例如一个电影推荐系统,一共有n个用户,m个电影,每部电影都有一定的特征,例如爱情片的比例、动作片的比例。n个用户对看过的电影进行评分,推荐系统如何给用户推荐新电影,预测用户对新电影的评分?
预测一个给电影打分的系统。
先介绍一些符号:
:表示用户数量
:表示电影数量
:代表用户j给电影i进行了评价
:表示用户j对电影i所给出的评分
则推荐系统的问题是:给出了和
数据,然后去查找那些没有被评级的电影并试图预测这些电影的评价星级。
13.1 内容推荐算法
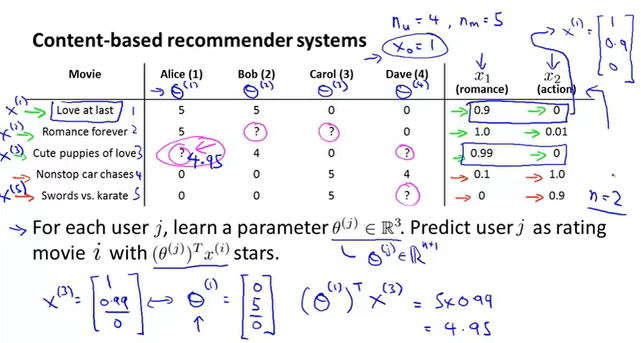
可以使用线性回归的方法进行训练,得到用户对于特征的参数,之后就可以根据
对电影进行打分。
:是每个用户
的一个参数
:评价了电影j的用户数量
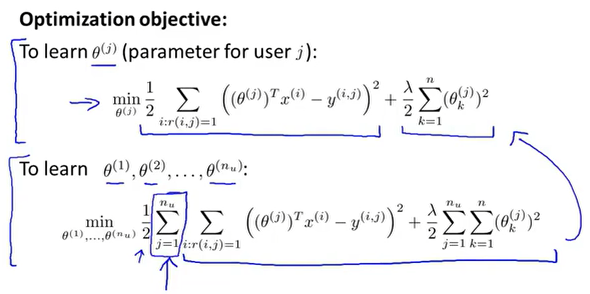
优化目标函数是:

内容推荐算法:因为假设变量是已有的,即不同电影的各个特征,我们有描述电影内容的特征量,这个电影的爱情程度怎样、动作成分有多少,同时我们用了这些描述电影内容特征量来做出预测。但对于许多电影来说,我们并没有这样的特征量或者很难获取所有电影的此类特征或者其他我们销售的东西。
13.2 协同过滤
协同过滤算法能自行学习所要使用的特征。
我们无法得到每部电影中不同特征的比例,例如电影中爱情和动作的比例?除非人工审核每一部电影,但是太耗时。这里有一个思路,首先用户根据自己的喜好对特征打分,通过计算可以大致确定已经打过分的电影它的特征值,根据已经确定的特征值,又可以计算出每个用户对这部电影的评分。
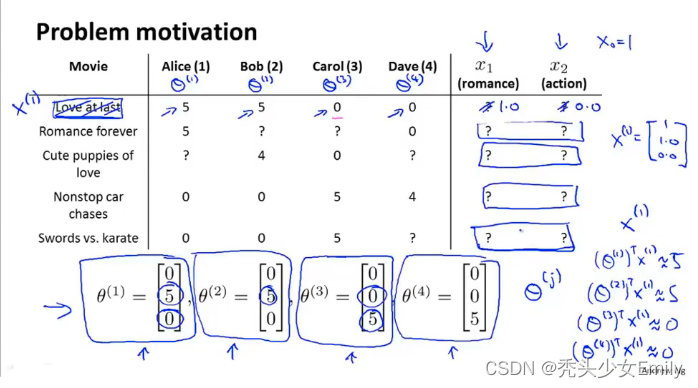
假设我们的用户告诉了我们的偏好,也就是说用户们给了我们的值,而我们想要学习的电影i的特征向量
,能做的就是提出以下优化问题:
先有鸡还是先有蛋…

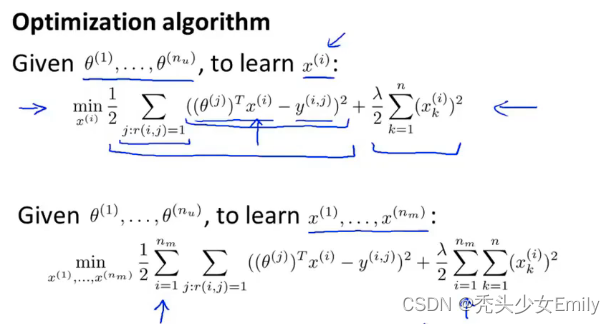
根据特征向量可以以通过线性回归得到用户的
向量,通过用户提供的
向量可以估计每部电影的特征数值。这就有点像鸡和蛋的问题。我们可以随机选取
向量计算得到特征数值,然后再通过线性回归去更新
,这样不停的迭代直到最后的收敛。
如果你有了电影的特征,就可以解出这个最小化问题找到用户参数;如果你拥有参数
,也可以用该参数估计特征
。我们也可以将两种函数合并为一个目标函数:
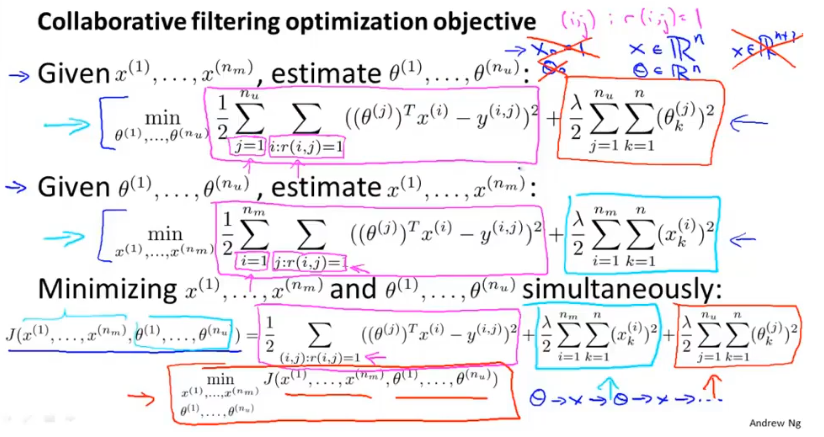
- 首先我们会把
和
初始为小的随机值,这里有点像神经网络训练
- 要用梯度下降或者其他高级的优化算法把这个代价函数最小化,如果求导的话,会发现梯度下降法写出的更新式如下图第二点所示
- 最后给你一个用户,如果这个用户有一些参数

13.3 矢量化-低秩矩阵分解
可以把n个用户对m部电影的评分结果表示为的矩阵
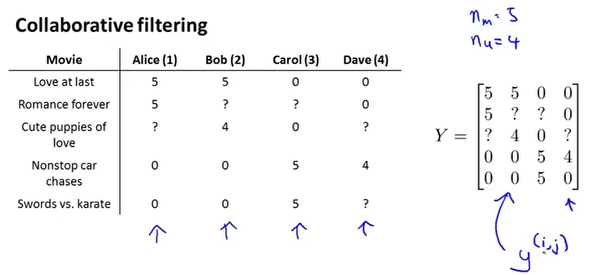
这个矩阵可以表示为
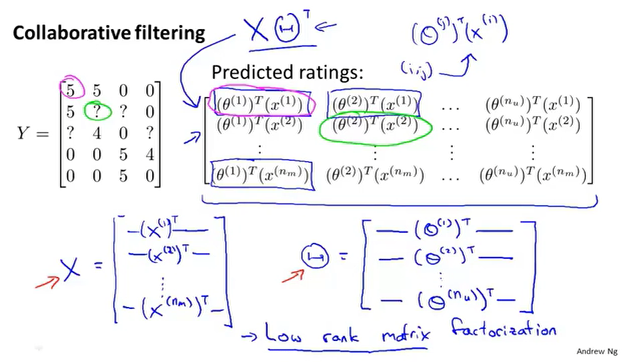
“低秩矩阵”表示,行、列都具有相关性。通俗来讲,就是可以用一部分的行、列来表示另一部分行、列。
通过特征值之间的偏差,我们可以找到类型相近的电影。

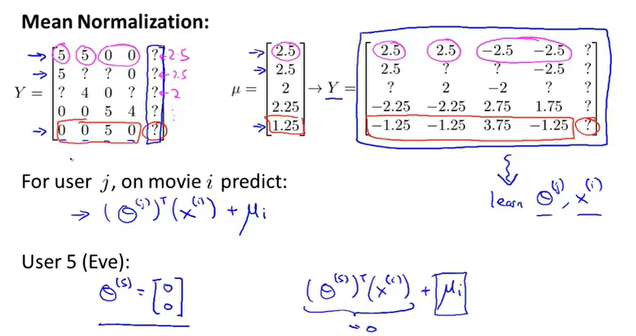
13.4 均值规范化
之前无论是参数特征
,都基于每个用户都对多个电影进行的评分,每部电影也被多个用户评分。对于新用户,他可能还没有对任何一部电影进行评分,一种思路就是把所有用户对每部电影的评分的均值作为新用户的初始评分。