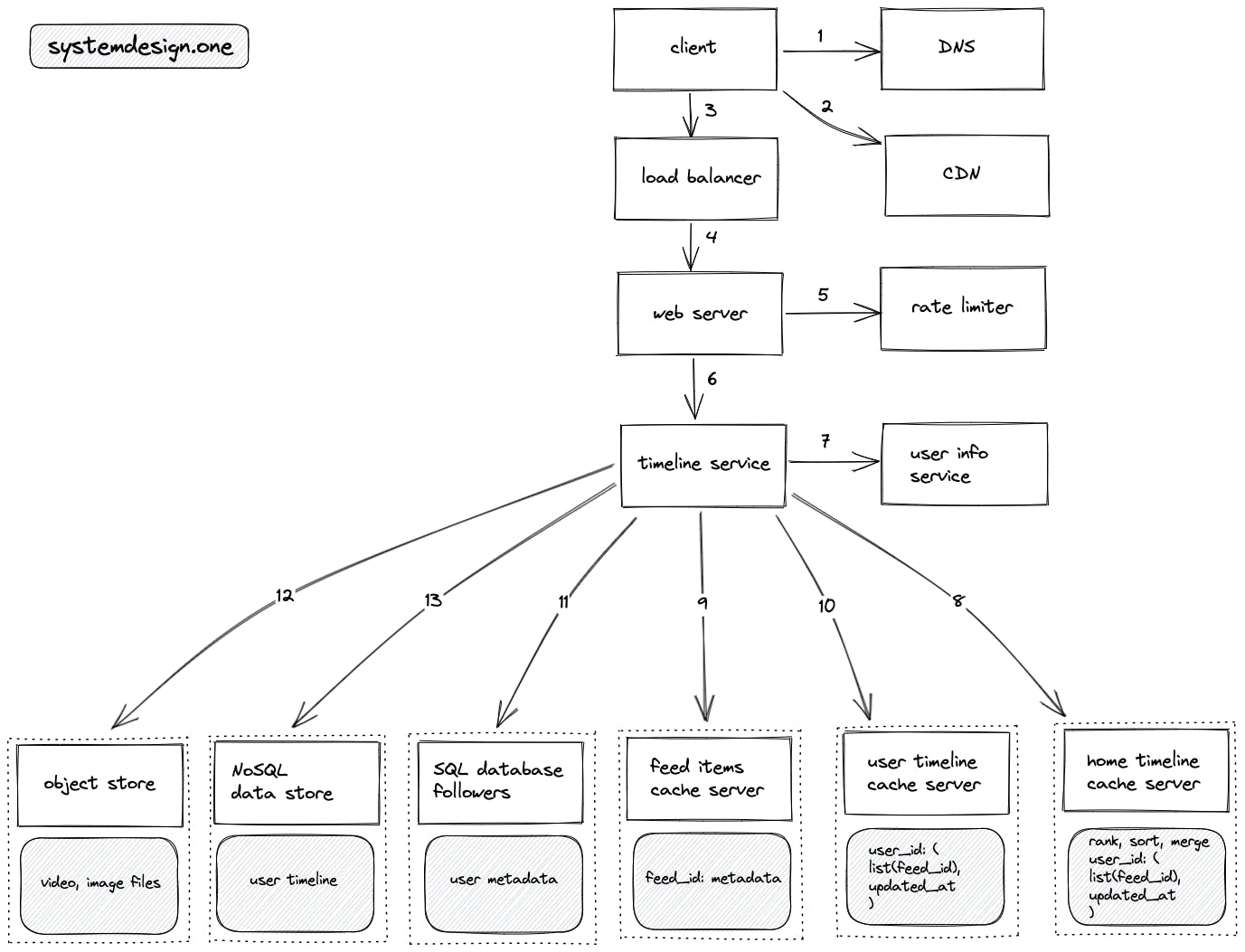
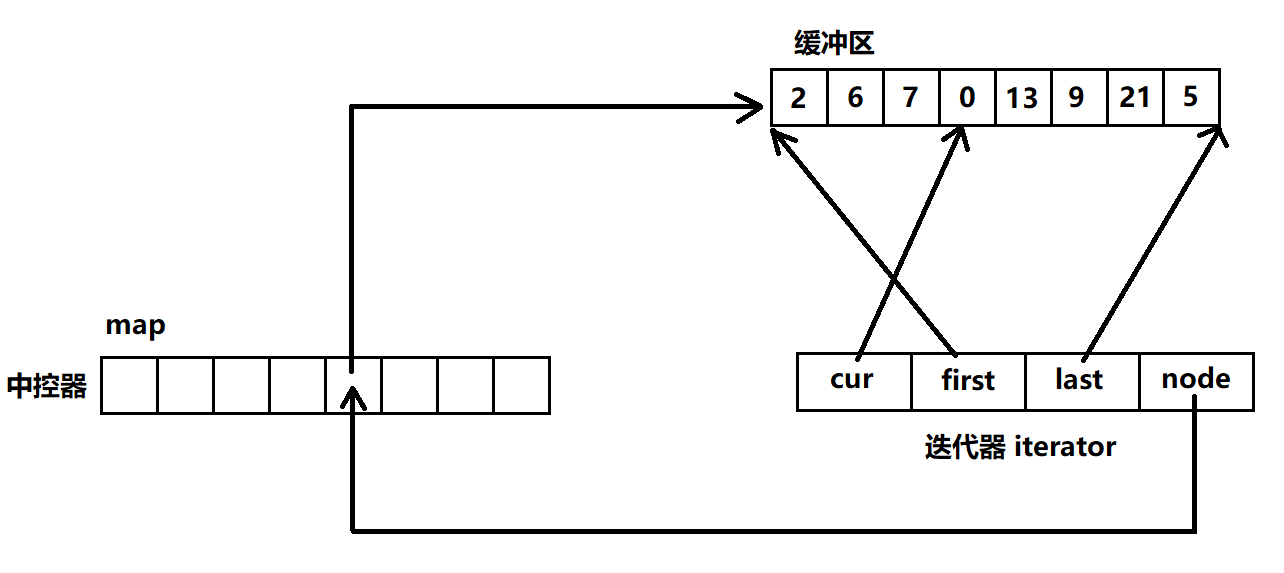
作者 | Python
ChatGPT强大的性能让人爱不释手,ChatGPT迟迟不开源让人恨得牙根痒痒。那仅通过开源数据,能够取得怎样的效果呢?近期,AI2的一篇论文显示,最好的65B规模的模型能够达到ChatGPT表现的83%,能够达到GPT-4表现的68%。让我们一起来看看他们是怎么做的。
论文题目:
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
论文链接:
https://arxiv.org/pdf/2306.04751.pdf
项目链接:
https://github.com/allenai/open-instruct
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
开源资源使用
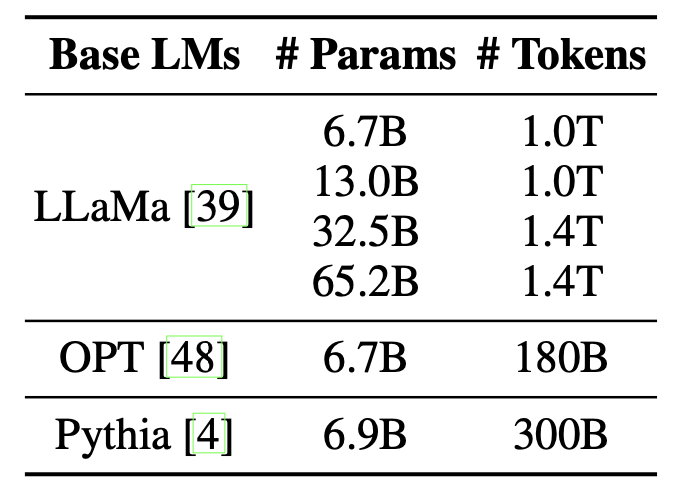
ChatGPT等大规模语言模型(简称大模型)的训练主要分成两个阶段:语言模型训练与指令精调。对语言模型训练,该文主要探索了不同规模3种预训练模型:LLaMa、OPT和Pythia。下图展示了不同模型的参数规模及预训练时的数据规模。
而在第二步的指令精调中,该文探索了如下12个开源的指令精调数据集。这些数据集的构建思路主要包括5个方向:
- 通过现有的NLP数据集构建
- 人类从头写
- 通过GPT4等特定模型生成
- 人类写的prompt+模型生成补全
- 通过思维链(CoT)、代码补全等特定形式构建

图中, N r o u n d s N_{rounds} Nrounds为对话的平均轮数,后两列为用户prompt与生成内容的平均长度。
作者还构建了2个混合数据源的训练集,包括:
- Human data mixture:含有人类标注的数据集(FLAN V2, CoT, Dolly, 和 Open Assistant 1)
- Human+GPT data mix:进一步增加模型生成的数据集(GPT4-Alpaca, Code-Alpaca, and ShareGPT)
评价方式
如何评估大模型的好坏也是个复杂的问题。该文采用了包括自动评价和人工评价的方式,包括:
- 事实知识:Massive Multitask Language Understanding dataset (MMLU)。以单选题的形式,涵盖了57个学科,从入门级到专业级难度的都有。
- 推理:Grade School Math dataset (GSM) 和 Big-Bench-Hard (BBH)。GSM是小学难度的数学题;而BBH包含了23种较难的推理任务,比如日期理解、影评、逻辑归纳、目标计数等。
- 多语言能力:基于TyDiQA,段落级抽取式阅读理解数据集,包含11种不同形式的语言。
- 编程:基于HumanEval数据集,基于文档的函数级变成能力(为避免混淆,这里改称为Codex-Eval)。
- 基于模型的评价方式:参考AlpacaFarm的设置,选取805个开放式指令。让Davinci-003生成长度不超过2048的回复作为基准,并让GPT-4来做排序比较。
- 人工评价:考虑了332个指令(源于Self-Instruct 和Vicuna)。指标包括:
- 二分类地去判断每个回复是否可以接受
- 5分类地两两比较模型输出结果
实验结果
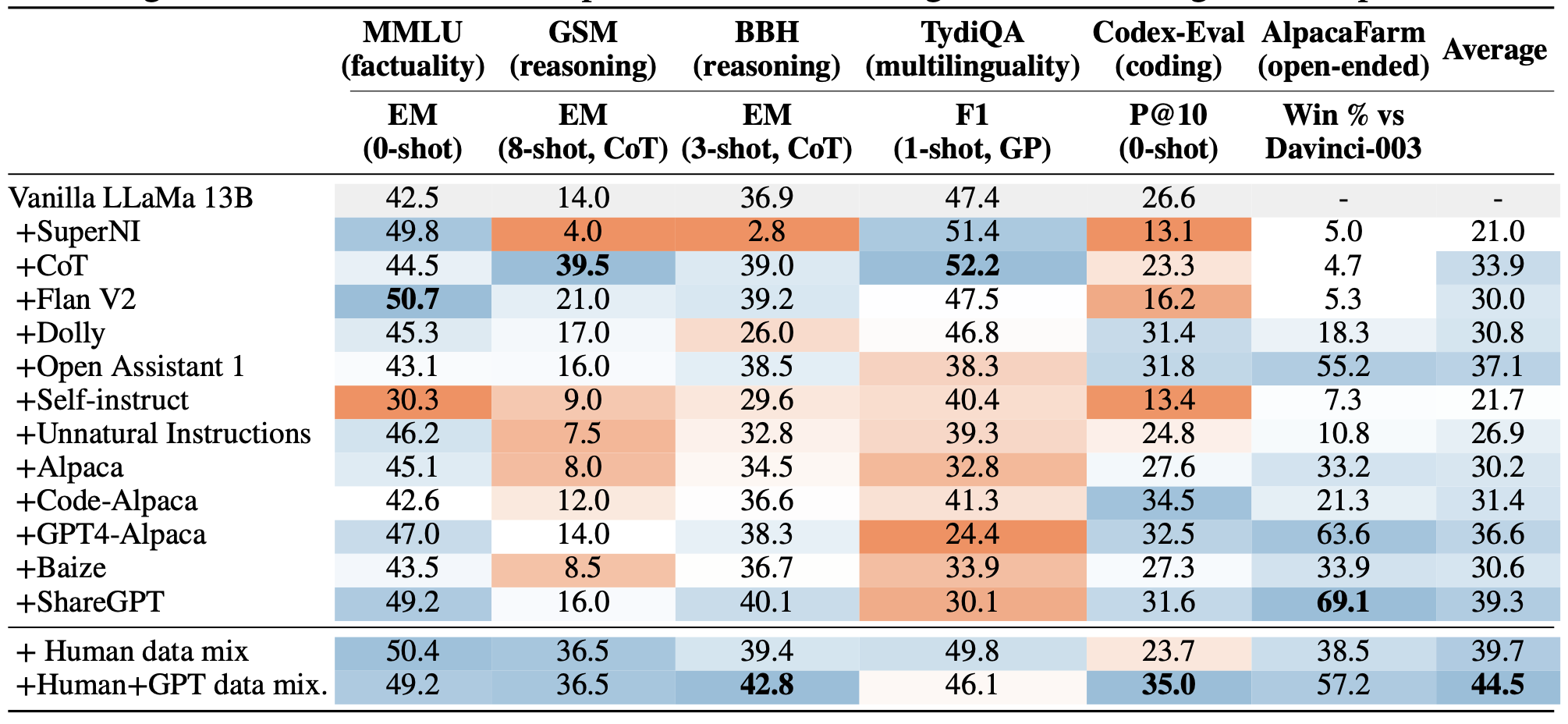
结论1:不同的Instruction Tuning数据集,会给模型带来不同方面的优势。
结论2:混合多种Instruction Tuning数据集效果会更好。
这两条结论很容易从下图中看出。比如MMLU上,用Flan V2最好,GSM上,用CoT最好,在Codex-Eval上用Code-Alpaca最好。Instruction Turing数据和下游任务一致性越高,表现就越好。而看均值的话,混合最多数据集的Human+GPT data mix最好。
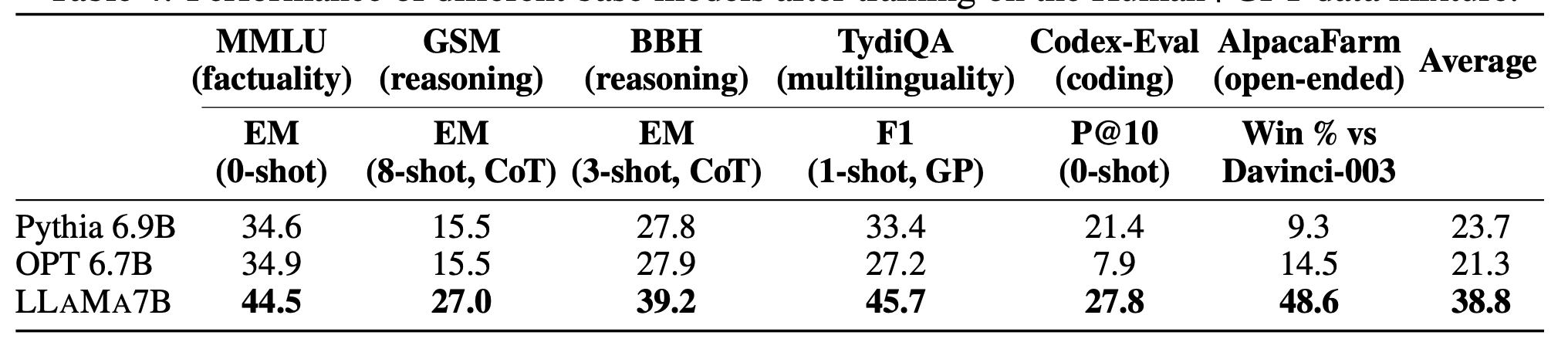
接下来,使用Human+GPT data mix,检验参数量相当的的Pythia(300B)、OPT(180B)和LLAMA(1.0T)模型的表现,如下图所示,发现表现与预训练时使用的数据规模一致。
结论3:参数规模相同时,backbone模型预训练数据量越大表现越好。
后文将在Human+GPT data mix上调整过的LLAMA模型称作TÜLU。下图印证了几个比较常规的结论:参数越多表现越好;Instruction Tuning对所有参数规模的模型都有效;参数规模越小提升越大。以及:
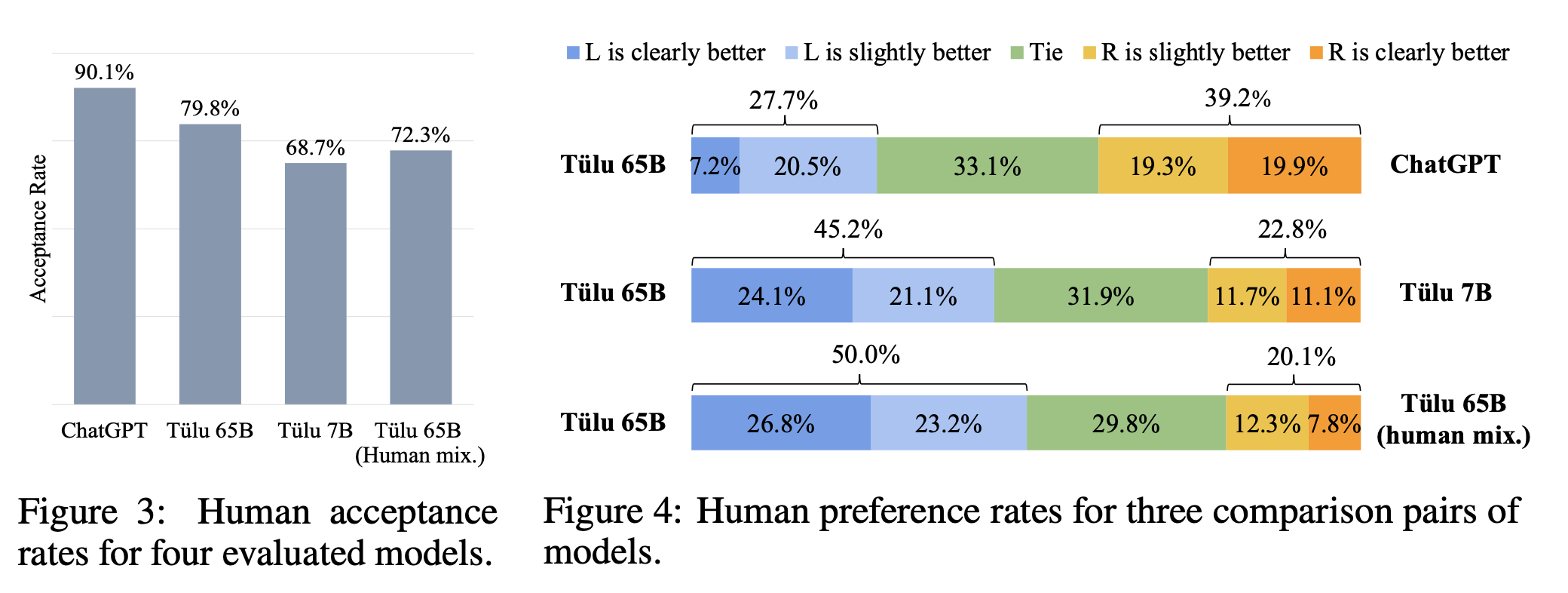
结论4:TÜLU 65B同ChatGPT相比还有差距,表现达到ChatGPT的83%,GPT-4的68%。

具体的人类评价结果如下图所示,可以看到 TÜLU 65B 和 ChatGPT 相比仍有较大差距。(下图左是是否接受的0-1评分,下图右为两两比较评分)
总结
OpenAI的ChatGPT等模型不开源,给学术界相关研究提出了很大的挑战。本文系统地探索了开源数据集上Instructiong Tuning的结果,并同ChatGPT于GPT-4的结果系统比较,对相关研究具有较好的参考价值。
此外,对比本文于OpenAI的论文也可以看出,OpenAI真的是什么训练细节都不讲。且不说GPT-4的技术报告中没有涉及任何技术细节,就连最近被大家夸赞开源了数据集的文章verify step by step中透露的技术细节也远少于本文。