目录
一、实验拓扑
二、环境配置
(一)设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
1、在虚拟机node1上操作
2、在虚拟机node2上操作
3、测试node1与node2的通联性
三、 安装node1与node2节点的elasticsearch
(一)在虚拟机node1与node2分别安装
(二)修改配置文件
1、在虚拟机node1上操作
2、在虚拟机node2上操作
(三)启动elasticsearch服务(在虚拟机node1和node2上分别操作)
(四)查看节点信息
四、在虚拟机node1安装elasticsearch-head插件
(一)安装node
(二)拷贝命令
(三)安装elasticsearch-head
(四)修改elasticsearch配置文件
(五)启动elasticsearch-head
(六)访问
(七)测试
五、node1服务器安装logstash
(一)安装
(二)启动服务
(三)查看端口号
(四)测试1:标准输入与输出
(五)测试2: 使用rubydebug解码
(六)测试3:输出到elasticsearch
(七)查看结果:
六、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
(一)Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。
(二)在每个部分中,也可以指定多个访问方式。
(三)案例
1、通过logstash收集系统信息日志
2、重启日志服务
3、查看日志: http://192.168.1.1:9100
七、在虚拟机node1节点上操作安装kibana
(一)安装
(二)配置kibana
(三)启动kibana
(四)访问kibana :http://192.168.1.1:5601
八、企业案例:收集httpd访问日志信息(在客户端httpd服务器上操作)
(一)安装httpd
(二)启动服务
(三)安装logstash
(四)编写httpd日志收集配置文件
(五)使用logstash命令导入配置:
(六)使用kibana查看即可!http://192.168.1.1:5601
一、实验拓扑
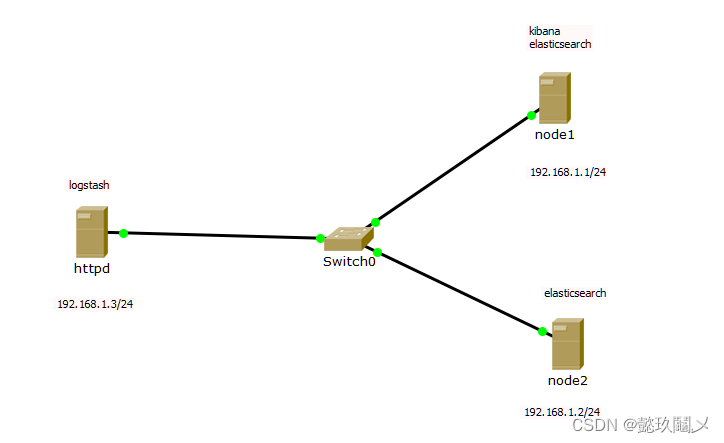
二、环境配置
(一)设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
1、在虚拟机node1上操作
①修改主机名
命令:hostnamectl set-hostname node1
②设置hosts文件
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2
2、在虚拟机node2上操作
①修改主机名
命令:hostnamectl set-hostname node2
②设置hosts文件
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2
3、测试node1与node2的通联性
三、 安装node1与node2节点的elasticsearch
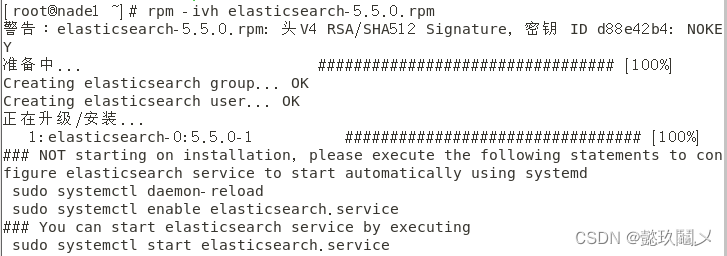
(一)在虚拟机node1与node2分别安装
命令:mv elk软件包 elk
cd elk
rpm -ivh elasticsearch-5.5.0.rpm
(二)修改配置文件
1、在虚拟机node1上操作
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery,zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
2、在虚拟机node2上操作
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
(三)启动elasticsearch服务(在虚拟机node1和node2上分别操作)
命令:systemctl start elasticsearch

netstat -anptu | grep :9200 #查看端口号,elasticsearch服务是否启动
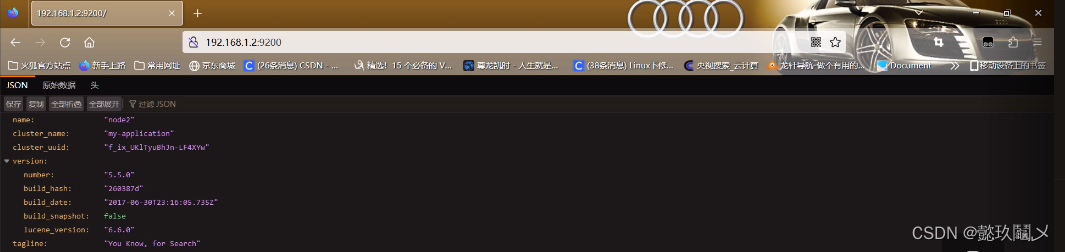
(四)查看节点信息
http://192.168.1.1:9200
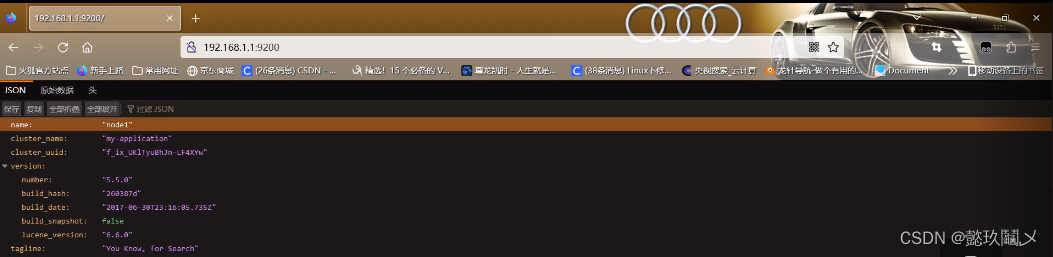
http://192.168.1.2:9200
四、在虚拟机node1安装elasticsearch-head插件
(一)安装node
命令:cd elk
tar xf node-v8.2.1.tar.gz #解包
cd node-v8.2.1
./configure && make && make install #配置、编译、安装
#等待安装完毕,安装完最终界面
(二)拷贝命令
命令:cd elk
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
(三)安装elasticsearch-head
命令:cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install
(四)修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin: "*" //跨域访问允许的域名地址

重启服务: systemctl restart elasticsearch

(五)启动elasticsearch-head
命令:cd /root/elk/elasticsearch-head
npm run start &
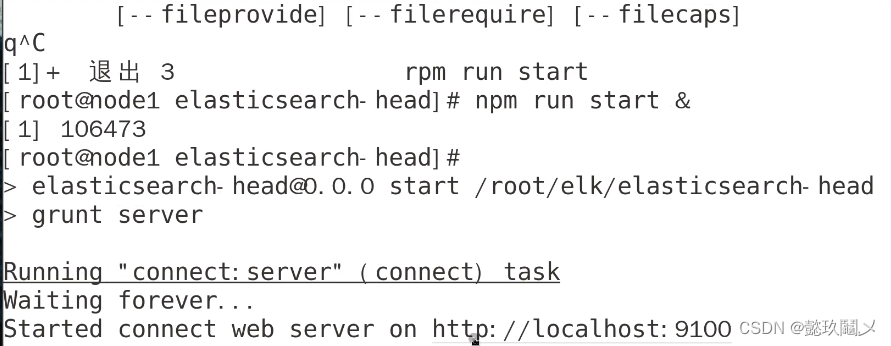
查看监听: netstat -anput | grep :9100
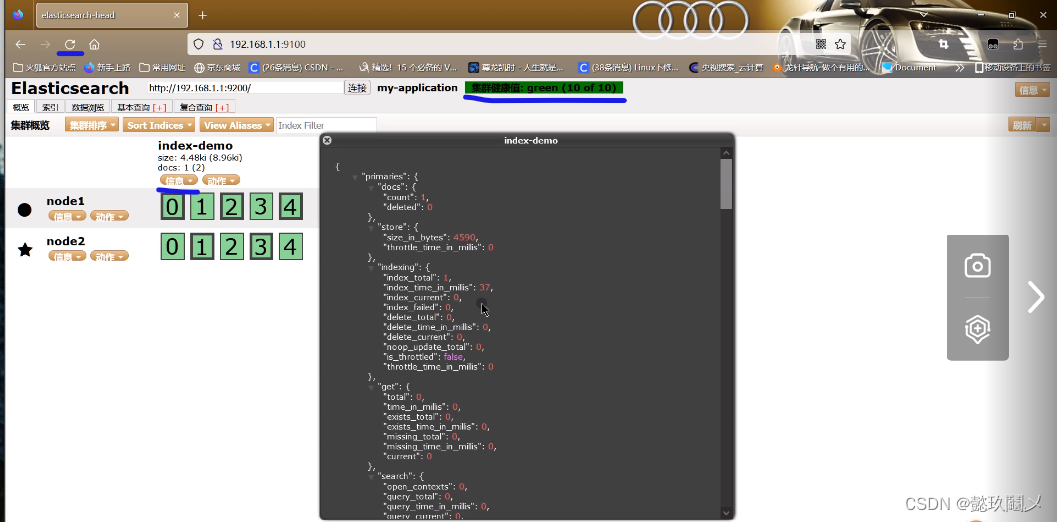
(六)访问
命令:http://192.168.1.1:9100

(七)测试
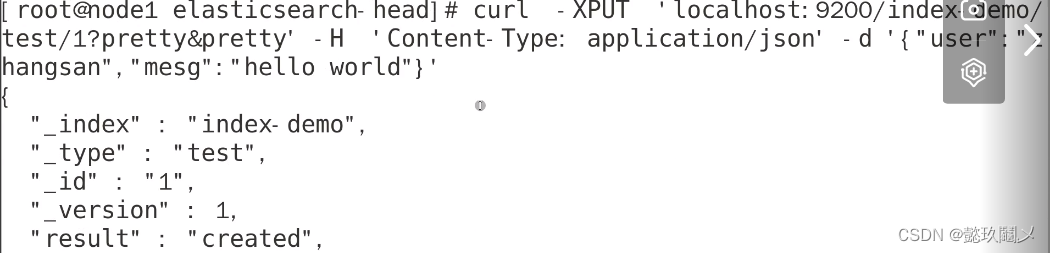
在node1的终端中输入:
curl -XPUT ‘localhost:9200/index-demo/test/1?pretty&pretty’ -H ‘Content-Type: application/json’ -d ‘{“user”:”zhangsan”,”mesg”:”hello world”}’
#最终显示界面

#刷新浏览器可以看到对应信息即可,相关界面如下
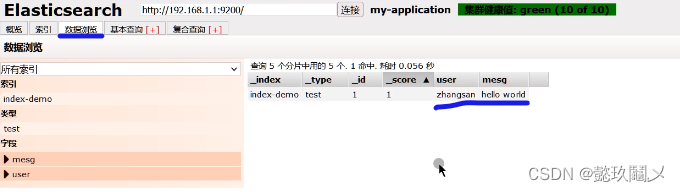
五、node1服务器安装logstash
(一)安装
命令:cd elk
rpm -ivh logstash-5.5.1.rpm

(二)启动服务
systemctl start logstash.service
(三)查看端口号
netstat -anputu | grep java

In -s /usr/share/logstash/bin/logstash /usr/local/bin/ #优化命令路径
(四)测试1:标准输入与输出
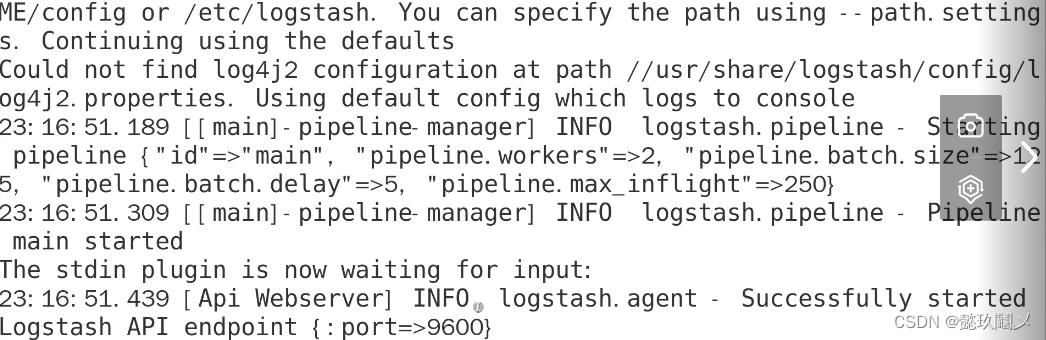
命令:logstash -e 'input{ stdin{} }output { stdout{} }'
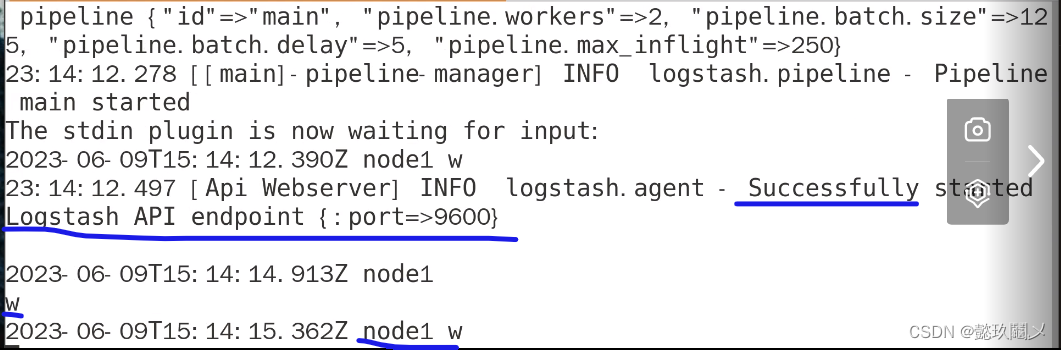
# 注意:最终界面显示情况如上图,当你输入w时,会有回应,按ctrl+c退出
(五)测试2: 使用rubydebug解码
命令:logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'
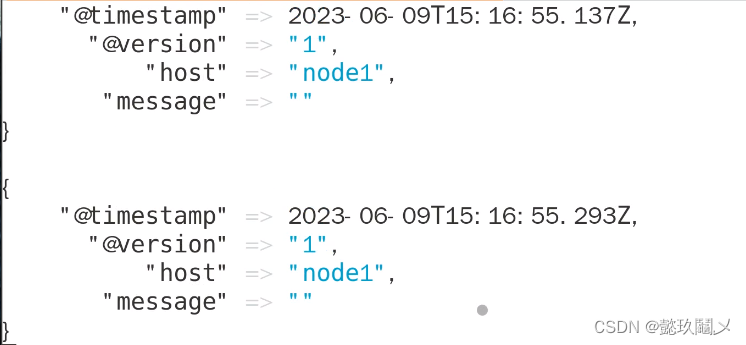
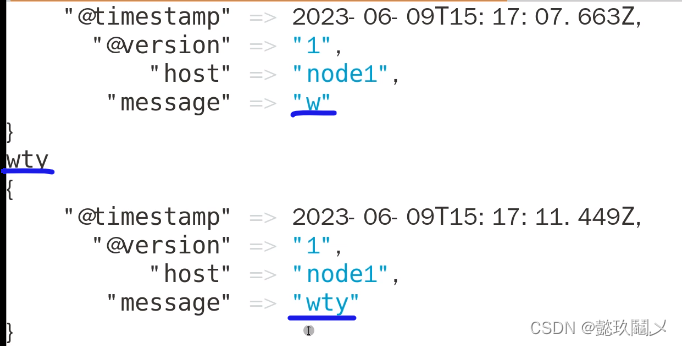
#注意:当你输入相应的内容时,会有回应,表示解码成功,按ctrl+c退出
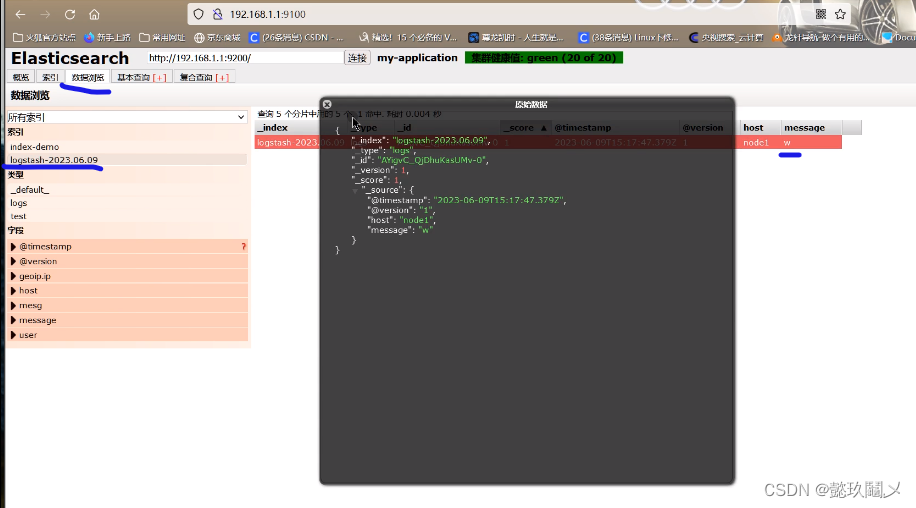
(六)测试3:输出到elasticsearch
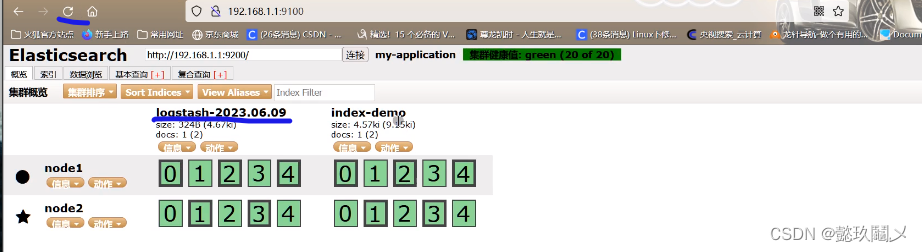
命令:logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.1.1:9200"]} }'

(七)查看结果:
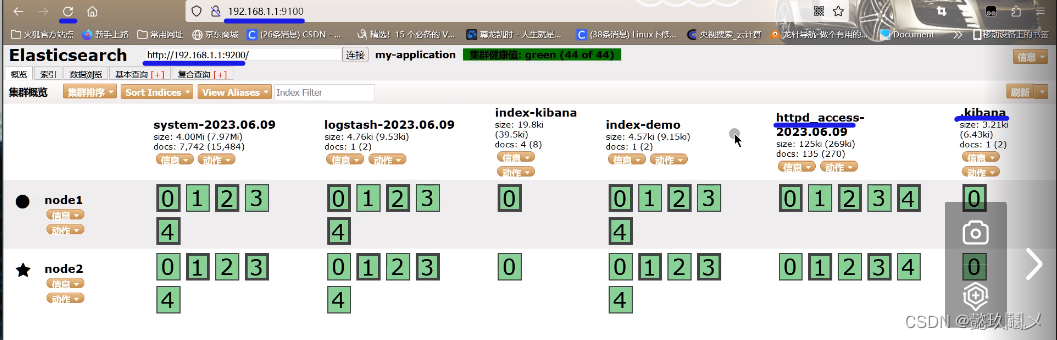
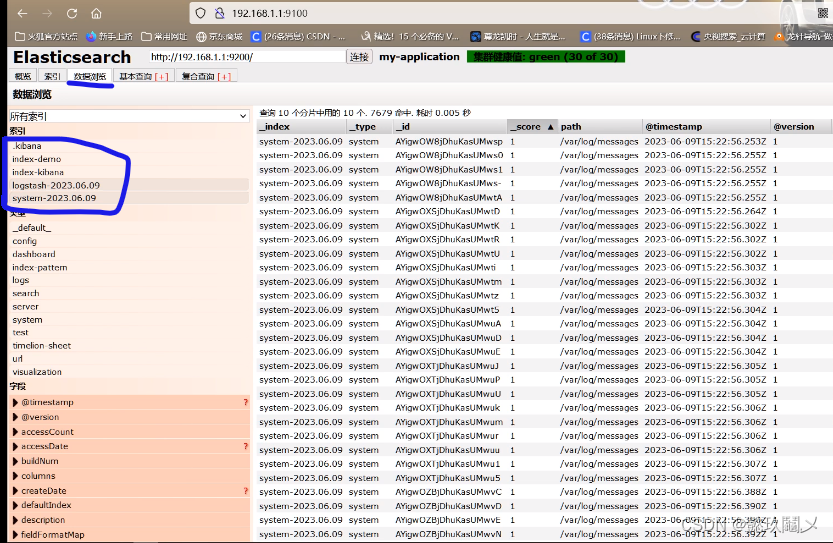
http://192.168.1.1:9100 #若看不到,请刷新!!!
六、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
(一)Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。
标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
(二)在每个部分中,也可以指定多个访问方式。
例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
(三)案例
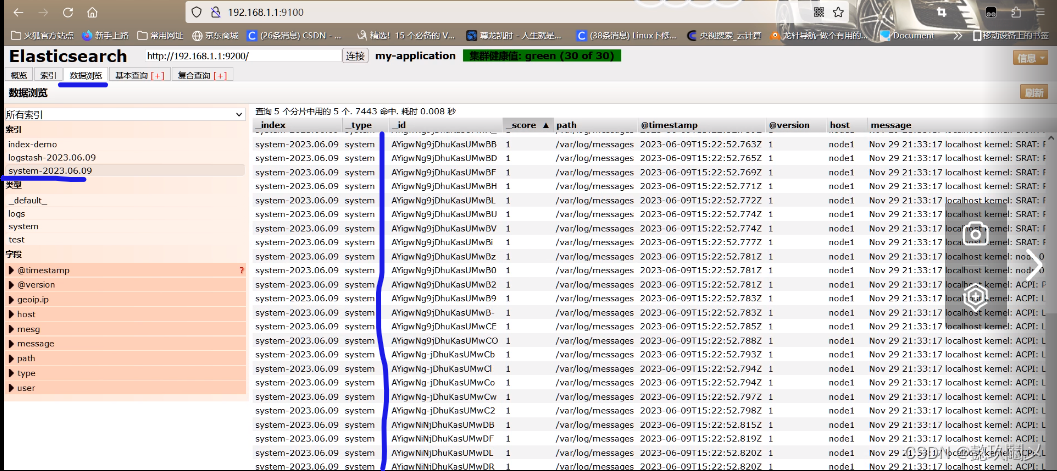
1、通过logstash收集系统信息日志
命令:chmod o+r /var/log/messages
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.1.1:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
2、重启日志服务
命令:systemctl restart logstash
3、查看日志: http://192.168.1.1:9100

七、在虚拟机node1节点上操作安装kibana
(一)安装
命令:cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm

(二)配置kibana
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.1.1:9200" //和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引
(三)启动kibana
命令:systemctl start kibana
netstat -anptu | grep :5601

(四)访问kibana :http://192.168.1.1:5601
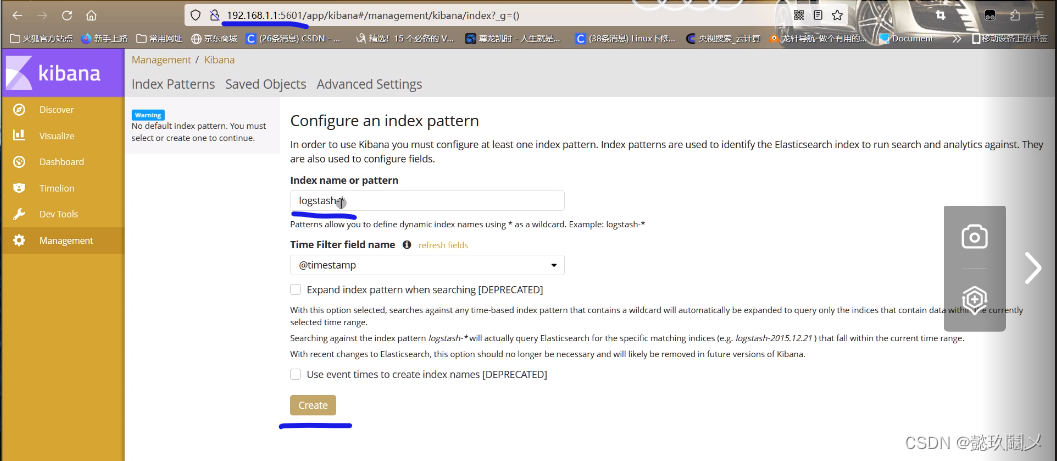
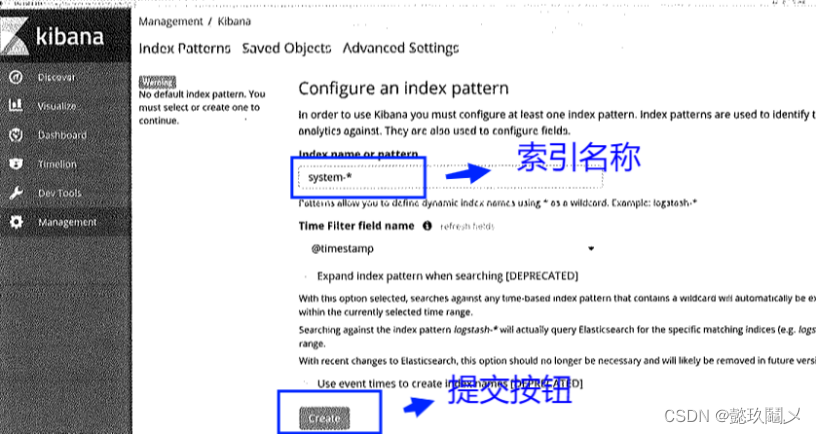
# 首次访问需要添加索引,我们添加前面已经添加过的索引:system-*
八、企业案例:收集httpd访问日志信息(在客户端httpd服务器上操作)
(一)安装httpd
命令:yum -y install httpd
(二)启动服务
命令:systemctl start httpd
(三)安装logstash
命令:cd elk
rpm -ivh logstash-5.5.1.rpm #安装
systemctl start logstash.service #启动服务
In -s /usr/share/logstash/bin/logstash /usr/local/bin/ #优化命令路径
#logstash在httpd服务器上作为agent(代理),不需要启动
(四)编写httpd日志收集配置文件
vim /etc/logstash/conf.d/httpd.conf
input {
file{
path=>"/var/log/httpd/access_log" //收集Apache访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
output{
elasticsearch {
hosts =>["192.168.1.1:9200"] // elasticsearch 监听地址及端口
index =>"httpd_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
(五)使用logstash命令导入配置:
命令:logstash -f /etc/logstash/conf.d/httpd.conf
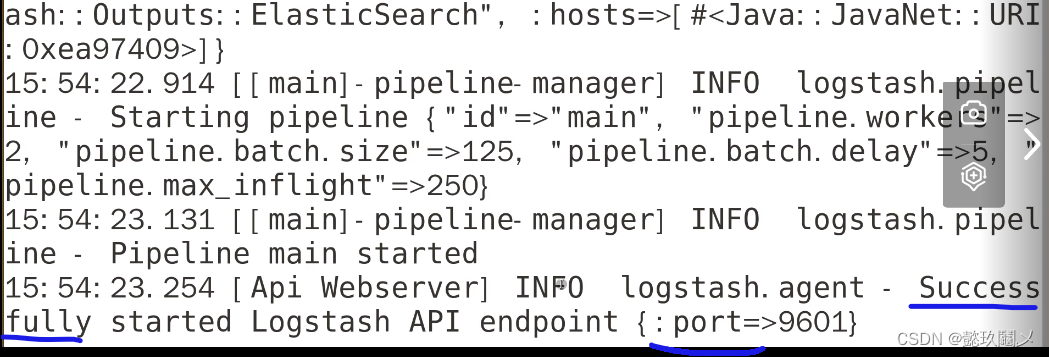
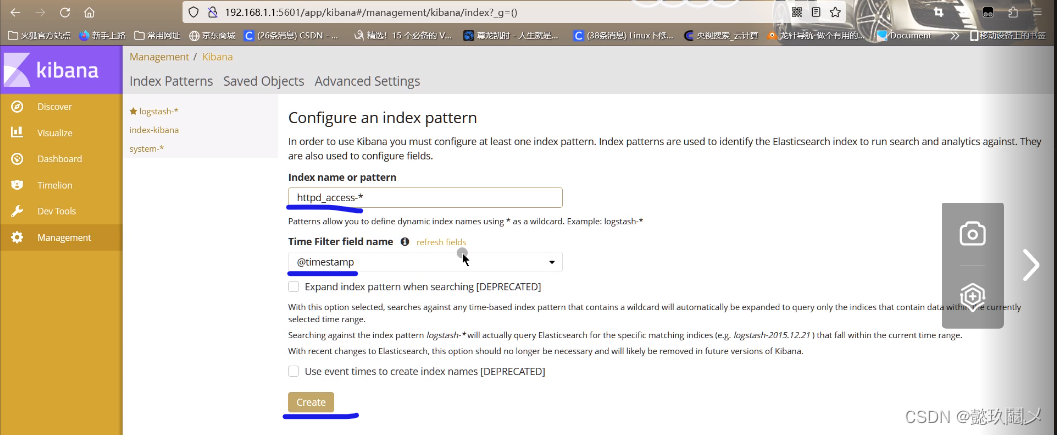
(六)使用kibana查看即可!http://192.168.1.1:5601
#查看时在mangement选项卡创建索引httpd_access-* 即可!

![[论文笔记]Bidirectional LSTM-CRF Models for Sequence Tagging](https://img-blog.csdnimg.cn/img_convert/38075ffe980f55263caec6b4557dfc85.png)