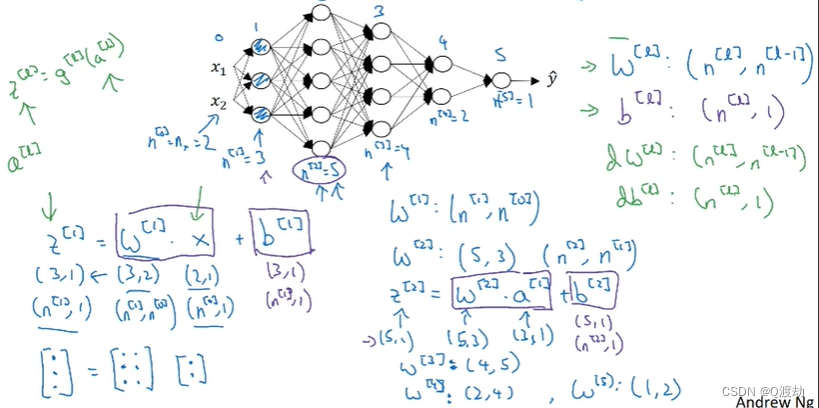
深层神经网络
1、深层网络中的前向传播
一个训练样本 x
前向传播
第一层需要计算
𝑧 [1] = 𝑤[1]𝑥 + 𝑏 [1],𝑎 [1] = 𝑔 [1] (𝑧 [1] )(𝑥可以看做
𝑎
[0]
)
第二层需要计算𝑧 [2] = 𝑤[2]𝑎
[1] + 𝑏 [2],𝑎 [2] = 𝑔 [2] (𝑧 [2] )
以此类推,
第四层为
𝑧
[4]
= 𝑤
[4]
𝑎
[3]
+ 𝑏
[4]
,𝑎 [4] = 𝑔 [4] (𝑧 [4] ) 前向传播可以归纳为多次迭代𝑧 [𝑙] = 𝑤[𝑙]𝑎 [𝑙−1] + 𝑏 [𝑙]
,
𝑎
[𝑙]
= 𝑔
[𝑙]
(𝑧
[𝑙]
)
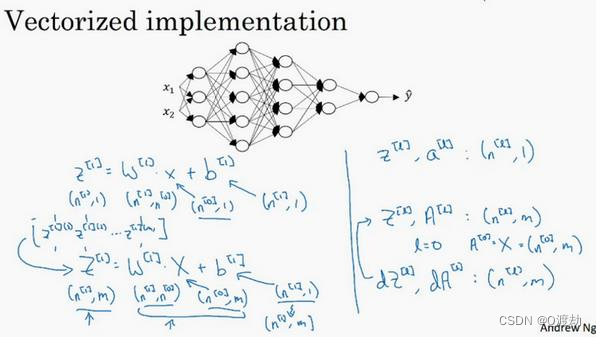
向量化实现过程可以写成: 𝑍 [𝑙] = 𝑊[𝑙]𝑎 [𝑙−1] + 𝑏 [𝑙],𝐴 [𝑙] = 𝑔[𝑙] (𝑍[𝑙] ) (𝐴 [0] = 𝑋)这里只能用一个显式 for 循环,𝑙从1到𝐿,然后一层接着一层去计算核对矩阵中的维数2、核对矩阵中的维数
检查矩阵的维度方法:
𝑤的维度是(下一层的维数,前一层的维数),即𝑤[𝑙]
: (
𝑛
[𝑙]
,
𝑛
[𝑙−1]
)
; 𝑏的维度是(下一层的维数,1),即
: 𝑏 [𝑙] : (𝑛 [𝑙] , 1); 𝑧 [𝑙] ,𝑎 [𝑙] : (𝑛 [𝑙] , 1); 𝑑𝑤[𝑙]和𝑤[𝑙]维度相同,𝑑𝑏[𝑙]
和
𝑏
[𝑙]
维度相同,且
𝑤
和
𝑏
向量化维度不变,但
𝑧
,
𝑎
以及𝑥的维 度会向量化后发生变化。
向量化后:
𝑍
[𝑙]
可以看成由每一个单独的𝑍 [𝑙]叠加而得到,𝑍 [𝑙] = (𝑧
[𝑙][1]
, 𝑧 [𝑙][2], 𝑧
[𝑙][3]
, …
, 𝑧
[𝑙][𝑚]
)
, 𝑚为训练集大小,所以𝑍 [𝑙]的维度不再是(𝑛 [𝑙]
, 1),而是(𝑛 [𝑙] , 𝑚)。 𝐴 [𝑙]:
(𝑛
[𝑙]
, 𝑚)
,
𝐴 [0] = 𝑋 = (𝑛 [𝑙] , 𝑚)
3、使用前向、后向传播函数搭建深层神经网络
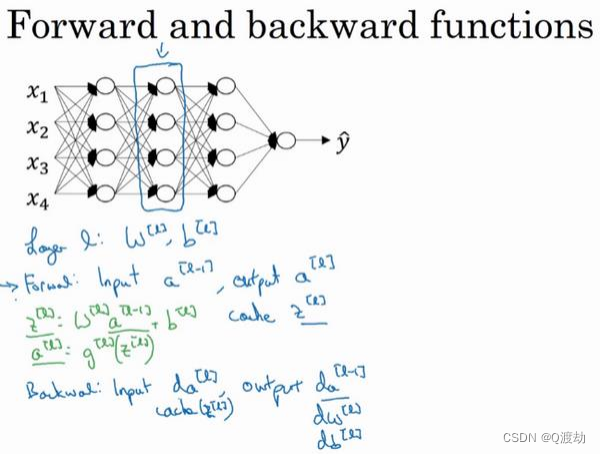
建一个深度神经网络
在第
𝑙
层你有参数𝑊[𝑙]和𝑏 [𝑙],正向传播里有输入的激活函数,输入是前一层𝑎 [𝑙−1],输是𝑎 [𝑙], 我们之前讲过𝑧 [𝑙]
= 𝑊[𝑙]𝑎 [𝑙−1] + 𝑏 [𝑙]
,
𝑎
[𝑙]
= 𝑔
[𝑙] (𝑧
[𝑙]
)
,那么这就是你如何从入𝑎
[𝑙−1]走到输出的𝑎 [𝑙]
。之后你就可以把𝑧 [𝑙]的值缓存起来,我在这里也会把这包括在缓存中,因为缓存的 𝑧 [𝑖]
对以后的正向反向传播的步骤非常有用
然后是反向步骤或者说反向传播步骤,同样也是第𝑙层的计算,你会需要实现一个函数输入为𝑑𝑎
[𝑙]
,输出
𝑑𝑎
[𝑙−1]的函数。一个小细节需要注意,输入在这里其实是𝑑𝑎 [𝑙]以及所缓存的𝑧 [𝑙]值,之前计算好的𝑧 [𝑙]值,除了输出
𝑑𝑎
[𝑙−1]
的值以外,也需要输出你需要的梯度
𝑑𝑊[𝑙]和 𝑑𝑏 [𝑙],这是为了实现梯度下降学习
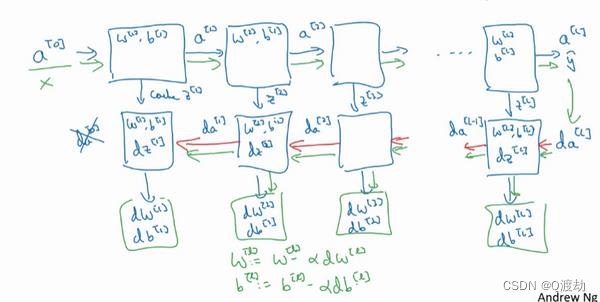
把输入特征𝑎 [0],放入第一层并计算第一层的激活函数,用𝑎 [1]表示,你需要𝑊[1]和𝑏 [1]
来计算,之后也缓存
𝑧
[𝑙]值。之后喂到第二层,第二层里,需要用到𝑊[2]和𝑏 [2],你会需要计算第二层的激活函数𝑎 [2]。后面几层以此类推,直到最后你算出了𝑎 [𝐿],第𝐿层的最终输出值 𝑦^。在这些过程里我们缓存了所有的𝑧值,这就是正向传播的步骤
把
𝑑𝑎 [𝐿]的值放在这里,然后这个方块会给我们𝑑𝑎[𝐿−1]的值,以此类推,直到我们得
𝑑𝑎
[2] 和𝑑𝑎[1],你还可以计算多一个输出值,就是𝑑𝑎[0]
,但这其实是你的输入特征的导数,并不重要,起码对于训练监督学习的权重不算重要,你可以止步于此。反向传播步骤中也会输出𝑑𝑊[𝑙]
和
𝑑𝑏
[𝑙]
,这会输出
𝑑𝑊
[3]
和
𝑑𝑏
[3]
等等
神经网络的一步训练包含了,从
𝑎 [0]开始,也就是 𝑥 然后经过一系列正向传播计算得到 𝑦^,之后再用输出值计算这个(第二行最后方块),再实现反向传播。现在你就有所有的导数项了,𝑊也会在每一层被更新为
𝑊 = 𝑊 − 𝛼𝑑𝑊,
𝑏也一样,𝑏 = 𝑏 − 𝛼𝑑𝑏,反向传播就都计算完毕,我们有所有的导数值,那么这是神经网络一个梯度下降循环
其中 反向传播中总是在循环进行da = dL/da,然后使用dz = dl/da*da/dz 求 dz(在 da/dz的求导中会使用到激活函数求导),最后使用 z 对 参数 w 和 b 求导进行梯度下降
4、参数和超参数
深度神经网络起很好的效果,还需要规划好参数以及超参数
参数:神经网络中的参数是指权重和偏置,它们是神经网络中可训练的部分,需要通过训练来学习得到。在神经网络的每一层中,都有一组权重和一个偏置。权重用于将输入信号进行线性变换,偏置用于调整变换后的数据分布,使其更符合任务要求。通过不断调整这些参数的值,神经网络可以逐渐逼近最优解。
超参数:超参数是指神经网络中的一些非训练参数,需要手动指定并根据经验或者调参等方法进行优化。比如神经网络中的学习率、正则化系数、网络层数、隐藏层神经元数量等都是超参数。超参数的选择可以直接影响神经网络的性能和泛化能力。
比如算法中的
learning rate 𝑎(学习率)、iterations (梯度下降法循环的数量)、𝐿(隐藏
层数目)、
𝑛
[𝑙]
(隐藏层单元数目)、
choice of activation function (激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数𝑊和𝑏的值,所以它们被称作超参数
参数的作用:神经网络中的参数是模型的核心部分,它们的优化可以让神经网络更好地拟合数据,从而提高模型的准确率。
超参数的作用:超参数的选择可以影响模型的训练效率、泛化能力、网络的容量和复杂度等方面,使得模型更加适合特定的任务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/661434.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!



![[进阶]Java:对象序列化、反序列化](https://img-blog.csdnimg.cn/6b812d83c89148f88fb0ef387a9d74d8.png)