一、分布式系统遇到的问题
1 服务雪崩效应
在分布式系统中,由于网络原因或自身的原因,服务一般无法保证 100%是可用的。如果一个服务出现了问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致调用服务瘫痪。
由于服务与服务之间的依赖性,故障会进行传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的 雪崩效应。
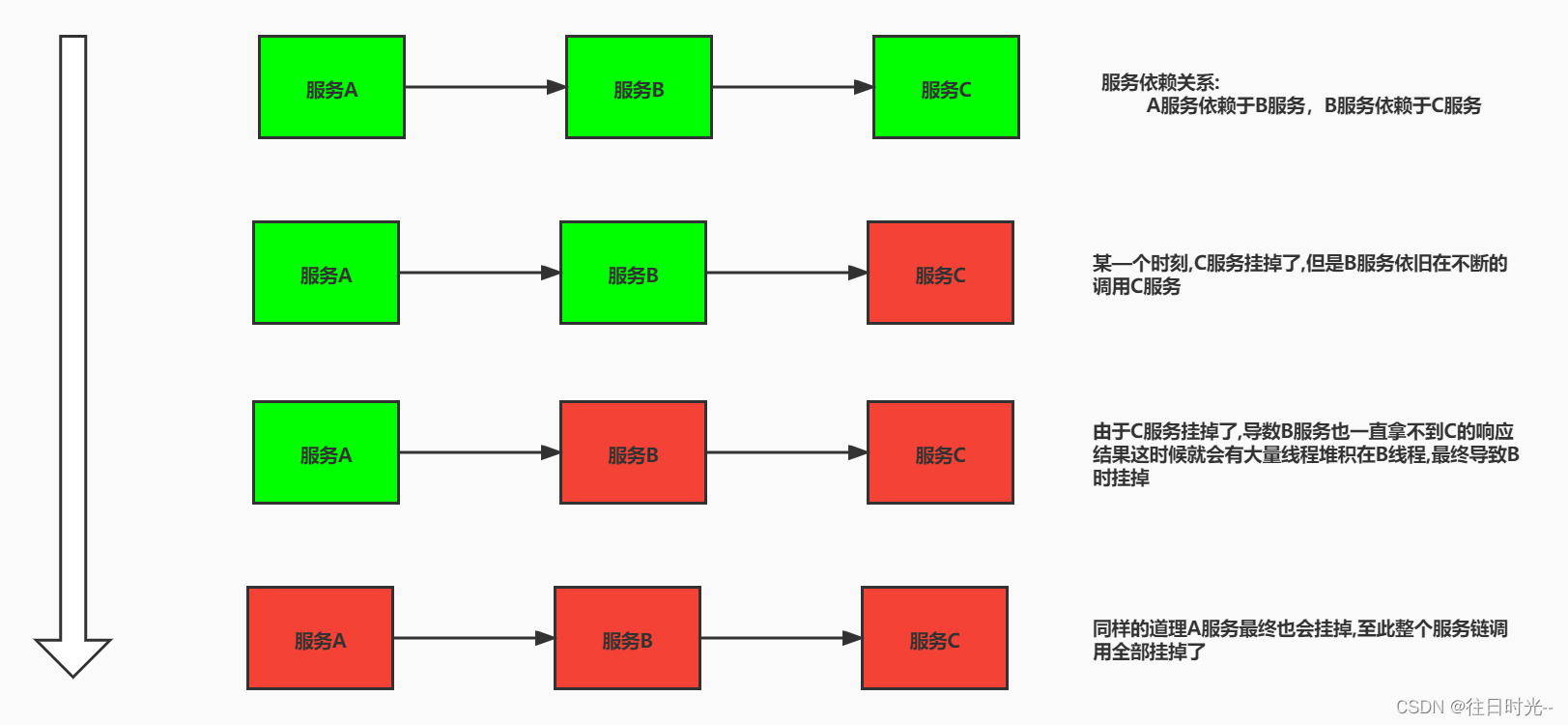
雪崩发生的原因有可能,最常用的原因:程序Bug,大流量请求,硬件故障,缓存击穿。等等
- 程序Bug: 比如说代码导致的死循环,这里的问题比较多,反正只要把服务拖死的都是 BUG。
- 大流量请求:在秒杀和大促开始前,如果准备不充分,瞬间大量请求会造成服务提供者的不可用。
- 硬件故障:可能为硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问。
- 缓存击穿:一般发生在缓存应用重启, 缓存失效时高并发,所有缓存被清空时,以及短时间内大量缓存失效时。大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用。
我们无法完全杜绝雪崩源头的发生,只有做好足够的容错,保证在一个服务发生问 题,不会影响到其它服务的正常运行。也就是"雪落而不雪崩"。
二、常见容错方案
要防止雪崩的扩