PyTorch 全连接自编码网络的无监督学习
文章目录
- PyTorch 全连接自编码网络的无监督学习
- 1. 数据去噪
- 1.1 计算库和数据准备工作
- 1.2 构建自编码网络
- 1.3 调用主函数
- 1.4 可视化
- 2. 数据的重建与降维
- 2.1 计算模块和数据的准备
- 2.2 自编码网络数据准备
- 2.3 自编码网络的构建
- 2.4 自编码网络的训练
- 2.5 自编码网络的数据重建
- 2.6 自编码网络的编码特征可视化
深度学习网络用于无监督学习是通过一种称为 自编码(Auto-Encoder, AE)的网络结构实现的。自编码神经网络是一种以重构输入信号为目标的神经网络,它是无监督学习领域中的一类网络,可以自动从无表注的数据中学习特征。
自编码由3个网络层:输入层、隐藏层和输出层。其中输入层的样本也会充当输出层的角色,即这个神经网络就是一个尽可能复线输入层信号的神经网络,具体结构如下

1. 数据去噪
1.1 计算库和数据准备工作
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
SEED = 2617
N = 500
SIG = 0.1
X, _ = make_moons(n_samples=N, noise=SIG, random_state=SEED)
plt.scatter(X[:,0],X[:,1])
plt.axis('equal');
XT = torch.tensor(X, dtype=torch.float32)
1.2 构建自编码网络
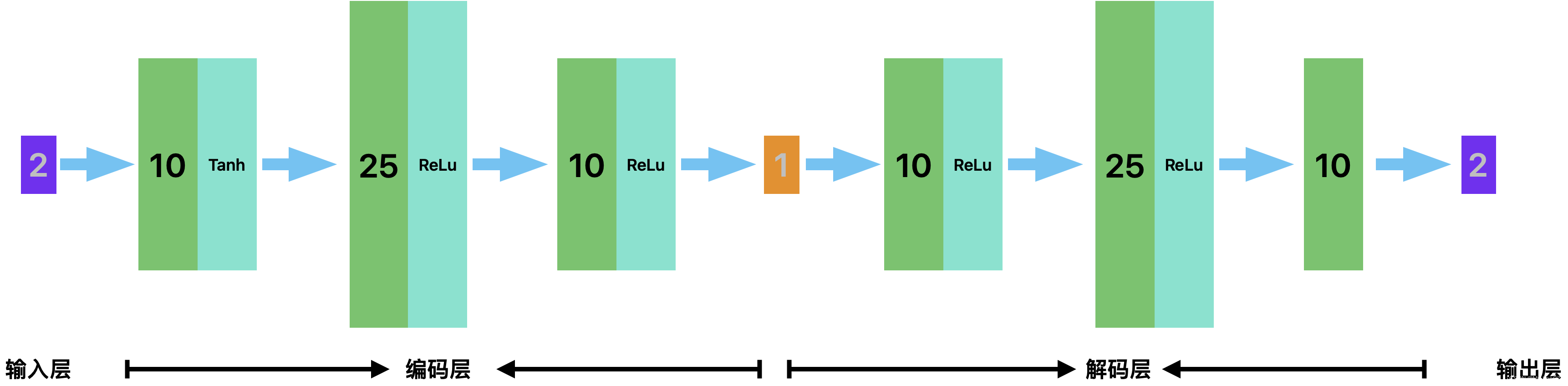
class NetworkAE(nn.Module):
def __init__(self, d_in, d_enc, d1, d2):
super().__init__()
# YOUR CODE HERE
self.encoder=nn.Sequential(
nn.Linear(d_in,d1),
nn.Tanh(),
nn.Linear(d1,d2),
nn.ReLU(),
nn.Linear(d2,d1),
nn.ReLU(),
nn.Linear(d1,d_enc)
)
self.decoder = nn.Sequential(
nn.Linear(d_enc, d1),
nn.ReLU(),
nn.Linear(d1, d2),
nn.ReLU(),
nn.Linear(d2, d1),
nn.Tanh(),
nn.Linear(d1, d_in)
)
#raise NotImplementedError()
def forward(self, x):
# YOUR CODE HERE
enc = self.encoder(x)
x = self.decoder(enc)
return x
训练网络
def train_nn(NN, X, learning_rate, max_iter, print_iter):
# YOUR CODE HERE
loss_func = nn.MSELoss(reduction='sum') # loss function,此函数默认均值对结果影响非常大,暂时不知道为什么
optimizer = torch.optim.SGD(NN.parameters(), lr=learning_rate)
for epoch in range(max_iter):
# ===================forward=====================
output = NN(X)
loss = loss_func(output, X)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ===================log========================
if epoch % print_iter == 0:
print('epoch [{}/{}], loss:{:.4f}'.format(epoch + 1, max_iter, loss.item()))
1.3 调用主函数
learning_rate = 5e-4
max_iter = 10000
d1 = 10
d2 = 25
netenc = NetworkAE(2, 1,d1,d2)
train_nn(netenc, XT, learning_rate, max_iter,1000)
X_NET = netenc(XT).detach().numpy()
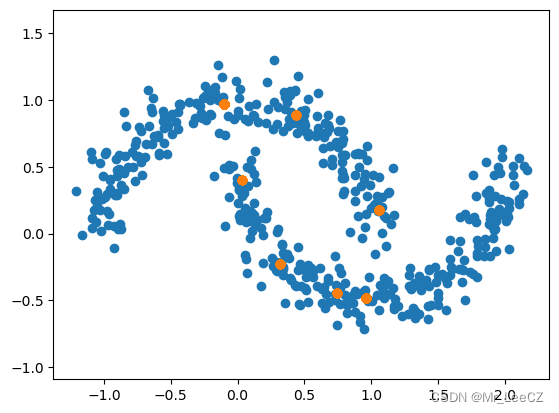
1.4 可视化
plt.scatter(X[:,0], X[:,1])
plt.scatter(X_NET[:,0], X_NET[:,1])
plt.axis('equal');
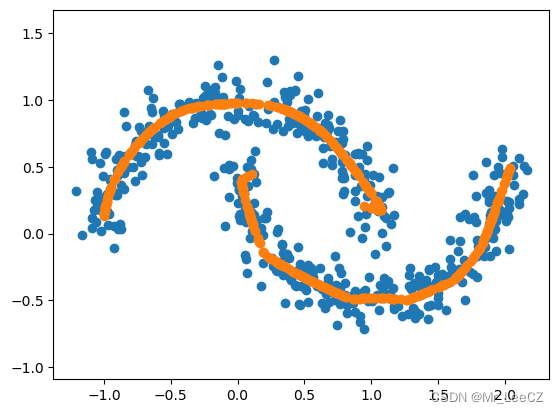
for i in range(1000):
X_NET = torch.tensor(X_NET, dtype=torch.float32)
X_NET = netenc(X_NET).detach().numpy()
plt.scatter(X[:,0], X[:,1])
plt.scatter(X_NET[:,0], X_NET[:,1])
plt.axis('equal');
2. 数据的重建与降维
2.1 计算模块和数据的准备
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 三维数据可视化
import hiddenlayer as hl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as Data
import torch.optim as optim
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import make_grid
# 模型加载选择GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device('cpu')
print(device)
print(torch.cuda.device_count())
print(torch.cuda.get_device_name(0))
cuda
1
NVIDIA GeForce RTX 2080 SUPER
2.2 自编码网络数据准备
# 使用手写体数据,准备训练数据集
train_data = MNIST(
root = './data/MNIST',
train = True, # 只使用训练数据集
transform = transforms.ToTensor(),
download = False
)
# 将图像数据转为向量数据
train_data_x = train_data.data.type(torch.FloatTensor) / 255.0
train_data_x = train_data_x.reshape(train_data_x.shape[0], -1)
train_data_y = train_data.targets
# 定义一个数据加载器
train_loader = Data.DataLoader(
dataset = train_data_x,
batch_size = 64,
shuffle = True,
num_workers = 2 # Windows需要设置为0
)
# 对测试数据集导入
test_data = MNIST(
root = './data/MNIST',
train = False, # 不使用训练数据集
transform = transforms.ToTensor(),
download = False
)
# 为测试数据添加一个通道维度,获取测试数据的X和Y
test_data_x = test_data.data.type(torch.FloatTensor) / 255.0
test_data_x = test_data_x.reshape(test_data_x.shape[0], -1)
test_data_y = test_data.targets
print('训练数据集:', train_data_x.shape)
print('测试数据集:', test_data_x.shape)
数据的显示
# 可视化训练数据集中一个batch的图像内容,以观察手写体图像的情况,程序如下:
for step, b_x in enumerate(train_loader):
if step > 0:
break
# 可视化一个batch
# make_grid将[batch, channel, height, width]形式的batch图像转为图像矩阵,便于对多张图像的可视化
im = make_grid(b_x.reshape((-1, 1, 28, 28)))
im = im.data.numpy().transpose((1, 2, 0))
plt.figure()
plt.imshow(im)
plt.axis('off')
plt.show()

2.3 自编码网络的构建
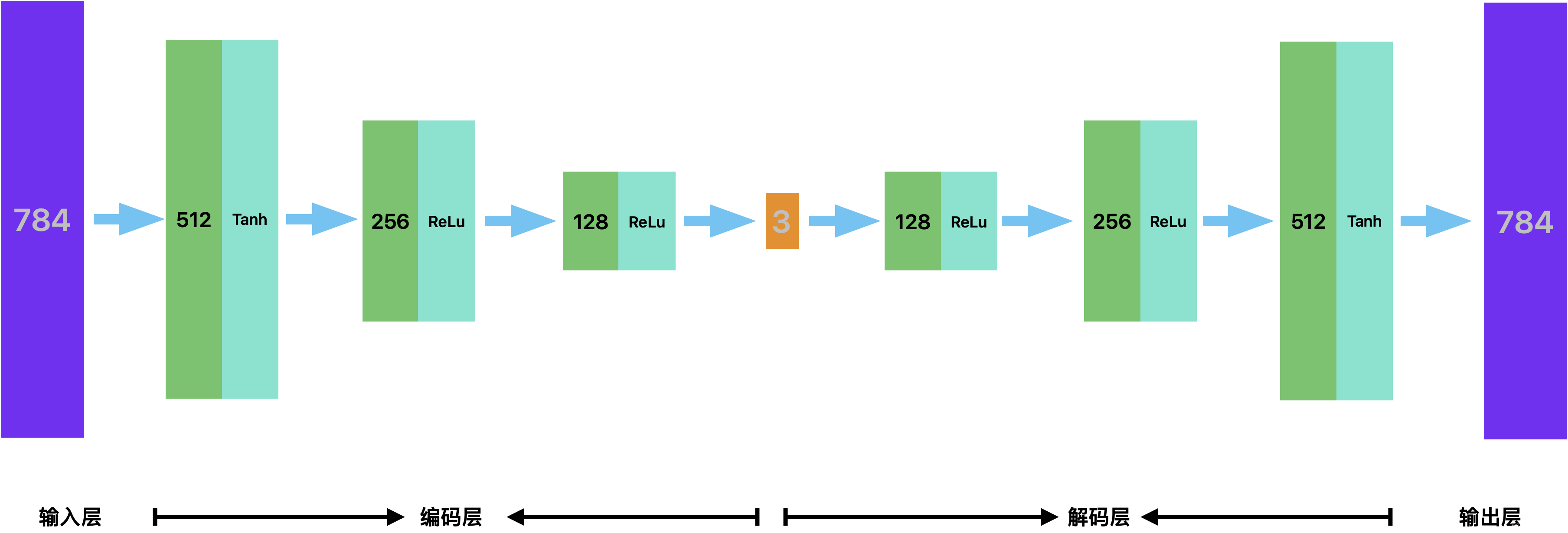
class EnDecoder(nn.Module):
def __init__(self):
super(EnDecoder, self).__init__()
# 定义Encoder
self.Encoder = nn.Sequential(
nn.Linear(784, 512),
nn.Tanh(),
nn.Linear(512, 256),
nn.Tanh(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 3),
nn.Tanh(),
)
# 定义Decoder
self.Decoder = nn.Sequential(
nn.Linear(3, 128),
nn.Tanh(),
nn.Linear(128, 256),
nn.Tanh(),
nn.Linear(256, 512),
nn.Tanh(),
nn.Linear(512, 784),
)
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return encoder, decoder
# 定义自编码网络edmodel
myedmodel = EnDecoder().to(device)
from torchsummary import summary
summary(myedmodel, input_size=(1, 784))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1, 512] 401,920
Tanh-2 [-1, 1, 512] 0
Linear-3 [-1, 1, 256] 131,328
Tanh-4 [-1, 1, 256] 0
Linear-5 [-1, 1, 128] 32,896
Tanh-6 [-1, 1, 128] 0
Linear-7 [-1, 1, 3] 387
Tanh-8 [-1, 1, 3] 0
Linear-9 [-1, 1, 128] 512
Tanh-10 [-1, 1, 128] 0
Linear-11 [-1, 1, 256] 33,024
Tanh-12 [-1, 1, 256] 0
Linear-13 [-1, 1, 512] 131,584
Tanh-14 [-1, 1, 512] 0
Linear-15 [-1, 1, 784] 402,192
Sigmoid-16 [-1, 1, 784] 0
================================================================
Total params: 1,133,843
Trainable params: 1,133,843
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.04
Params size (MB): 4.33
Estimated Total Size (MB): 4.37
----------------------------------------------------------------
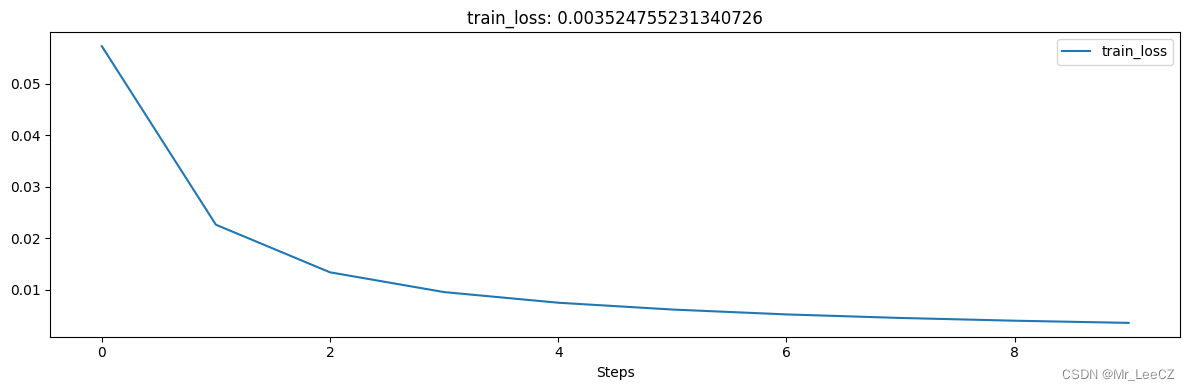
2.4 自编码网络的训练
optimizer = optim.Adam(myedmodel.parameters(), lr = 0.003)
loss_func = nn.MSELoss().to(device)
# 记录训练过程的指标
historyl = hl.History()
# 使用Canvas进行可视化
canvasl = hl.Canvas()
train_num = 0
val_num = 0
# 对模型迭代训练
for epoch in range(10):
train_loss_epoch = 0
# 对训练数据的加载器进行迭代计算
for step, b_x in enumerate(train_loader):
# 使用每个batch进行训练模型
b_x = b_x.to(device)
_, output = myedmodel(b_x) # 前向传递输出
loss = loss_func(output, b_x) # 均方根误差
optimizer.zero_grad() # 每个迭代步的梯度初始化为0
loss.backward() # 损失的后向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss_epoch += loss.item() * b_x.size(0)
train_num = train_num + b_x.size(0)
# 计算一个epoch的损失
train_loss = train_loss_epoch / train_num
# 保存每个epoch上的输出loss
historyl.log(epoch, train_loss = train_loss)
# 可视网络训练的过程
with canvasl:
canvasl.draw_plot(historyl['train_loss'])
2.5 自编码网络的数据重建
# 预测测试集前100张图像的输出
myedmodel.eval()
_, test_decoder = myedmodel(test_data_x[0: 100, :].to(device))
# 可视化原来的图像
plt.figure(figsize = (6, 6))
for ii in range(test_decoder.shape[0]):
plt.subplot(10, 10, ii + 1)
im = test_data_x[ii, :]
im = im.cpu().data.numpy().reshape(28, 28)
plt.imshow(im, cmap = plt.cm.gray)
plt.axis('off')
plt.show()
# 可视化编码后的图像
plt.figure(figsize = (6, 6))
for ii in range(test_decoder.shape[0]):
plt.subplot(10, 10, ii + 1)
im = test_decoder[ii, :]
im = im.cpu().data.numpy().reshape(28, 28)
plt.imshow(im, cmap = plt.cm.gray)
plt.axis('off')
plt.show()


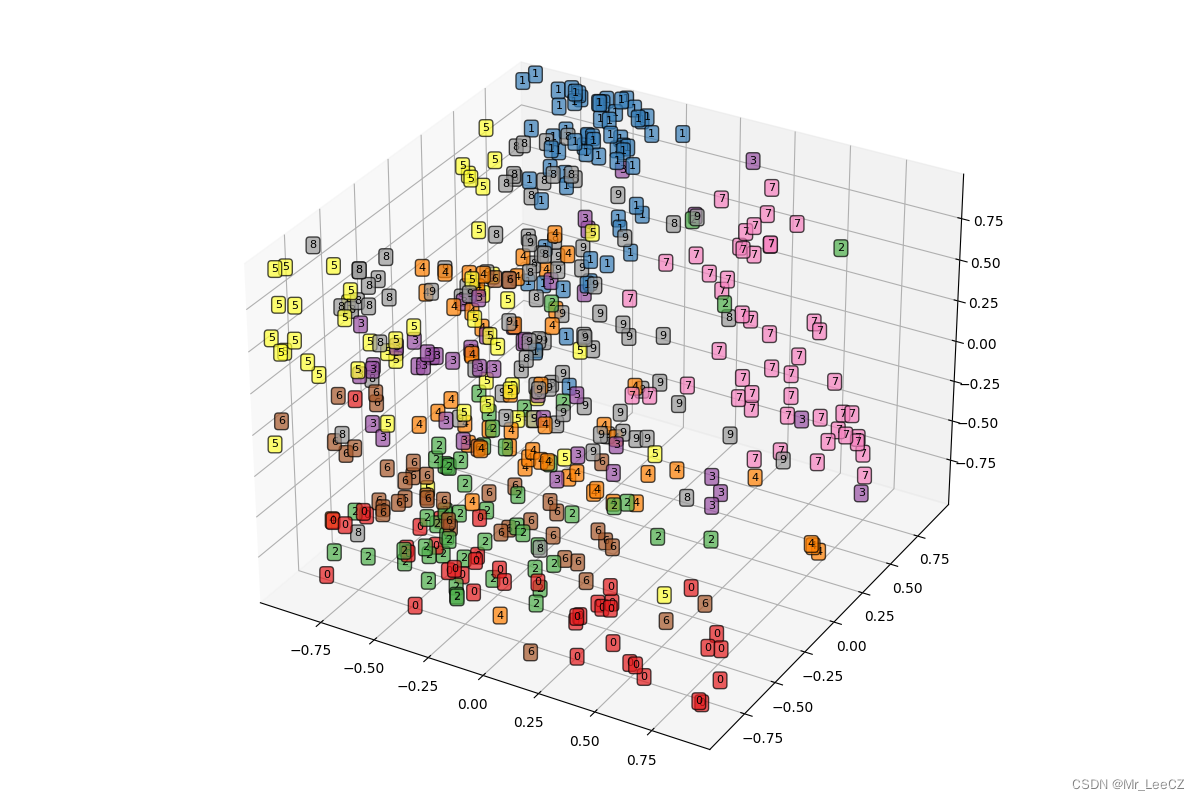
2.6 自编码网络的编码特征可视化
# 获取前500个样本的自编码后的特征,并对数据进行可视化
myedmodel.eval()
TEST_num = 500
test_encoder, _ = myedmodel(test_data_x[0: TEST_num, :].to(device))
print('test_encoder.shape:', test_encoder.shape)
%config InlineBackend.print_figure_kwargs = {'bbox_inches': None}
# 将3个维度的特征进行可视化
test_encoder_arr = test_encoder.cpu().data.numpy()
fig = plt.figure(figsize = (12, 8))
ax1 = Axes3D(fig)
X = test_encoder_arr[:, 0]
Y = test_encoder_arr[:, 1]
Z = test_encoder_arr[:, 2]
ax1.set_xlim([min(X), max(X)])
ax1.set_ylim([min(Y), max(Y)])
ax1.set_zlim([min(Z), max(Z)])
for ii in range(test_encoder.shape[0]):
text = test_data_y.data.numpy()[ii]
ax1.text(X[ii], Y[ii], Z[ii], str(text), fontsize = 8, bbox = dict(boxstyle = 'round', facecolor = plt.cm.Set1(text), alpha = 0.7))
plt.show()







![[INFO] [copilotIgnore] inactive,github copilot没反应怎么解决](https://img-blog.csdnimg.cn/ef5990c33cf04f49ac0fb76077bd762f.png)