问题描述
使用文件和内存模拟系统缓存,并利用矩阵乘法验证实际和理论情况。
算法思想
设计一个Matrix类,其中Matrix是存在磁盘中的一个二进制文件,类通过保存的矩阵属性来读取磁盘。前八个字节为两个int32,保存矩阵的行列数。
Matrix中有一个buffer成员为读取到的数据缓存,通过pos属性来确定其在矩阵中的位置。其映射逻辑为
r
o
w
=
⌊
p
o
s
÷
c
o
l
S
i
z
e
⌋
,
c
o
l
=
p
o
s
m
o
d
c
o
l
S
i
z
e
row=\lfloor pos \div colSize\rfloor, col=pos \mod colSize
row=⌊pos÷colSize⌋,col=posmodcolSize。而缓存的管理模型则是模仿CPU的内存缓存模型,采用写回法。当读取矩阵中row行col列时,判断逻辑如下。
完成磁盘交互后,其余操作即为正常的矩阵操作
功能模块设计
矩阵类的成员变量,:
Buffer buffer;
const int rowSize;
const int colSize;
long cacheMissCount; // cache miss 次数
long cacheCount; // cache 访问次数
int pos; // pos = -1 means invalid buffer
const int offset = 2 * INT_BYTE;
fstream file;
矩阵值获取和修改的函数
int get(int row, int col)
{
int index = row * colSize + col;
assert(index < rowSize * colSize && index >= 0);
cacheCount++;
if (index >= pos && index < pos + buffer.size && pos != -1)
return buffer.get(index - pos);
else
{
cacheMissCount++;
readBuffer(index);
return buffer.get(0);
}
}
void set(int row, int col, int val)
{
assert(row <= rowSize && col <= colSize);
if (pos <= indexOf(row, col) && indexOf(row, col) < pos + buffer.size)
buffer.set(indexOf(row, col) - pos, val);
else
{
cacheMissCount++;
readBuffer(indexOf(row, col));
buffer.set(0, val);
}
buffer.dirty = true;
}
磁盘操作函数
void writeBuffer()
{
file.seekp(pos * INT_BYTE + offset, ios::beg);
for (int i = 0; i < buffer.size; i++)
{
file.write((char *)&buffer.get(i), INT_BYTE);
}
buffer.dirty = false;
}
void readBuffer(int startIndex)
{
if (buffer.dirty)
{
writeBuffer();
}
file.seekg(startIndex * INT_BYTE + offset, ios::beg);
buffer.size = 0;
for (int i = 0; i < buffer.capacity && startIndex + i < rowSize * colSize; i++)
{
int value;
file.read((char *)&value, INT_BYTE);
buffer.set(i, value);
buffer.size++;
}
pos = startIndex;
}
矩阵乘法函数
Matrix *multiple_ijk(Matrix &right)
{
Matrix *t = new Matrix(rowSize, right.colSize, buffer.capacity);
int i, j, k;
for (i = 0; i < rowSize; i++)
{
for (j = 0; j < right.colSize; j++)
{
for (k = 0; k < right.rowSize; k++)
{
t->set(i, j, t->get(i, j) + get(i, k) * right.get(k, j));
}
}
}
return t;
}
Matrix *multiple_ikj(Matrix &right)
{
Matrix *t = new Matrix(rowSize, right.colSize, buffer.capacity);
int i, j, k;
for (i = 0; i < rowSize; i++)
{
for (k = 0; k < right.rowSize; k++)
{
for (j = 0; j < right.colSize; j++)
{
t->set(i, j, t->get(i, j) + get(i, k) * right.get(k, j));
}
}
}
return t;
}
测试结果与分析
测试用例
class MatrixTest
{
public:
void test1()
{
Matrix m(10, 10, 3, "m.txt");
m.randomize();
cout << m << endl;
cout << "cache miss:" << m.getCacheMissCount() << endl;
Matrix m1(10, 10, 3);
m1.randomize();
cout << m1 << endl;
cout << "cache miss:" << m1.getCacheMissCount() << endl;
}
void test2()
{
Matrix m(10, 10, 3);
cout << m << endl;
m.set(0, 0, 9999);
cout << m << endl;
m.set(5, 0, 9999);
cout << m << endl;
m.set(3, 7, 9999);
cout << m << endl;
}
void test3()
{
Matrix m1(2, 3, 5, "m1.txt");
m1.randomize(100);
cout << m1 << endl;
Matrix m2(3, 4, 7, "m2.txt");
m2.randomize(100);
cout << m2 << endl;
Matrix *m3 = m1.multiple_ijk(m2);
cout << *m3 << endl;
Matrix *m4 = m1.multiple_ikj(m2);
cout << *m4 << endl;
assert(m3->toString() == m4->toString());
}
void test4(int n, int cacheSize)
{
cout << "cache size is " << cacheSize << endl;
Matrix m1(n, n, cacheSize, "m1.txt");
cout << "initial m1(size is " << n << ")finished" << endl;
Matrix m2(n, n, cacheSize, "m2.txt");
cout << "initial m2(size is " << n << ")finished" << endl;
Matrix *m3 = m1.multiple_ijk(m2);
cout << "m1 ijk m2 finished" << endl;
cout << "cache coutnt of m1: " << m1.getCacheCount() << ", cache miss count of m1:" << m1.getCacheMissCount() << endl;
cout << "cache coutnt of m2: " << m2.getCacheCount() << ", cache miss count of m2:" << m2.getCacheMissCount() << endl;
cout << "cache coutnt of m3: " << m3->getCacheCount() << ", cache miss count of m3:" << m3->getCacheMissCount() << endl;
cout << endl;
}
void test5(int n, int cacheSize)
{
cout << "cache size is " << cacheSize << endl;
Matrix m1(n, n, cacheSize, "m1.txt");
cout << "initial m1(size is " << n << ")finished" << endl;
Matrix m2(n, n, cacheSize, "m2.txt");
cout << "initial m2 finished" << endl;
Matrix *m3 = m1.multiple_ikj(m2);
cout << "m1 ijk m2(size is " << n << ")finished" << endl;
cout << "cache coutnt of m1: " << m1.getCacheCount() << ", cache miss count of m1:" << m1.getCacheMissCount() << endl;
cout << "cache coutnt of m2: " << m2.getCacheCount() << ", cache miss count of m2:" << m2.getCacheMissCount() << endl;
cout << "cache coutnt of m3: " << m3->getCacheCount() << ", cache miss count of m3:" << m3->getCacheMissCount() << endl;
cout << endl;
}
void runTest()
{
for (int i = 5; i < 35; i += 5)
{
for (int j = 1; j < 5; j++)
{
test4(i, i / j);
test5(i, i / j);
}
}
}
};
实验测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ei8rZnSV-1670300721028)(figures/外部矩阵乘法/image-20221205225242144.png)]](https://img-blog.csdnimg.cn/06be27c3cae54533abc521122e33da21.png)

实验分析
假设矩阵为 C = A × B C=A\times B C=A×B,且cache大小小于矩阵的一行或一列,且A、B、C都是大小为n的方阵
对于ijk的情况:
每次读取时发生一次磁盘访问,而若cache当中有脏数据,则有另一次的写入访问。对于矩阵C,因为其作为操作矩阵*(总是进行+=操作)*,所以只要是C矩阵发生了cache miss其实是进行了两次磁盘访问,而对于AB矩阵,发生cache miss 时只发生一次磁盘访问。
cache miss 发生次数如下
C
c
a
c
h
e
m
i
s
s
=
n
2
c
a
c
h
e
s
i
z
e
A
c
a
c
h
e
m
i
s
s
=
n
3
c
a
c
h
e
s
i
z
e
B
c
a
c
h
e
m
i
s
s
=
n
3
C_{cache\ miss} = \frac{n^2}{cache\ size}\\ A_{cache\ miss} = \frac{n^3}{cache\ size}\\ B_{cache\ miss} = n^3
Ccache miss=cache sizen2Acache miss=cache sizen3Bcache miss=n3
所消耗的总时间
t
t
o
t
a
l
=
2
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
C
c
a
c
h
e
m
i
s
s
+
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
A
c
a
c
h
e
m
i
s
s
+
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
B
c
a
c
h
e
m
i
s
s
=
n
3
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
c
a
c
h
e
s
i
z
e
(
1
+
1
n
+
c
a
c
h
e
s
i
z
e
)
t_{total}=2T_{disk\ access\ time}C_{cache\ miss}+T_{disk\ access\ time}A_{cache\ miss}+T_{disk\ access\ time}B_{cache\ miss}\\ =\frac{n^3T_{disk\ access\ time}}{cache\ size(1+\frac{1}{n}+cache\ size)}
ttotal=2Tdisk access timeCcache miss+Tdisk access timeAcache miss+Tdisk access timeBcache miss=cache size(1+n1+cache size)n3Tdisk access time
而当顺序化为ijk的时候,B矩阵的cache hit 率有所提高
C
c
a
c
h
e
m
i
s
s
=
n
3
c
a
c
h
e
s
i
z
e
A
c
a
c
h
e
m
i
s
s
=
n
2
c
a
c
h
e
s
i
z
e
B
c
a
c
h
e
m
i
s
s
=
n
3
c
a
c
h
e
s
i
z
e
C_{cache\ miss} = \frac{n^3}{cache\ size}\\ A_{cache\ miss} = \frac{n^2}{cache\ size}\\ B_{cache\ miss} = \frac{n^3}{cache\ size}
Ccache miss=cache sizen3Acache miss=cache sizen2Bcache miss=cache sizen3
所消耗的总时间变为了
t
t
o
t
a
l
=
2
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
C
c
a
c
h
e
m
i
s
s
+
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
A
c
a
c
h
e
m
i
s
s
+
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
B
c
a
c
h
e
m
i
s
s
=
n
3
T
d
i
s
k
a
c
c
e
s
s
t
i
m
e
c
a
c
h
e
s
i
z
e
(
2
+
1
n
)
t_{total}=2T_{disk\ access\ time}C_{cache\ miss}+T_{disk\ access\ time}A_{cache\ miss}+T_{disk\ access\ time}B_{cache\ miss}\\ =\frac{n^3T_{disk\ access\ time}}{cache\ size(2+\frac{1}{n})}
ttotal=2Tdisk access timeCcache miss+Tdisk access timeAcache miss+Tdisk access timeBcache miss=cache size(2+n1)n3Tdisk access time
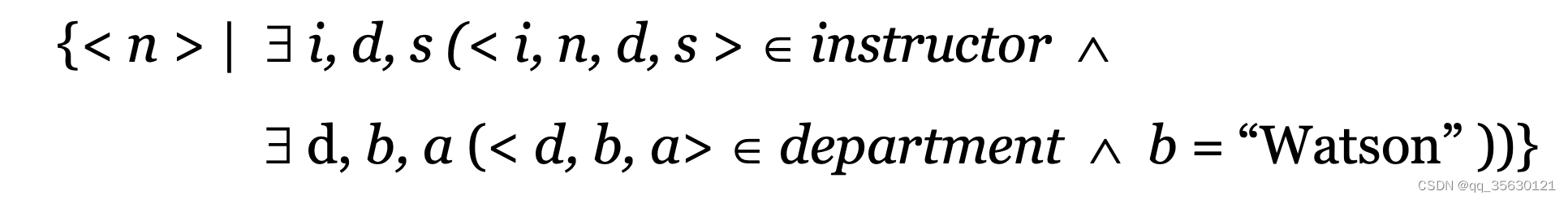


![[附源码]Python计算机毕业设计SSM家庭安防系统(程序+LW)](https://img-blog.csdnimg.cn/ea56d1cdaf6240728267497ceb3e4f1c.png)