串
术语概念
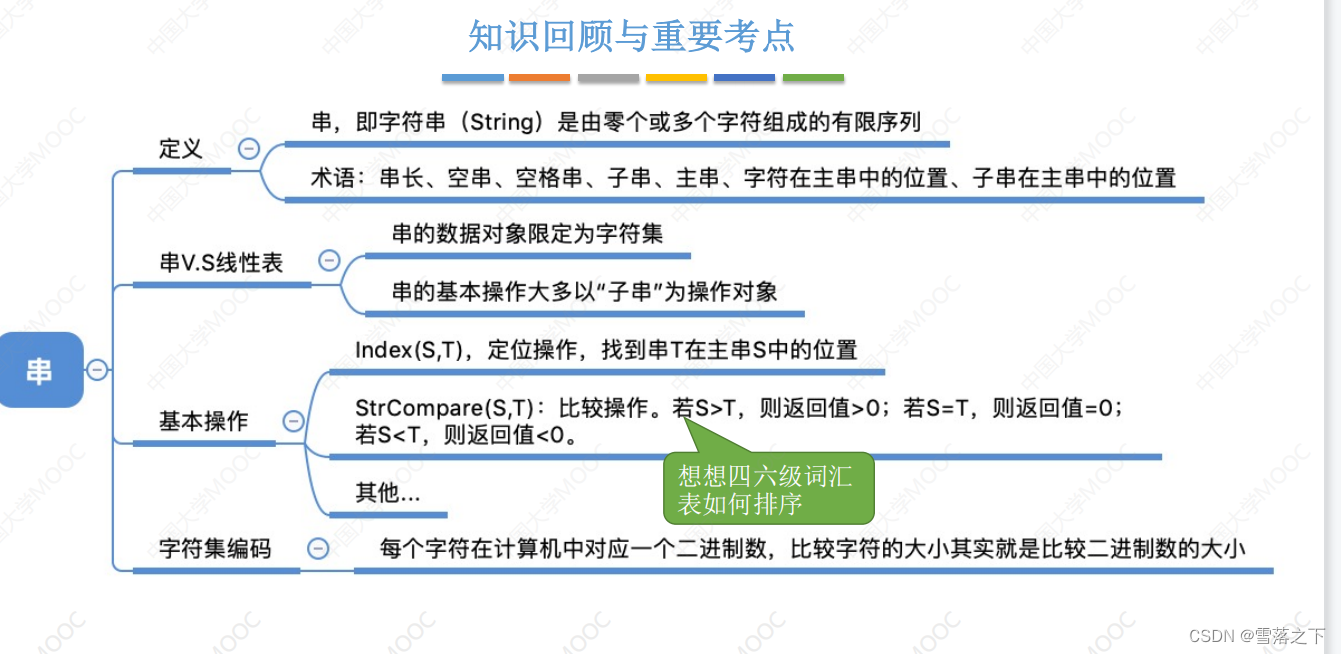
在数据结构中,串(String)是由零个或多个字符组成的有限序列。它是一种常见的数据类型,常用于表示文本、字符串和符号序列等信息。串可以包含任意字符,包括字母、数字、符号以及空格等。
主串(Main String)是指一个串中的完整序列,它可以包含一个或多个字串。主串是整个串的基础,在处理串的问题时,通常会对主串进行操作。
字串(Substring)是指主串中连续的一段字符序列。换句话说,字串是主串的一部分,它由主串中的一个或多个字符按照顺序组成。字串可以包含主串中的所有字符,也可以只包含其中的一部分。
串长(Length of a String)是指串中字符的数量,也就是串的长度。它表示了一个串中字符的个数,可以用来衡量串的大小。常用的方法是使用一个整数来表示串的长度。
在计算机科学中,对串的操作和处理是非常常见的,比如搜索、匹配、替换、排序等。理解主串、字串和串长的概念有助于进行字符串处理和相关算法的设计与实现。
存储结构
串的存储结构有多种方式,其中包括定长顺序存储、堆分配存储和块链存储。
- 定长顺序存储(Fixed-Length Sequential Storage):在定长顺序存储中,串的字符被连续地存储在一块连续的存储区域中,如数组。串的长度在创建时被确定,存储空间被分配给每个字符,且长度不可变。这种存储结构适用于已知长度的串,能够快速访问和操作,但可能会浪费存储空间。
对于定长顺序存储的示例,使用C语言的代码如下:
#include <stdio.h>
int main() {
char str[11] = "Hello World";
printf("The string is: %s\n", str);
return 0;
}
- 堆分配存储(Heap Allocation Storage):堆分配存储通过动态内存分配来存储串。在堆分配存储中,使用指针来引用字符序列,而不需要预先确定存储空间大小。这种存储结构适用于长度可变的串,可以根据需要动态分配和释放存储空间,但需要额外的内存管理开销。
实例:假设我们需要处理一个长度可变的串,用户输入的长度不确定。可以使用堆分配存储,通过动态内存分配来存储字符串。
#include <stdio.h>
#include <stdlib.h>
int main() {
int length;
printf("Enter the length of the string: ");
scanf("%d", &length);
// 动态分配存储空间
char* str = (char*)malloc((length + 1) * sizeof(char));
printf("Enter the string: ");
scanf("%s", str);
printf("The string is: %s\n", str);
// 释放内存
free(str);
return 0;
}
- 块链存储(Linked Storage):块链存储使用链表数据结构来表示串。每个节点包含一个字符和一个指向下一个节点的指针。块链存储可以动态地增加和删除字符,适用于频繁的插入和删除操作。然而,块链存储对于访问和搜索操作可能不如定长顺序存储和堆分配存储高效。
实例:假设我们要存储一个字符串"Hello World",可以使用块链存储,每个节点包含一个字符和一个指向下一个节点的指针。
#include <stdio.h>
#include <stdlib.h>
struct Node {
char data;
struct Node* next;
};
struct Node* create_linked_string() {
struct Node* node1 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node2 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node3 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node4 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node5 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node6 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node7 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node8 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node9 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node10 = (struct Node*)malloc(sizeof(struct Node));
struct Node* node11 = (struct Node*)malloc(sizeof(struct Node));
// 设置节点的数据
node1->data = 'H';
node2->data = 'e';
node3->data = 'l';
node4->data = 'l';
node5->data = 'o';
node6->data = ' ';
node7->data = 'W';
node8->data = 'o';
node9->data = 'r';
node10->data = 'l';
node11->data = 'd';
// 构建链表
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = node5;
node5->next = node6;
node6->next = node7;
node7->next = node8;
node8->next = node9;
node9->next = node10;
node10->next = node11;
node11->next = NULL;
return node1;
}
int main() {
// 创建块链存储的串
struct Node* head = create_linked_string();
// 遍历打印串
struct Node* current = head;
while (current != NULL) {
printf("%c", current->data);
current = current->next;
}
// 释放内存
current = head;
while (current != NULL) {
struct Node* temp = current;
current = current->next;
free(temp);
}
return 0;
}
在上述代码中,我们定义了一个结构体 Node,包含一个字符数据 data 和一个指向下一个节点的指针 next。然后,我们通过动态内存分配来创建每个节点,并设置节点的数据。接下来,我们使用指针将节点连接起来,形成一个链表。最后,我们遍历链表打印出字符序列,并释放动态分配的内存。
选择合适的存储结构取决于串的特性和操作需求。如果串的长度已知且固定,则定长顺序存储是一个简单且高效的选择。如果串的长度可变且需要频繁的插入和删除操作,则堆分配存储或块链存储可能更合适。
模式匹配算法

暴力匹配法
暴力匹配法(Brute Force Algorithm):
概念:暴力匹配法是一种简单直观的模式匹配算法。它的基本思想是从文本串的第一个字符开始,逐个与模式串的字符进行比较。如果字符相匹配,则继续比较下一个字符,如果不匹配,则将文本串的指针回溯到上一次比较的位置的下一个字符,再重新开始比较。
使用:暴力匹配法的实现相对简单,通过两层循环遍历文本串和模式串进行逐个字符的比较。
实例(C语言):
#include <stdio.h>
#include <string.h>
int bruteForce(char* text, char* pattern) {
int textLen = strlen(text);
int patternLen = strlen(pattern);
for (int i = 0; i <= textLen - patternLen; i++) {
int j;
for (j = 0; j < patternLen; j++) {
if (text[i + j] != pattern[j])
break;
}
if (j == patternLen)
return i; // 匹配成功,返回起始位置
}
return -1; // 匹配失败,返回-1
}
int main() {
char text[] = "ABCABABCDABABCABAB";
char pattern[] = "ABABCABAB";
int result = bruteForce(text, pattern);
if (result == -1)
printf("Pattern not found in the text\n");
else
printf("Pattern found at position: %d\n", result);
return 0;
}
KMP算法
概念:KMP算法是一种高效的模式匹配算法,它利用了模式串自身的信息来避免无效的比较。KMP算法通过构建一个部分匹配表(即next数组),用于记录模式串中每个位置的最长公共前缀后缀的长度,从而在匹配过程中跳过一些无需比较的字符。
使用:KMP算法的实现分为两个阶段,首先构建部分匹配表(next数组),然后利用该表进行匹配。
实例(C语言):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void buildNext(char* pattern, int* next) {
int len = strlen(pattern);
next[0] = -1;
int i = 0, j = -1;
while (i < len) {
if (j == -1 || pattern[i] == pattern[j]) {
i++;
j++;
next[i] = j;
} else {
j = next[j];
}
}
}
int kmp(char* text, char* pattern) {
int textLen = strlen(text);
int patternLen = strlen(pattern);
int* next = (int*)malloc((patternLen + 1) * sizeof(int));
buildNext(pattern, next);
int i = 0, j = 0;
while (i < textLen && j < patternLen) {
if (j == -1 || text[i] == pattern[j]) {
i++;
j++;
} else {
j = next[j];
}
}
free(next);
if (j == patternLen)
return i - j; // 匹配成功,返回起始位置
return -1; // 匹配失败,返回-1
}
int main() {
char text[] = "ABCABABCDABABCABAB";
char pattern[] = "ABABCABAB";
int result = kmp(text, pattern);
if (result == -1)
printf("Pattern not found in the text\n");
else
printf("Pattern found at position: %d\n", result);
return 0;
}
KMP算法的进一步改进—nextval数组
概念:nextval数组是对KMP算法的一种改进,它进一步减少了模式串与文本串的比较次数。nextval数组在构建过程中,根据模式串的特点,对部分匹配表的构建进行了优化。
使用:使用方法与KMP算法类似,只是在构建部分匹配表时,需要使用nextval数组的构建规则。
实例(C语言):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void buildNextval(char* pattern, int* nextval) {
int len = strlen(pattern);
nextval[0] = -1;
int i = 0, j = -1;
while (i < len) {
if (j == -1 || pattern[i] == pattern[j]) {
i++;
j++;
if (pattern[i] != pattern[j])
nextval[i] = j;
else
nextval[i] = nextval[j];
} else {
j = nextval[j];
}
}
}
int kmpWithNextval(char* text, char* pattern) {
int textLen = strlen(text);
int patternLen = strlen(pattern);
int* nextval = (int*)malloc((patternLen + 1) * sizeof(int));
buildNextval(pattern, nextval);
int i = 0, j = 0;
while (i < textLen && j < patternLen) {
if (j == -1 || text[i] == pattern[j]) {
i++;
j++;
} else {
j = nextval[j];
}
}
free(nextval);
if (j == patternLen)
return i - j; // 匹配成功,返回起始位置
return -1; // 匹配失败,返回-1
}
int main() {
char text[] = "ABCABABCDABABCABAB";
char pattern[] = "ABABCABAB";
int result = kmpWithNextval(text, pattern);
if (result == -1)
printf("Pattern not found in the text\n");
else
printf("Pattern found at position: %d\n", result);
return 0;
}