1. sys模块介绍
什么是Python 解释器
当编写Python 代码时,通常都会得到一个包含Python 代码的以.py 为扩展名的文件。要运行编写的代码,就需要使用Python 解释器去执行.py 文件。因此,Python 解释器就是用来执行Python 代码的一种工具。常见的Python 解释器有以下几种:
-
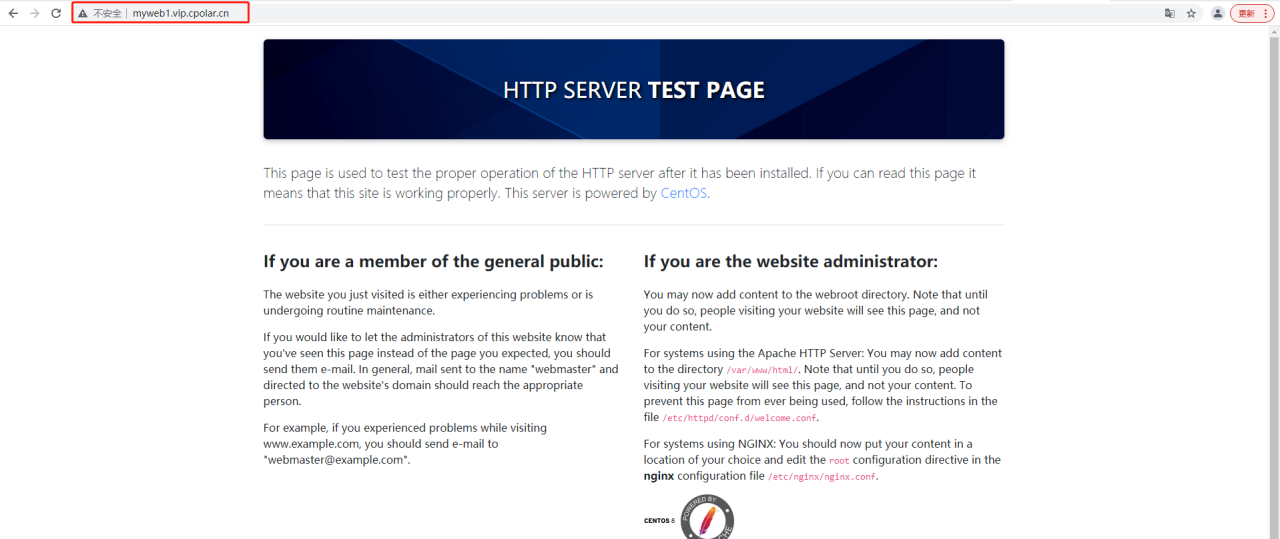
CPython:Python 的官方解释器。当我们从Python 官方网站下载并安装好Python 后,就直接获得了CPython 解释器,该解释器是使用C 语言开发的,所以叫CPython。我们在CMD 命令窗口中运行python 命令就是启动CPython 解释器,如图1 所示。
-
IPython :IPython 是基于CPython 之上的一个交互式解释器,它执行Python 代码的功能和CPython 是完全一样的,唯一的区别是:CPython 用“>>>”作为提示符,而IPython 用“In[ 序号]:”作为提示符。
-
PyPy :PyPy 解释器的目标是执行速度,它采用JIT 技术,对Python 代码进行动态编译,所以可以显著提高Python 代码的执行速度。
-
Jython:运行在Java 平台上的Python 解释器,可以直接把Python 代码编译成Java 字节码执行。
-
IronPython :运行在微软.NET平台上的Python解释器,可以直接把Python代码编译成.NET的中间代码。
sys 模块的作用
sys 模块提供访问Python 解释器使用或维护的属性,以及与Python 解释器进行交互的方法。简单来讲,sys 模块负责程序与Python 解释器的交互,并提供了一系列的属性和方法,用于操控Python 运行时的环境。
在Python 程序中使用sys 模块,首先需要使用import 导入,代码如下:
import sys
导入sys 模块后,就可以使用该模块提供的属性和方法了。
2. argv属性——程序命令行参数列表
argv 属性表示传递给Python 脚本的命令行参数列表。argv[0] 是脚本名称(取决于操作系统是否为完整路径名)。语法格式如下:
sys.argv
注意:在Unix 系统中,命令行参数是从OS 传递的字节。Python 使用文件系统编码和“surrogateescape”错误处理程序对它们进行解码。
通过使用argv 属性获取Python 解释器的命令行参数列表,并使用argv[0] 获取Python 脚本的完整路径,代码如下:
import sys
print(sys.argv)
print(sys.argv[0])
3. __breakpointhook__属性——breakpointhook()方法的初始值
__breakpointhook__ 属性用于获取程序启动时breakpointhook() 方法的初始值。在breakpointhook()方法发生重写时,可以使用__breakpointhook__ 对其初始值进行设置。语法格式如下:
sys.__breakpointhook__
说明:breakpointhook 是Python 3.7 版中新增的。
使用__breakpointhook__ 属性获取__breakpointhook__ 对象的类型,代码如下:
import sys
print(sys.__breakpointhook__)
程序运行结果如下:
<built-in function breakpointhook>
说明:上面的运行结果说明__breakpointhook__ 是一个内置函数,它是breakpointhook() 方法的默认形式。
4. base_exec_pref ix属性——获取Python安装目录
在site.py 运行之前,Python 启动时,base_exec_prefix 属性被设置为与exec_prefix 属性同样的值。如果不是运行在虚拟环境中,base_exec_prefix 属性和exec_prefix 属性的值会保持相同;如果site.py发现处于一个虚拟环境中,prefix 和exec_prefix 属性将会指向虚拟环境,而base_exec_prefix 属性将仍然会指向基础的Python 环境(用来创建虚拟环境的Python 环境)。语法格式如下:
sys.base_exec_prefix
通过使用base_exec_prefix 属性输出Python 的安装目录,代码如下:
import sys
print(sys.base_exec_prefix)
程序运行结果如下:
D:\Python\Python37
通过使用base_exec_prefix 属性输出Python 的安装目录,并判断是否安装在C 盘上,代码如下:
import sys
print(‘Python安装目录:'+sys.base_exec_prefix)
if sys.base_exec_prefix[0:1]==’C’: # 判断是否安装在C盘
print(‘Python安装在系统盘C盘中,请谨慎!')
else:
print(‘Python没有安装在系统盘C盘中,这个习惯不错哦!')
5. base_pref ix属性——获取Python虚拟环境目录
在site.py 运行之前,Python 启动时,base_prefix 属性被设置为与prefix 属性同样的值。如果不是运行在虚拟环境中,base_prefix 属性和prefix 属性的值会保持相同;如果site.py 发现处于一个虚拟环境中,prefix 和exec_prefix 属性将会指向虚拟环境,而base_prefix 属性将仍然指向基础的Python 环境(用来创建虚拟环境的Python 环境)。语法格式如下:
sys.base_prefix
通过使用base_prefix 属性输出Python 的虚拟环境目录,代码如下:
import sys
print(sys.base_prefix)
6. byteorder属性——本机字节顺序指示器
byteorder 属性表示本机字节顺序指示器。big-endian(最高有效字节在第一位)值为“big”,little-endian(最低有效字节在第一位)值为“little”。语法格式如下:
sys.byteorder
通过使用byteorder 属性获取本机的字节顺序指示器,代码如下:
import sys
print(sys.byteorder)
程序运行结果如下:
little
说明:上面结果为little,说明本机的字节存储顺序是小端序,小端序是权值低的在前面,大端序是权值高的在前面,比如0x12345678 在小端序下是按照78563412 存储的, 而大端序是按照12345678存储的。
7. builtin_module_names属性——获取Python解释器中的所有模块名称
通过builtin_module_names 属性可以得到一个字符串元组,它包含了Python 解释器中的所有模块的名称(不包括导入的模块)。语法格式如下:
sys.builtin_module_names
获取并输出Python 中的所有内置模块,代码如下:
import sys
print(sys.builtin_module_names)
8. copyright属性——Python版权信息
copyright 属性用于获取与Python 解释器相关的版权信息的字符串,语法格式如下:
sys.copyright
使用copyright 属性输出Python 解释器的版权信息,代码如下:
import sys
print(sys.copyright)
9. dont_write_bytecode属性——是否写字节码文件
dont_write_bytecode 属性用来表示是否写字节码文件,其值是一个布尔值,标识在导入模块时,Python 是否写入字节码文件(.pyc 或.pyo 文件)。初始值是True 或False,取决于-B 命令行选项和PYTHONDONTWRITEBYTECODE 环境变量的设置。开发人员可以在自己的程序中根据需要修改该设置。语法格式如下:
sys.dont_write_bytecode[=True/False]
说明:.pyc 文件是由.py 文件经过编译后生成的字节码文件,其加载速度相对于之前的.py 文件有所提高,而且还可以实现源码隐藏,以及一定程度上的反编译;而.pyo 文件是优化编译后的程序(相比于.pyc文件更小),也可以提高加载速度。对于嵌入式系统,它可将所需模块编译成.pyo 文件以减少容量。
使用dont_write_bytecode 属性获取本机Python 模块导入时是否自动生成字节码文件的标识并输出,代码如下:
import sys
print(sys.dont_write_bytecode)
程序运行结果如下:
False
说明:上面代码返回值为False,说明默认不生成字节码文件,因为.pyc 文件只有在工程目录下同时有
__main__.py 文件和其他将要调用的模块时才会生成。如果只有当前运行的脚本"__main__",则不会生成.pyc 的文件。
10. dllhandle属性——获取Python DLL的整数句柄
dllhandle 属性用于获取Python DLL 的整数句柄,仅限于Windows 系统中使用。语法格式如下:
sys.dllhandle
使用dllhandle 属性获取Python DLL 组件句柄的整数表示形式并打印,代码如下:
import sys
print(sys.dllhandle)
11. __excepthook__属性——excepthook()方法的初始值
__excepthook__ 属性表示程序启动时excepthook() 方法的初始值。在excepthook() 方法发生重写时,可以使用__excepthook__ 对其进行重置。语法格式如下:
sys.__excepthook__
输出__excepthook__ 对象的类型,代码如下:
import sys
print(sys.__excepthook__)
程序运行结果如下:
<built-in function excepthook>
说明:上面的运行结果说明__excepthook__ 是一个内置函数,它是excepthook() 方法的默认形式。
12. exec_pref ix属性——获取Python安装文件目录
exec_prefix 属性用于获取一个字符串,表示特定的目录,其中安装了与平台相关的Python 文件。语法格式如下:
sys.exec_prefix
说明:可以在构建程序时,使用configure 脚本的–exec-prefix 参数对其进行设置,其中,所有的配置文件被安装在“exec_prefix/lib/pythonX.Y/config”路径下,所有的共享模块被安装在“exec_prefix/lib/pythonX.Y/lib-dynload”路径下,X、Y 是Python 的版本号。
注意:如果虚拟环境生效,则exec_prefix 属性为虚拟环境的目录。
使用exec_prefix 属性获取Python 安装文件的目录,代码如下:
import sys
print(sys.exec_prefix)
程序运行结果如下:
J:\PythonDemo\venv
说明:上面代码运行后的返回结果是一个虚拟目录,这是在PyCharm 中创建项目时创建的虚拟目录。
13. executable属性——Python解释器的绝对路径
executable 属性用于返回一个字符串,表示Python 解释器的可执行文件的绝对路径。如果Python无法检索其可执行文件的真实路径,executable 属性将返回空字符串或None。语法格式如下:
sys.executable
获取并输出Python 解释器的绝对路径,代码如下:
import sys
print(sys.executable)
14. flags属性——启动Python时的命令行选项
flags 属性返回一个只读的结构序列,其保存并导出了启动Python 时的命令行选项。语法格式如下:
sys.flags
flags 属性包含的属性及对应命令行选项如表
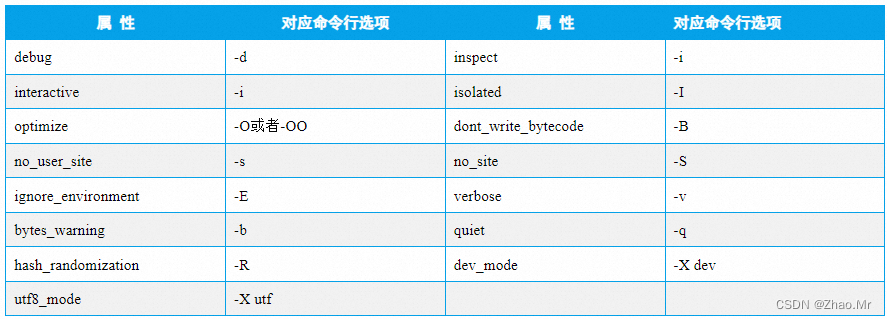
说明:1. 版本3.2 中为quiet 属性增加了-q 选项。2. 版本3.2.3 新增了hash_randomization 属性。3. 版本3.3 中删除了过时的division_warning 属性。4. 版本3.4 中为isolated 属性增加了-I 选项。5. 版本3.7 中为dev_mode 属性增加了-X dev 选项,为utf8_mode 属性增加了-X utf8 选项。
在CMD 命令窗口中,输入如下命令:
python
>>> import sys
>>> sys.flags
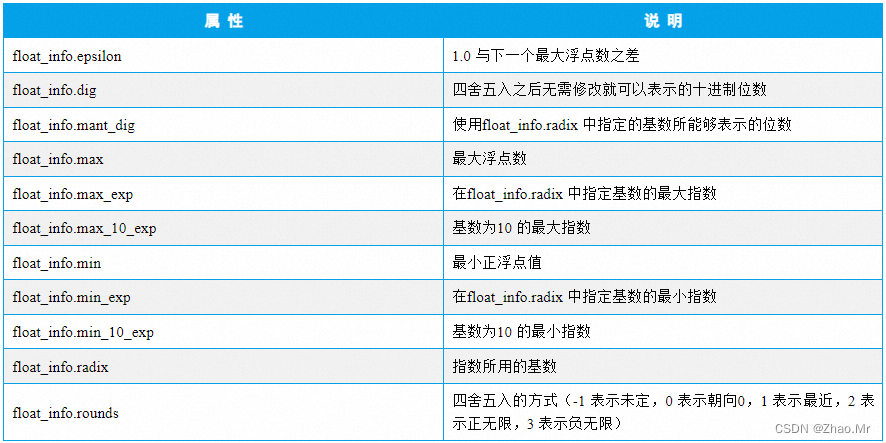
15. float_info属性——包含浮点类型的信息
float_info 属性返回包含有关浮点类型信息的结构序列,它包含有关精度和内部表示的低级信息,这些值对应于C 语言的float.h 标准头文件中定义的各种浮点常量。语法格式如下:
sys.float_info
浮点类型属性及说明如表
获取并输出Python 中浮点类型的相关信息,代码如下:
import sys
print(sys.float_info)
程序运行结果如下:
sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308,
min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53,
epsilon=2.220446049250313e-16, radix=2, rounds=1)
通过使用float_info 对象中的max 属性显示最大浮点数,代码如下:
import sys
print(sys.float_info.max)
16. float_repr_style属性——表示repr()函数输出的浮点数类型
float_repr_style 属性用于返回一个表示repr() 函数输出的浮点数类型的字符串,如果返回值为“short”,那么对于有限浮点数x,repr(x) 旨在生成具有该属性的短字符串。例如,float(repr(x)) == x。语法格式如下:
sys.float_repr_style
说明:float_repr_style 属性是Python 3.1 版本中新增的,因此只能在Python 3.1 及以上版本使用。
使用float_repr_style 属性获取repr() 函数输出的浮点数,代码如下:
import sys
print(sys.float_repr_style)
程序运行结果如下:
Short
说明:返回值为short,说明本机输出浮点数时,默认精度为16。例如,在使用下面代码输出浮点数时,print(repr(3.1415926542354543324))输出结果为:3.1415926542354544。
17. hash_info属性——获取哈希信息
hash_info 属性返回一个表示数字散列执行参数的结构序列,即哈希相关的信息。语法格式如下:
sys.hash_info
数字散列执行参数及说明如表
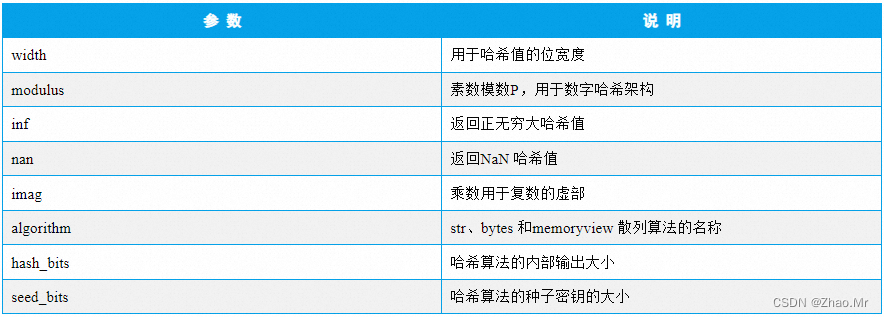
说明:
- hash_info 属性是Python 3.2 版本中新增的,因此只能在Python 3.2 及以上版本使用。
- 在Python 3.4 版本中添加了hash_bits 属性和seed_bits 属性。
获取Python 中与哈希相关的信息并输出,代码如下:
import sys
print(sys.hash_info)
18. hexversion属性——十六进制表示的版本号
hexversion 属性获取使用十六进制整数表示的版本号。该整数值总是随着更新的解释器版本而增大,包括对非生产版本的适当支持。语法格式如下:
sys.hexversion
说明:可以使用hex() 函数获取hexversion 版本号的十六进制表示形式。
获取并输出本机上当前正在运行的Python 解释器的十六进制版本号,代码如下:
import sys
print(sys.hexversion)
程序运行结果如下:
50790896
使用hexversion 属性判断当前使用的Python 解释器版本是不是3.7.1,代码如下:
import sys
if sys.hexversion == 0x030701F0:
print(‘您当前使用的是Python 3.7.1版本')
else:
print(‘您使用的Python不匹配')
19. implementation属性——当前运行的解释器的信息
implementation 属性用于返回一个包含当前运行的Python 解释器实现信息的对象。语法格式如下:
sys.implementation
包含Python 解释器信息的属性及说明如表
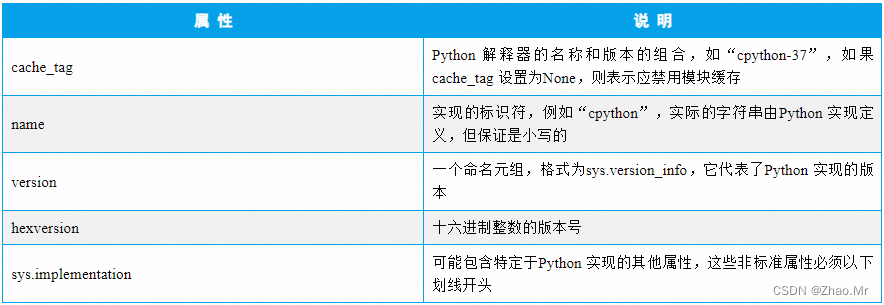
说明:implementation 属性是Python 3.3 版本中新增的,因此只能在Python 3.3 及以上版本使用。
使用implementation 属性获取当前Python 解释器的信息并输出,代码如下:
import sys
print(sys.implementation)
20. int_info属性——Python内部整数表示的信息
int_info 属性返回一个包含有关Python 内部整数相关信息的结构序列。语法格式如下:
sys.int_info
int_info 属性是只读的,它所获取到的int 相关属性如下:
-
bits_per_digit:每个数字中保持的位数。
-
sizeof_digit:用于表示数字的C语言类型的字节大小。
使用int_info 属性获取Python 中整数类型的相关信息并输出,代码如下:
import sys
print(sys.int_info)
21. __interactivehook__属性——交互模式下启动解释器
__interactivehook__ 属性用于在交互模式下启动解释器。当此属性存在,并在交互模式下启动解释器时,将自动调用其值(不带参数)。该操作在PYTHONSTARTUP 文件被读取之后进行,所以开发人员可以在那之前设置此钩子函数,钩子函数在site 模块中进行设置。语法格式如下:
sys.__interactivehook__
使用__interactivehook__ 属性获取__interactivehook__ 对象原型,代码如下:
import sys
print(sys.__interactivehook__)
程序运行结果如下:
<function enablerlcompleter.<locals>.register_readline at 0x0000015C7FDAD9D8>
使用sys.interactivehook() 获取__interactivehook__ 对象的初始值,代码如下:
import sys
print(sys.__interactivehook__())
22. maxsize属性——最大整数值
maxsize 属性表示Python 中理论上支持的最大整数值,该数值与系统有关。如果是32 位系统,最大整数值为231-1 ;如果是64 位系统,最大整数值为263-1。语法格式如下:
sys.maxsize
打印当前系统中Python 支持的最大整数值,代码如下:
import sys
print(sys.maxsize)
程序运行结果如下:
9223372036854775807
说明:虽然使用maxsize 属性获取到的Python 中的最大整数值理论上是9223372036854775807,但实际上,Python 中支持的最大整数值是无限大的,比如下面的整数也可以正常输出。
23. maxunicode属性——能够表示的最大Unicode码的整数
maxunicode 属性用于表示最大Unicode 码的整数。UCS-2 编码的默认值是65535,UCS-4 编码的默认值为1114111(0x10FFFF 十六进制)。语法格式如下:
sys.maxunicode
使用maxunicode 属性获取本机的Unicode 编码的最大整数表示并输出,代码如下:
import sys
print(sys.maxunicode)
24. meta_path属性——获取元路径查找器对象的列表
meta_path 属性用于获取元路径查找器对象的列表,其find_spec() 方法用来查看某对象是否可以找到要导入的模块。语法格式如下:
sys.meta_path
说明:
- find_spec() 方法调用时,第一个参数必须是要导入模块的绝对名称;如果要导入的模块包含在包中,则父包的__path__ 属性为第二个参数。该方法返回模块规范,如果未找到模块,返回None。
- 在Python 3.4 版本之前,使用find_module() 方法来实现与find_spec() 方法相同的功能。实际应用时,如果meta_path 中没有find_spec() 方法,则仍然可以使用find_module() 方法。
使用meta_path 属性获取Python 的默认元路径查找对象列表,代码如下:
import sys
print(sys.meta_path)
25. modules属性——将模块名称映射到已加载模块的字典
modules 属性返回一个将模块名称映射到已加载模块的字典。语法格式如下:
sys.modules
参数说明:
- 返回值:返回一个字典。
使用modules 属性获取本机所有已安装的模块及所在模块文件,代码如下:
import sys
for k, v in sys.modules.items(): # 遍历所有模块字典
print(k,’:’, v) # 打印模块及所在模块文件
程序运行结果如下:
sys : <module 'sys' (built-in)>builtins : <module 'builtins' (built-in)>_frozen_importlib : <module 'importlib._bootstrap' (frozen)>_imp : <module '_imp' (built-in)>_thread : <module '_thread' (built-in)>
_warnings : <module '_warnings' (built-in)>_weakref : <module '_weakref' (built-in)>
zipimport : <module 'zipimport' (built-in)>_frozen_importlib_external : <module 'importlib._bootstrap_external' (frozen)>_io : <module 'io' (built-in)>marshal : <module 'marshal' (built-in)>nt : <module 'nt' (built-in)>
……
说明:上面运行结果中的“(built-in)”表示该模块为内置模块。
26. path属性——指定模块搜索路径
path 属性用于获取一个字符串列表,它指定模块的搜索路径。在程序启动时,此列表的第一项path[0] 通常是Python 脚本(.py 文件)所在的目录。如果脚本目录不可用(例如,交互式调用解释器或者从标准输入读取脚本),则path[0] 为空字符串,它指示Python 首先搜索当前目录中的模块。语法格式如下:
sys.path
使用path 属性获取Python 解释器的模块搜索路径,并遍历输出,代码如下:
import sys
for i in sys.path: # 遍历所有路径列表
print(i) # 打印遍历到的路径
27. path_hooks属性——为路径创建f inder
path_hooks 属性用来为路径创建finder,它的属性值是一个callables 列表。如果可以创建一个finder,它将由callable 返回,否则拖出ImportError 异常。语法格式如下:
sys.path_hooks
获取并打印path_hooks 属性的值,代码如下:
import sys
print(sys.path_hooks)
28. path_importer_cache属性——查找程序对象缓存的字典
path_importer_cache 属性用于返回查找程序对象缓存的字典,键是已传递到sys.path_hooks 的路径,值是找到的查找程序。如果路径是有效的文件系统路径但未在sys.path_hooks 中找到查找器,则值为None。语法格式如下:
sys.path_importer_cache
使用path_importer_cache 属性获取Python 程序及其对象缓存的字典,并打印输出,代码如下:
import sys
print(sys.path_importer_cache)
29. platform属性——获取系统标识符
platform 属性返回一个表示系统标识符的字符串。语法格式如下:
sys.platform
操作系统及对应的platform 值如表
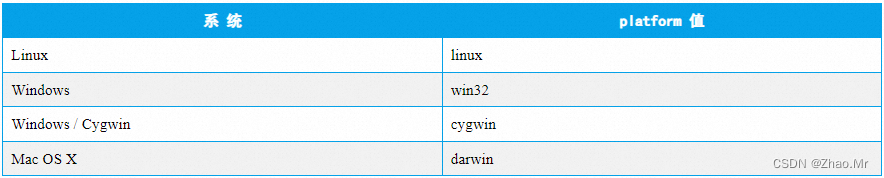
说明:从Python 3.3 版开始,在Linux 上使用platform 属性获取系统标识符时,获取到的系统标识符不再包含主要版本,即得到的结果是“linux”,而不是“linux2”或“linux3”。
使用platform 属性获取当前系统的标识符,代码如下:
import sys
print(sys.platform)
程序运行结果如下:
win32
30. pref ix属性——表示特定于站点的目录前缀
prefix 属性返回一个特定于站点的目录前缀的字符串,其中安装了与平台无关的Python 文件。语法格式如下:
sys.prefix
说明:如果虚拟环境生效,则site.py 文件中的此值将会指向虚拟环境,而Python 安装文件的值仍然可以通过base_prefix 得到。
使用prefix 属性可以获取与平台无关的Python 文件的安装目录,这里使用该属性获取Python 虚拟环境的安装目录(在PyCharm 中创建项目,然后在项目中创建Python 文件来存储下面代码),代码如下:
import sys
print(sys.prefix)
31. ps1属性——解释器的主要提示
ps1 属性用于指定解释器的主要提示字符串,该属性只有在Python 解释器处于交互模式时才可用。ps1 属性的默认值为“>>>”。语法格式如下:
sys.ps1[=value]
参数说明:
- value:表示要设置的解释器主要提示。
在CMD 命令窗口中使用ps1 属性获取主提示符的值,代码如下:
>>> import sys
>>> sys.ps1
输出运行结果如下:
'>>> '
在CMD 命令窗口中设置ps1 属性的值为“<<<”,并重新输出主提示符的值,代码如下:
>>> import sys
>>> sys.ps1='<<<'
<<<sys.ps1
输出运行结果如下:
'<<<'
32. ps2属性——解释器的辅助提示
ps2 属性用于指定解释器的辅助提示字符串,该属性只有在Python 解释器处于交互模式时才可用。ps2 默认值为“…”。语法格式如下:
sys.ps2[=value]
参数说明:
- value:可选参数,表示可以为ps2设置的特定值。
在CMD 命令窗口中使用ps2 属性获取辅助提示符的值,代码如下:
>>> import sys
>>> sys.ps2
输出运行结果如下:
'... '
在CMD 命令窗口中设置ps2 属性的值为“***”,并重新输出辅助提示符的值,代码如下:
>>> import sys
>>> sys.ps2='***'
>>> sys.ps2
输出运行结果如下:
'***'
33. stderr属性——标准错误对象
stderr 属性表示Python 解释器的标准错误对象,主要显示Python 解释器自己的提示及其错误消息。语法格式如下:
sys.stderr[=value]
参数说明:
- value:可选参数,表示可以为stderr 设置特定的标准错误输出对象。
手动改变stderr 输出形式,将错误信息写入log.txt 日志文件中,代码如下:
import sys
saveerr = sys.stderr # 在重定向前保存stderr
# 打开一个新文件用于写入。如果文件不存在,将会被创建。如果文件存在,将被覆盖
info = open(‘log.txt’, ‘w’)
sys.stderr = info # 所有后续的错误信息都会被重定向到刚才打开的新文件上
print(‘change stderr’) # 将错误“打印”到日志文件中
sys.stderr = saveerr # 重置stderr
info.close() # 关闭日志文件
34. stderr.write()方法——标准错误输出
stderr 是sys 模块中的标准错误输出流,可以实现将错误信息向屏幕、文件等进行输出。stderr通过write() 方法实现错误的标准输出。stderr.write() 方法的基本用法如下:
sys.stderr.write(obj)
参数说明:
- obj:表示输出的错误信息。
分别使用stderr.write() 方法和stdout.write() 方法在控制台中输出标准错误提示和正确的信息,对它们进行比较,代码如下:
import sys
sys.stderr.write(‘错误提示\n’)
sys.stdout.write(‘正确信息')
35. stdin属性——标准输入对象
stdin 属性表示Python 解释器的标准输入对象,它可用于所有交互式输入,包括调用input() 方法。语法格式如下:
sys.stdin[=value]
参数说明:
- value:可选参数,表示可以为stdin设置特定的标准输入对象。
获取标准输入流中输入的内容并打印输出。在标准输入流中获取输入内容时,需要使用sys.stdin.readline() 方法,代码如下:
import sys
sys.stdout.write(‘请输入字符串:') # 提示用户输入字符串
str=sys.stdin.readline() # 记录用户输入
sys.stdout.write(str) # 输出字符串
36. stdin.read()方法——获取输入的前n个字符
stdin 是sys 模块中的标准输入流,其stdin.read() 方法用来获取标准输入流中的前n 个字符。语法格式如下:
sys.stdin.read(n)
参数说明:
-
n :表示要获取的字符数。
-
返回值:返回获取到的字符。
stdin.read() 方法可以从标准输入流中获取参数指定的前n 个字符。下面是一些常用的获取内容,可以获取中文、英文、数字或者各种混合字符串的前5 个字符,代码如下:
import sys
sys.stdout.write(‘用户输入:')
str=sys.stdin.read(5) # 读取输入的前5个字符
sys.stdout.write(str) # 输出字符串
37. stdin.readline()方法——标准输入流输入
stdin 是sys 模块中的标准输入流,可以读取用户的输入。stdin 通过readline() 方法实现数据的标准输入。stdout.readline() 方法的语法格式如下:
sys.stdout.readline()
参数说明:
- 返回值:返回输入的内容。
事实上,使用input() 方法进行输入时,其实是将内容传递给stdin 标准输入流,然后通过stdout.readline() 方法进行输入;但使用stdin.readline( ) 会将标准输入全部获取,包括末尾的“\n”。因此如果想只获取输入内容,而不包括最后的换行符“\n”,应该使用如下代码:
import sys # 调用sys模块
sys.stdin.readline()[:-1]
stdout.write() 方法可以直接进行输出,配合转义字符可以进行换行、对齐等操作,但在使用前一定先导入sys 模块。下面举例列出一些常规的输出,代码如下:
import sys
sys.stdout.write(‘请输入字符串:') # 提示用户输入字符串
str=sys.stdin.readline() # 记录用户输入
sys.stdout.write(str) # 输出字符串
sys.stdout.write(‘请输入数字:') # 提示用户输入数字
str=sys.stdin.readline() # 记录用户输入
sys.stdout.write(str) # 输出数字
sys.stdout.write(‘请输入字母:') # 提示用户输入字母
str=sys.stdin.readline() # 记录用户输入
sys.stdout.write(str) # 输出字母
sys.stdout.write(‘请输入混合字符串:') # 提示用户输入混合字符串
str=sys.stdin.readline() # 记录用户输入
sys.stdout.write(str) # 输出混合字符串
输入数据时,有时可能输入了空格等非法字符,可以使用strip()、lstrip()、rstrip() 等方法去除空格,代码如下:
import sys
sys.stdout.write(‘请输入您的姓名:') # 提示用户输入字符串
name =sys.stdin.readline().strip(‘ ‘)
sys.stdout.write(‘请输入您的年龄:') # 提示用户输入字符串
age =sys.stdin.readline().lstrip(‘ ‘)
sys.stdout.write(name) # 输出字符串
sys.stdout.write(age) # 输出字符串
程序运行结果如下:
请输入您的姓名:小 王 子
请输入您的年龄: 10
小王子
10
input() 支持多个参数数据输入,输入的时候通常用split() 函数进行分割。如同时输入某一地点的坐标值,代码如下:
import sys
sys.stdout.write(‘请输入出发地点的横、纵坐标值:’) # 提示用户输入字符串
x,y=sys.stdin.readline().split(‘,’) # 一行输入两个不限定类型的值
sys.stdout.write(‘请输入你的姓名、年龄和身高:\n’) # 提示用户输入字符串
name,age,height=sys.stdin.readline().split(‘,’) # 一行输入3个不限定类型的值
a,b=map(int,sys.stdin.readline().split()) # 一行输入两个限定类型为int的值
print(x,y)
print(age)
print(a,b)
程序运行结果如下:
请输入出发地点的横、纵坐标值:123,210
请输入你的姓名、年龄和身高:
mike,15,1.75
27 89
123 210
15
27 89
通过循环语句也可以实现多数据输入,也需要使用split() 函数对输入的数据进行分割,代码如下:
import sys
sum = 0
sys.stdout.write(‘请输入多位加数,中间用空格分开:') # 提示用户输入
for x in sys.stdin.readline().split(' '):
sum = sum+int(x)
print(sum)
程序运行结果如下:
请输入多位加数,中间用空格分开:1 2 3 4 5 6 7 8
36
有时候输入的数据需要强制转化,如输入后转成整型、字符型、日期型等。下面用强制转数字int(integer)修改输出文字类型,代码如下:
import sys
sys.stdout.write(‘age:') # 提示用户输入
age = int(sys.stdin.readline())
程序运行结果如下:
age:20
强制转换字符串时,可以使用lower()、upper()、capitalize()、title() 等方法强制转换字符串为小写、大写、句子大写、单词大写等形式,代码如下:
import sys
sys.stdout.write(‘请输入您的密码:')
password = sys.stdin.readline().upper()
sys.stdout.write(‘请输入您的姓名:')
name = sys.stdin.readline().capitalize()
sys.stdout.write(‘请输入您的学校:')
school = sys.stdin.readline().title()
print(password,name,school)
程序运行结果如下:
请输入您的密码:abcdefg
请输入您的姓名:Mike
请输入您的学校:harvard
ABCDEFG Mike Harvard
在Python 中,提供了对字符串操作非常有用的验证方法,可以非常方便地判断输入文字是大写字母、小写字母、数字,或是空白。主要方法如下:
-
str.isalnum():所有字符都是数字或者字母。
-
str.isalpha():所有字符都是字母。
-
str.isdigit():所有字符都是数字。
-
str.islower() :所有字符都是小写。
-
str.isupper() :所有字符都是大写。
-
str.istitle():所有单词都是首字母大写,像标题。
-
str.isspace() :所有字符都是空白字符、\t、\n、\r。
使用str.isdigit() 可以验证输入是否为数字,例如,需要输入为纯数字方可进入系统,否则退出系统重新进入,代码如下:
import sys
sys.stdout.write(‘请输入数字验证码:')
if sys.stdin.readline()[:-1].isdigit():
print(‘正在登录程序员之家商务系统!')
else:
print(‘输入了非数字字符,请重新输入!')
在编写程序时,有时需要动态输出一些提示性文字,如程序加载、联网或杀毒时,如果需要用户等待一点时间,可以输出提示用户并显示进度。下面代码将实现在提示文字后动态输出程序加载进度的功能。
import sys
sys.stdout.write(‘请输入字符串:') # 提示用户输入字符串
str1=sys.stdin.readline() # 记录用户输入
str2=input()
sys.stdout.write(‘str1长度:'+str(len(str1))+’\n’) # 输出字符串长度
sys.stdout.write(‘str2长度:'+str(len(str2))) # 输出字符串长度
程序运行结果如下:
请输入字符串:我和我的祖国
我和我的祖国
str1长度:7
str2长度:6
说明:从上文的运行结果中可以看出,两个字符串输入的内容虽然一样,但获取的长度却不一样。这是因为,stdin.readline( ) 会将标准输入全部获取,包括末尾的“\n”,因此用len 计算长度时,是把换行符“\n”算进去了;但是input( ) 获取输入时,返回的结果是不包含末尾的换行符“\n”的。
38. stdout属性——标准输出对象
stdout 属性表示Python 解释器的标准输出对象。语法格式如下:
sys.stdout[=value]
参数说明:
- value:可选参数,表示可以为stdout设置特定的标准输出对象。
注意:要从标准流读取二进制数据,或者向标准流写入二进制数据,请使用二进制buffer对象。例如,要使用stdout写入字节,请使用“sys.stdout.buffer.write(b’abc’)”代码。
手动改变stdout 输出形式,将提示信息写入log.txt 日志文件中,代码如下:
import sys
saveout = sys.stdout # 在重定向前保存stdout
# 打开一个新文件用于写入。如果文件不存在,将会被创建。如果文件存在,将被覆盖
info = open(‘log.txt’, ‘w’)
sys.stdout = info # 所有后续的输出都会被重定向到刚才打开的新文件上
print(‘change stdout’) # 将输出结果“打印”到日志文件中,屏幕上不会看到输出
sys.stdout = saveout # 重置stdout
info.close() # 关闭日志文件
39. stdout.write()方法——标准输出流输出
stdout 是sys 模块中的标准输出流,可以实现将数据向屏幕、文件等进行输出。stdout 通过write() 方法实现数据的标准输出。语法格式如下:
sys.stdout.write(obj)
参数说明:
- obj:表示输出的内容或文件。
事实上,使用print() 方法进行打印输出时,其实是将内容传递给stdout 标准输出流,然后通过stdout.write() 方法进行输出,输出完光标会停留在输出内容的最后位置;而print() 方法输出后,光标会自动跳到下一行行首。所以要实现等同效果,需要在stdout.write() 输出时追加一个换行符,代码如下:
print('hello')
等同于:
import sys # 调用sys模块
sys.stdout.write('hello' + '\n')
stdout.write() 方法可以直接进行输出,配合转义字符可以进行换行、对齐等操作,但在使用前一定先导入sys 模块。下面举例列出一些常规的输出,代码如下:
import sys # 调用sys模块
sys.stdout.write(‘用户名称:') # 正常输出,光标在最后一个字符后面
sys.stdout.write(‘张三丰') # 在上一个光标处输出
sys.stdout.write(‘\n用户密码:') # 先换行输出,光标在最后一个字符后面
sys.stdout.write(‘********\n’) # 在上一个光标处输出,输出完内容后换行到下一行行首
sys.stdout.write(‘确认密码:')
sys.stdout.write(‘********\n’) # 输出完内容后换行到下一行行首
sys.stdout.write(‘商品名称\t’) # 输出完内容后增加一个制表符距离
sys.stdout.write(‘商品价格\t’) # 输出完内容后增加一个制表符距离
sys.stdout.write(‘采购数量\t’) # 输出完内容后增加一个制表符距离
sys.stdout.write(‘商品金额')
程序运行结果如下:
用户名称:张三丰
用户密码:********
确认密码:********
商品名称 商品价格 采购数量 商品金额
在编写程序时,有时需要动态输出一些提示性文字。如程序加载、联网或杀毒时,如果需要用户等待一点时间,可以输出提示信息并显示进度。如要实现在提示文字输出后再动态输出程序加载进度,代码如下:
import sys
import time
sys.stdout.write(‘程序正在连接网络,请稍后')
sys.stdout.write(“\n”)
for i in range(20):
sys.stdout.write('#')
time.sleep(0.3)
如果动态输出的文字希望在原始位置跑马灯似的循环输出,需要将开始文字先定位到行首,然后再输出并刷新。转义字符“\r”可以使光标回到行首,代码如下:
sys.stdout.write("\r")
使用stdout 不但可以将内容输出到屏幕,还可以输出到文件,代码如下:
import sys # 调入系统模块
sys.stdout=open('mingri.txt','w')
sys.stdout.write('hello world ')
40. stdout.flush()方法——刷新输出
在标准输出流中输出内容时,使用flush() 方法可以刷新输出。语法格式如下:
sys.stdout.flush()
实现动态跑马灯输出效果,每次循环输出1 到6 个状态,往复进行,代码如下:
import sys # 调用sys模块
import time
sys.stdout.write(‘动态输出跑马灯文字\n’)
for i in range(20):
for j in range(6):
sys.stdout.write('.')
sys.stdout.flush()
time.sleep(0.3)
在某些程序开发中,经常需要在某位置动态重复输出一些内容,如杀毒软件、计数程序、倒计时程序等。输出杀毒软件杀毒时提示用户杀毒时间的动态模拟显示,代码如下:
import sys # 调用sys模块
import time
sys.stdout.write(‘杀毒程序正在全盘检查,请稍后\n’)
for i in range(20):
sys.stdout.write("\r")
if i%2==1 :
sys.stdout.write("\\")
else:
sys.stdout.write("/")
sys.stdout.flush()
time.sleep(0.3)
41. __stderr__属性——获取stderr值的文件对象
在Python 解释器启动时,使用__stderr__ 属性获取包含stderr 值的文件对象,主要用于将实际文件还原到已知的工作文件对象,以防被破坏。但是,执行此操作的首选方法是在替换之前显式保存先前的流,并还原已保存的对象。语法格式如下:
sys.__stderr__
注意:在某些情况下,stderr 以及原始值__stderr__ 可以为None。例如,那些没有连接到控制台的Windows GUI 应用程序以及使用pythonw 启动的Python 应用程序。
获取__stderr__ 属性的原始对象信息并输出,代码如下:
import sys
print(sys.__stderr__)
42. __stdin__属性——获取stdin值的文件对象
在Python 解释器启动时,使用__stdin__ 属性获取包含stdin 值的文件对象,主要用于将实际文件还原到已知的工作文件对象,以防被破坏。但是,执行此操作的首选方法是在替换之前显式保存先前的流,并还原已保存的对象。语法格式如下:
sys.__stdin__
注意:在某些情况下,stdin 以及原始值__stdin__ 可以为None。例如,那些没有连接到控制台的Windows GUI 应用程序以及使用pythonw 启动的Python 应用程序。
获取__stdin__ 属性的原始对象信息并输出,代码如下:
import sys
print(sys.__stdin__)
43. __stdout__属性——获取stdout值的文件对象
在Python 解释器启动时,使用__stdout__ 属性获取包含stdout 值的文件对象,主要用于将实际文件还原到已知的工作文件对象,以防被破坏。但是,执行此操作的首选方法是在替换之前显式保存先前的流,并还原已保存的对象。语法格式如下:
sys.__stdout__
注意:在某些情况下,stdout 以及原始值__stdout__ 可以为None。例如,那些没有连接到控制台的Windows GUI 应用程序以及使用pythonw 启动的Python 应用程序。
获取__stdout__ 属性的原始对象信息并输出,代码如下:
import sys
print(sys.__stdout__)
44. thread_info属性——包含有关线程实现信息的结构序列
thread_info 属性表示包含有关线程实现信息的结构序列。语法格式如下:
sys.thread_info
thread_info 属性中的属性及说明如表
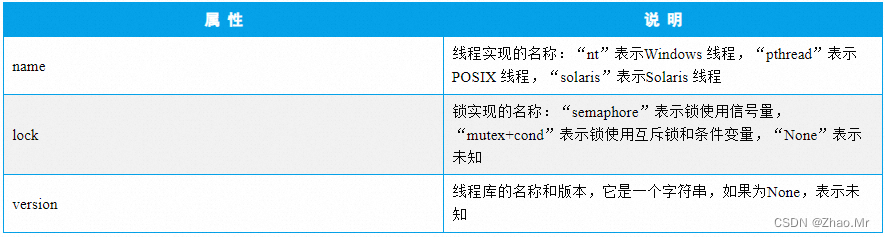
获取当前线程的相关信息并输出,代码如下:
import sys
print(sys.thread_info)
45. tracebacklimit属性——发生未处理异常时打印的最大回溯信息级别数
tracebacklimit 属性用来获取发生未处理异常时打印的最大回溯信息级别数。当其值设置为整数值时,表示发生未处理的异常时打印的最大回溯信息级别数,默认为1000 ;当设置为0 或更小时,将禁止所有回溯信息,并仅打印异常类型和值。语法格式如下:
sys.tracebacklimit=value
设置发生未处理异常时,打印的最大回溯信息级别数为100,并输出该值,代码如下:
import sys
sys.tracebacklimit=100 # 设置最大递归(回溯)层级为100级
print(sys.tracebacklimit) # 打印递归(回溯)层级
46. version属性——Python解释器的版本号等信息
version 属性返回一个包含Python 解释器的版本号、内部版本号和编译器的附加信息的字符串。语法格式如下:
sys.version
说明:不要从version 属性获取的值中提取版本信息,而应该使用version_info。
使用version 属性获取Python 解释器的版本号等信息并输出,代码如下:
import sys
print(sys.version)
程序运行结果如下:
3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD64)]
47. api_version属性——Python解释器的C API版本号
api_version 属性返回Python 解释器的C API 版本号,语法格式如下:
sys.api_version
说明:api_version 属性主要用于调试Python 和扩展模块之间的版本冲突。
使用api_version 属性获取本机安装的Python 解释器的C 语言版的API 版本号并输出,代码如下:
import sys
print(sys.api_version)
48. version_info属性——包含Python版本信息5个组件的元组
version_info 属性用于返回一个包含Python 版本信息的元组,这个元组包含了版本信息的5 个值。语法格式如下:
sys.version_info
使用version_info 属性得到的版本信息元组中的5 个值分别为:
-
major :一个整数,表示主版本号。
-
minor :一个整数,表示次版本号。
-
micro :一个整数,表示生成号。
-
releaselevel :版本级别,返回值为alpha(内测版)、beta(公测版)、candidate(候选版)、final(最版)。
-
serial :一个整数,表示修订号。
获取并输出Python 解释器的版本信息,代码如下:
import sys
print(sys.version_info)
49. warnoptions属性——警告框架的实现细节
warnoptions 属性用于获取使用命令行选项-W 时提供给解释器的警告选项列表。语法格式如下:
sys.warnoptions
说明:默认的警告选项列表为空,即[ ]。
以交互方式启动Python 解释器,启动时使用-W 指定一个警告选项。命令如下:
python -W warning
>>> import sys
>>> sys.warnoptions
输出运行结果如下:
['warning']
以交互方式启动Python 解释器,启动时使用-W 指定多个警告选项。命令如下:
python -W warning1,warning2,warning3
>>> import sys
>>> sys.warnoptions
输出运行结果如下:
['warning1,warning2,warning3']
50. winver属性——Windows平台上形成注册表项的版本号
winver 属性用于返回Python 解释器在Windows 平台上生成注册表项的版本号,它作为字符串存
储在Python DLL 中,该值通常是version 属性的前3 个字符。语法格式如下:
sys.winver
说明:winver 属性只能用于Windows 系统中。
使用winver 属性获取Python 解释器在Windows 平台上生成注册表项的版本号并打印,代码如下:
import sys
print(sys.winver)
51. _xoptions属性——获取-X命令行选项的字典
_xoptions 属性用于获取通过-X 命令行选项传递的各种指定参数标志的字典,如果明确指定了选项的值,则选项名称可以映射到指定的值,否则,映射到True。语法格式如下:
sys._xoptions
以交互方式启动Python 解释器,启动时使用-X 设置一个命令行选项,名称为test ;然后使用ys._xoptions 属性输出命令行选项test 及其对应的默认值,命令如下:
python -X test
>>> import sys
>>> sys._xoptions
输出运行结果如下:
{'test': True}
以交互方式启动Python 解释器,启动时使用-X 分别指定x 坐标和y 坐标的值都为1 ;然后使用_xoptions 属性输出命令行选项参数列表,命令如下:
python -X x=1 -X y=1
>>> import sys
>>> sys._xoptions
输出运行结果如下:
{'x': '1', 'y': '1'}
52. call_tracing()方法——递归调用/调试代码
call_tracing() 方法用于启用跟踪时调用函数func(*args) 并保存跟踪状态。语法格式如下:
sys.call_tracing(func,args)
参数说明:
-
func :表示要调用的方法名。
-
args :方法中要传递的参数,如果有多个参数,使用元组传递。
-
返回值:与要调用的方法的返回值一致。
定义一个add() 函数,计算两个数的和;然后使用call_tracing() 方法调用自定义的add() 函数,并传入两个整数;最后打印结果,代码如下:
import sys
def add(a,b): # 定义一个函数,用来计算两个数的和
return a+b # 返回值为两个数的和
# 使用call_tracing调用定义的add()函数,并传入相应的参数
result = sys.call_tracing(add, (3,4))
print(result) # 打印结果
53. _clear_type_cache()方法——清除内部类型缓存
_clear_type_cache() 方法用于清除内部类型缓存,类型缓存用于加速属性和方法的查找。语法格式如下:
sys._clear_type_cache()
说明:通常情况下,不必要清空缓存;但在一些特殊情况下,比如调试,可以使用该方法删除不必要的引用。
使用_clear_type_cache() 方法清除内部类型缓存,代码如下:
import sys
sys._clear_type_cache()
说明:_clear_type_cache() 方法是一个性能优化方法,因此执行时,没有运行结果。
54. _current_frames()方法——将线程标识符映射到最顶层堆栈
_current_frames() 方法用于返回将每个线程的标识符映射到调用该方法时该线程中当前活动的最顶层堆栈帧的字典。语法格式如下:
sys._current_frames()
参数说明:
- 返回值:返回一个字典,表示当前线程标识符的最顶层堆栈帧信息。
说明:_current_frames() 方法对于调试死锁非常有用:此函数不需要死锁线程的协作,只要这些线程的调用堆栈保持死锁,它们就会被冻结;对于非死锁线程返回的帧,在调用代码检查帧时可能与该线程的当前活动没有关系。
使用_current_frames() 方法获取当前线程标识符的最顶层堆栈帧信息,代码如下:
import sys
print(sys._current_frames())
55. breakpointhook()方法——breakpoint()的钩子函数
breakpointhook() 方法是一个钩子函数,这个钩子函数由内置函数breakpoint() 调用。默认情况下,它会进入pdb 调试器中,但可以将其设置为任何其他函数,以便可以选择使用哪个调试器。法格式如下:
sys.breakpointhook(*args, **kws)
参数说明:
-
args :可变参数,它是一个元组,允许传入0 个或者任意一个参数。
-
kws:关键字参数,它是一个字典,允许传入0 个或者任意一个含参数名的参数。
-
返回值:根据PYTHONBREAKPOINT 环境变量的值而定,具体说明如下:
breakpointhook() 作为breakpoint() 的钩子函数,是真正实现具体功能的地方。它会访问环境变量
PYTHONBREAKPOINT,从而确定hook 的引用对象,也就是说,PYTHONBREAKPOINT 的状态对 执行结果有决定性的作用。具体而言,PYTHONBREAKPOINT 存在如下几种状态:
Ø 完全不设置该环境变量:此时,hook 会引用pdb.set_trace,所以最终会进入pdb 调试器(提示:由于pdb.set_trace(*,header=None) 只接受关键字参数header,因此不要向breakpoint() 传递任何其他参数)。PYTHONBREAKPOINT= :此时,环境变量的值为空字符串,这与完全不设置该环境变量的效果相同。
Ø PYTHONBREAKPOINT=0 :此时,breakpointhook() 会立即返回None,从而禁用调试。
Ø PYTHONBREAKPOINT=some.importable.callable : 此时,breakpointhook() 将导入some.importable模块,然后通过hook 引用模块中的callable 对象。
Ø PYTHONBREAKPOINT=callable :此时,callable 表示一个内置可调用对象,PYTHONBREAKPOINT=print。
每次调用breakpointhook() 时,都会访问PYTHONBREAKPOINT 变量。如果在程序执行期间改变了PYTHONBREAKPOINT 的值,breakpointhook() 便会读取变化后的值。例如:
os.environ[‘PYTHONBREAKPOINT’] = ‘foo.bar.baz’
breakpoint() # 导入foo.bar并且自动调用foo.bar.baz()
注意:如果使用-E 命令行选项启动Python 解释器,会忽略所有PYTHON*环境变量(包括PYTHONBREAKPOINT),这意味着breakpoint() 会遵守默认行为,即中断当前程序并进入pdb 调试器。
说明:breakpointhook() 方法是Python 3.7 版本中新增的功能。
Python 官方给出的breakpointhook() 方法的原始实现代码如下:
def breakpointhook(*args, **kws):
import importlib, os, warnings
hookname = os.getenv('PYTHONBREAKPOINT')
if hookname is None or len(hookname) == 0:
hookname = 'pdb.set_trace'
elif hookname == '0':
return None
modname, dot, funcname = hookname.rpartition('.')
if dot == ‘‘:
modname = ‘builtins’
try:
# 模块导入失败,或funcname不可调用都会引发RuntimeWarning
module = importlib.import_module(modname)
hook = getattr(module, funcname)
except:
# 如果抛出异常,则不会执行hook(*args, **kws)
warnings.warn(‘Ignoring unimportable $PYTHONBREAKPOINT: {}’.format(hookname),RuntimeWarning)
# 如果实参与函数签名中的参数不匹配,则会抛出TypeError
return hook(*args, **kws)
__breakpointhook__ = breakpointhook
import sys
print(sys.breakpointhook())
56. _debugmallocstats()方法——打印关于 CPython内存分配器状态的低级信息
_debugmallocstats() 方法用于向stderr 打印关于CPython 内存分配器状态的低级信息。如果Python配置为-with-pydebug,它还会执行一些内部一致性检查。语法格式如下:
sys._debugmallocstats()
参数说明:
- 返回值:返回一个字符串,记录了关于CPython内存分配器状态的低级信息。
说明:_debugmallocstats() 方法特定于CPython,并且是在Python 3.3 中新增的方法,因此只能用于Python 3.3 及以上版本。
使用_debugmallocstats() 方法获取CPython 内存分配器状态的低级信息,并使用print() 函数打印,代码如下:
import sys
print(sys._debugmallocstats())
57. displayhook()方法——打印表达式结果
displayhook() 方法用于打印表达式结果,语法格式如下:
sys.displayhook(value)
参数说明:
-
value:表示要打印的值。
-
返回值:如果值不为None,这个函数打印repr(value) 到sys.stdout,并将值保存到builtins._中。如果repr(value) 无法编码为sys.stdout.encoding,使用sys.stdout.errors 错误处理程序;如果可以编码为sys.stdout.encoding,则使用backslashreplace 错误处理程序。
说明:Python 官方给出的displayhook() 方法的原始实现代码如下:
def displayhook(value):
if value is None:
return
# 将“_”设置为None,以防止递归
builtins._ = None
text = repr(value)
try:
sys.stdout.write(text)
except UnicodeEncodeError:
bytes = text.encode(sys.stdout.encoding, 'backslashreplace')
if hasattr(sys.stdout, 'buffer'):
sys.stdout.buffer.write(bytes)
else:
text = bytes.decode(sys.stdout.encoding, 'strict')
sys.stdout.write(text)
sys.stdout.write("\n")
builtins._ = value
displayhook() 方法只有一个参数,但参数的类型可以任意,即可传入任意类型的值。例如:
import sys
sys.displayhook(2) # 传入整数值
sys.displayhook(‘Test’) # 传入字符串
sys.displayhook(True) # 传入bool值
sys.displayhook([‘python’,’c’]) # 传入列表
sys.displayhook((‘python’,’c’)) # 传入元组
程序运行结果如下:
2
'Test'
True
['python', 'c']
('python', 'c')
说明:上面代码中并没有使用print() 函数打印输出,但还是可以正常地输出displayhook() 方法中传入的参数值,这说明displayhook() 方法的实现效果就是将参数打印到标准输出。
58. excepthook()方法——发生未捕获异常时调用
发生未捕获异常时调用该方法,默认行为是打印该异常并回溯到标准错误。但是,可以通过为其分配另一个包含三个参数的函数来自定义这种顶级异常的excepthook() 方法处理。语法格式如下:
sys.excepthook(type,value,traceback)
参数说明:
-
type:表示异常类。
-
value:表示异常实例。
-
traceback:表示回溯对象。
-
返回值:返回未捕获的异常信息。
使用exc_info() 方法捕获除数为0 的异常信息,然后使用excepthook() 方法打印异常信息,代码如下:
import sys
try:
result = 1/0
except:
types, value, back = sys.exc_info() # 捕获异常
sys.excepthook(types, value, back) # 打印异常
59. exec_info()方法——捕获正在处理的 异常信息
exec_info() 方法用于捕获正在处理的异常信息,它的返回值是一个包含三个值的元组,这些值提供有关当前正在处理的异常信息,返回的信息仅针对当前线程和当前堆栈帧。如果当前堆栈帧未处理异常,则从调用堆栈帧或其调用者那里获取信息,依此类推,直到找到正在处理异常的堆栈帧。这里,“处理异常”被定义为“执行except 子句”,对于任何堆栈帧,只能访问有关当前处理的异常信息。语法格式如下:
sys.exc_info()
参数说明:
- 返回值:返回一个包含了三个值的元组,存储正在处理的异常信息。
使用try…except 捕获除数为0 的异常,并使用exc_info() 方法输出异常相关类、实例及回溯对象,代码如下:
import sys
try:
print(1/0)
except:
print(sys.exc_info()) # 捕获并打印异常相关信息
60. exit()方法——退出Python
exit() 方法用于退出Python 解释器,即退出正在运行的程序。语法格式如下:
sys.exit([arg])
参数说明:
-
arg :可选参数,该参数是一个整数,表示退出状态。0 表示正常退出,非0 表示异常终止。如果指定为一个非整数值,则将它打印到sys.stderr,并使用退出码1。
-
返回值:返回退出码,0 表示正常退出,1 表示异常退出。
说明:arg 参数的取值范围通常在0~127 范围内,否则会产生不确定的结果。
正常退出程序的代码如下:
import sys
sys.exit()
程序运行结果如下:
Process finished with exit code 0
通过为exit() 方法指定非0 参数异常终止程序,代码如下:
import sys
sys.exit(1)
程序运行结果如下:
Process finished with exit code 1
61. getallocatedblocks分配的内存块数量
getallocatedblocks() 方法用于返回Python 解释器当前分配的内存块数量。该功能主要用于跟踪和调试内存泄漏。如果Python 构建或实现无法合理地计算此信息,getallocatedblocks() 方法则返回0。语法格式如下:
sys.getallocatedblocks()
参数说明:
- 返回值:返回当前分分配的内存块数量。
说明:1. 由于Python 解释器的内部缓存等原因,结果可能会因调用而不同,这时最好调用_clear_type_cache() 方法和gc.collect() 方法获得更为准确的结果。2. getallocatedblocks() 方法是Python 3.4 版本中新增加的,因此只能在Python 3.4 及以上版本中才可以使用。
使用getallocatedblocks() 方法获取Python 解释器当前分配的内存块数量,并使用print() 方法打印输出,代码如下:
import sys
print(sys.getallocatedblocks())
62. getcheckinterval()方法——获取解释器的检查间隔
getcheckinterval() 方法用于返回检査间隔值(以毫秒为单位)。语法格式如下:
sys.getcheckinterval()
参数说明:
- 返回值:返回解释器的检查间隔值。
说明:从Python 3.2 版本开始,不推荐使用getcheckinterval() 方法,而应该使用getswitchinterval() 方法
使用getcheckinterval() 方法获取Python 解释器的默认检查间隔,代码如下:
import sys
print(sys.getcheckinterval()) # 打印默认检查间隔
程序运行结果如下:
100
J:/PythonDemo/Python速查手册/sysDemo.py:49: DeprecationWarning: sys.getcheckinterval()and sys.setcheckinterval() are deprecated. Use sys.getswitchinterval() instead.print(sys.getcheckinterval()) # 打印默认检查间隔
说明:上面的运行结果中输出了默认检查间隔为100,但同时下面有个警告,提示getcheckinterval() 方法已经过期,推荐使用sys.getswitchinterval()。
63. getdefaultencoding()方法——获取默认字符串编码名称
getdefaultencoding() 方法用于返回当前默认字符串编码的名称,语法格式如下:
sys.getdefaultencoding()
参数说明:
- 返回值:返回类似“ascii”“utf-8”或者“gbk”等的字符串,具体的值根据site.py 模块中设置的默认编码而定。
使用etdefaultencoding() 方法获取本地Python 解释器使用的默认字符串编码,代码如下:
import sys
print(sys.getdefaultencoding())
64. getf ilesystemencoding()方法——获取文件系统使用的编码名称
getfilesystemencoding() 方法用于返回将Unicode 文件名映射到底层操作系统使用的文件名的编码名称,即文件系统使用的编码名称。语法格式如下:
sys.getfilesystemencoding()
参数说明:
- 返回值:有以下4 种情况:
Ø 在UTF-8 模式下,在任何平台上都是utf-8 编码。
Ø 在Mac OS X 平台上,编码是utf-8。
Ø 在Unix 平台上,编码是本地设置的编码。
Ø 在Windows 平台上,编码可能是utf-8 或mbcs,取决于用户配置。
说明:为了确保使用正确的编码和解码模式,应该使用os.fsencode() 和os.fsdecode() 对文件名进行编码和解码。
使用getfilesystemencoding() 方法获取本地文件系统的编码名称并输出,代码如下:
import sys
print(sys.getfilesystemencoding())
65. getf ilesystemencodeerrors()方法——获取 文件名转换时的错误模式名称
getfilesystemencodeerrors() 方法用于返回在Unicode 文件名和字节文件名之间进行转换时产生的错误模式名称。语法格式如下:
sys.getfilesystemencodeerrors()
参数说明:
- 返回值:返回文件名转换时的错误模式名称。
使用getfilesystemencodeerrors() 方法获取本地Unicode 文件名和字节文件名之间转换时产生的错误模式名称,并使用print() 输出,代码如下:
import sys
print(sys.getfilesystemencodeerrors())
66. getrefcount()方法——获取对象的引用计数
getrefcount() 方法用于返回对象的引用计数。语法格式如下:
sys.getrefcount(object)
参数说明:
-
object:表示任意一个对象。
-
返回值:返回object 的引用计数。返回的计数通常比预期的高一个,因为使用参数引用时,参数会引用一次,同时参数会自动产生一个临时引用。
定义一个测试类,分别以构造函数直接创建对象的方式和对象的方式向getrefcount() 方法中传入参数,并分别输出它们的引用计数,代码如下:
import sys
class Test: # 定义一个类
pass
t = Test() # 创建类的对象
print(sys.getrefcount(Test())) # Test()作为参数
print(sys.getrefcount(t)) # 对象t作为参数
程序运行结果如下:
1
2
说明:使用Test() 作为参数,返回1,因为Test() 不是引用;而使用对象t 作为参数,t 本身就是引用Test(),但是它又引用了一次Test(),所以输出为2。
分别向getrefcount() 方法中传入几个不同大小的整数,并输入它们的引用计数,比较输出结果,代码如下:
import sys
print(‘参数为1:',sys.getrefcount(1))
print(‘参数为256:',sys.getrefcount(256))
print(‘参数为257:',sys.getrefcount(257))
print(‘参数为1111111:',sys.getrefcount(1111111))
print(‘参数为-5439:',sys.getrefcount(-5439))
程序运行结果如下:
参数为1: 1587
参数为256: 75
参数为257: 3
参数为1111111: 3
参数为-5439: 3
说明:在Python 启动解释器时,会创建一个小整数池,-5~256 之间的整数对象会被自动创建并加载到内存中等待调用,所以会根据值的不同,输出不同的计数;而在此范围之外的所有整数作为参数时,getrefcount() 返回固定值3。
67. getrecursionlimit()方法——获取递归限制的值
getrecursionlimit() 方法返回递归限制的当前值,即Python 解释器可递归的最大深度。该功能可防止无限递归引起堆栈溢出并导致Python 崩溃。语法格式如下:
sys.getrecursionlimit()
参数说明:
- 返回值:返回一个整数,表示Python 解释器可递归的最大深度,默认为1000,可以使用setrecursionlimit() 方法改变该值。
使用getrecursionlimit() 方法获取Python 解释器的默认递归限制值并输出,代码如下:
import sys
print(‘默认递归次数:',sys.getrecursionlimit()) # 打印默认递归深度
68. getsizeof()方法——返回对象占用的内存大小
getsizeof() 方法用于查看python 对象的内存占用,单位为字节(byte)。语法格式如下:
sys.getsizeof(object[,default])
参数说明:
-
object:表示要检测的对象。
-
default:可选参数。若指定了该参数,如果对象未提供检索大小的方法,则返回default,否则抛出TypeError 异常。
-
返回值:返回对象占用的内存大小。
使用getsizeof() 方法获取不同类型对象所占用的内存大小,代码如下:
import sys
print(‘列表:',sys.getsizeof([]))
print(‘元组:',sys.getsizeof(()))
print(‘字典:',sys.getsizeof({}))
print(‘字符串:',sys.getsizeof(‘‘))
print(‘字节:',sys.getsizeof(b’bytes’))
print(‘整数:',sys.getsizeof(1))
print(‘小数:',sys.getsizeof(3.14))
程序运行结果如下:
列表: 64
元组: 48
字典: 240
字符串: 49
字节: 38
整数: 28
小数: 24
说明:getsizeof() 方法实际上是调用了__sizeof__() 方法。例如,获取字符串占用的内存大小可以使用下面代码:print(‘’.__sizeof__())
69. getswitchinterval()方法——获取线程切换间隔
getswitchinterval() 方法用于返回Python 解释器的线程切换间隔,单位为秒。语法格式如下:
sys.getswitchinterval()
参数说明:
- 返回值:返回以秒为单位表示的线程的切换间隔。
说明:在Python 3.2 及以上的版本中,使用getswitchinterval() 方法代替了原来的getcheckinterval() 方法。
使用getswitchinterval() 方法获取Python 解释器默认的线程切换间隔,代码如下:
import sys
print(sys.getswitchinterval()) # 打印默认线程间隔
70. _getframe()方法——返回一个框架对象
_getframe() 方法用于从调用堆栈返回一个框架对象。语法格式如下:
sys._getframe([depth])
参数说明:
-
depth:可选参数。如果省略depth 或depth 为0,返回顶层帧;否则,返回堆栈顶部下方多次调用的框架对象。如果它比调用堆栈更深,则引发ValueError 异常。depth 的默认值为零,表示返回调用堆栈顶部的框架。
-
返回值:返回框架对象。
说明:_getframe([depth]) 方法仅用于内部和专用目的,并不保证在Python 的所有实现中都存在。
为_getframe() 方法传入参数0,以获取调用堆栈顶部的框架对象,代码如下:
import sys
print(sys._getframe(0))
71. getprof ile()方法——获取探查器函数
getprofile() 方法用于获取由setprofile() 方法设置的探查器函数。语法格式如下:
sys.getprofile()
参数说明:
- 返回值:返回设置的探查器函数。
首先获取默认的探查器函数,然后使用setprofile() 函数设置一个自定义的探查器函数,最后使用getprofile() 获取设置之后的探查器函数,代码如下:
import sys
# 定义一个函数,用来作为探查器函数,必须定义三个参数
def Test(frame,event,arg):
caller=frame.f_back # 获取当前堆栈
print(‘call’,caller) # 返回调用的堆栈信息
def testA(): # 测试输出
print('testA')
def testB(): # 测试输出
print(‘testB’)
testA() # 调用testA()
print(‘默认探查器函数:', sys.getprofile()) # 获取默认探查器函数
sys.setprofile(Test) # 设置探查器函数
testB() # 调用testB()
print(‘设置的探查器函数:',sys.getprofile()) # 获取设置的探查器函数
72. gettrace()方法——获取设置的跟踪函数
gettrace() 方法用于获取由settrace() 方法设置的跟踪函数。语法格式如下:
sys.gettrace()
参数说明:
- 返回值:返回设置的跟踪函数。
说明:gettrace() 方法仅用于实现调试器、分析器、覆盖工具等,它是实现平台的一部分,而不是语言定义的一部分,因此,该方法并非在所有Python 实现中都可用。
首先获取默认的跟踪函数,然后使用settrace() 函数设置一个自定义的跟踪函数,最后使用gettrace() 获取设置之后的跟踪函数,代码如下:
import sys
# 定义一个函数,用来作为跟踪函数,必须定义3个参数
def Test(frame,event,arg):
caller=frame.f_back # 获取当前堆栈
print(‘call’,caller) # 返回调用的堆栈信息
def testA(): # 测试输出
print('testA')
def testB(): # 测试输出
print(‘testB’)
testA() # 调用testA()
print(‘默认跟踪函数:', sys.gettrace()) # 获取默认跟踪函数
sys.settrace(Test) # 设置跟踪函数
testB() # 调用testB()
print(‘设置的跟踪函数:',sys.gettrace()) # 获取设置的跟踪函数
73. getwindowsversion()方法——获取Windows版本信息
getwindowsversion() 方法用于返回一个描述当前正在运行的Windows 版本的元组,该元组包括五个元素,分别是major、minor、build、platform 和text。其中,major 是主版本号;minor 是次版本号;build 是Windows 编译号;platform 是平台标识,值可以为0(表示Window 3.1 上的Win32)、1(表示Windows 95、98 或Me)、2(表示Windows NT,如Window XP、Windows 10 等);text 是Windows的SP 补丁信息。语法格式如下:
sys.getwindowsversion()
参数说明:
- 返回值:返回Windows 的版本信息。
说明:getwindowsversion() 方法只能在Windows 操作系统中使用。
使用getwindowsversion() 方法获取当前的Windows 版本信息,并输出到屏幕中,代码如下:
import sys
print(sys.getwindowsversion())
程序运行结果如下:
sys.getwindowsversion(major=10, minor=0, build=18362, platform=2, service_pack='')
使用getwindowsversion() 方法获取当前的Windows 版本信息,并分别输出到屏幕中,代码如下:
import sys
# 检测Windows版本号
__MAJOR, __MINOR, __MICRO = sys.getwindowsversion()[0], sys.getwindowsversion()[1],sys.getwindowsversion()[2]
print(‘Windows主版本号:’ + str(__MAJOR))
print(‘Windows次版本号:’ + str(__MINOR))
print(‘Windows编译号:’ + str(__MICRO))
74. get_asyncgen_hooks()方法——返回 asyncgen_hooks对象
get_asyncgen_hooks() 方法用于返回一个asyncgen_hooks 对象,它类似于一个命名元组(firstiter,finalizer),其中,firstiter 和finalizer 应该是None,或者采用异步迭代器作为参数的函数。语法格式如下:
sys.get_asyncgen_hooks()
参数说明:
- 返回值:返回asyncgen_hooks对象。
说明:get_asyncgen_hooks() 方法是Python 3.6 版本中新增的功能,因此只能在Python 3.6 及以上版本中使用。
使用get_asyncgen_hooks() 方法获取asyncgen_hooks 对象默认值并输出,代码如下:
import sys
print(sys.get_asyncgen_hooks())
75. get_coroutine_origin_tracking_depth()方法 ——获取当前的协程源跟踪深度
get_coroutine_origin_tracking_depth() 方法用于获取当前的协程源跟踪深度。语法格式如下:
sys.get_coroutine_origin_tracking_depth()
参数说明:
- 返回值:返回当前的协程源跟踪深度。
说明:get_coroutine_origin_tracking_depth() 方法是Python 3.7 版本中新增的功能,因此只能在Python 3.7及以上版本中使用。
先获取当前的协程源跟踪深度,然后使用set_coroutine_origin_tracking_depth() 设置该值,设置完成后再次获取,进行比较,代码如下:
import sys
print(‘默认:',sys.get_coroutine_origin_tracking_depth())
sys.set_coroutine_origin_tracking_depth(10)
print(‘设置后:',sys.get_coroutine_origin_tracking_depth())
76. get_coroutine_wrapper()方法——返回None或一个包装器
get_coroutine_wrapper() 方法用于返回None 或由set_coroutine_wrapper() 设置的包装器。语法格式如下:
sys.get_coroutine_wrapper()
参数说明:
- 返回值:返回一个包装器或None值。
说明:get_coroutine_wrapper() 方法是Python 3.5 版本中新增的功能,但从Python 3.7 开始不推荐使用,因为协程包装器功能已被弃用,而且将在Python 3.8 中删除,所以了解即可。
首先使用get_coroutine_wrapper() 方法获取默认包装器,然后设置一个自定义的包装器后,再次获取,比较两次获取的结果,代码如下:
import sys
print(‘默认包装器',sys.get_coroutine_wrapper())
def wrapper(coro):
async def wrap(coro): # 异步函数
return await coro # 程序挂起
return wrap(coro)
sys.set_coroutine_wrapper(wrapper) # 设置包装器
print(‘设置的包装器',sys.get_coroutine_wrapper())
程序运行结果如下:
默认包装器 NoneJ:/PythonDemo/Python速查手册/sysDemo.py:20: DeprecationWarning: get_coroutine_wrapperis deprecated
设置的包装器 <function wrapper at 0x0000026AF10ED2F0>print('默认包装器',sys.get_coroutine_wrapper())
J:/PythonDemo/Python速查手册/sysDemo.py:25: DeprecationWarning: set_coroutine_wrapperis deprecated
sys.set_coroutine_wrapper(wrapper) # 设置包装器
J:/PythonDemo/Python速查手册/sysDemo.py:26: DeprecationWarning: get_coroutine_wrapperis deprecated
print('设置的包装器',sys.get_coroutine_wrapper())
说明:上面的输出结果中,每调用一次get_coroutine_wrapper() 方法或者set_coroutine_wrapper() 方法,都会提示该方法已经过时,所以,这里只需要了解这两个方法即可,因为在Python 3.8 版本中,这两个方法就会被彻底删除。
77. intern()方法——获取字符串或副本
intern() 方法用于返回字符串本身或副本。该方法的主要作用在于性能优化,它会维护一个内部字符串表,这个内部字符串表的意义在于:当你试图实现一个字符串时,函数会优先在表中查找它,如果字符串存在,直接返回;如果不存在,intern() 方法会将其保存,并从中返回。语法格式如下:
sys.intern(string)
参数说明:
-
string:表示字符串。
-
返回值:返回字符串本身或副本。
使用intern() 方法获取字符串的实现代码如下:
import sys
print(sys.intern('hello'))
78. is_f inalizing()方法——获取是否关闭Python解释器
is_finalizing() 方法用于获取是否关闭Python 解释器。如果Python 解释器正在关闭,返回True,否则返回False。语法格式如下:
sys.is_finalizing()
参数说明:
- 返回值:返回一个布尔值,True 表示Python解释器关闭,False表示Python解释器未关闭。
说明:is_finalizing() 方法是Python 3.5 版本中新增的功能,因此只能在Python 3.5 及以上版本中使用。
使用is_finalizing() 方法获取Python 解释器是否正在关闭,并使用print() 函数输出得到的结果,代码如下:
import sys
print(sys.is_finalizing())
79. set_asyncgen_hooks()方法——设置事件循环中的 异步生成器终结器和迭代拦截器
set_asyncgen_hooks() 方法用于设置事件循环中的异步生成器终结器和迭代拦截器,允许事件循环拦截异步生成器的迭代和终结,这样最终用户就不需要关心终结问题,一切都可以正常工作。语法格式如下:
sys.set_asyncgen_hooks(firstiter, finalizer)
参数说明:
-
firstiter:表示一个可调用函数,当异步生成器第一次迭代时被调用。
-
finalizer:表示一个可调用函数,当异步生成器即将被垃圾回收时调用。
说明:set_asyncgen_hooks(firstiter, finalizer) 方法是Python 3.6 版本中新增的功能,因此只能在Python 3.6及以上版本中使用。
使用set_asyncgen_hooks() 方法修改asyncio 异步IO,以便允许异步生成器的安全终结,代码如下:
class BaseEventLoop:
def run_forever(self):
...
old_agen_hooks = sys.get_asyncgen_hooks() # 获取默认的异步生成器函数
# 设置新的异步生成器终结器和拦截迭代器
sys.set_asyncgen_hooks(firstiter=self._asyncgen_firstiter_hook,
finalizer=self._asyncgen_finalizer_hook)
try:
...
finally:
...
sys.set_asyncgen_hooks(*old_agen_hooks) # 如果出现异常,设置默认的异步生成器
# 定义异步生成器即将被垃圾回收时调用的函数
def _asyncgen_finalizer_hook(self, agen):
self._asyncgens.discard(agen)
if not self.is_closed():
self.call_soon_threadsafe(self.create_task, agen.aclose())
# 定义异步生成器第一次迭代时使用的函数
def _asyncgen_firstiter_hook(self, agen):
if self._asyncgens_shutdown_called:
...
说明:上面代码位于Python 安装路径下的Lib\asyncio 文件夹中的base_events.py 文件中。
80. set_coroutine_origin_tracking_depth()方法 ——允许启用或禁用协同源跟踪
set_coroutine_origin_tracking_depth() 方法用于允许启用或禁用协同源跟踪。启用时,coroutine_origin对象上的属性将包含(filename,line number,function name) 元组,这个元组描述创建协同程序对象的回溯,最先调用最近的调用;禁用时,coroutine_origin 将为None。语法格式如下:
sys.set_coroutine_origin_tracking_depth(depth)
参数说明:
- depth:表示要设置的协同源跟踪深度,为0 表示禁用协同源跟踪。
说明:set_coroutine_origin_tracking_depth(depth) 方法是Python 3.7 版本中新增的功能, 因此只能在Python 3.7 及以上版本中使用。
获取当前的协程源默认跟踪深度,然后使用set_coroutine_origin_tracking_depth() 设置深度值为10,设置完成后,再次获取协程源跟踪深度,代码如下:
import sys
print(‘默认:',sys.get_coroutine_origin_tracking_depth())
sys.set_coroutine_origin_tracking_depth(10)
print(‘设置后:',sys.get_coroutine_origin_tracking_depth())
81. set_coroutine_wrapper()方法——允许拦截协同程序对象的创建
set_coroutine_wrapper() 方法用于允许拦截协同程序对象的创建(只有由async def 定义的函数、由types.coroutine() 或者asyncio.coroutine() 创建的装饰器可以不被拦截)。语法格式如下:
sys.set_coroutine_wrapper(wrapper)
参数说明:
- wrapper :必须是以下两种情况之一:一是接受一个参数(一个协程对象)的回调函数;二是None,用来重置包装器。
如果调用两次,则新包装器将替换前一个包装器,该函数是特定于线程的。
说明:set_coroutine_wrapper(wrapper) 方法是Python 3.5 版本中新增的功能,但从Python 3.7 开始不推荐使用,因为协程包装器功能已被弃用,而且将在Python 3.8 中删除,所以了解即可。
定义一个wrapper() 函数,在该函数中嵌套一个异步函数,执行程序的挂起操作;然后使用set_coroutine_wrapper() 方法设置包装器,代码如下:
import sys
def wrapper(coro):
async def wrap(coro): # 异步函数
return await coro # 程序挂起
return wrap(coro)
sys.set_coroutine_wrapper(wrapper) # 设置包装器
程序运行结果如下:
J:/PythonDemo/Python速查手册/sysDemo.py:24: DeprecationWarning: set_coroutine_wrapper isdeprecated
sys.set_coroutine_wrapper(wrapper) # 设置包装器
说明:上面的输出结果中,提示set_coroutine_wrapper() 方法已经过时,所以,这里只需要了解这个方法即可,因为在Python 3.8 版本中,这个方法就会被彻底删除。
82. setcheckinterval()方法——设置解释器的检查间隔
setcheckinterval() 方法用于设置解释器的“检查间隔”,此整数值确定解释器检查周期性事物(如线程切换和信号处理程序)的频率。默认值是100,意味着每100 条Python 虚拟指令执行一次检查。将其设置为更大的值,可以提高使用线程的程序的性能;而如果将其设置为小于等于0 的值,将检查每个虚拟指令,从而最大限度地提高响应速度和开销。语法格式如下:
sys.setcheckinterval(interval)
参数说明:
- interval:表示要设置的检查间隔。
说明:从Python 3.2 版本开始,不推荐使用setcheckinterval() 方法,而应该使用setswitchinterval() 方法。
首先获取Python 解释器的默认检查间隔,然后使用setcheckinterval() 将检查间隔设置为10,再次获取设置之后的Python 解释器检查间隔,代码如下:
import sys
print(sys.getcheckinterval()) # 打印默认检查间隔
sys.setcheckinterval(10) # 手动设置检查间隔为10
print(sys.getcheckinterval()) # 打印设置完的检查间隔
程序运行结果如下:
100
10
print(sys.getcheckinterval())J:/PythonDemo/Python速查手册/sysDemo.py:20: DeprecationWarning: sys.getcheckinterval()and sys.setcheckinterval() are deprecated. Use sys.setswitchinterval() instead.
sys.setcheckinterval(10)J:/PythonDemo/Python速查手册/sysDemo.py:21: DeprecationWarning: sys.getcheckinterval()
and sys.setcheckinterval() are deprecated. Use sys.getswitchinterval() instead.print(sys.getcheckinterval())
说明:上面的运行结果中输出了检查间隔为100 和手动设置后的检查间隔10,但同时下面有两个警告,提示setcheckinterval() 和getcheckinterval() 方法已经过期,推荐使用getswitchinterval() 和setswitchinterval()。
83. setprof ile()方法——设置函数以允许对Python源码分析
setprofile() 方法用于设置系统的配置文件函数,允许您在Python 中实现Python 源代码分析器。系统配置文件函数的调用类似于系统的跟踪函数(请参考settrace() 方法),但它是使用不同的事件调用的。例如,不会为每个执行的代码行调用它,而是在调用和返回时调用它,但会报告返回事件。setprofile() 方法是特定于线程的,但是探查器无法知道线程之间的上下文切换,因此存在多个线程时,使用它是没有意义的。另外,它的返回值没有使用,所以它可以简单地返回None。语法格式如下:
setprofile(profilefunc)
参数说明:
- profilefunc:表示要设置的系统配置文件函数名称。系统配置文件函数应该有三个参数:frame、event 和arg,它们的含义如下:
Ø frame :当前的堆栈帧。
Ø event :一个字符串,可以是“call”“return”“c_call”“c_return”或“c_exception”,它们的含义如下:
Ø call:一个函数(或输入的代码块)被调用,配置文件函数将访问它,arg 是None。
Ø return :返回一个函数(或代码块),配置文件函数将访问它,arg 是要返回的值,或者
Ø None(如果事件引发异常)。
Ø c_call:一个C函数将被调用,这个函数可以是扩展函数或内置函数。 arg是C函数对象。
Ø c_return :返回一个C函数,arg 是C函数对象。
Ø c_exception:一个C函数引发的异常,arg 是C函数对象。
Ø arg :取决于事件类型。
使用setprofile() 函数设置一个自定义的探查器函数,以便在程序执行过程中,对代码进行分析,代码如下:
import sys
# 定义一个函数,用来作为探查器函数,必须定义3个参数
def Test(frame,event,arg):
caller=frame.f_back # 获取当前堆栈
print(‘call’,caller) # 返回调用的堆栈信息
def testA(): # 测试输出
print('testA')
def testB(): # 测试输出
print('testB')
testA() # 调用testA()
sys.setprofile(Test) # 设置探查器函数
testB() # 调用testB()
84. setrecursionlimit()方法——设置递归限制的值
setrecursionlimit() 方法用于设置Python 解释器的最大递归深度,该限制可防止无限递归引发Python解释器本身的栈溢出,从而导致崩溃。语法格式如下:
sys.setrecursionlimit(limit)
参数说明:
- limit:一个整数,表示要设置的递归深度,默认值是1000。
使用setrecursionlimit() 设置递归深度为10,然后定义一个递归函数,执行该递归函数,并在达到递归限制时,产生RuntimeError 异常,代码如下:
import sys
print(‘默认递归次数:',sys.getrecursionlimit()) # 打印默认递归深度
sys.setrecursionlimit(10) # 手动设置递归深度为10
print(‘修改后递归次数:',sys.getrecursionlimit()) # 打印修改后递归深度
# 定义一个递归函数
def Test(i):
print(‘第 {} 次数’.format(i)) # 打印执行次数
Test(i+1) # 函数递归执行
# 捕获异常信息
try:
Test(1) # 调用递归函数
except RuntimeError as err: # 捕捉异常
print(err) # 打印异常信息
85. setswitchinterval()方法——设置线程切换间隔
setswitchinterval() 方法用于设置解释器的线程切换间隔(以秒为单位)。语法格式如下:
sys.setswitchinterval(interval)
参数说明:
- interval:一个浮点值,表示分配给并发运行的Python线程的理想持续时间。但在该时间结束后,要调度的线程是由操作系统决定的,因为Python 解释器没有自己的调度程序。
说明:在Python 3.2 及以上的版本中,使用setswitchinterval() 方法替换了原来的setcheckinterval() 方法。
首先获取Python 解释器的默认线程切换间隔,然后使用setswitchinterval() 将线程切换间隔设置为0.1 秒,再次获取设置之后的Python 解释器线程切换间隔,代码如下:
import sys
print(sys.getswitchinterval()) # 打印默认线程间隔
sys.setswitchinterval(0.1) # 手动设置线程间隔为0.1秒
print(sys.getswitchinterval()) # 打印设置后的线程间隔
86. settrace()方法——设置系统的跟踪功能
settrace() 方法用于设置系统的跟踪功能,允许在Python 中实现Python 源代码调试器,该函数是特定于线程的,语法格式如下:
sys.settrace(tracefunc)
参数说明:
- ? tracefunc:表示要设置的跟踪函数名称。跟踪函数应该有3 个参数:frame、event 和arg,它们的含义如下:
Ø frame :当前的堆栈帧。
Ø event :一个字符串,可以是“call”“line”“return”“exception”或“opcode”,它们的含义如下:
Ø call:如果全局跟踪函数被调用或者一个函数被调用,或输入一些其他代码块,arg 是
Ø None,返回值为本地跟踪功能。
Ø line:解释器即将执行新的代码行或重新执行循环的条件。如果调用本地跟踪功能,arg是None,返回值指定新的本地跟踪功能。
Ø return :函数(或其他代码块)即将返回。如果调用本地跟踪功能,arg 是将返回的值;或者是None,跟踪函数的返回值将被忽略。
Ø exception:发生了异常。如果调用本地跟踪功能,arg 是一个(exception,value,traceback)元组,返回值指定新的本地跟踪功能。
Ø opcode :解释器即将执行新的操作码。如果调用本地跟踪功能,arg 是None,返回值指定新的本地跟踪功能。默认情况下不会发出操作码事件,必须通过设置f_trace_opcodes为True,来显式请求它们。
Ø arg :取决于事件类型。
注意:settrace() 方法仅用于实现调试器、分析器、覆盖工具等,它的行为是实现平台的一部分,而不是语言定义的一部分,因此不是在所有Python 实现中都可用。
使用settrace() 方法设置一个自定义的跟踪函数,跟踪程序执行过程中的访问,代码如下:
import sys
# 定义一个函数,用来作为跟踪函数,必须定义3个参数
def Test(frame,event,arg):
caller=frame.f_back # 获取当前堆栈
print(‘call’,caller) # 返回调用的堆栈信息
def testA(): # 测试输出
print('testA')
def testB(): # 测试输出
print(‘testB’)
testA() # 调用testA()
sys.settrace(Test) # 设置跟踪函数
testB() # 调用testB()
87. _enablelegacywindowsfsencoding()方法——改变 默认文件系统编码和错误模式
_enablelegacywindowsfsencoding() 方法用于将默认文件系统编码和错误模式分别更改为“mbcs”和“replace”,以便与Python 3.6 之前的版本保持一致,这相当于在启动Python 之前定义了PYTHONLEGACYWINDOWSFSENCODING 环境变量。语法格式如下:
sys._enablelegacywindowsfsencoding()
说明:
- _enablelegacywindowsfsencoding() 方法只能在Windows 操作系统中使用。
- _enablelegacywindowsfsencoding() 方法是Python 3.6 版本中新增的功能,因此只能在Python 3.6及以上版本中使用。
使用_enablelegacywindowsfsencoding() 方法改变默认的文件系统编码和错误模式,然后分别使用getfilesystemencoding() 方法和getfilesystemencodeerrors() 方法获取改变之后的文件系统编码和错误模式,代码如下:
import sys
sys._enablelegacywindowsfsencoding() # 改变默认文件系统编码和错误模式
print(‘文件系统编码:',sys.getfilesystemencoding()) # 打印文件系统编码
print(‘文件名转换错误模式:',sys.getfilesystemencodeerrors()) # 打印文件名转换时的错误模式名称