文章目录
- 前言
- 一、程序的组成
- 二、未初始化和初始化变量保存地址
- 三、栈什么时候被创建
- 四、内存映射段
- 总结
前言
本篇文章我们来深入的理解一下理解程序的结构。
一、程序的组成
通常情况下,一个可执行程序由以下几个不同的段组成:
1.代码段 (Text Segment):
代码段通常被加载到只读内存区域中,并包含程序的指令和函数。在段加载完成后,代码段的内容不可更改。当程序开始执行时,指令将从代码段中加载并执行。
2.数据段 (Data Segment):
数据段通常存储了程序中的初始化数据,包括静态变量和可以修改的全局变量。数据段通常在可读写的内存区域中,并且在程序开始前就已经被初始化好了。
3.BSS段:
BSS 段通常存储了未初始化的全局变量和静态变量,它在执行前会被清零。这个段的名称来自Block Started by Symbol,这个名称来自汇编程序语言中的一种数据定义。
4..rodata 段
.rodata 段是可执行程序或共享库中的一个内存段(或区段),用于存储只读数据(read-only data)。rodata 是 “read-only data” 的缩写,表示该段中的数据是只读的,无法在运行时被修改。
.rodata 段主要包含以下类型的数据:
字符串常量:包括程序中使用的字符串文字,如错误消息、提示语等。这些字符串在程序运行期间不可修改。
全局常量:程序中定义的全局常量,如常量数组、常量结构体等。
格式化字符串:包括格式化输出函数(如printf)中使用的格式化字符串,这些字符串描述了输出的格式,因此必须保持不变。
5.堆 (Heap):
堆是程序在运行时动态分配内存的区域,由程序员手动管理和控制。堆在程序开始执行之前不存在,必须使用 malloc() 或者其他的内存分配函数来动态创建和释放。
65.栈 (Stack):
栈用于存储程序执行时的函数调用信息、局部变量和参数等信息。每当需要调用一个函数时,栈上就会生成一个新的栈帧,该函数所需要的信息都存储在这个栈帧中。当函数调用结束后,这个栈帧就会被弹出。
二、未初始化和初始化变量保存地址
在编译和链接的过程中,编译器和链接器对变量进行了不同的处理,导致未初始化变量和初始化变量在内存中保存的位置不同。
未初始化的全局变量或静态变量被存储在程序的 BSS 段(Block Started by Symbol)中。BSS 段在可执行文件中保留了足够的空间来容纳未初始化的静态变量。当程序加载到内存中时,操作系统会清零 BSS 段的内存区域,使得其中的变量都被自动初始化为零值(或 null 值)。因此,未初始化的全局变量和静态变量在内存中占据一片被清零的内存区域。
而初始化的全局变量或静态变量被存储在程序的 data 段中。data 段在可执行文件中保存了已经初始化的全局变量和静态变量的值。当程序加载到内存中时,操作系统会将 data 段中的数据复制到内存中相应的位置。因此,初始化的全局变量和静态变量在内存中占据的是已经被赋予初始值的内存区域。
需要注意的是,局部变量(即在函数内定义的变量)通常放在栈上,而不是 BSS 段或 data 段中。局部变量的生命周期与函数的执行周期相关,在每次函数调用时会被分配内存,并在函数返回时被释放。
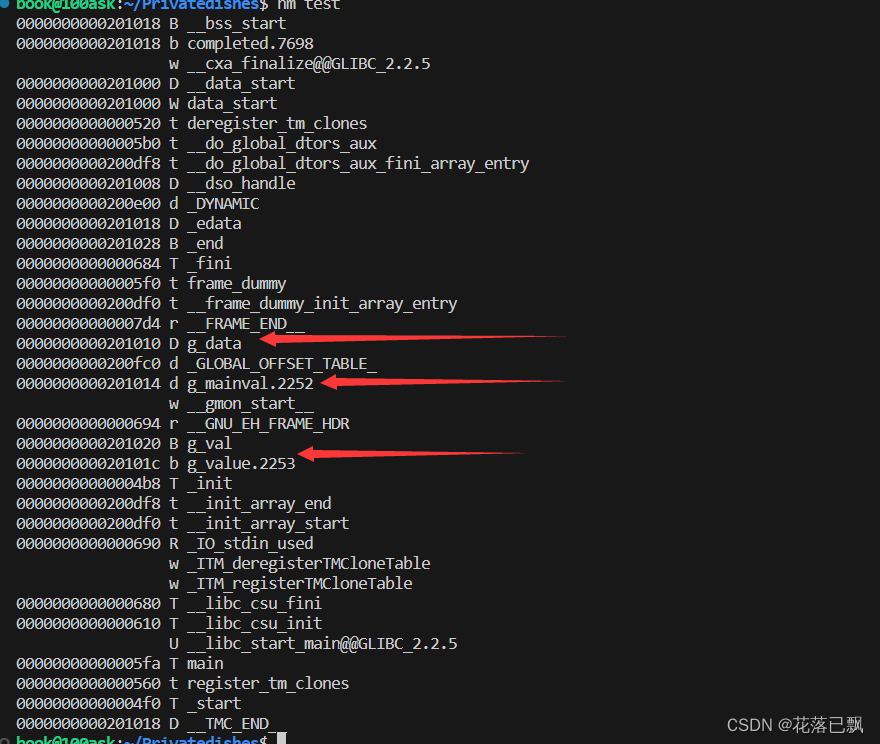
这里来进行一个实验:
#include <stdio.h>
int g_val;
int g_data = 1;
int main(void)
{
static int g_mainval = 1;
static int g_value;
int a;
return 0;
}
三、栈什么时候被创建
栈是在程序执行期间动态创建和管理的,它用于存储局部变量、函数调用信息、函数参数等。栈是一种后进先出(LIFO)的数据结构,其中的数据以栈帧的形式存储。
栈的创建和销毁是由程序的执行流控制的。当程序执行到一个函数调用时,会在栈上创建一个新的栈帧,用于存储函数的局部变量、参数和返回地址等信息。这个过程称为函数调用的栈帧入栈。当函数执行完毕或遇到返回语句时,相应的栈帧会被销毁,从而释放栈上的内存空间,这个过程称为栈帧出栈。
在上面的程序中我们定义了局部变量a,但是使用nm命令后并没有查看到这个变量具体是存放在哪里的,因为局部变量都是存储在栈中的,而栈是在程序运行后才被创建的,所以没有执行这个程序我们是无法观察到这个变量具体存放在哪里的。
四、内存映射段
内存映射是指将文件或设备中的数据映射到进程的内存空间,使得进程可以像访问内存一样访问这些数据。内存映射段是指将不同的文件或设备映射到进程的不同内存区域的段(区段)。
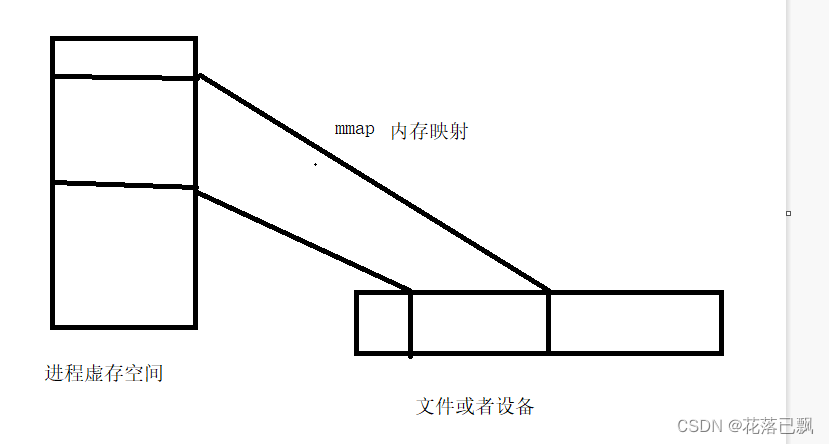
使用内存映射的方式创建内存映射段包括以下步骤:
打开文件或选择设备:首先,需要打开要映射到内存的文件或选择要映射的设备。这可以通过文件系统中的文件路径或设备的标识符来完成。
调用内存映射函数:操作系统提供了特定的系统调用或库函数来进行内存映射。这些函数的名称和具体调用方法会根据操作系统的不同而有所差异。
指定映射参数:在调用内存映射函数时,需要指定映射的相关参数,例如要映射的文件描述符、映射的起始偏移量和长度、访问权限等。
分配内存:操作系统会为内存映射段分配一段连续的虚拟内存空间,这段内存空间在进程的地址空间中保留一块空闲区域。
关联文件或设备:操作系统会将打开的文件或设备的数据与分配的虚拟内存空间进行关联,使得进程可以通过访问内存来读写文件或设备的数据。
访问和操作数据:通过指针或偏移量等方式,进程可以直接在所分配的内存空间中读取和写入数据。对内存的操作会直接反映到关联的文件或设备中。
解除映射和释放资源:在不再需要内存映射段时,可以调用相应的解除映射函数来解除关联,并释放分配的内存资源。
内存映射具有以下几个重要的用途和优势,使得其在编程和操作系统中得到广泛应用:
简化文件和设备的访问:通过内存映射,可以将文件和设备中的数据映射到进程的内存空间,从而使得对文件和设备的访问变得更加简单、方便和高效。进程可以通过直接读取和写入内存的方式来访问数据,而不必进行繁琐的文件读写和设备访问操作。
提高性能:内存映射可以减少系统调用的次数,从而降低了IO操作的开销。相比于传统的文件读取和写入操作,内存映射可以大幅度提升数据访问的速度和效率,尤其是对于大型文件的操作。
共享和通信:多个进程可以同时映射同一个文件,实现数据的共享和通信。这种共享内存的方式能够提供高效的进程间通信机制,是一种常见的实现并发和分布式系统的方式。
简化数据结构和算法:内存映射可以使得进程将复杂的数据结构和算法映射到内存中,从而简化了程序的设计和实现。例如,使用内存映射可以将一整个文件直接映射到内存中,然后通过指针操作和数据访问来实现高效的文件处理和搜索操作。
无需读取整个文件:使用内存映射时,可以选择只映射文件中的部分数据,而不是将整个文件都映射到内存中。这种方式在处理大型文件时非常有用,可以避免一次性读取整个文件导致内存不足的问题。
总之,内存映射提供了一种便捷和高效的方式来访问文件和设备中的数据,简化了编程任务并提升了系统性能。它被广泛应用于许多领域,如文件系统、数据库、网络编程、并发编程等。
总结
本篇文章就讲解到这里,掌握这些知识有助于大家深入了解程序的结构。







![[INFO] [copilotIgnore] inactive,github copilot没反应怎么解决](https://img-blog.csdnimg.cn/ef5990c33cf04f49ac0fb76077bd762f.png)