) # 将prepared模型转换成真正的int8定点模型
print('Convert done.')
torch.save(model_quantized.state_dict(), 'model_int8.pth') # 保存定点模型的state_dict以上代码中,对原始的Float32模型是从头训练的,其实我们也可以把训练好的浮点模型加载进来,再继续通过QAT训练之后进行量化。
2. 加载预训练好的浮点模型参数—>QAT训练—>转换成int8模型
首先,加载已经训练好的Float32模型:
# 实例化一个模型
model = unet(4, 4)
model.to(device)
# 加载提前训练好的模型参数
checkpoints = torch.load(model_path, map_location=device)
model.load_state_dict(checkpoints)
# 接下来直接进行QAT准备和训练
print('Begin QAT...')
model_to_quantize = copy.deepcopy(model)
model_to_quantize.train() # Set model mode to train
# Get default qconfig
qconfig_dict = {"": torch.quantization.get_default_qconfig('qnnpack')}
# Prepare model
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_dict)
model_prepared.to(device) # 模型拷贝至用于训练的device
train_model(model_prepared, 5) # 使用与Float32模型同样的训练函数,对prepared模型继续训练若干轮,这里为了方便,我只设置了5轮
torch.save(model_prepared.state_dict(), 'model_prepared.pth') # 保存prepared模型
# Convert model to int8
print('Converting model to int8...')
model_quantized = quantize_fx.convert_fx(model_prepared) # 将prepared模型转换成真正的int8定点模型
print('Convert done.')
torch.save(model_quantized.state_dict(), 'model_int8.pth') # 保存定点模型的state_dict
3. int8模型的使用
那么,对于训练好的int8模型,怎样调用来做推理呢?这个时候,直接拿原来的模型结构来加载就会失败,需要我们把原来的模型结构,按照QAT流程转换成int8形式之后,再进行加载,具体见代码:
# 加载int8模型的参数
state_dict_int8 = torch.load('model_int8.pth', map_location=device)
# 实例化原始模型
model = unet(4,4)
model_to_quantize = copy.deepcopy(model)
# 获取qconfig参数
qconfig_dict = {"": torch.quantization.get_default_qconfig('qnnpack')}
# 模型prepare
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_dict)
# 将prepared模型转换成int8结构
model_quantized = quantize_fx.convert_fx(model_prepared)
# 用转换出的int8模型结构加载int8模型参数
model_quantized.load_state_dict(state_dict_int8)
# 设置int8模型模式为eval
model_quantized.eval()
# Pre-process for input_data
# int8模型的调用,input_data是符合输入要求的4通道数据,output_data是模型输出的4通道数据,注意这里我省略了输入输出数据的前后处理,主要展示模型的QAT过程及定点化模型在pytorch中的调用方法。
output_data = model_quantized(input_data)
# Post-process for output_data