基本概念
孤立森林(Isolation Forest)是一种基于异常检测的机器学习算法,用于识别数据集中的异常点。孤立森林算法在异常检测、网络入侵检测、金融欺诈检测等领域有广泛应用,并且在处理大规模数据和高维数据时表现出色。孤立森林的基本思想的前提是,将异常点定义为那些 容易被孤立的离群点:
可以理解为分布稀疏,且距离高密度群体较远的点。从统计学来看,在数据空间里,若一个区域内只有分布稀疏的点,表示数据点落在此区域的概率很低,因此可以认为这些区域的点是异常的。
也就是说,孤立森林算法的理论基础有两点:
- 异常数据占总样本量的比例很小;
- 异常点的特征值与正常点的差异很大。
算法特点:
- 在训练过程中,每棵孤立树都是随机选取部分样本;
- 对于大规模数据集,孤立森林算法具有较高的计算效率。不同于 KMeans、DBSCAN等算法,孤立森林不需要计算有关距离、 密度的指标,可大幅度提升速度,减小系统开销;
- 因为基于 ensemble,所以有线性时间复杂度。通常树的数量越多,算法越稳定;
- 由于每棵树都是独立生成的,因此可部署在大规模分布式系统上来加速运算。
- 不受数据维度的影响,适用于高维数据。
- 不需要对数据进行归一化或标准化预处理。
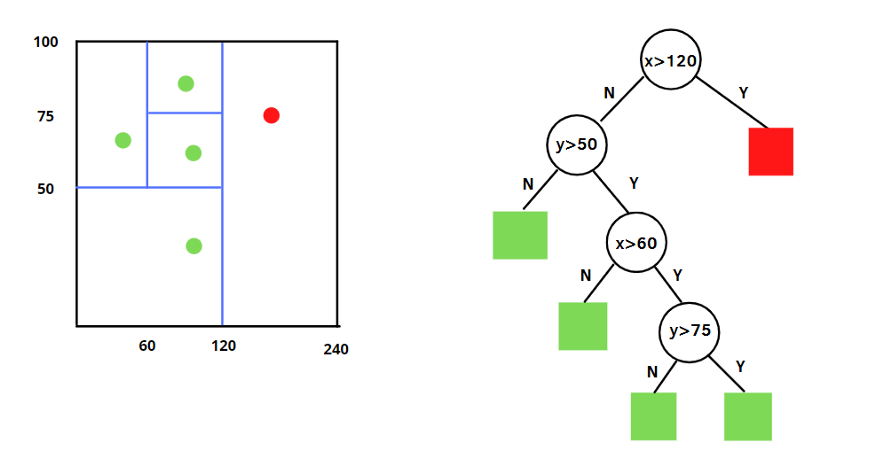
算法的工作过程如下:
- 选择一个样本集中的特征,并随机选择一个特征值范围。
- 根据选择的特征和范围,将样本集中的数据点分割成左右两个子集。
- 重复步骤1和2,将每个子集继续分割,直到达到预定的停止条件,例如树的高度达到最大限制或子集中只剩下一个数据点。
- 构建一棵二叉树,其中每个数据点都是树节点。树的深度即为数据点的路径长度。
- 重复步骤1至4,构建多棵独立的随机树。
- 对于新的数据点,通过计算其在每棵树中的路径长度来判断其是否为异常点。如果路径长度较短,则该数据点被认为是异常点。
实例代码
import plotly.express as px
from sklearn.datasets import load_iris
from sklearn.ensemble import IsolationForest
data = load_iris(as_frame=True)
X,y = data.data,data.target
df = data.frame
# 模型训练
iforest = IsolationForest(n_estimators=100, max_samples='auto',
contamination=0.05, max_features=4,
bootstrap=False, n_jobs=-1, random_state=1)
# fit_predict 函数 训练和预测一起 可以得到模型是否异常的判断,-1为异常,1为正常
df['label'] = iforest.fit_predict(X) # 传入的X可以是一维或多维的dataframe
# 预测 decision_function 可以得出 异常评分
df['scores'] = iforest.decision_function(X)
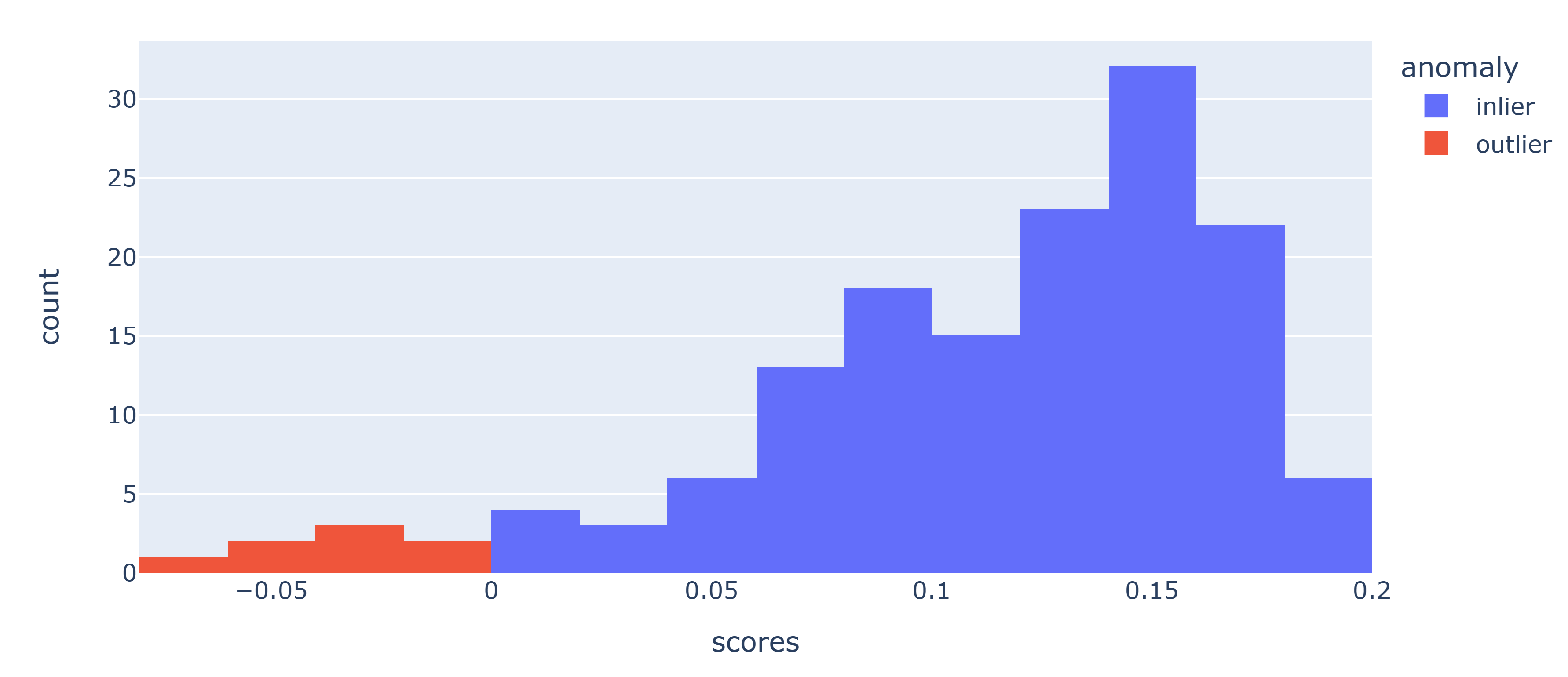
结果可视化
## 重命名
df['anomaly'] = df['label'].apply(lambda x: 'outlier' if x==-1 else 'inlier')
## 绘制不同“scores”的概率密度分布
fig = px.histogram(df,x='scores',color='anomaly')
fig.show()
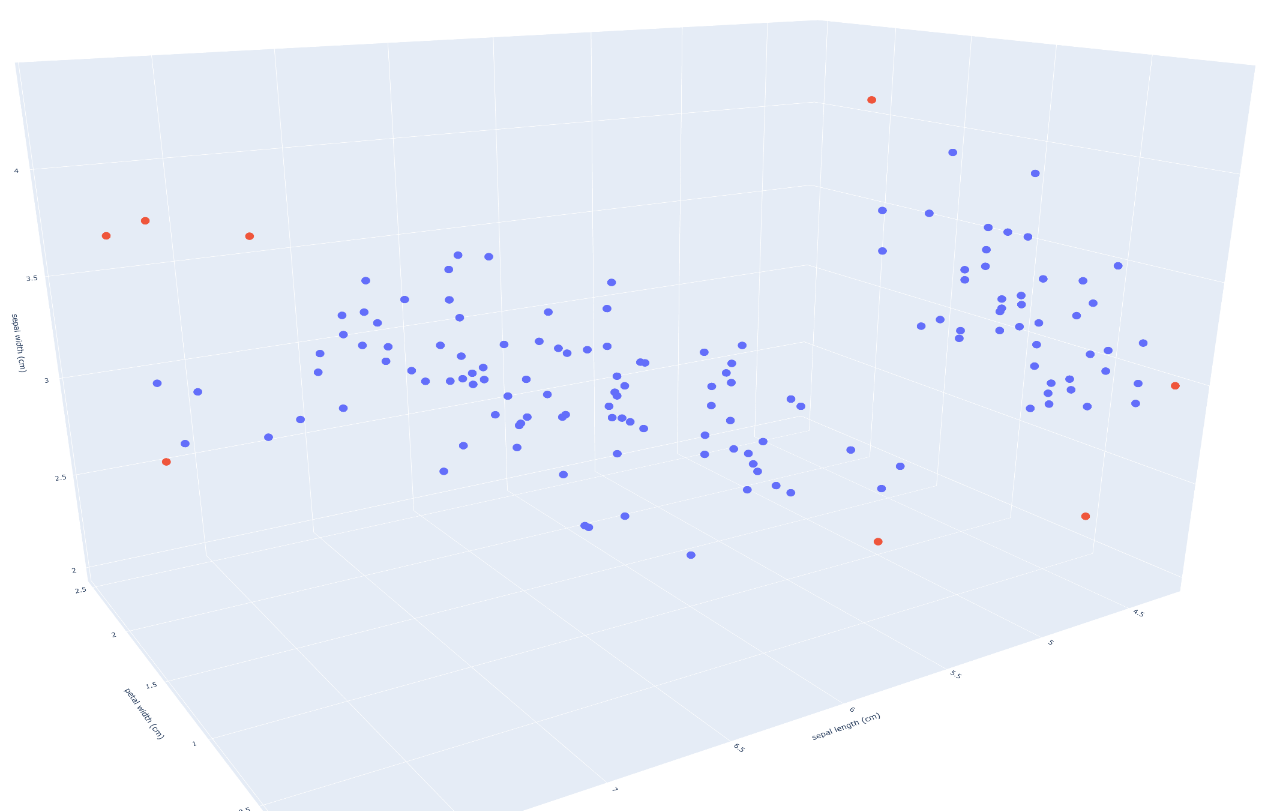
## 绘制3D散点图
fig = px.scatter_3d(df, x='petal width (cm)',
y='sepal length (cm)',
z='sepal width (cm)',
color='anomaly')
fig.show()




![[经验]PMP快速通过指南](https://img-blog.csdnimg.cn/fb76ef0d48ff4f98bb2ad61b1dc1fe92.png)