目录
前言
ByteBuf类
ByteBuffer 实现原理
ByteBuffer 写入模式
ByteBuffer 读取模式
ByteBuffer 写入模式切换为读取模式
clear() 与 compact() 方法
ByteBuffer 使用案例
总结
前言
网络数据传输的基本单位是字节,缓冲区就是存储字节的容器。在存取字节时,会先把字节放入缓冲区,再在操作缓冲区实现字节的批量存储以提升性能。
Java NIO 提供了ByteBuffer 作为它的缓冲区,但是这个类用起来过于复杂,而且也有些繁琐。因此,Netty 自己实现了 ByteBuf 以替代 ByteBuffer 。
本篇文章就来介绍Netty自己缓冲区的作用。
io.netty学习使用汇总
ByteBuf类
缓冲区可以简单理解为一段内存区域,某些情况下,如果程序频繁的操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入内存的一块区域之中,以后直接从此区域中读取数据即可。因为读取内存速度会很快,这样就可以提升程序的性能。
因此,缓冲区决定了网络数据处理的性能。
ByteBuf 被设计为一个可从底层解决 ByteBuffer 问题,并可满足日常网络应用开发需要的缓冲类型,其特点如下:
-
允许使用自定义的缓冲区类型。
-
通过内置的复合缓冲区类型实现了透明的零拷贝。
-
容量可以按需增长(类似于 JDK 的
StringBuilder)。 -
在读和写这两种模式之间切换不需要调用 ByteBuffer 的
flip()方法; -
正常情况下具有比 ByteBuffer 更快的响应速度。
ByteBuffer 实现原理
使用 ByteBuffer 读写数据一般遵循以下4个步骤。
-
写入数据到 ByteBuffer 。
-
调用
flip()方法。 -
从 ByteBuffer 中读取数据。
-
调用
clear()方法或者compact()方法。
当向 ByteBuffer 写入数据时, ByteBuffer 会记录下写了多少数据。一旦读取数据时,需要通过flip()方法将 ByteBuffer 从写入模式切换到读取模式。在读取模式下,可以读取之前写入 ByteBuffer 的所有数据。
一旦读完了所有数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()方法或者compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清空已经读取过的数据,任何未读的数据都被移到缓冲区的起初处,新写入的数据将放到缓冲区未读数据的后面。
下面是一个 Java NIO 实现 服务器端实例中使用ByteBuffe的例子:
// 可写
if (key.isWritable()) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer output = (ByteBuffer) key.attachment();
output.flip();
client.write(output);
System.out.println("NonBlokingEchoServer -> "
+ client.getRemoteAddress() + ":" + output.toString());
output.compact();
key.interestOps(SelectionKey.OP_READ);
}
对于ByteBuffer,其主要有五个属性:mark,position,limit,capacity和array。这五个属性的作用如下:
-
mark:记录了当前所标记的索引下标。
-
position:对于写入模式,表示当前可写入数据的下标,对于读取模式,表示接下来可以读取的数据的下标。
-
limit:对于写入模式,表示当前可以写入的数组大小,默认为数组的最大长度,对于读取模式,表示当前最多可以读取的数据的位置下标。
-
capacity:表示当前数组的容量大小。
-
array:保存了当前写入的数据。
上述变量存在以下关系:
0 <= mark <= position <=limit <= capacity
这几个数据中,除了 array 是用于保存数据的以外,这里最需要关注的是position,limit和capacity三个属性,因为对于写入和读取模式,这三个属性的表示的含义大不一样。
ByteBuffer 写入模式
如下图所示为初始状态和写入3个字节之后position,limit和capacity三个属性的状态:
从图中可以看出,在写入模式下:
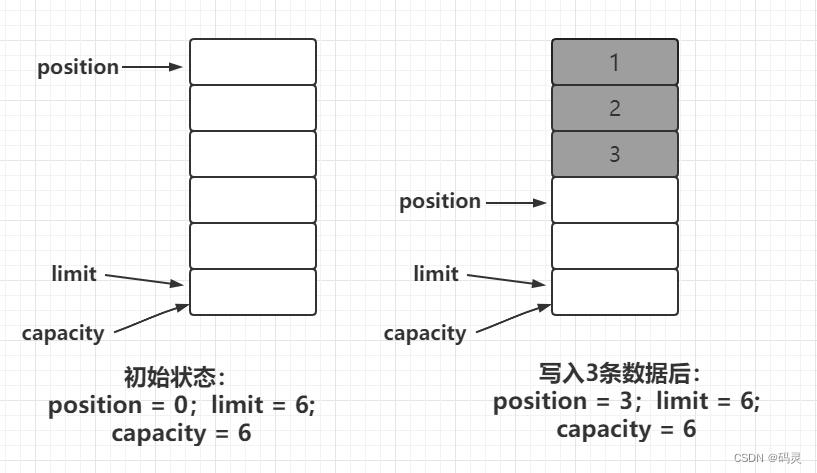
-
limit指向的始终是当前可最多写入的数组索引下标。 -
position指向的则是下一个可以写入的数据的索引位置。 -
capacity则始终不会变化,即为数组大小。
ByteBuffer 读取模式
假设我们按照上述方式在初始长度为6的 ByteBuffer 中写入了三个字节的数据,此时我们将模式切换为读取模式,那么这里的position,limit和capacity则变为如下形式:
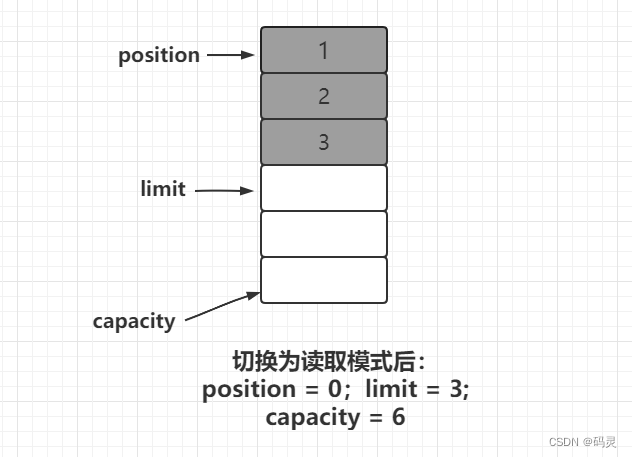
可以看到,当切换为读取模式之后:
-
limit则指向了最后一个可读取数据的下一个位置,表示最多可读取的数据。 -
position则指向了数组的初始位置,表示下一个可读取的数据的位置。 -
capacity还是表示数组的最大容量。
这里当我们一个一个读取数据的时候,position就会依次往下切换,当与limit重合时,就表示当前ByteBuffer中已没有可读取的数据了。
ByteBuffer 写入模式切换为读取模式
读写切换时要调用flip()方法。flip()方法的核心源码如下:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
从上述源码可以看出,执行flip()后,将limit设置为position,然后将该position设置为0。
clear() 与 compact() 方法
一旦读取完 ByteBuffer 中的数据,需要让 ByteBuffer 准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设置为0,limit将被设置为capacity的值。换句话说,ByteBuffer 被清空了。ByteBuffer 中的数据并未清除,只是这些标记告诉我们可以从哪里开始往 ByteBuffer 里写数据。
如果 ByteBuffer 中有一些未读的数据,调用clear()方法,数据将被遗忘,意味着不再有任何标记标注哪些数据被读过,哪些还没有。
clear()方法的核心源码如下:
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
如果 ByteBuffer 中仍有未读的数据,且后续还需要这些数据,但是此时想要先写些数据,那么使用compact()方法。
compact()方法将所有的未读的数据复制到 ByteBuffer 起始处。然后将 position 设置到最后一个未读元素的后面。limit属性依然像clear()方法一样设置成capacity。现在 ByteBuffer 准备好写数据了,但是不会覆盖未读的数据。
compact()方法核心源码如下:
public ByteBuffer compact() {
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
unsafe.copyMemory(ix(pos), ix(0), (long)rem << 0);
position(rem);
limit(capacity());
discardMark();
return this;
}
ByteBuffer 使用案例
为了更好的理解 ByteBuffer ,我们来看一些示例:
public class ByteBufferDemo {
public static void main(String[] args) {
// 创建一个缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
System.out.println("------------初始时缓冲区------------");
printBuffer(buffer);
// 添加一些数据到缓冲区中
System.out.println("------------添加数据到缓冲区------------");
String s = "love";
buffer.put(s.getBytes());
printBuffer(buffer);
// 切换成读模式
System.out.println("------------执行flip切换到读取模式------------");
buffer.flip();
printBuffer(buffer);
// 读取数据
System.out.println("------------读取数据------------");
// 创建一个limit()大小的字节数组(因为就只有limit这么多个数据可读)
byte[] bytes = new byte[buffer.limit()];
// 将读取的数据装进我们的字节数组中
buffer.get(bytes);
printBuffer(buffer);
// 执行compact
System.out.println("------------执行compact------------");
buffer.compact();
printBuffer(buffer);
// 执行clear
System.out.println("------------执行clear清空缓冲区------------");
buffer.clear();
printBuffer(buffer);
}
/**
* 打印出ByteBuffer的信息
*
* @param buffer
*/
private static void printBuffer(ByteBuffer buffer) {
System.out.println("mark:" + buffer.mark());
System.out.println("position:" + buffer.position());
System.out.println("limit:" + buffer.limit());
System.out.println("capacity:" + buffer.capacity());
}
}
输出结果:
------------初始时缓冲区------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10
------------添加数据到缓冲区------------
mark:java.nio.HeapByteBuffer[pos=4 lim=10 cap=10]
position:4
limit:10
capacity:10
------------执行flip切换到读取模式------------
mark:java.nio.HeapByteBuffer[pos=0 lim=4 cap=10]
position:0
limit:4
capacity:10
------------读取数据------------
mark:java.nio.HeapByteBuffer[pos=4 lim=4 cap=10]
position:4
limit:4
capacity:10
------------执行compact------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10
------------执行clear清空缓冲区------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10
Process finished with exit code 0
总结
本文首先展示了ByteBuffer在写入模式和读取模式下内部的一个状态,然后分析了clear() 与 compact() 方法的源码,最后讲解了ByteBuffer的使用案例。
下节我们再来分析ByteBuf实现原理。

![flink 实时数仓构建与开发[记录一些坑]](https://img-blog.csdnimg.cn/844058373c3b45e29655afac40604d3a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAY2c2,size_20,color_FFFFFF,t_70,g_se,x_16)