Attentive Moment Retrieval in Videos论文笔记
- 0.论文地址
- 1.摘要
- 2.引言
- 3.模型结构
- 3.1Memory Attention Network
- 3.2Cross-Modal Fusion Network
- 4.训练
- 4.1对齐损失
- 4.2定位回归损失
- 4.3合并
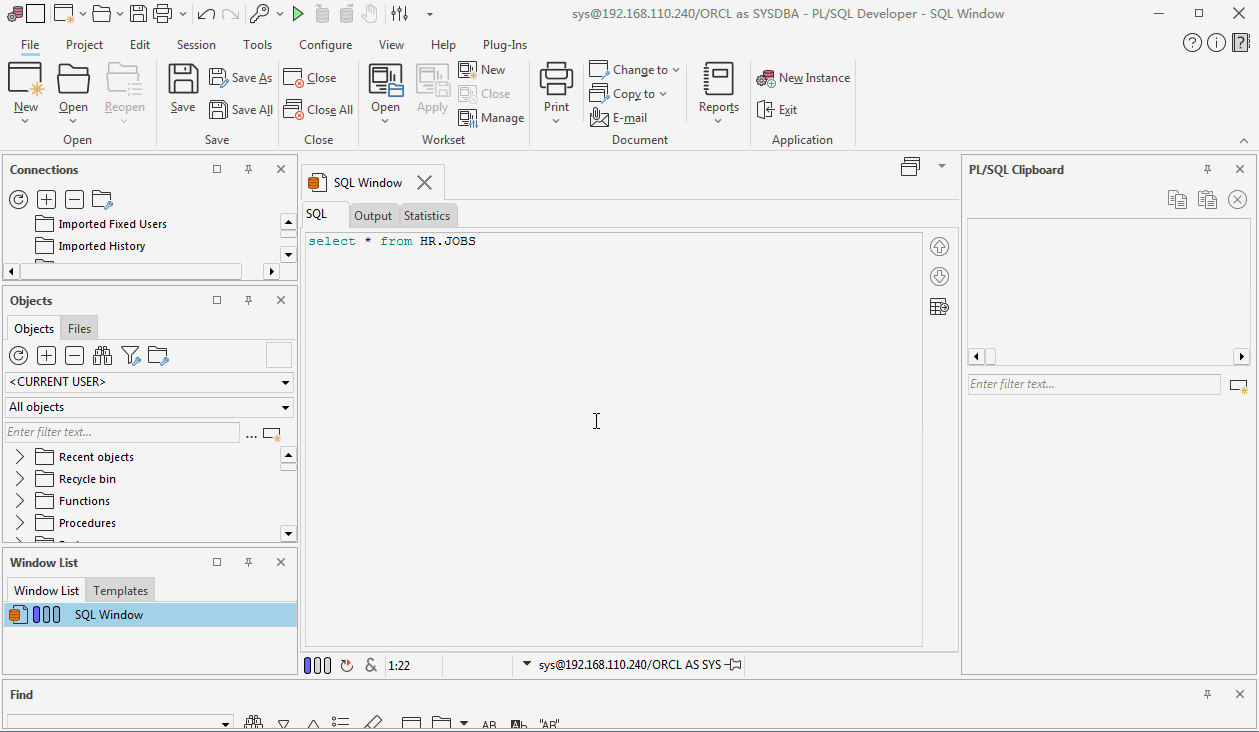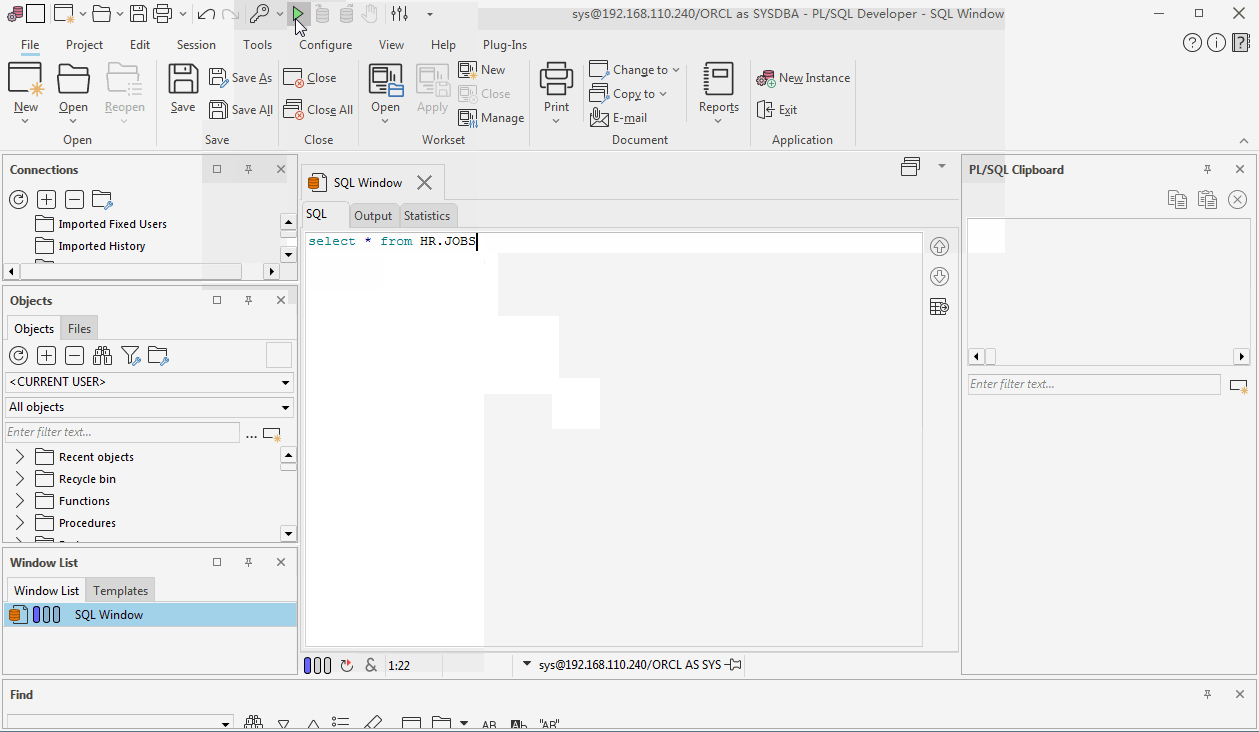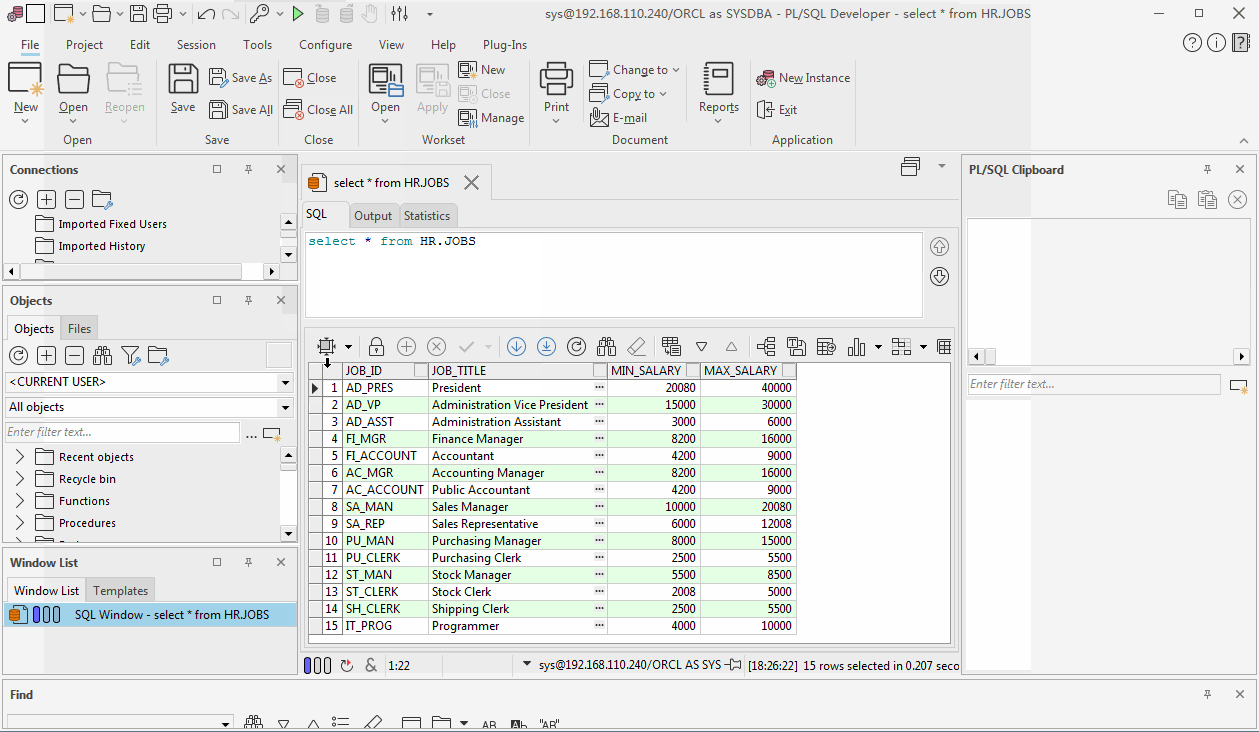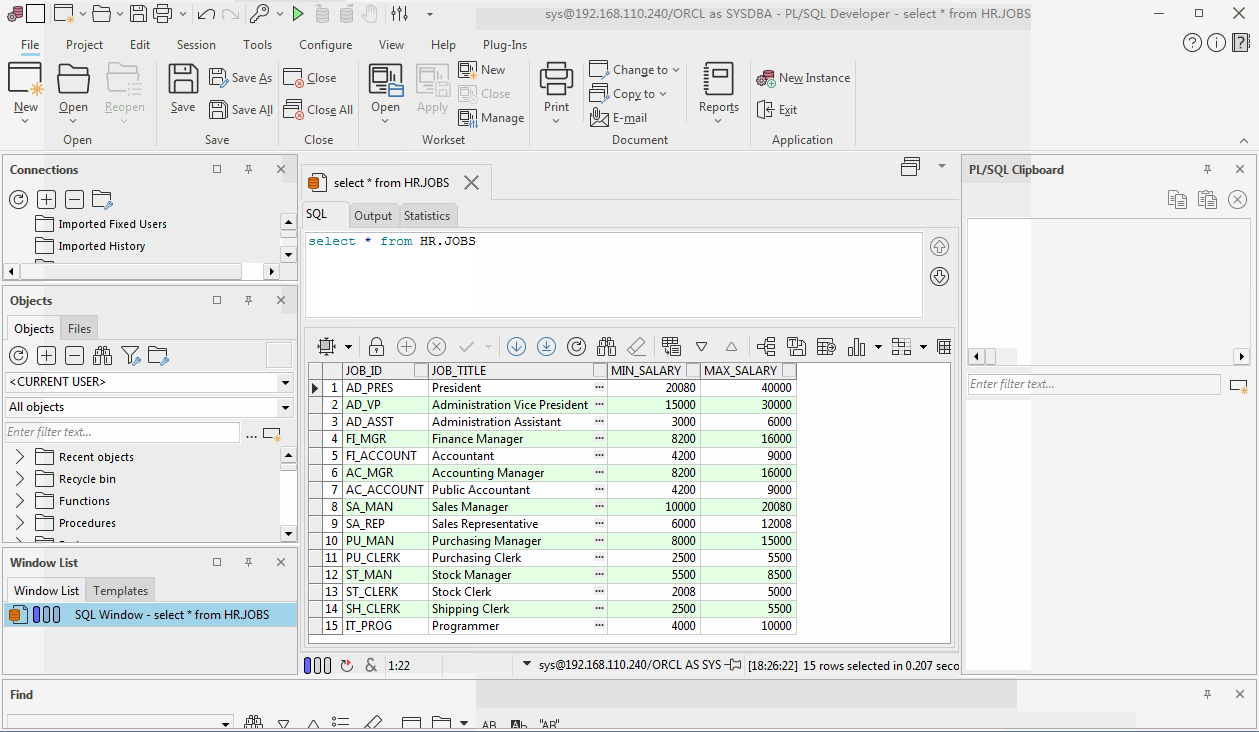
- 5.实验
- 5.1数据集
- 5.2效果
- 5.3ACRN的研究
- 6未来工作
0.论文地址
2018 Attentive Moment Retrieval in Videos
1.摘要
设计了一种记忆注意机制来强调查询中提到的视觉特征,并同时合并它们的上下文,在DiDeMo and TACoS两个数据集表现的比较好。
2.引言
候选时刻的选择和相关性估计是任务的关键所在,目前常见的方法是在不同尺度上对滑动窗口进行密集采样。但是这种方法存在计算成本高和搜索空间大的问题。另外,相关性估计是一个典型的跨模态检索问题。一种可行的解决方案是,首先将时刻候选的视觉特征和查询的文本特征投影到一个共同的潜在空间中,然后根据它们的相似性计算相关性。然而,这种方法忽略了时刻和查询内部的时空信息。例如,对于查询“一个穿橙色衣服的女孩先经过摄像头”,“先”这个词是相对的,需要有时序上下文来进行正确理解。
作者提出了ACRN模型并指出文章的贡献有3个:
- 我们提出了一种新颖的注意力交叉模态检索模型,它同时表征注意力上下文视觉特征和跨模态特征表示。据我们所知,现有的研究要么只考虑其中一种模型,要么没有将它们集成到一个统一的模型中。
- 为了在自然语言视频检索任务中精确定位时刻,我们首次引入了一种临时记忆注意力网络,为每个时刻记住其上下文信息,将自然语言查询作为注意力网络的输入,自适应地为记忆表示分配权重。
- 两个基准数据集上进行了广泛的实验,证明了性能的改进。作为副产品,我们发布了数据和代码。
3.模型结构
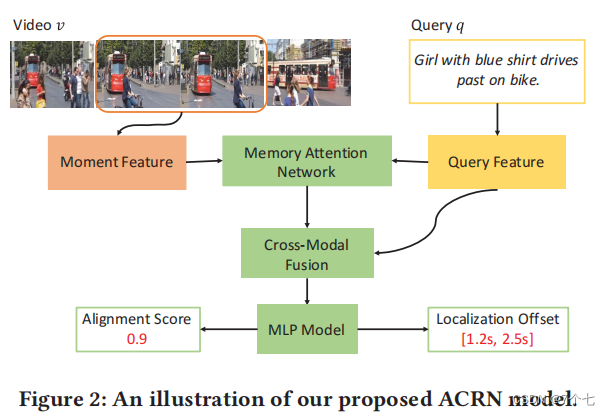
-
基于记忆的注意力网络,用于增强每个时刻的视觉嵌入表示,其中权重上下文信息用于进行注意力加权。
-
跨模态融合网络,用于探索时刻-查询的表示表示与视觉特征的内部和外部交互方式,生成每个时刻和查询之间的联合嵌入表示。
-
回归网络,用于预测每个时刻与查询的关联度得分以及黄金时刻的开始和结尾时间点之间的偏移量。
3.1Memory Attention Network
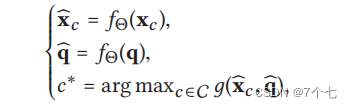
我们将视频片段的视觉特征和查询的文本特征都投影到一个共同的潜在空间中,并将它们输入到一个相似度函数中进行计算。计算得到的分数最高的视频片段会被作为最终的检索结果返回。具体来说,式子中的xc和q分别代表视频片段和查询的嵌入向量,fΘ(·)是一个映射函数,用于将xc和q映射到共同的潜在空间中,同时д表示相似度函数,用于计算视频片段和查询之间的相似度。
作者考虑通过赋予每个上下文中的不同片段一个注意力权重来明确捕捉其变化重要性。使用一种记忆注意力网络来实现这个想法,该网络由两个部分组成,可以为每个上下文片段的嵌入分配一个注意力权重。记忆注意力网络的细节如下图所示:
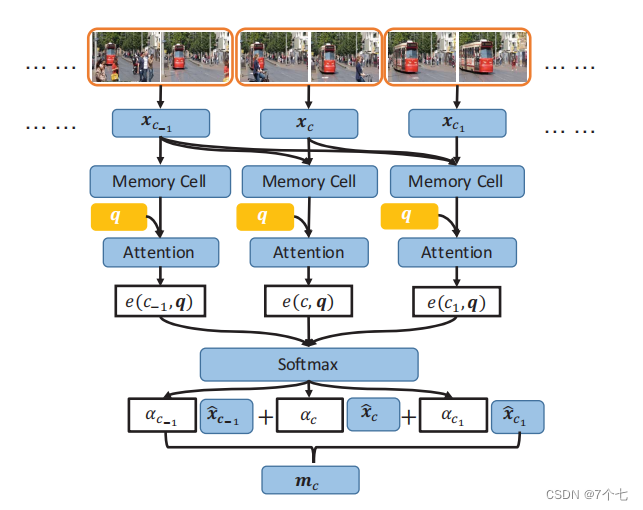
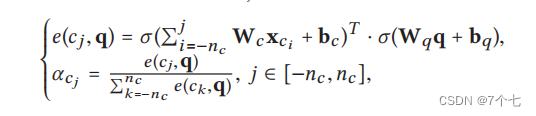
每个视频与查询问题之间的相关度得分(e(cj,q))。其中,cj表示视频帧的特征向量,q表示问题的嵌入向量,Wcq、Wqq、Wcx是模型的可训练参数,bcq、bq、bc是偏置项,σ代表sigmoid函数。然后,将所有相关度得分归一化为注意力权重αcj,用于后续计算。其中,nc表示视频帧的数量,e(ck,q)是所有视频帧与查询问题之间相关度得分的总和。
在得到注意力权重αcj之后,进行融合特征:
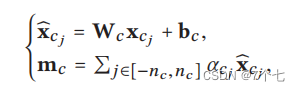
查询文本就是一个简单的
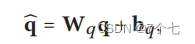
3.2Cross-Modal Fusion Network
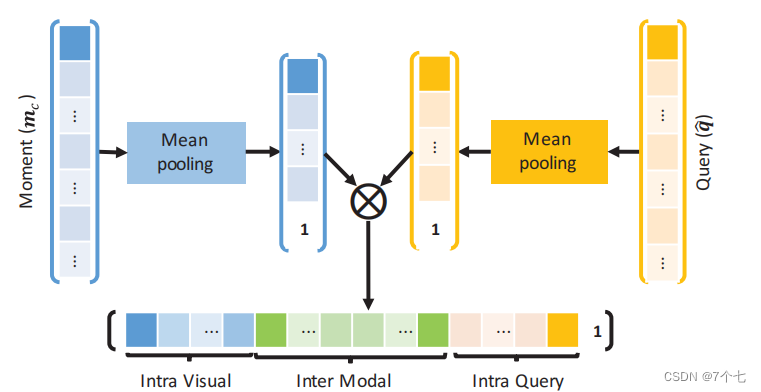
- 平均池化
每个输入嵌入应用一个大小为n的线性Filter,输出中的每个条目都是相应大小的核窗口的值的平均值。 - 张量融合
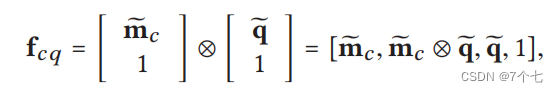
4.训练
4.1对齐损失
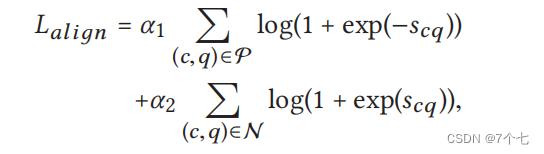
其中P为正矩查询对的集合,即对齐的矩查询对;N为负矩查询对的集合,即不对齐的矩查询对;α1和α2是控制正、负矩查询对之间权值的超参数。
4.2定位回归损失
由于采用多尺度时间滑动窗口来分割视频,不同的候选时刻有不同的持续时间。因此,对于每个时刻-查询对,我们不仅需要判断该时刻是否与查询相关,还需要决定与黄金时刻相比的定位偏移量。在形式上,我们表示起始点和结束点的偏移值如下:
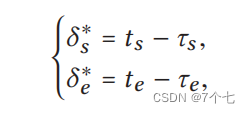
其中(ts,te)为给定查询的起始点和结束点,(τs,τe)为p中候选时刻的起始点和结束点。同时,我们使用δ∗= [δs∗,δe∗]来表示偏移。
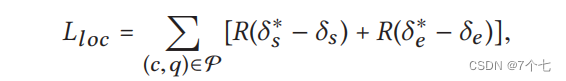
4.3合并
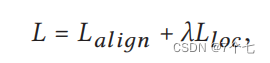
5.实验
5.1数据集
TACoS
DiDeMo
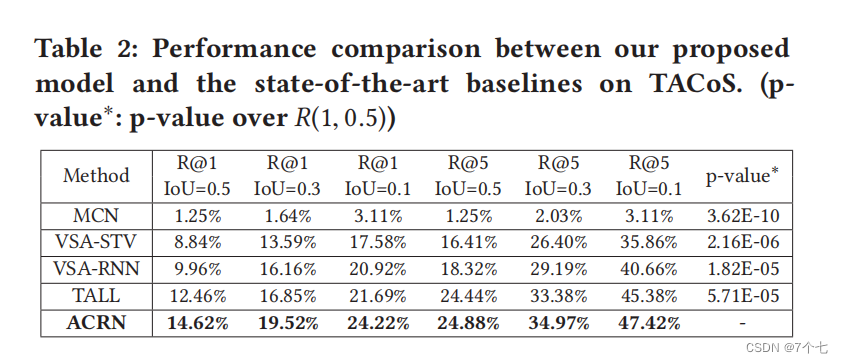
5.2效果
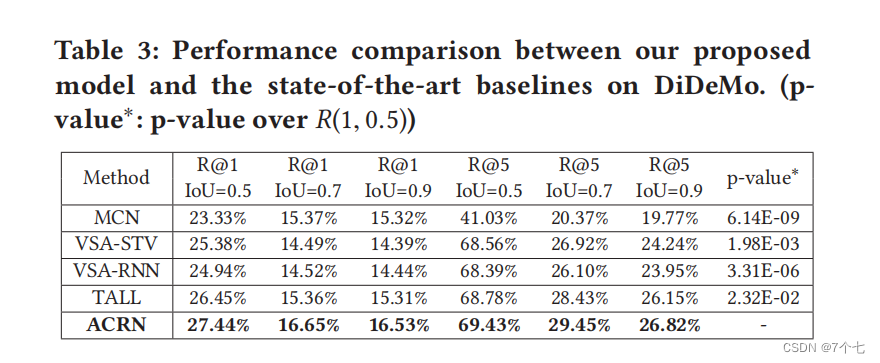
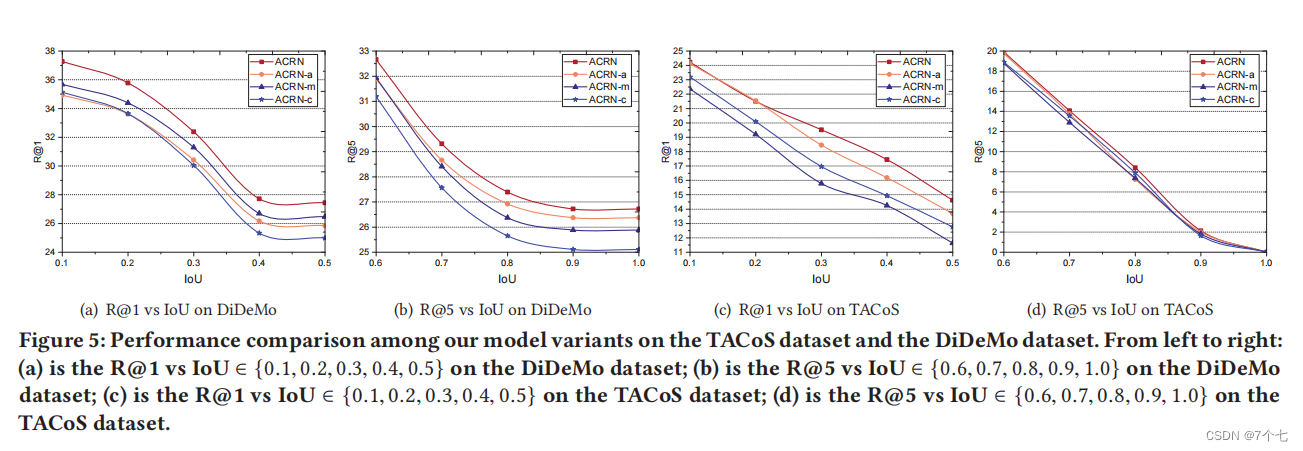
5.3ACRN的研究
- ACRN -a:采用了平均池化来取代我们提出的记忆注意网络来记忆上下文嵌入。
- ACRN-m:我们在等式中消除了记忆注意模型中的记忆部分。也就是说,每个上下文注意值只与其自身和查询相关,而不考虑上下文信息。
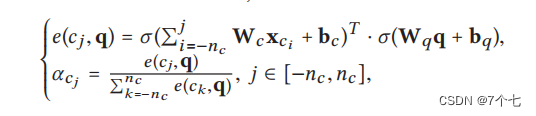
- ACRN-c:我们采用了早期的融合策略,即连接多模态特征。
6未来工作
- 计划设计一个端到端模型,它观察时刻,并决定下一步看哪里和何时做出预测。它不需要用多尺度滑动窗口预分割视频,并且可以快速缩小搜索空间。
- 在帧层面上研究不同的注意网络,并将它们纳入我们的模型,因为框架的不同部分对场景和查询理解有不同的影响
- 将在个性化时刻推荐中考虑我们的框架,其中检索结果与用户的个人兴趣相关。特别是,当给定一个视频时,个人查询历史记录被视为与用户-项目交互,以更好地捕捉用户对时刻的偏好。