消除积分姿态回归的偏差
ICCV2021
论文链接
补充材料链接
参考链接
摘要: 尽管姿态估计的回归法更直观,但由于热图法的优越性能,使其在2D人体姿态估计中占主导地位。积分回归法在架构上使用隐式热图,拉近了热图法与回归法。这就引出了一个问题——检测真的优于回归吗?本文研究了这两个方法最关键的区别:监督差异。在此过程中,我们发现在softmax后取期望,使积分姿态回归存在潜在偏差。为了抵消偏差,我们提出了一种能够提高积分姿态回归精度的补偿方法,并进一步提出了一种组合检测和偏差补偿的回归方法,该方法在几乎没有添加组件的情况下显著优于sota baseline。
文章目录
- 消除积分姿态回归的偏差
- 1. Introduction
- 2. Related Work
- 3. Pose Estimation Preliminaries
- 3.1. Detection-Based Method
- 3.2. Integral Regression Method
- 4. Bias-Compensated Integral Pose Regression
- 4.1. Derivation of Bias 偏差推导
- 4.2. Bias Compensation
- 4.3. Joint Framework
- 5. Experiments
- 5.1. Datasets and Implementation Details
- 5.2. Performance Comparison
- 5.2.1 Architecture design
- 5.2.2 Influencing Factors
- 5.2.3 Comparison Results
- 5.3. Comparison with State-of-the-Art
- 5.4. Ablation Study
- 6. Conclusion
- 7. Supplementary Material
- A. Derivation of Bias
- B. Experiment Details
1. Introduction
姿态估计的热图法保持架构的全卷积,在整个编码和解码过程中保留空间结构使得其性能优于坐标回归法。标准热图法使用 argmax 函数将输出热图解码为关键点坐标,但 argmax 有两个缺陷:① 不可微 ② 将估计坐标的分辨率固定为热图本身的分辨率。一个替代方案是采用带期望的 softmax 来解码热图,softmax 和期望函数都可微,因此既能保留完全卷积架构的优点,又能端到端训练,人体姿态估计将该方法称为积分姿态估计 integral pose estimation。
那么,基于热图的检测和积分回归哪个更适合2D姿态估计呢?两者最大区别是:积分法的收敛更慢,与积分回归的关节坐标相比,显式热图标签的监督更密集。本文表明:慢收敛也可能诱导积分回归的偏差,因为softmax与期望的组合可能会 shift 热图与gt坐标位置的对齐,反过来也限制了神经网络的学习。通过补偿偏差,我们改进了积分回归方法的学习和性能。
本文在比较性能时,深入挖掘当前基准中的变化因素,将不同的因素分开,超越了现行的单一AP和PCK平均值报告标准。我们发现:积分回归在“Hard”模式(smaller size, fewer joints, or more occlusion)下优于热图。但这些影响比较模糊,因为 hard 样本构成了数据集尾部。
最后,为了保留热图法和积分回归的优点,我们提出了一个组合学习框架:将偏差补偿纳入端到端的积分回归学习中,初始阶段利用基于检测的损失进行密集监督。 我们的贡献如下:
- 推导出 softmax 组合期望的积分姿态回归的偏差。
- 提出一种简单的补偿方案来抵消这种偏差,它可以提升训练并提高积分回归方法的性能。
- 分析了基于检测和基于回归的人体姿态估计方法在不同变化因素下的性能差异。回归方法在关节较少、遮挡较多和分辨率较低的 “Hard” 情况下表现更好。
- 提出了一种联合检测和回归的偏差补偿框架,该框架保持了快收敛与hard情况下高性能的优点,在MS COCO和MPII的2D姿态估计以及RHD的2D, 3D手势姿态估计上实现了sota。
2. Related Work
略。
本文并非为姿态估计开发新架构,而是研究了人体姿态估计回归法的潜在缺陷可能是 softmax结合期望值产生的偏差。我们的工作类似于处理量化误差的DARK和处理偏置数据的UDP。
3. Pose Estimation Preliminaries
采用 top-down 方法,cropped 人体图像 I 作为输入,标准的 2D 人体姿态估计利用一个 encoder-decoder 框架,encoder 通过一系列卷积层将图像缩小为低分辨率特征图;然后 decoder 对特征图进行上采样形成最终输出 H ∈ R h × w × K H∈ R^{h×w×K} H∈Rh×w×K,其中h和w是输入图像 I 的 shape scale factor,K个通道代表 K 个关节的输出。
3.1. Detection-Based Method
基于检测的方法中,H 显式表示为热图。推理过程通过argmax运算来估计关节 k 的坐标
J
d
J^d
Jd:

p表示热图的像素坐标。若 H与关节位置的概率密度成比例,则该公式表示在热图上取最大似然。实际中,为减少量化误差,最终坐标估计取在热图最高和次高响应之间。
训练期间,以 k 个 GT 关节点
J
g
t
J^{gt}
Jgt 为小高斯中心生成的 k 张 GT 热图
H
g
t
H^{gt}
Hgt,
H
g
t
H^{gt}
Hgt 和估计热图 H 间逐像素作MSE计算 k-th 关节的损失:

3.2. Integral Regression Method
积分回归法中,H 并非明确的热图,通过应用 softmax 进行归一化,然后求期望,将其解码为坐标。具体而言,通过softmax函数将关节 k 的估计热图 H 归一化为 H ~ \widetilde{H} H :

β 是一个平滑参数,β越小,softmax的结果越“扁平”,越大则结果越“尖锐”。softmax 确保
H
~
\widetilde{H}
H
元素总和为1,因此当取期望值来估计坐标
J
r
J^r
Jr 时,
H
~
\widetilde{H}
H
可以直接用作概率密度:

采用期望值而非 argmax 的主要优点是计算期望值可微。训练期间采用关节坐标间的L1距离作loss:

4. Bias-Compensated Integral Pose Regression
4.1. Derivation of Bias 偏差推导
用一个归一化概率密度函数来取期望值,softmax函数用于归一化H,且 softmax 也很密集,它将非零值分配给
H
~
k
\widetilde{H}_k
H
k中的所有像素,即使是H的零元素(考虑 eq(3)的分子: exp(β·0) =1)。给H的零值像素(或接近零值的像素)赋非零值反过来也 contributes to 预期值,并使估计坐标
J
r
J^r
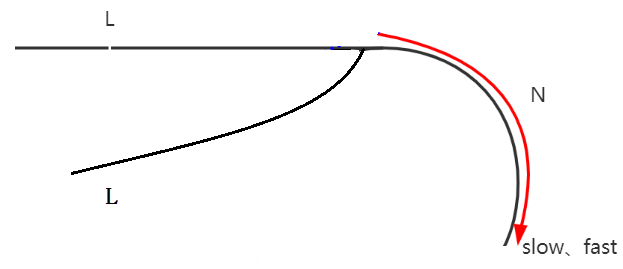
Jr偏离热图中心。如图1所示,关节坐标离中心越远,偏差越大。

在softmax中选择适当的β值,可以稍微减小偏差。β越小,函数分布的概率密度越大,H中零像素的影响越大,β越大,函数将密度集中在H的最大值附近,但当β趋近无穷大时,Softmax就会收敛到Argmax形式,函数就变成不可导了,且随着 β 增大,远离中心点像素上的梯度会变小,直到消失。 因此需要在偏差与学习梯度间进行 trade-off 。
注意,解码器可以通过学习估计一个具有 densities shifted 甚至远离中心的H来补偿这种偏差。但这样网络必须考虑关节从热图中心的偏移,为神经网络增加了额外的学习挑战。从图2中 COCO 训练数据集的关节位置分布可以看出这增加了偏差值额外变化的重要来源。训练常采用的数据增强可能会进一步加剧这种情况。

4.2. Bias Compensation
如图1所示,只有概率密度位于热图中心时才不存在偏差,自然想到直接移动坐标系并将热图置于gt关节坐标中心来补偿偏差,但这需要知道gt 关节的位置,这对于训练可行,但不适于推理。
问题根源在于:期望值趋近于中央,响应值不够大使得Soft-Argmax方法不准,而期望值趋近于中央的原因在于,Softmax后出现的多余的非零值,且这个非零值只能通过增大 β 尽可能地缩小,无法消除,甚至在这个过程中还会产生副作用(回传导数消失)。那么,换个思路,求出这些非零值,然后从结果期望值里减去这些非零值,就相当于切掉了它们。具体而言,假设我们希望恢复的真实坐标位置 (xo,yo) (即响应值)位于热图的左上象限,假设响应值符合高斯分布,根据响应最大值点两倍的宽度,把特征图划分成四个区域:Ω1包含(xo,yo),Ω2、Ω3、Ω4表示顺时针方向的其他区域(参见图1中的左上图),基于这一划分,我们可以将 eq(4) 中定义的期望划分如下:

一旦经过Softmax,原本都是0值的2、3、4象限区域瞬间会被非零值填满,而对于第1象限区域,由于响应值正处于区域的中央,因此不论响应值大小,该区域的估计期望值都是准确的。假设(xo,yo) 完全包含在Ω1中,Ω2至Ω4只包含零或接近零的元素,这样,eq(6) 仅第一项对
J
r
o
J^{ro}
Jro 有用,关节位置可以估计为 eq(6) 第一项的 scale 版本:

J
r
o
J^{ro}
Jro 定义为(xo,yo)的估计值,即偏差补偿关节位置,上述公式是隐含的,因为Ω1取决于(xo, yo),通过代数重排,可以将
J
r
o
J^{ro}
Jro公式化为
J
r
J^r
Jr的函数:

上式 C 是softmax中使用的归一化常数,即 eq(3) 的分母,C是β的函数:

从eq8,9 可以看出,当C较大时,scale因子接近1,偏差接近0,可忽略不计,使用较大的β时,情况正好如此;但C较小时,偏差变得更大。因此,若β不够大,网络必须学习非常大且集中的H§ 值进行补偿以估计正确的
J
r
J^r
Jr,这种相互作用使网络学习非常困难,从而导致积分回归法的慢收敛。补充材料描述了xo、yo位于其他象限的情况。
eq(8) 可以恢复偏差补偿关节位置
J
r
o
J^{ro}
Jro,且无需已知GT关节坐标,因此推理过程中,可以基于 eq(4) 中的期望值直接补偿有偏差的关节位置
J
r
J^r
Jr。训练期间也可以这样做,只需使用
J
r
o
J^{ro}
Jro 更新 eq(5) 的L1损失,即:

我们的方案保留softmax,并补偿期望值
4.3. Joint Framework
本文提出了一种新的结合偏差补偿的姿态估计方法,能同时实现端到端训练和快速收敛。基于检测的方法中使用 Gaussian 标签能够提供密集监督和空间信息,从而使训练有效。 但DSNT表明:pixel-wise L2损失迫使热图与 gt 完全相同,这并非我们真正关心的指标,因为该损失不能确保持续提高预测关节的准确性。
因此,我们使用基于检测的方法的逐像素监督(eq2)作为额外损失:

随时间减少λ,在训练后期最小化
L
d
e
L_{de}
Lde 的影响,并允许网络学习任意形状的隐式热图。简单起见,对 λ(t) 使用简单的阶跃函数:t<To, λ(t) =1; t>=To, λ(t)=0。联合框架的关键目的是加快训练,同时保持隐式热图的自由度,允许网络学习能够定位正确坐标位置的任何分布(而非高斯分布)。
5. Experiments
5.1. Datasets and Implementation Details
数据集与评估准则:使用COCO和MPII以及人手姿态数据集:RHD。
对COCO数据集使用OKS评估,OKS利用人体实例面积来归一化预测位置和 GT 位置间的绝对误差。使用主要竞争指标:10 OKS个阈值的平均精度(AP)来评估性能。实验还报告了归一化前的值,即预测和GT值间的平方欧几里德距离,将其表示为端点误差(EPE)。
MPII数据集使用PCK和EPE进行评估。
RHD数据集使用AUC和EPE进行评估。
实施细节:基于 Pytorch 进行使用,并使用Adam进行模型训练。使用具有不同 backbone 的SBL和HRNet 作baseline,例如SBL-ResNet50和HRNet-W32。公平起见,重跑了基于检测的方法。默认β=10,SBL的 T0 = 120 epoch,HRNet的T0=190 epoch。
5.2. Performance Comparison
5.2.1 Architecture design
为了直接比较基于检测和回归的方法,应排除影响最终性能的其他影响因素。这两种方法的框架基本相同:编码步骤从输入图像中提取特征,而解码步骤将特征转换回显式或隐式热图表示,区别仅在于损失。检测方法使用MSE损失来监督显式热图,而回归方法直接监督隐式热图取期望生成的预测关节位置。
实施比较时应用现成的模型:SBL或HRNet,作为共享的 encoding-decoding 架构来生成所有K个关键点的热图H。对于检测,使用 eq2 训练模型,使用 eq1的argmax获取最终预测结果,对于回归,采用 sota Integral human pose regression 法通过 eq4 获得关节点坐标,使用 eq5 训练模型。
5.2.2 Influencing Factors
当两种方法(包括提取和表示特征)的 capacity 相同时,两者间的区别仅在于将热图转换为坐标和监督信号的方式,因此,可以比较两种方法在训练和推理过程中的结果来研究差异。
具体而言,训练过程评估验证集或测试集的上升速度,推理过程比较验证集或测试集上不同类型样本的泛化能力。类似 [Benchmarking and error diagnosis in multi-instance pose estimation],根据图像中不同的人体分别来划分基准,考虑3个因素:当前关键点的数量(11-17、6-10、1-5)、遮挡率(<10%、10-50%、>50%)、输入bbox的最大尺度 (> 128px, 96-128px, 64-96px, 32-64px),图3所示为这三个因素的划分示例。

5.2.3 Comparison Results
SBL-ResNet50和HRNet-W32用作 baseline 来评估COCO val set的训练效率和泛化误差。
训练比较:随着迭代的增加,AP的上升速度可以评估训练效率。图4可以观察到检测和回归最后达到的精度相当,但检测法在40个epoch后能够达到可观的结果,但回归法需要90个epoch(检测法比回归法的收敛快)。原因可能是检测法应用整张空间特征图进行密集监督,而回归法仅对预期的坐标位置进行监督,因此回归法潜在的特征图是任意的,这种任意性虽热可以解释为是有益的,但确实增加了训练难度。

推理比较:表1最后一列的结果可以看出,回归法在微小姿态和多遮挡情况下表现得更好,这些情况更 hard ;此外,当前关键点的数量改变时,两种方法的性能不同,简而言之,回归法在hard模式下表现更好。

图5中可以看出,我们的方法在 hard 情况下优于回归方法,在easy情况下优于检测方法。

5.3. Comparison with State-of-the-Art
MS COCO评估。表2表3,在COCO val 和 test-dev set上的比较结果可看出,我们的方法与检测法性能相当,并很大程度上超过了回归法。


MPII的评估。结果如表4所示:

RHD的评估,结果如表5所示。

表6为不同方法的结果,检测 loss 不仅加快了训练,而且提高了性能。hard 样本的EPE结果表明我们的方法优于检测法。

5.4. Ablation Study
我们的方法有两个新组件:偏差补偿和正则化项。使用SBL-ResNet-50作为backbone,输入大小为256×192,在COCO val set上进行消融实验。图6可以看出每个组成部分都会加快训练速度。同时,表6的结果表明每个组件都有助于提高性能。

6. Conclusion
本文的主要贡献是揭示了积分姿态回归方法的偏差,首次系统性比较了检测和回归方法。并结合这两种方法的优势,补偿积分回归中的偏差。COCO、MPII和RHD上的实验结果表明,我们的方法作为插件能够大大提高baseline性能。
7. Supplementary Material
A. Derivation of Bias
如 main paper 中所定义的,通过 soft-argmax函数获得归一化热图,如下所示:

H§ 是网络的输出热图,由像素范围Ω内的像素p索引。方便起见,eq1的分母定义为变量C:

如图1所示,进一步将热图像素Ω 分成四个section: {Ω1.Ω2.Ω3.Ω4} 。定义Ω1使真实关节位置 (xo,yo) 为该 section 的期望值和中心。

我们工作中的关键假设是:真实关节位置(xo,yo)定位良好且在H中被完全包含在 Ω1 内。 因此,Ω2至Ω4只包含零或接近零的元素,代入eq1,分子部分接近1,则这4部分可以如下表示:

偏差关节位置
J
r
(
x
r
,
y
r
)
J^r(x_r, y_r)
Jr(xr,yr) 定义为整张热图的期望值,可进一步分解为四个部分:

其中,
J
1
=
(
x
o
,
y
o
)
,
J
2
=
(
x
o
,
y
o
+
w
/
2
)
,
J
3
=
(
x
o
+
h
/
2
,
w
/
2
)
,
J
4
=
(
x
o
+
h
/
2
,
y
o
+
w
/
2
)
J_1=(x_o, y_o), J_2 = (x_o, y_o + w/2 ), J_3 = (x_o + h/2 , w/2), J_4 = (x_o + h/2 , y_o + w/2 )
J1=(xo,yo),J2=(xo,yo+w/2),J3=(xo+h/2,w/2),J4=(xo+h/2,yo+w/2),由于每个区域的对称性,可以将权重w2到w4表示为w、h和C的表达式:

将 eq7 中的权重代入 eq8,且已知 w1=1−w2−w3−w4,可得以下线性方程:

尽管是从(xo,yo)位于Ω1中推导的,但当(xo,yo) 位于其他三个象限时,eq9 同样适用。观察 eq9,if xo < h/2 , then xr > xo,推动坐标向中心移动;if xo > h/2 , then xr < xo,也使得预测更接近中心,yo与xo类似。因此,该方程适用于所有象限。
因此,可以通过以下形式从Jr预测Jo:

B. Experiment Details
表1为HRNet 在不同子基准上的性能。

表2表3显示了COCO val set上被 proposal factor 划分的每个子基准中的人体数量。


表4报告了我们方法在划分的子基准上详细的EPE,以支持 main paper 的图5。








![[激光原理与应用-39]:《光电检测技术-6》- 光干涉的原理与基础](https://img-blog.csdnimg.cn/7d01ff03a27b4709be798a9425f2040e.png)

![[附源码]计算机毕业设计农村人居环境治理监管系统Springboot程序](https://img-blog.csdnimg.cn/524152c3fe744e9ca83a9aaefa5bb6f5.png)