背景
现在动不动就是微服务架构,但是微服务划分的合理与否会极大的影响开发过程中的复杂度,划分的重要性不言而喻,但是在微服务划分这条路上并没有银弹,有的说DDD可以解决微服务的划分问题,吕哥想说的是那只是理论上的,实际上影响微服务划分的因素众多,不能死搬教条,每个项目都有自己的特点和实际情况,我们要做的把理论与实际结合,把知识融会贯通,走“自己特色的项目道路”.
一、单体系统分解成微服务系统,如何划分最合理,为什么?
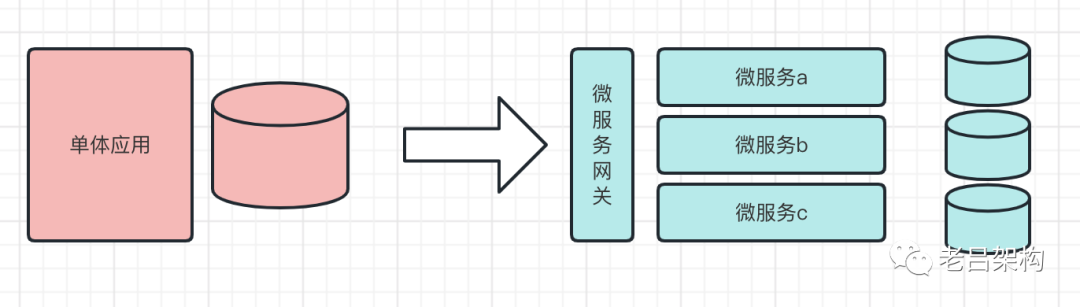
简单说的话就是:找到合理的划分边界,把每一个功能每一个接口每一个类放到最合适的服务中,使划分后的服务之间满足”高内聚,低耦合,同时要兼顾职责单一,代码复用率高“,这并不是一件容易的事情,难就难在影响的因素太多(技术因素、业务因素、人为利益因素,甚至受到公司部门斗争人情世故的影响),死搬教条是行不通的,一定要在基本正确的前提下不断改进与重构,向着最优解靠近。
“高内聚低耦合”意味着服务独立性高,依赖关系简单,那么复用率会受到什么影响呢?我之前写过关于“聊聊代码复用的文章”,复用的种类主要分两种情况:
1)集成式的JAR包复用;
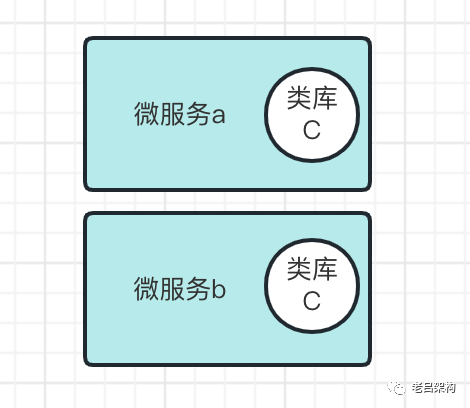
2)RPC式的接口复用;
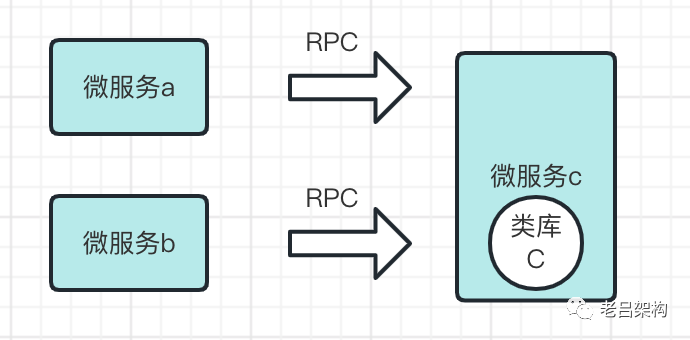
“高内聚低耦合” 对于集成式JAR包复用我认为没有影响,对于RPC式的接口复用意味着 复用率降低,但这同时也是低耦合的表现,不一定是坏处,这里面就需要一个平衡。
对于项目经验较少的同学来说,以上说法还是很抽象的,下面吕哥通过曾经的项目经历来剖析微服务化后带来的复杂性。
二、单体系统微服务化后到底会遇到什么问题?
1、数据库纵向拆分
微服务要求每个服务都有独立的数据库,跨服务的SQL联查会全部失效,如何解决?
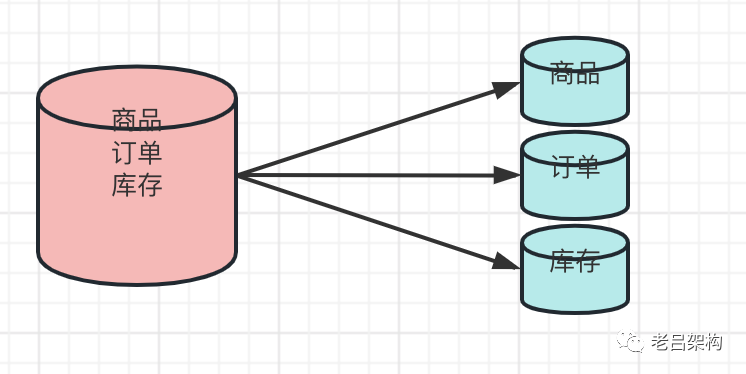
SQL联查意味着表之间是有关联性、依赖性、耦合性的,现在虽然数据库进行了物理隔离,但是这种业务上的关联性仍然是需要解决的,如何解决呢?
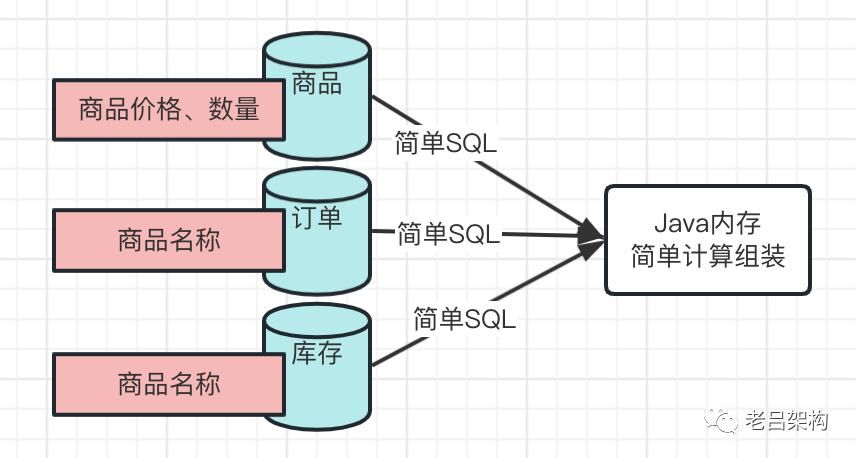
方案1)
关联逻辑转移到服务代码层,将复杂查询SQL拆解,属于自己服务管理的部分直接查库,属于别的服务管理的部分通过RPC查询,最后在内存中计算组合得到最终想要的结果;

方案2)
主库数据冗余,冗余的粒度可大可小,大则整张表冗余,小则按列进行冗余。无论哪种方式都需要解决数据的实时性和数据一致性问题;
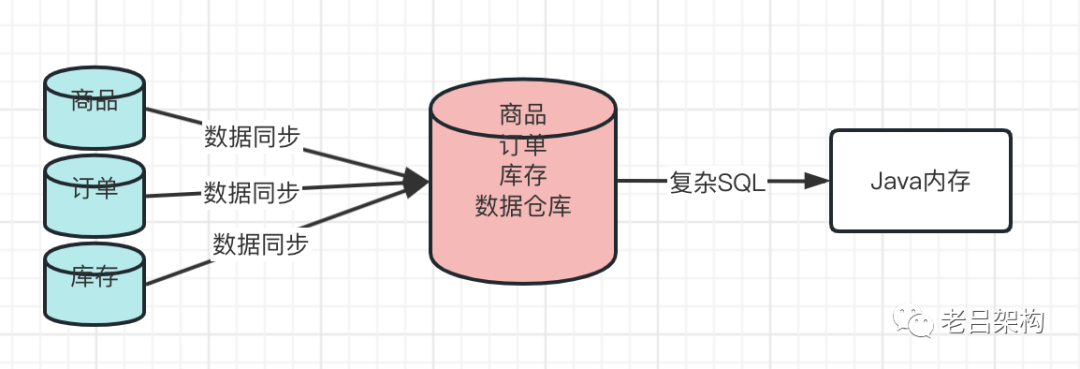
方案3)
数据集中到只读数据仓库中,再进行跨域SQL查询,同样需要解决数据的实时性和数据一致性问题;
2、分布式事务
微服务化后会产生RPC操作,由此产生的分布式事务(数据一致性问题)如何解决?
系统之间交互无非两种模式:
1)同步通信
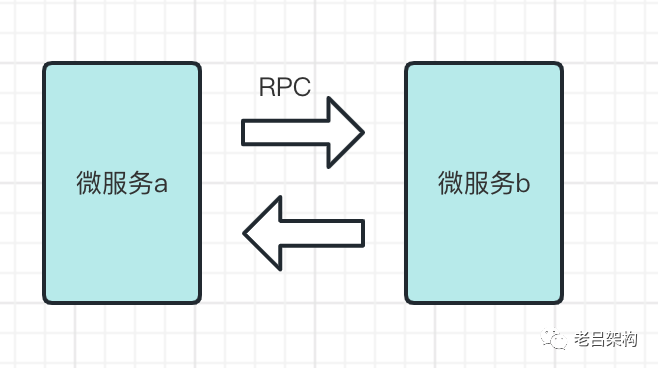
2)异步通信
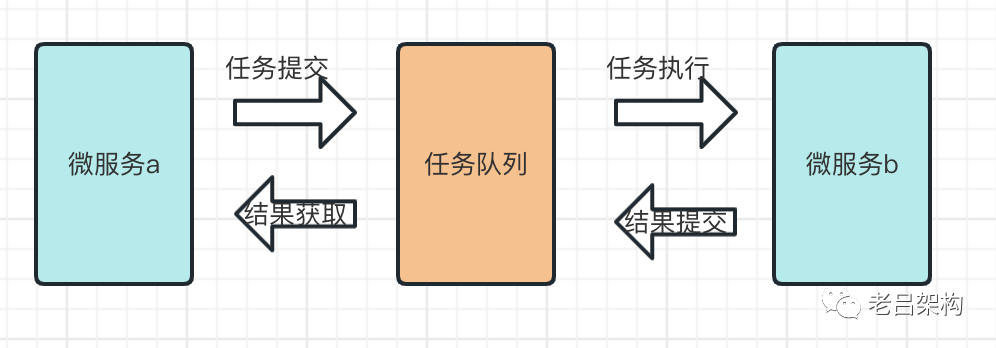
哪些业务需要同步通信,哪些业务可以接受异步通信?
同步通信模式下如何解决分布式事务问题?
1)SEAT框架AT模式
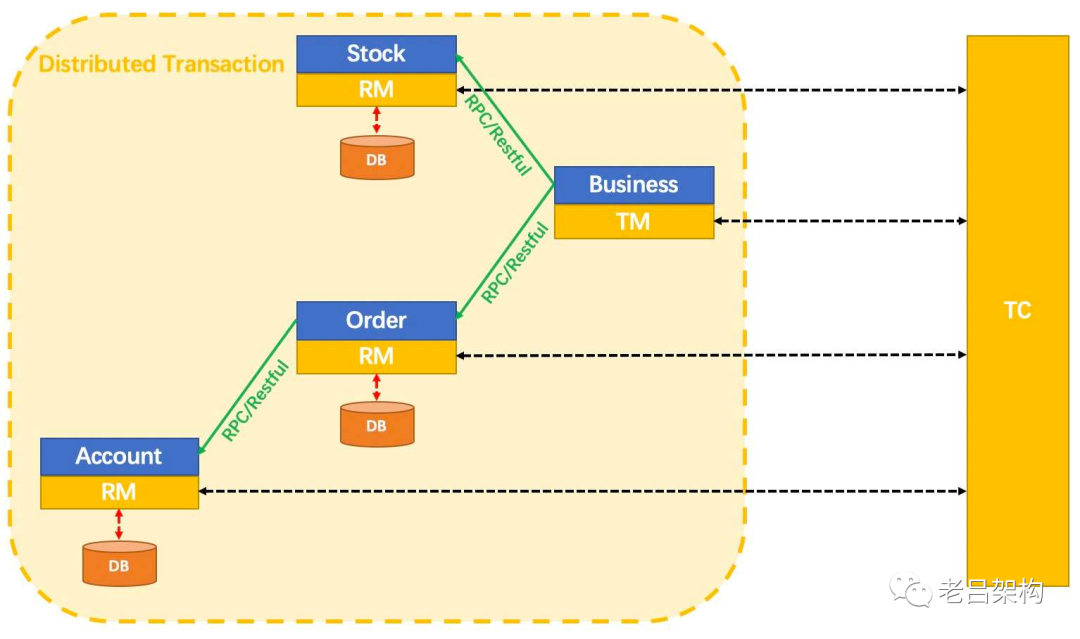
2)TCC框架
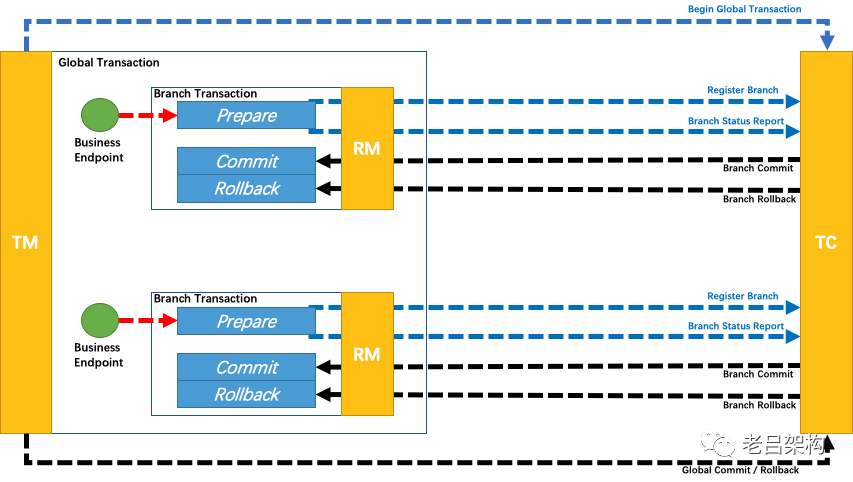
3)SAGA框架
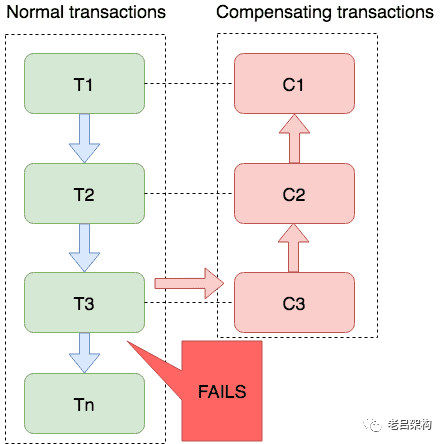
异步通信模式下如何解决分布式事务问题?
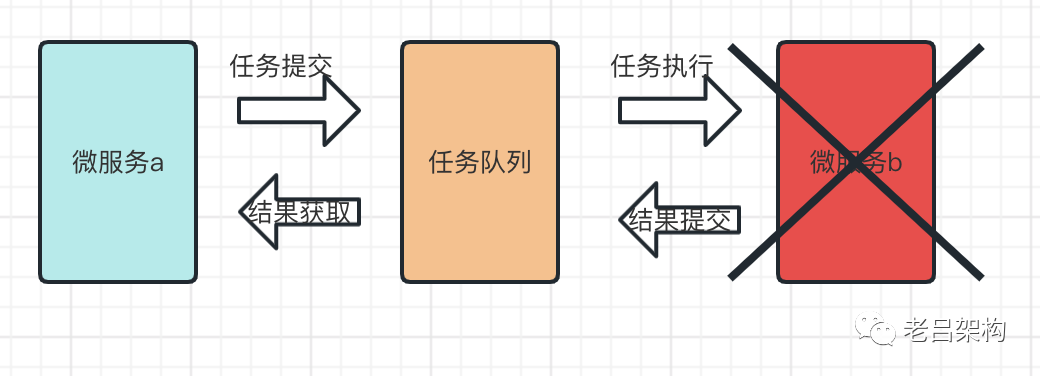
1)消息队列


2)定时任务


3、服务依赖
如何解决领域存活问题?服务雪崩问题?
对于同步通信模式下,领域存活会受到挑战,一般只能通过功能降级来应对;受接口堵塞的影响雪崩问题会接踵而来,一般通过限制接口超时时间、限制重试次数、接口熔断来解决;
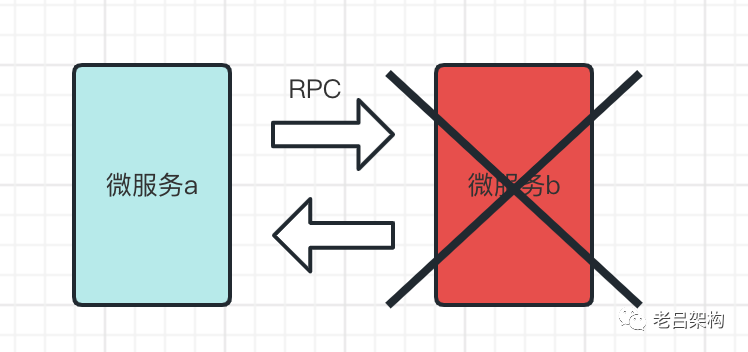
对于异步通信模式下,领域存活不会受到影响,也不会有雪崩问题,但是业务的进度会受到积压。
4、服务的主次之分
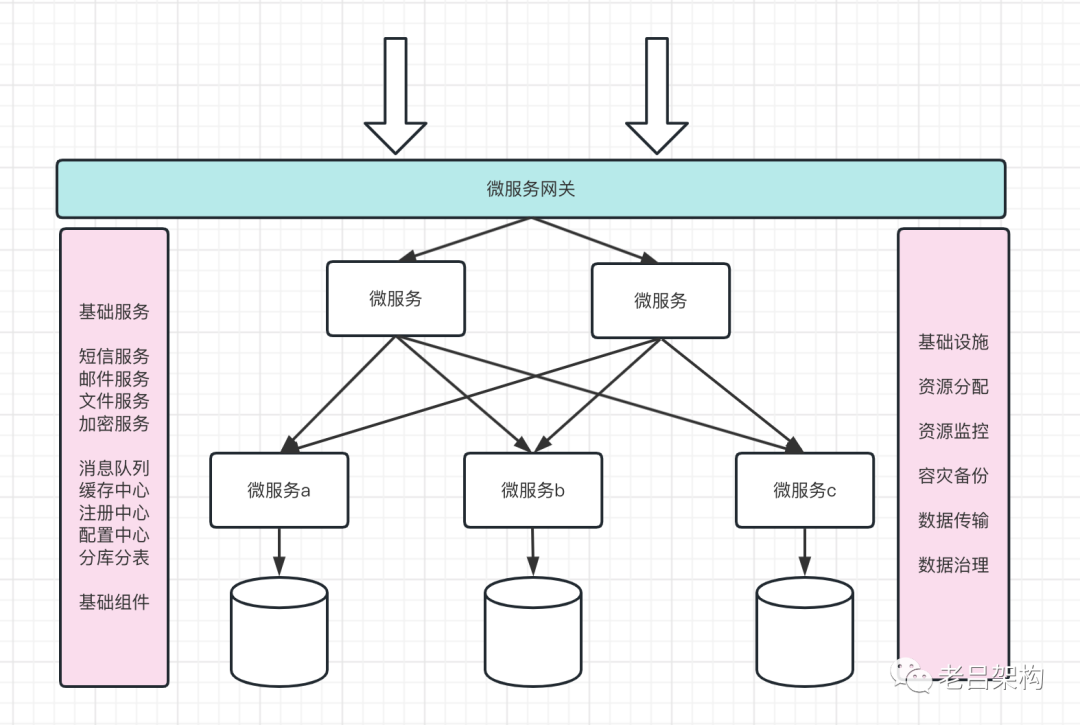
核心服务:影响全局服务的基础服务(如:ID生成服务)、影响关键路径的服务(如:登录服务)
重要服务:主要业务所在的服务,用户大部分时间都是在这个服务上操作的,如:商品查询、订单提交、订单支付
次要服务:辅助性的服务,售后服务、退货退款、发票服务、报表统计
对于核心服务是要保障三高的,它影响的是全局;
对于重要服务是要保障领域独立存活的,影响最小化,即使支付服务挂了,也不能影响 商品查询和订单提交等服务;
次要服务在遇到故障或资源紧张的情况下是可以降低资源投入或者临时关闭的;
三、总结
1、以服务的“高内聚,低耦合,兼顾职责单一,代码复用率高”为指导原则;
2、可以参考DDD领域驱动设计的方法论;
3、服务的拆分影响因素很多,包括团队技术水平、业务水平、人为因素、部门斗争、康威定律;
4、不要死搬教条,要不断地思考、改进重构、及时修正错误 才能达到一个相对理想的效果;





![[进阶]Java:线程概述、线程创建方式](https://img-blog.csdnimg.cn/e6dce84128e44b4cbb69d2d4687f3b4b.png)


![[进阶]Java:文件字节输出流、文件拷贝、资源释放](https://img-blog.csdnimg.cn/bcd54b185e91421198b7c0b436c1805d.png)