CenterNet: Objects as Points - 目标作为点(arXiv 2019)
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 准备工作
- 4. 目标作为点
- 4.1 3D 检测
- 4.2 人体姿态估计
- 5. 实施细节
- 6. 实验
- 6.1 目标检测
- 6.1.1 附加实验
- 6.2 3D 检测
- 6.3 姿态估计
- 7. 结论
- References
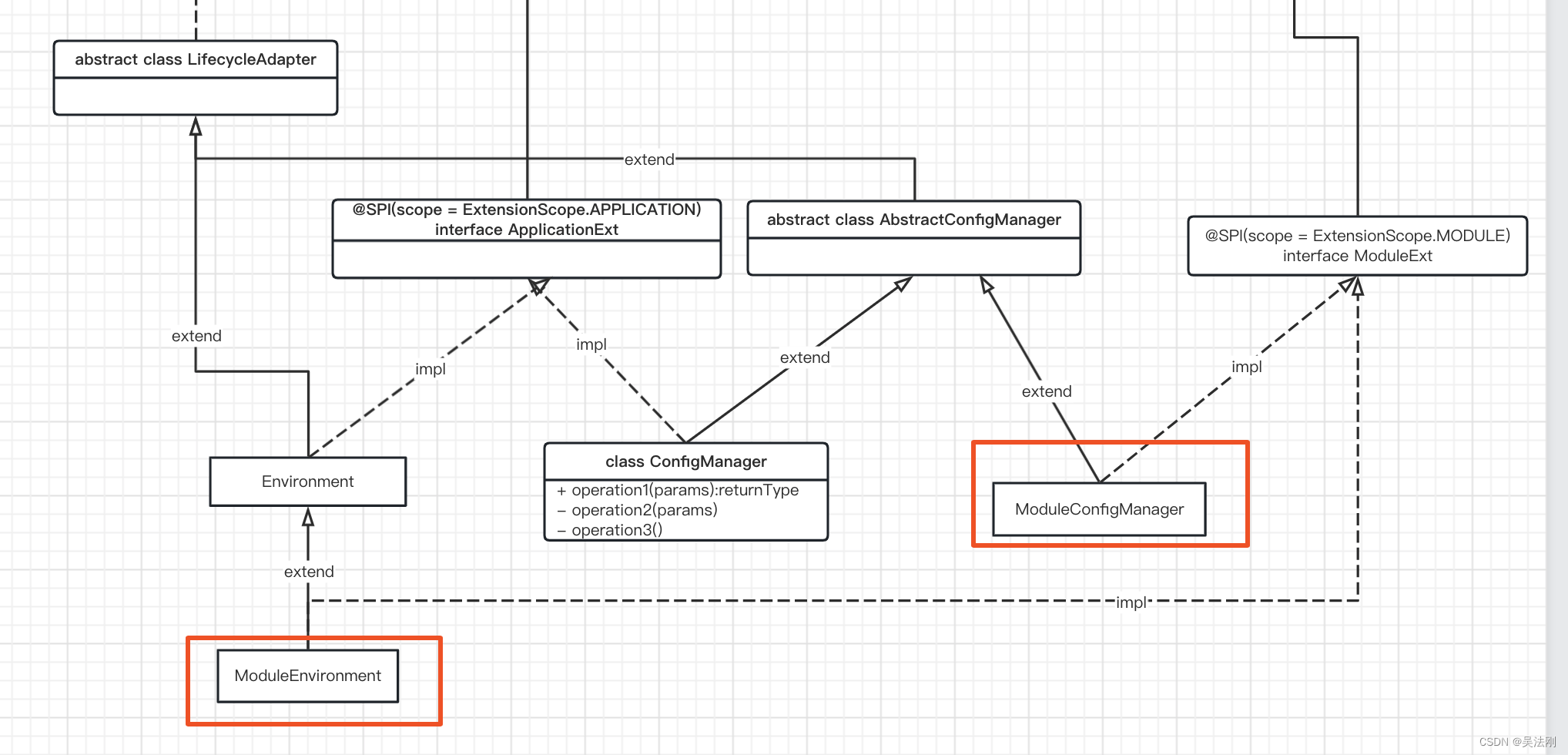
- 附录A:模型体系结构
- 附录B:3D BBox估算细节
- 附录C:碰撞实验细节
- 附录D:PascalVOC实验
- 附录E:误差分析
声明:此翻译仅为个人学习记录
文章信息
- 标题:Objects as Points (arXiv 2019)
- 作者:Xingyi Zhou, Dequan Wang, Philipp Krähenbühl
- 文章链接:https://arxiv.org/pdf/1904.07850.pdf
- 文章代码:https://github.com/xingyizhou/CenterNet
摘要
检测将目标识别为图像中的轴对齐框。大多数成功的目标检测器列举了一个几乎详尽的潜在目标位置列表,并对每个位置进行分类。这是浪费、低效的,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将目标建模为单个点,即其边界框的中心点。我们的检测器使用关键点估计来找到中心点,并回归到所有其他目标属性,如大小、3D位置、方向,甚至姿势。我们的基于中心点的方法CenterNet是端到端可微,比相应的基于边界框的检测器更简单、更快、更准确。CenterNet在MS COCO数据集上实现了最佳的速度-精度权衡,在142 FPS下具有28.1%的AP,在52 FPS下具有37.4%的AP,以及在1.4 FPS下具有多尺度测试的45.1%的AP。我们使用相同的方法来估计KITTI基准中的3D边界框和COCO关键点数据集上的人体姿态。我们的方法与复杂的多阶段方法相比具有竞争力,并且实时运行。
1. 引言
目标检测为许多视觉任务提供了动力,如实例分割[7,21,32]、姿态估计[3,15,39]、跟踪[24,27]和动作识别[5]。它在监控[57]、自动驾驶[53]和视觉问答[1]中有下游应用。当前目标检测器通过紧密包围目标的轴对齐边界框来表示每个目标[18,19,33,43,46]。然后,他们将目标检测简化为大量潜在目标边界框的图像分类。对于每个边界框,分类器确定图像内容是特定目标还是背景。一级检测器[33,43]在图像上滑动一个称为锚点的可能边界框的复杂排列,并在不指定框内容的情况下直接对其进行分类。两级检测器[18,19,46]重新计算每个潜在盒子的图像特征,然后对这些特征进行分类。后处理,即非最大值抑制,然后通过计算边界框IoU来去除相同实例的重复检测。这种后处理很难区分和训练[23],因此大多数当前检测器不是端到端可训练的。尽管如此,在过去的五年[19]中,这一想法取得了良好的实证成功[12,21,25,26,31,35,47,48,56,62,63]。然而,基于滑动窗口的目标检测器有点浪费,因为它们需要枚举所有可能的目标位置和维度。

图1:实时检测器COCO验证的速度-精度权衡。所提出的CenterNet优于一系列最先进的算法。
在本文中,我们提供了一种更简单、更有效的替代方案。我们用边界框中心的一个点来表示目标(见图2)。然后直接从中心位置的图像特征回归其他特性,如目标大小、尺寸、3D范围、方向和姿态。因此,目标检测是一个标准的关键点估计问题[3,39,60]。我们只需将输入图像馈送到生成热图的全卷积网络[37,40]。该热图中的峰值对应于目标中心。每个顶点处的图像特征预测目标边界框的高度和权重。该模型使用标准的密集监督学习进行训练[39,60]。推理是单个网络前向传递,没有用于后处理的非最大抑制。

图2:我们将一个目标建模为其边界框的中心点。边界框大小和其他目标特性是从中心的关键点特征推断出来的。最佳观看颜色。
我们的方法是通用的,只需付出很小的努力就可以扩展到其他任务。我们通过预测每个中心点的额外输出,提供了3D目标检测[17]和多人人体姿态估计[4]的实验(见图4)。对于3D边界框估计,我们回归到目标绝对深度、3D边界框尺寸和目标方向[38]。对于人体姿态估计,我们将2D关节位置视为距中心的偏移,并在中心点位置直接回归到它们。
我们的方法CenterNet的简单性使它能够以非常高的速度运行(图1)。通过简单的Resnet-18和上卷积层[55],我们的网络以142 FPS运行,具有28.1%的COCO边界框AP。通过精心设计的关键点检测网络DLA-34[58],我们的网络在52 FPS下实现了37.4%的COCO AP。配备了最先进的关键点估计网络Hourglass-104[30,40]和多尺度测试,我们的网络在1.4 FPS下实现了45.1%的COCO AP。在3D边界框估计和人体姿态估计方面,我们以更高的推理速度与最先进的技术相比具有竞争力。代码位于https://github.com/xingyizhou/CenterNet.
2. 相关工作
通过区域分类进行目标检测。首批成功的深度目标检测器之一,RCNN[19],从一大组候选区域中枚举目标位置[52],对其进行裁剪,并使用深度网络对每个目标进行分类。Fast-RCNN[18]裁剪图像特征,以节省计算。然而,这两种方法都依赖于缓慢的低级别区域建议方法。
使用隐式锚点进行目标检测。Faster-RCNN[46]在检测网络内生成区域建议。它对低分辨率图像网格周围的固定形状边界框(锚点)进行采样,并将每个边界框分类为“前景或非前景”。锚点被标记为与任何真值目标重叠大于0.7的前景、重叠小于0.3的背景,或者在其他情况下被忽略。每个生成的区域建议都被再次分类[18]。将建议分类器更改为多类分类形成了一级检测器的基础。对一级检测器的一些改进包括锚形状先验[44,45]、不同的特征分辨率[36]和不同样本之间的损失重新加权[33]。
我们的方法与基于锚的一阶段方法密切相关[33,36,43]。中心点可以看作是一个单一的形状不可知的锚点(见图3)。然而,也有一些重要的区别。首先,我们的CenterNet仅根据位置而不是方框重叠来分配“锚点”[18]。我们没有用于前景和背景分类的手动阈值[18]。其次,我们每个目标只有一个正“锚点”,因此不需要非最大抑制(NMS)[2]。我们简单地提取关键点热图中的局部峰值[4,39]。第三,与传统的目标检测器[21,22](输出步长为16)相比,CenterNet使用更大的输出分辨率(输出步长4)。这消除了对多个锚的需要[47]。
通过关键点估计进行目标检测。我们不是第一个将关键点估计用于目标检测的人。CornerNet[30]检测两个边界框角作为关键点,而ExtremeNet[61]检测所有目标的顶部、左侧、底部、最右侧和中心点。这两种方法都建立在与我们的CenterNet相同的鲁棒关键点估计网络上。然而,它们需要在关键点检测之后进行组合分组阶段,这显著减慢了每个算法的速度。另一方面,我们的CenterNet只需为每个目标提取一个中心点,而无需分组或后处理。
单目3D目标检测。3D边界框估计为自动驾驶提供了动力[17]。Deep3Dbox[38]使用slow-RCNN[19]风格的框架,通过首先检测2D目标[46],然后将每个目标馈送到3D估计网络中。3D RCNN[29]为Faster-RCNN[46]添加了一个额外的头,然后是3D投影。Deep Manta[6]使用在许多任务中训练的从粗到细的更快RCNN[46]。我们的方法类似于Deep3Dbox[38]或3DRCNN[29]的单阶段版本。因此,CenterNet比竞争方法简单快捷得多。

图3:基于锚的检测器(a)和我们的中心点检测器(b)之间的不同。最好在屏幕上观看。
3. 准备工作
设 I ∈ R W × H × 3 I∈R^{W×H×3} I∈RW×H×3是宽度W和高度H的输入图像。我们的目标是产生关键点热图 Y ^ ∈ [ 0 , 1 ] W R × H R × C \hat{Y}∈[0,1]^{\frac{W}{R}×\frac{H}{R}×C} Y^∈[0,1]RW×RH×C,其中R是输出步长,C是关键点类型的数量。关键点类型包括人体姿态估计中的C=17个人体关节[4,55],或目标检测中的C=80个目标类别[30,61]。我们在文献[4,40,42]中使用R=4的默认输出步幅。输出步幅通过因子R对输出预测进行下采样。预测 Y ^ x , y , c = 1 \hat{Y}_{x,y,c}=1 Y^x,y,c=1对应于检测到的关键点,而 Y ^ x , y , c = 0 \hat{Y}_{x,y,c}=0 Y^x,y,c=0是背景。我们使用几种不同的全卷积编码器-解码器网络来预测图像 I I I中的 Y ^ \hat{Y} Y^:堆叠沙漏网络[30,40]、上卷积残差网络(ResNet)[22,55]和深层聚合(DLA)[58]。
我们按照Law和Deng[30]训练关键点预测网络。对于类c的每个真值关键点
p
∈
R
2
p∈R^2
p∈R2,我们计算一个低分辨率等价
p
~
=
⌊
p
R
⌋
\tilde{p}=\lfloor\frac{p}{R}\rfloor
p~=⌊Rp⌋。然后,我们使用高斯核
Y
x
y
c
=
e
x
p
(
−
(
x
−
p
x
~
)
2
+
(
y
−
p
y
~
)
2
2
σ
p
2
)
Y_{xyc}=exp(-\frac{(x−\tilde{p_x})^2+(y−\tilde{p_y})^2}{2σ^2_p})
Yxyc=exp(−2σp2(x−px~)2+(y−py~)2)将所有真值关键点泼溅到热图
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y∈[0,1]^{\frac{W}{R}×\frac{H}{R}×C}
Y∈[0,1]RW×RH×C上,其中
σ
p
σ_p
σp是目标大小自适应标准偏差[30]。如果同一类的两个高斯重叠,我们取元素最大值[4]。训练目标是具有焦点损失的惩罚减少像素逻辑回归[33]:

其中,α和β是焦损失的超参数[33],N是图像I中的关键点数量。选择N的归一化来将所有正焦损失实例归一化为1。我们在所有实验中使用α=2和β=4,遵循Law和Deng[30]。
为了恢复由输出步幅引起的离散化误差,我们还预测了每个中心点的局部偏移量
O
^
∈
R
W
R
×
H
R
×
2
\hat{O}∈R^{\frac{W}{R}×\frac{H}{R}×2}
O^∈RRW×RH×2。所有类别c共享相同的偏移预测。偏移以L1损失进行训练

监督仅作用于关键点位置
p
~
\tilde{p}
p~,忽略所有其他位置。
在下一节中,我们将展示如何将该关键点估计器扩展到通用目标检测器。
4. 目标作为点
设
(
x
1
(
k
)
,
y
1
(
k
)
,
x
2
(
k
)
,
y
2
(
k
)
)
(x^{(k)}_1,y^{(k)}_1,x^{(k)}_2,y^{(k)}_2)
(x1(k),y1(k),x2(k),y2(k))为具有类别
c
k
c_k
ck的目标k的边界框,其中心点位于
p
k
=
(
x
1
(
k
)
+
x
2
(
k
)
2
,
y
1
(
k
)
+
y
2
(
k
)
2
)
p_k=(\frac{x^{(k)}_1+x^{(k)}_2}{2},\frac{y^{(k)}_1+y^{(k)}_2}{2})
pk=(2x1(k)+x2(k),2y1(k)+y2(k))。我们使用我们的关键点估计器
Y
^
\hat{Y}
Y^来预测所有的中心点。此外,我们回归到每个目标
k
k
k的目标大小
s
k
=
(
x
2
(
k
)
−
x
1
(
k
)
,
y
2
(
k
)
−
y
1
(
k
)
)
s_k=(x^{(k)}_2-x^{(k)}_1,y^{(k)}_2-y^{(k)}_1)
sk=(x2(k)−x1(k),y2(k)−y1(k))。为了限制计算负担,我们对所有目标类别使用单尺寸预测
S
^
∈
R
W
R
×
H
R
×
2
\hat{S}∈R^{\frac{W}{R}×\frac{H}{R}×2}
S^∈RRW×RH×2。我们在中心点使用L1损失,类似于目标2:

我们不归一化尺度,而是直接使用原始像素坐标。相反,我们通过恒定的
λ
s
i
z
e
λ_{size}
λsize来缩放损失。总体训练目标是

除非另有规定,否则我们在所有实验中都设置
λ
s
i
z
e
=
0.1
λ_{size}=0.1
λsize=0.1和
λ
o
f
f
=
1
λ_{off}=1
λoff=1。我们使用单个网络来预测关键点
Y
^
\hat{Y}
Y^、偏移量
O
^
\hat{O}
O^和大小
S
^
\hat{S}
S^。该网络在每个位置预测总共
C
+
4
C+4
C+4个输出。所有输出共享一个公共的全卷积骨干网络。对于每个模态,主干的特征然后通过单独的3×3卷积、ReLU和另一个1×1卷积。图4显示了网络输出的概述。第5节和补充材料包含额外的架构细节。
从点到边界框 在推断时,我们首先独立地提取每个类别的热图中的峰值。我们检测其值大于或等于其8连接邻居的所有响应,并保持前100个峰值。设
P
^
c
\hat{P}_c
P^c是c类的
n
n
n个检测到的中心点
P
^
=
{
(
x
^
i
,
y
^
i
)
}
i
=
1
n
\hat{P}=\{(\hat{x}_i,\hat{y}_i)\}_{i=1}^n
P^={(x^i,y^i)}i=1n的集合。每个关键点位置由整数坐标
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)给出。我们使用关键点值
Y
^
x
i
y
i
c
\hat{Y}_{x_iy_ic}
Y^xiyic作为其检测置信度的度量,并在位置处生成边界框

其中
(
δ
x
^
i
,
δ
y
^
i
)
=
O
^
x
^
i
,
y
^
i
(δ\hat{x}_i,δ\hat{y}_i)=\hat{O}_{\hat{x}_i,\hat{y}_i}
(δx^i,δy^i)=O^x^i,y^i是偏移预测,并且
(
w
^
i
,
h
^
i
)
=
S
^
x
^
i
,
y
^
i
(\hat{w}_i,\hat{h}_i)=\hat{S}_{\hat{x}_i,\hat{y}_i}
(w^i,h^i)=S^x^i,y^i是尺寸预测。所有输出都是直接从关键点估计产生的,而不需要基于IoU的非最大值抑制(NMS)或其他后处理。峰值关键点提取是一种足够的NMS替代方案,可以使用3×3最大池化操作在设备上高效实现。

图4:我们的网络针对不同任务的输出:顶部用于目标检测,中间用于3D目标检测,底部:用于姿态估计。所有模态都是从一个公共主干产生的,具有由ReLU分隔的不同的3×3和1×1输出卷积。括号中的数字表示输出通道。详见第4节。
4.1 3D 检测
3D检测估计每个目标的3D边界框,并且每个中心点需要三个附加属性:深度、3D尺寸和方向。我们为每一个添加一个单独的头。深度d是每个中心点的单个标量。然而,深度很难直接回归。相反,我们使用Eigen等人[13]的输出变换和 d = 1 / σ ( d ^ ) − 1 d=1/σ(\hat{d})−1 d=1/σ(d^)−1,其中σ是sigmoid函数。我们将深度计算为我们的关键点估计器的附加输出通道,其中, D ^ ∈ [ 0 , 1 ] W R × H R \hat{D}∈[0,1]^{\frac{W}{R}×\frac{H}{R}} D^∈[0,1]RW×RH。它再次使用由ReLU分隔的两个卷积层。与以前的模态不同,它在输出层使用逆sigmoidal变换。在sigmoidal变换之后,我们在原始深度域中使用L1损失来训练深度估计器。
目标的3D尺寸是三个标量。我们使用单独的头 Γ ^ ∈ R W R × H R × 3 \hat{Γ}∈R^{\frac{W}{R}×\frac{H}{R}×3} Γ^∈RRW×RH×3和L1损失直接回归到它们的绝对值(以米为单位)。
默认情况下,方向是单个标量。然而,它可能很难回归到。我们遵循Mousavian等人[38],并将方向表示为两个具有in-bin回归的bins。具体来说,使用8个标量对方向进行编码,每个bin有4个标量。对于一个bin,两个标量用于softmax分类,其余两个标量回归到每个bin内的角度。有关这些损失的详细信息,请参阅补充资料。
4.2 人体姿态估计
人体姿态估计旨在为图像中的每个人体实例估计k个2D人体关节位置(对于COCO,k=17)。我们将姿态视为中心点的k×2维属性,并通过到中心点的偏移量对每个关键点进行参数化。我们直接回归到具有L1损失的联合偏移(以像素为单位) J ^ ∈ R W R × H R × k × 2 \hat{J}∈R^{\frac{W}{R}×\frac{H}{R}×k×2} J^∈RRW×RH×k×2。我们通过掩盖损失来忽略不可见的关键点。这导致了一种基于回归的一阶段多人姿态估计器,类似于slow-RCNN版本的对应Toshev等人[51]和Sun等人[49]。
为了细化关键点,我们使用标准的自下而上的多人姿态估计[4,39,41]进一步估计了 k k k个人体关节热图,其中 Φ ^ ∈ R W R × H R × k \hat{Φ}∈R^{\frac{W}{R}×\frac{H}{R}×k} Φ^∈RRW×RH×k。我们训练具有焦点损失和局部像素偏移的人体关节热图,类似于第3节中讨论的中心检测。
然后,我们将最初的预测捕捉到热图上最接近的检测到的关键点。在这里,我们的中心偏移充当分组提示,将单个关键点检测分配给其最近的人实例。具体地,设 ( x ^ , y ^ ) (\hat{x},\hat{y}) (x^,y^)为检测到的中心点。我们首先回归到 j ∈ 1... k j∈1...k j∈1...k的所有关节位置 l j = ( x ^ , y ^ ) + J ^ x ^ y ^ j l_j=(\hat{x},\hat{y})+\hat{J}_{\hat{x}\hat{y}j} lj=(x^,y^)+J^x^y^j。我们还从对应的热图 Φ ^ . . j \hat{Φ}_{..j} Φ^..j中提取每个关节类型 j j j的置信度>0.1的所有关键点位置 L j = { l ~ j i } i = 1 n j L_j=\{\tilde{l}_{ji}\}^{n_j}_{i=1} Lj={l~ji}i=1nj。然后,我们将每个回归位置 l j l_j lj分配给其最近的检测关键点 a r g m i n l ∈ L j ( l − l j ) 2 arg min_{l∈L_j}(l−l_j)^2 argminl∈Lj(l−lj)2,仅考虑检测目标的边界框内的关节检测。
5. 实施细节
我们对4种架构进行了实验:ResNet-18、ResNet-101[55]、DLA-34[58]和Hourglass-104[30]。我们使用可变形卷积层[12]修改了ResNets和DLA-34,并按原样使用Hourglass网络。
Hourglass 堆叠沙漏网络[30,40]将输入向下采样4×,然后是两个顺序沙漏模块。每个沙漏模块是一个具有跳跃连接的对称5层上下卷积网络。该网络相当大,但通常产生最佳的关键点估计性能。

表1:COCO验证集上不同网络的速度/准确性权衡。我们展示了没有测试增强(N.A.)、翻转测试(F)和多尺度增强(MS)的结果。
ResNet Xiao等人[55]用三个上卷积网络扩充标准残差网络[22],以实现更高分辨率的输出(输出步长4)。我们首先将三个上采样层的通道分别更改为256, 128, 64,以节省计算。然后,我们分别在与通道256, 128, 64的每个上卷积之前添加一个3×3可变形卷积层。上卷积核被初始化为双线性插值。有关详细的体系结构图,请参阅补充。
DLA 深层聚合(DLA)[58]是一种具有分层跳过连接的图像分类网络。我们利用DLA的全卷积上采样版本进行密集预测,该版本使用迭代深度聚合来对称地提高特征图分辨率。我们用可变形卷积[63]将跳跃连接从较低层扩展到输出。具体来说,我们在每个上采样层用3×3可变形卷积代替原始卷积。有关详细的体系结构图,请参阅补充。我们在每个输出头之前添加一个具有256通道的3×3卷积层。最后的1×1卷积产生所需的输出。我们在补充材料中提供了更多细节。
训练 我们在512×512的输入分辨率上进行训练。这为所有模型产生了128×128的输出分辨率。我们使用随机翻转、随机缩放(在0.6到1.3之间)、裁剪和颜色抖动作为数据增强,并使用Adam[28]来优化总体目标。我们不使用增强来训练3D估计分支,因为裁剪或缩放会改变3D测量。对于残差网络和DLA-34,我们以128的批量大小(在8个GPU上)和140个时期的学习率5e-4进行训练,在90和120个时期,学习率分别下降了10倍(如同[55])。对于Hourglass-104,我们遵循ExtremeNet[61],并使用批次大小29(在5个GPU上,主GPU批次大小为4)和50个时期的学习率2.5e-4,其中10×学习率在40个时期下降。对于检测,我们微调ExtremeNet[61]中的Hourglass-104以节省计算。Resnet-101和DLA-34的下采样层用ImageNet预训练初始化,上采样层随机初始化。Resnet-101和DLA-34在8个TITAN-V GPU上训练2.5天,而Hourglass-104需要5天。
推理 我们使用三个级别的测试增强:无增强、翻转增强、翻转和多尺度(0.5、0.75、1、1.25、1.5)。对于翻转,我们在解码边界框之前对网络输出进行平均。对于多尺度,我们使用NMS来合并结果。这些增强产生了不同的速度-精度权衡,如下一节所示。
6. 实验
我们在MS COCO数据集[34]上评估了我们的目标检测性能,该数据集包含118k个训练图像(train2017)、5k个验证图像(val2017)和20k个保持测试图像(test-dev)。我们报告了所有IOU阈值(AP)的平均精度,在IOU阈值0.5(AP50)和0.75(AP75)时的AP。该补充包含PascalVOC的额外实验[14]。
6.1 目标检测
表1显示了我们在不同主干和测试选项下对COCO验证的结果,而图1将CenterNet与其他实时检测器进行了比较。运行时间在我们的本地机器上进行了测试,包括Intel Core i7-8086K CPU、Titan Xp GPU、Pytorch 0.4.1、CUDA 9.0和CUDNN 7.1。我们下载代码和预先训练的模型(https://github.com/facebookresearch/Detectron、https://github.com/pjreddie/darknet),在同一台机器上测试每个模型的运行时间。
Hourglass-104以相对良好的速度获得了最佳的精度,在7.8 FPS的帧速率下达到了42.2%的AP。在这个主干上,CenterNet在速度和准确性方面都优于CornerNet[30](4.1 FPS时的40.6%AP)和ExtremeNet[61](3.1 FPS时的40.3%AP)。运行时的改进来自于更少的输出头和更简单的框解码方案。更高的精度表明中心点比角点或极值点更容易检测。
使用ResNet-101,我们在相同网络主干的情况下优于RetinaNet[33]。我们只在上采样层中使用可变形卷积,这不会影响RetinaNet。在相同的精度下,我们的速度是原来的两倍多(CenterNet在45 FPS(输入512×512)时的34.8%AP,而RetinaNet在18 FPS(输入500×800)时为34.4%AP)。我们最快的ResNet-18模型在142 FPS的帧速率下也取得了28.1%的COCO AP的可观性能。
DLA-34提供了最佳的速度/精度权衡。它以52 FPS的速度运行,AP为37.4%。这帧率是YOLOv3[45]的两倍多,4.4% AP更多的准确率。通过翻转测试,我们的模型仍然比YOLOv3[45]更快,并达到了更快的RCNN FPN[46]的精度水平(28 FPS时的CenterNet 39.2%AP与11 FPS时的Faster-RCNN 39.8%AP)。
最先进的比较 我们在表2中与COCO测试开发中的其他最先进的检测器进行了比较。通过多尺度评估,带有Hourglass-104的CenterNet实现了45.1%的AP,优于所有现有的单级检测器。复杂的两级检测器[31,35,48,63]更准确,但也更慢。对于不同的目标大小或IoU阈值,CenterNet和滑动窗口检测器之间没有显著差异。CenterNet的行为就像一个普通的检测器,只是速度更快。

表2:COCO测试的最新比较。顶部:两级检测器;底部:一级检测器。我们展示了大多数单级检测器的单尺度/多尺度测试。尽可能在同一台机器上测量每秒帧数(FPS)。斜体FPS突出显示了从原始出版物中复制性能度量的情况。短划线表示既没有代码和模型,也没有公开时间可用的方法。
6.1.1 附加实验
在不幸的情况下,如果两个不同的目标完全对齐,它们可能共享同一个中心。在这种情况下,CenterNet将只检测到其中一个。我们首先研究这种情况在实践中发生的频率,并将其与竞争方法的遗漏检测联系起来。
中心点碰撞 在COCO训练集中,有614对目标在步幅4处碰撞到同一中心点上。总共有860001个目标,因此由于中心点的碰撞,CenterNet无法预测<0.1%的目标。这远小于由于不完美的区域建议[52](~2%)导致的slow-或fast-RCNN未命中,也小于由于锚位置不足[46]导致的基于锚的方法未命中(对于0.5 IOU阈值下有15个锚的Faster-RCNN为20.0%)。此外,715对目标的边界框IoU>0.7,并且将被分配给两个锚点,因此基于中心的分配导致较少的碰撞。
NMS 为了验证CenterNet不需要基于IoU的NMS,我们将其作为预测的后处理步骤。对于DLA-34(翻转测试),AP从39.2%提高到39.7%。对于Hourglass-104,AP保持在42.2%。考虑到较小的影响,我们不使用它。接下来,我们去除模型的新超参数。所有实验均在DLA-34上进行。
训练和测试解决方案 在训练过程中,我们将输入分辨率固定为512×512。在测试过程中,我们遵循CornerNet[30]来保持原始图像分辨率,并将输入填零(zero-pad)到网络的最大步幅。对于ResNet和DLA,我们用最多32个像素填充图像,对于HourglassNet,我们使用128个像素。如表3a所示,保持原始分辨率略好于固定测试分辨率。在较低分辨率(384×384)下进行训练和测试的速度提高了1.7倍,但下降了3AP。
回归损失 对于大小回归,我们将vanilla L1损失与Smooth L1[18]进行了比较。我们在表3c中的实验表明,L1比Smooth L1好得多。它在精细尺度上产生了更好的准确性,而COCO评估指标对此很敏感。这在关键点回归中独立观察到[49,50]。

表3:COCO验证集上的设计选择消融。结果显示在COCO AP中,时间以毫秒为单位。
边界框大小权重 我们分析了我们的方法对损失权重 λ s i z e λ_{size} λsize的敏感性。表3b显示0.1给出了良好的结果。对于较大的值,由于从0到输出大小w/R或h/R(而不是从0到1)的损失规模,AP显著退化。但是,对于较低的权重,该值不会显著降低。
训练计划 默认情况下,我们训练140个时期的关键点估计网络,在90个时期时学习率下降。如果我们在降低学习率之前将训练时间增加一倍,则性能将进一步提高1.1AP(表3d),代价是更长的训练计划。为了节省计算资源(和polar bears),我们在消融实验中使用了140个时期,但与其他方法相比,DLA坚持使用230个时期。
最后,我们通过回归到多个目标大小,尝试了CenterNet的多个“锚点”版本。实验没有取得任何成功。参见补充。
6.2 3D 检测
我们在KITTI数据集[17]上进行了3D边界框估计实验,该数据集包含了驾驶场景中车辆的仔细注释的3D边界框。KITTI包含7841张训练图像,我们遵循文献[10,54]中的标准训练和验证划分。评估指标是在IOU阈值为0.5的情况下,汽车在11次召回(0.0至1.0,增量为0.1)时的平均精度,如目标检测[14]。我们基于2D边界框(AP)、方向(AOP)和鸟瞰图边界框(BEV AP)来评估IOU。我们将原始图像分辨率和pad保持为1280×384,用于训练和测试。训练在70个时期收敛,学习率分别在45和60个时期下降。我们使用DLA-34主干,并将深度、方向和尺寸的损失权重设置为1。所有其他超参数与检测实验相同。
由于召回阈值的数量非常少,验证AP的波动幅度高达10%。因此,我们训练了5个模型,并报告了具有标准偏差的平均值。
我们比较了基于slow-RCNN的Deep3DBox[38]和基于Faster-RCNN的方法Mono3D[9]的具体验证集划分。如表4所示,我们的方法在AP和AOS中的表现与同行不相上下,在BEV中表现稍好。我们的CenterNet比这两种方法快两个数量级。
6.3 姿态估计
最后,我们评估了CenterNet在MS COCO数据集中的人体姿态估计[34]。我们评估关键点AP,它类似于边界框AP,但用目标关键点相似性替换了边界框IoU。我们在COCO测试中与其他方法进行了测试和比较。
我们用DLA-34和Hourglass-104进行了实验,它们都是从中心点检测进行微调的。DLA-34在320个时期中收敛(在8GPU上约3天),Hourglass-104在150个时期(在5GPU上8天)中收敛。所有附加损耗权重均设置为1。所有其他超参数与目标检测相同。
结果如表5所示。对关键点的直接回归表现合理,但不是最先进的。它在高IoU统治方式中尤其挣扎。将我们的输出投影到最接近的关节检测可以改善整个结果,并与最先进的多人姿势估计器相比具有竞争力[4,21,39,41]。这验证了CenterNet是通用的,易于适应新任务。
图5显示了所有任务的定性示例。

表4:KITTI评估。我们展示了不同验证集划分上的2D边界框AP、平均方位得分(AOS)和鸟瞰图(BEV)AP。越高越好。

图5:定性结果。所有图像都是按主题选取的,而不考虑我们的算法性能。第一行:COCO验证集上的目标检测。第二行和第三行:基于COCO验证集的人体姿态估计。对于每一对,我们显示了中心偏移回归(左)和热图匹配(右)的结果。第四行和第五行:KITTI验证集的3D边界框估计。我们展示了投影的边界框(左)和鸟瞰图(右)。真值检测显示在红色实心框中。中心热图和3D框显示为覆盖在原始图像上。

表5:COCO测试的关键点检测-reg/-jd分别用于直接中心向外偏移回归和匹配回归到最接近的关节检测。结果显示在COCO关键点AP中。越高越好。
7. 结论
总之,我们为目标提供了一种新的表示形式:作为点。我们的CenterNet目标检测器建立在成功的关键点估计网络上,找到目标中心,并回归到它们的大小。该算法简单、快速、准确、端到端可微,无需任何NMS后处理。这个想法是通用的,除了简单的二维检测之外,还有广泛的应用。CenterNet可以在一次前进过程中估计一系列额外的目标属性,如姿态、3D方向、深度和范围。我们的初步实验令人鼓舞,并为实时目标识别和相关任务开辟了新的方向。
References
[1] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. Lawrence Zitnick, and D. Parikh. Vqa: Visual question answering. In ICCV, 2015.
[2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Soft-nmsimproving object detection with one line of code. In ICCV, 2017.
[3] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. In arXiv preprint arXiv:1812.08008, 2018.
[4] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Real time multi-person 2d pose estimation using part affinity fields. In CVPR, 2017.
[5] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017.
[6] F. Chabot, M. Chaouch, J. Rabarisoa, C. Teuliere, and T. Chateau. Deep manta: A coarse-to-fine manytask network for joint 2d and 3d vehicle analysis from monocular image. In CVPR, 2017.
[7] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2018.
[8] X. Chen and A. Gupta. An implementation of faster rcnn with study for region sampling. arXiv preprint arXiv:1702.02138, 2017.
[9] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. In CVPR, 2016.
[10] X. Chen, K. Kundu, Y. Zhu, A. G. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In NIPS, 2015.
[11] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. In NIPS, 2016.
[12] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017.
[13] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014.
[14] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results.
[15] H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu. RMPE: Regional multi-person pose estimation. In ICCV, 2017.
[16] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. Dssd: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659, 2017.
[17] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In CVPR, 2012.
[18] R. Girshick. Fast r-cnn. In ICCV, 2015.
[19] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[20] P. Goyal, P. Doll´ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
[21] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In ICCV, 2017.
[22] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[23] J. H. Hosang, R. Benenson, and B. Schiele. Learning non-maximum suppression. In CVPR, 2017.
[24] H.-N. Hu, Q.-Z. Cai, D. Wang, J. Lin, M. Sun, P. Kr¨ahenb¨uhl, T. Darrell, and F. Yu. Joint monocular 3d vehicle detection and tracking. arXiv preprint arXiv:1811.10742, 2018.
[25] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017.
[26] B. Jiang, R. Luo, J. Mao, T. Xiao, and Y. Jiang. Acquisition of localization confidence for accurate object detection. In ECCV, 2018.
[27] Z. Kalal, K. Mikolajczyk, and J. Matas. Trackinglearning-detection. TPAMI, 2012.
[28] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. ICLR, 2014.
[29] A. Kundu, Y. Li, and J. M. Rehg. 3d-rcnn: Instance-level 3d object reconstruction via render-and-compare. In CVPR, 2018.
[30] H. Law and J. Deng. Cornernet: Detecting objects as paired keypoints. In ECCV, 2018.
[31] Y. Li, Y. Chen, N. Wang, and Z. Zhang. Scale-aware trident networks for object detection. arXiv preprint arXiv:1901.01892, 2019.
[32] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017.
[33] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. ICCV, 2017.
[34] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[35] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In CVPR, 2018.
[36] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In ECCV, 2016.
[37] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[38] A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka. 3d bounding box estimation using deep learning and geometry. In CVPR, 2017.
[39] A. Newell, Z. Huang, and J. Deng. Associative embedding: End-to-end learning for joint detection and grouping. In NIPS, 2017.
[40] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, 2016.
[41] G. Papandreou, T. Zhu, L.-C. Chen, S. Gidaris, J. Tompson, and K. Murphy. Personlab: Person pose estimation and instance segmentation with a bottomup, part-based, geometric embedding model. ECCV, 2018.
[42] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy. Towards accurate multi-person pose estimation in the wild. In CVPR, 2017.
[43] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016.
[44] J. Redmon and A. Farhadi. Yolo9000: better, faster, stronger. CVPR, 2017.
[45] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[46] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[47] B. Singh and L. S. Davis. An analysis of scale invariance in object detection–snip. In CVPR, 2018.
[48] B. Singh, M. Najibi, and L. S. Davis. SNIPER: Efficient multi-scale training. NIPS, 2018.
[49] X. Sun, J. Shang, S. Liang, and Y. Wei. Compositional human pose regression. In ICCV, 2017.
[50] X. Sun, B. Xiao, F. Wei, S. Liang, and Y. Wei. Integral human pose regression. In ECCV, 2018.
[51] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. In CVPR, 2014.
[52] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
[53] D. Wang, C. Devin, Q.-Z. Cai, F. Yu, and T. Darrell. Deep object centric policies for autonomous driving. In ICRA, 2019.
[54] Y. Xiang, W. Choi, Y. Lin, and S. Savarese. Subcategory-aware convolutional neural networks for object proposals and detection. In WACV, 2017.
[55] B. Xiao, H. Wu, and Y. Wei. Simple baselines for human pose estimation and tracking. In ECCV, 2018.
[56] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.
[57] J. Xu, R. Zhao, F. Zhu, H. Wang, and W. Ouyang. Attention-aware compositional network for person re-identification. In CVPR, 2018.
[58] F. Yu, D. Wang, E. Shelhamer, and T. Darrell. Deep layer aggregation. In CVPR, 2018.
[59] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li. Single-shot refinement neural network for object detection. In CVPR, 2018.
[60] X. Zhou, A. Karpur, L. Luo, and Q. Huang. Starmap for category-agnostic keypoint and viewpoint estimation. In ECCV, 2018.
[61] X. Zhou, J. Zhuo, and P. Kr¨ahenb¨uhl. Bottom-up object detection by grouping extreme and center points. In CVPR, 2019.
[62] C. Zhu, Y. He, and M. Savvides. Feature selective anchor-free module for single-shot object detection. arXiv preprint arXiv:1903.00621, 2019.
[63] X. Zhu, H. Hu, S. Lin, and J. Dai. Deformable convnets v2: More deformable, better results. arXiv preprint arXiv:1811.11168, 2018.

图6:模型图。方框中的数字表示图像的步幅。(a):Hourglass Network[30]。我们在CornerNet[30]中按原样使用它。(b) :具有转置卷积的ResNet[55]。我们在每个上采样层之前添加一个3×3可变形卷积层[63]。具体来说,我们首先使用可变形卷积来改变通道,然后使用转置卷积来对特征图进行上采样(这两个步骤分别显示在32中→ 16.我们将这两个步骤一起显示为16的虚线箭头→ 8和8→ 4) 。(c) :用于语义分割的原始DLA-34[58]。(d) :我们修改的DLA-34。我们从底层添加了更多的跳跃连接,并将上采样阶段的每个卷积层升级为可变形卷积层。
附录A:模型体系结构
体系结构图见图6。
附录B:3D BBox估算细节
我们的网络输出深度为
D
^
∈
R
W
R
×
H
R
\hat{D}∈R^{\frac{W}{R}×\frac{H}{R}}
D^∈RRW×RH,三维维度为
Γ
^
∈
R
W
R
×
H
R
×
3
\hat{Γ}∈R^{\frac{W}{R}×\frac{H}{R}×3}
Γ^∈RRW×RH×3和方向编码为
A
^
∈
R
W
R
×
H
R
×
8
\hat{A}∈R^{\frac{W}{R}×\frac{H}{R}×8}
A^∈RRW×RH×8的图。对于每个目标实例
k
k
k,我们从真值中心点位置的三个输出映射中提取输出值:
d
^
k
∈
R
,
γ
^
k
∈
R
3
,
α
^
k
∈
R
8
\hat{d}_k∈R,\hat{γ}_k∈R^3,\hat{α}_k∈R^8
d^k∈R,γ^k∈R3,α^k∈R8。在将输出转换到绝对深度域后,用L1损失来训练深度:

其中
d
k
d_k
dk是真值绝对深度(以米为单位)。类似地,3D维度是用绝对度量中的L1损失来训练的:

其中
γ
k
γ_k
γk是目标的高度、宽度和长度,单位为米。
默认情况下,方向θ是单个标量。继Mousavian等人[24,38]之后,我们使用8标量编码来简化学习。8个标量被分为两组,每组用于一个角度仓。一个bin用于
B
1
=
[
−
7
π
6
,
π
6
]
B_1=[-\frac{7π}{6},\frac{π}{6}]
B1=[−67π,6π]中的角度,另一个用于
B
2
=
[
−
π
6
,
7
π
6
]
B_2=[-\frac{π}{6},\frac{7π}{6}]
B2=[−6π,67π]中的角度。因此,我们为每个bin有4个标量。在每个bin内,2个标量
b
i
∈
R
2
b_i∈R^2
bi∈R2用于softmax分类(如果方向落入该bin i)。其余2个标量
a
i
∈
R
2
a_i∈R^2
ai∈R2用于in-bin偏移(到bin中心
m
i
m_i
mi)的sin和cos值。即,
α
^
=
[
b
^
1
,
a
^
1
,
b
^
2
,
a
^
2
]
\hat{α} = [\hat{b}_1, \hat{a}_1, \hat{b}_2, \hat{a}_2]
α^=[b^1,a^1,b^2,a^2],使用softmax训练分类,使用L1损失训练角度值:

其中
c
i
=
1
(
θ
∈
B
i
)
c_i=1(θ∈B_i)
ci=1(θ∈Bi),
a
i
=
(
s
i
n
(
θ
−
m
i
)
,
c
o
s
(
θ
−
m
i
)
)
a_i=(sin(θ−m_i),cos(θ−m_i))
ai=(sin(θ−mi),cos(θ−mi))。
1
1
1 是指示器函数。预测的方向θ由8标量编码解码为

其中
j
j
j是具有较大分类得分的bin索引。
附录C:碰撞实验细节
我们分析了COCO训练集的注释,以显示碰撞情况发生的频率。COCO训练集(train 2017)包含N=118287个图像和M=86001个目标(其中MS=356340个小目标,MM=295163个中等目标,ML=208498个大目标),属于C=80个类别。设类别c的图像k的第
i
i
i个边界框为
b
b
(
k
c
i
)
=
(
x
1
(
k
c
i
)
,
y
1
(
k
c
i
)
,
x
2
(
k
c
i
)
,
y
2
(
k
c
i
)
)
bb^{(kci)}=(x^{(kci)}_1,y^{(kci)}_1,x^{(kci)}_2,y^{(kci)}_2)
bb(kci)=(x1(kci),y1(kci),x2(kci),y2(kci)),其在4×步幅之后的中心为
p
k
c
i
=
(
⌊
1
4
⋅
x
1
(
k
c
i
)
+
x
2
(
k
c
i
)
2
⌋
,
⌊
1
4
⋅
y
1
(
k
c
i
)
+
y
2
(
k
c
i
)
2
⌋
)
p^{kci}=(\lfloor\frac{1}{4}·\frac{x^{(kci)}_1+x^{(kci)}_2}{2}\rfloor,\lfloor\frac{1}{4}·\frac{y^{(kci)}_1+y^{(kci)}_2}{2}\rfloor)
pkci=(⌊41⋅2x1(kci)+x2(kci)⌋,⌊41⋅2y1(kci)+y2(kci)⌋)。设
n
(
k
c
)
n^{(kc)}
n(kc)是图像
k
k
k中类别
c
c
c的目标的数量。中心点碰撞的数量通过以下公式计算:

我们在数据集上得到
N
c
e
n
t
e
r
=
614
N_{center}=614
Ncenter=614。
类似地,我们通过以下公式计算基于IoU的碰撞

这给
N
I
o
U
@
0.7
=
715
N_{IoU@0.7}=715
NIoU@0.7=715和
N
I
o
U
@
0.5
=
5179
N_{IoU@0.5}=5179
NIoU@0.5=5179。
基于锚点的检测器中的遗漏目标 如果锚点的IoU大于0.5,则RetinaNet[33]会将锚点分配给真值边界框。在真值边界框未被任何IoU>0.5的锚覆盖的情况下,将为其分配IoU最大的锚。我们计算这种强制分配发生的频率。我们使用15个锚点(5个大小:32、64、128、256、512,3个纵横比:0.5、1、2,如RetinaNet[33]所示),步长S=16。对于每个图像,在将其较短边调整为800[33]后,我们将这些锚定在位置
{
(
S
/
2
+
i
×
S
,
S
/
2
+
j
×
S
)
}
\{(S/2+i×S,S/2+j×S)\}
{(S/2+i×S,S/2+j×S)},其中
i
∈
[
0
,
⌊
(
W
−
S
/
2
)
S
⌋
]
i∈[0,\lfloor\frac{(W−S/2)}{S}\rfloor]
i∈[0,⌊S(W−S/2)⌋]和
j
∈
[
0
,
⌊
(
H
−
S
/
2
)
S
⌋
]
j∈[0,\lfloor\frac{(H−S/2)}{S}\rfloor]
j∈[0,⌊S(H−S/2)⌋]。W,H是图像的宽度和高度(较小的一个等于800)。这就产生了一组锚
A
A
A。
∣
A
∣
=
15
×
⌊
(
W
−
S
/
2
)
S
+
1
⌋
×
⌊
(
H
−
S
/
2
)
S
+
1
⌋
|A|=15×\lfloor\frac{(W−S/2)}{S}+1\rfloor×\lfloor\frac{(H−S/2)}{S}+1\rfloor
∣A∣=15×⌊S(W−S/2)+1⌋×⌊S(H−S/2)+1⌋。我们通过以下公式计算强制分配的数量:

RenitaNet要求
N
a
n
c
h
o
r
=
170220
N_{anchor}=170220
Nanchor=170220强制分配:小目标为125831(占所有小目标的35.3%),中等目标为18505(占所有中等目标的6.3%),大目标为25884(占所有大目标的12.4%)。
附录D:PascalVOC实验
Pascal VOC[14]是一个流行的小目标检测数据集。我们对VOC 2007和VOC 2012训练集进行训练,并对VOC 2007测试集进行测试。它包含20个类别的16551个训练图像和4962个测试图像。评估度量是IOU阈值0.5时的平均精度(mAP)。
我们用我们改进的ResNet-18、ResNet-101和DLA-34(见主要论文第5节)在两种训练分辨率下进行实验:384×384和512×512。对于所有网络,我们训练了70个时期,学习率分别在45和60个时期下降了10倍。我们使用批量大小32和学习率1.25e-4,遵循线性学习率规则[20]。对于ResNet-101和DLA-34,一个GPU分别需要7小时/10小时以384×384进行训练。对于512×512,训练在两个GPU中花费相同的时间。翻转增强用于测试。所有其他超参数与COCO实验相同。我们不使用Hourglass-104[30],因为当从头开始训练时,它无法在合理的时间(2天)内收敛。

表6:Pascal VOC 2007测试的实验结果。结果如表所示mAP@0.5。翻转测试用于CenterNet。其他方法的FPS是从原始出版物中复制的。

表7:COCO验证集的误差分析。我们显示了在用其真值替换每个网络预测后的COCO AP(%)。
结果如表6所示。我们最好的CenterNet-DLA模型与顶级方法相比具有竞争力,并保持实时速度。
附录E:误差分析
我们通过用其真值替换每个输出头来执行误差分析。对于中心点热图,我们使用渲染的高斯真值热图。对于边界框大小,我们对每个检测使用最接近的真值大小。
表7中的结果表明,改进两个尺寸图会带来适度的性能增益,而中心图的增益要大得多。如果仅关键点偏移没有被预测,则最大AP达到83.1。由于高斯热图渲染中的离散化和估计误差,整个真值管道遗漏了约0.5%的目标。

![[进阶]Java:线程概述、线程创建方式](https://img-blog.csdnimg.cn/e6dce84128e44b4cbb69d2d4687f3b4b.png)


![[进阶]Java:文件字节输出流、文件拷贝、资源释放](https://img-blog.csdnimg.cn/bcd54b185e91421198b7c0b436c1805d.png)