目录
1、IK分词器下载
2、下载完毕后解压,放入到elasticsearch的plugins下即可
3、重启elasticsearch,可以看到ik分词器被加载了
4、也可以通过elasticsearch-plugin这个命令来查看加载进来的插件
5、使用kibana测试ik分词器
6、扩展配置ik分词器词典
6.1、进入到ik分词器的配置文件夹config下
6.2、在当前目录下新建一个词典,my.dic(以.dic结尾,命名自己定义)
6.3、打开IKAnalyzer.cfg.xml文件(ik分词器的配置文件)
6.4、重启elasticsearch即可把自定义的词典加载进来
6.5、重新使用kibana进行测试
IK分词器是elasticsearch的一个插件
分词的主要用于把一段中文或者英文的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看成一个词,比如"我爱技术"会被分为"我","爱","技","术",这显然不符合要求,所以我们需要安装中文分词器IK来解决这个问题
IK提供了两个分词算法:ik_smart和ik_max_word
ik_smart为最少切分,添加了歧义识别功能,推荐
ik_max_word为最细粒度切分,能切的都会被切掉
1、IK分词器下载
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
注意要下载release版本,具体版本最好与elasticsearch的版本对应
如果下载了源码则需要自己手动打包
2、下载完毕后解压,放入到elasticsearch的plugins下即可
在elasticsearch的plugins下,可以新建一个文件夹管理ik分词器解压后的文件
3、重启elasticsearch,可以看到ik分词器被加载了

4、也可以通过elasticsearch-plugin这个命令来查看加载进来的插件
在elasticsearch-7.6.1\bin下cmd打开一个新的命令行窗口
输入elasticsearch-plugin list

5、使用kibana测试ik分词器
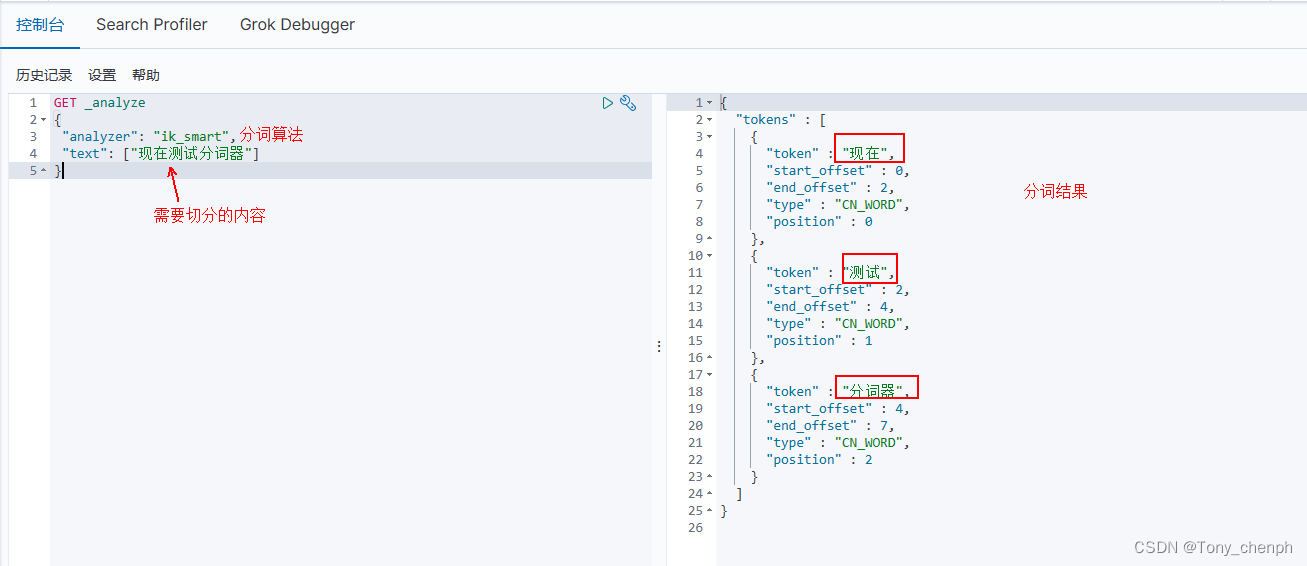
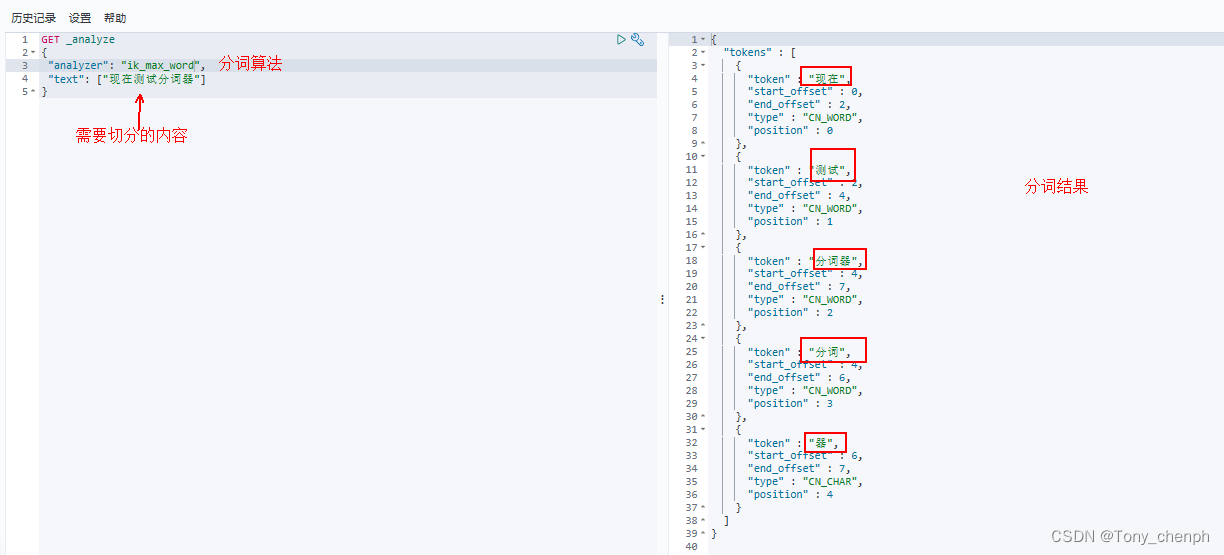
可以看到选择不同的ik分词器的分词算法,相同的切分内容会有不同的分词结果,具体根据自己的需求选择。如果不指定“analyzer”的分词算法,则会使用默认的分词器,默认的分词算法会把切分的内容中的每个字当成一个词进行切分,如上述“现在测试分词器”会被切分出“现”、“在”、“测”、“试”、“分”、“词”、“器”七个词
6、扩展配置ik分词器词典
分词器分词规则是根据字典来进行拆分的,同样,我们可以添加自定义字典
有些词在逻辑上不是一个整体,但是自己又想当成一个词来用,这就需要把这个词加到分词器的字典中,例如上面的内容“现在测试分词器”,我想把“现在测试”当成一个词来用
6.1、进入到ik分词器的配置文件夹config下

6.2、在当前目录下新建一个词典,my.dic(以.dic结尾,命名自己定义)
在里面输入我们的需要定义成一个词的内容,如我想把“现在测试”当成一个词,那就输入“现在测试”然后保存
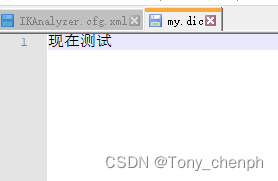
需要配置多个不同的词以换行区分,参照ik分词器自带的dic词典的内容格式即可(随便打开一个.dic词典参照)
6.3、打开IKAnalyzer.cfg.xml文件(ik分词器的配置文件)
添加扩展配置自己的词典,保存
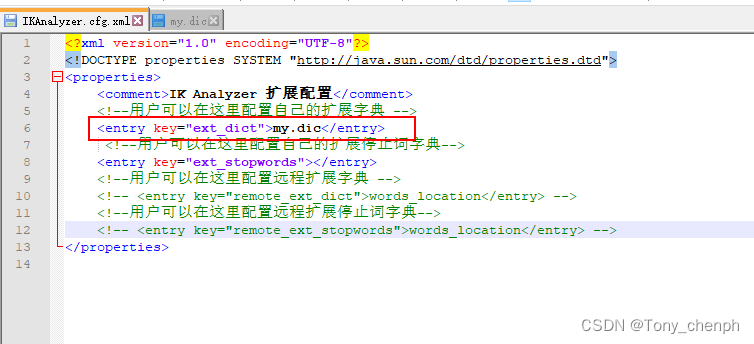
6.4、重启elasticsearch即可把自定义的词典加载进来
启动时可以看到my.dic被elasticsearch被加载的日志

6.5、重新使用kibana进行测试
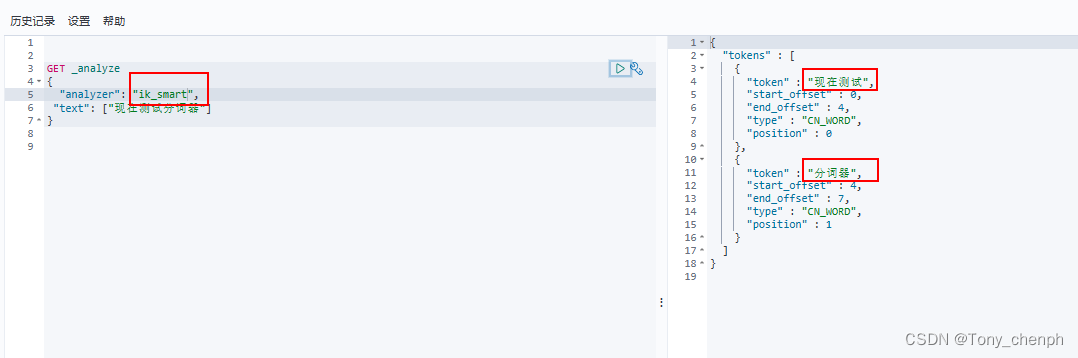
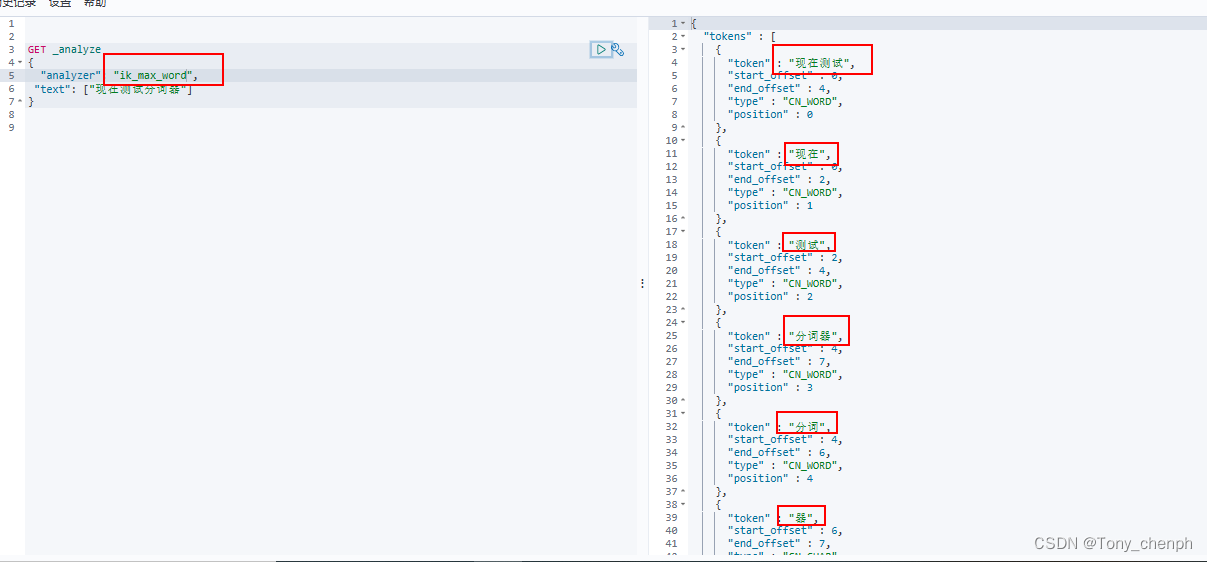
可以看到我们配置的分词字典生效了,“现在测试”被当成一个词解析了出来
综上,以后需要自己配置分词规则,只需要在自己定义的分词词典(my.dic)中添加需要的词即可(换行区分),ik分词器则会根据词典和分词算法对内容进行切分