摘要
在本文中,我们提出了一种新的序列到序列学习框架的视觉跟踪,称为SeqTrack。它将视觉跟踪转换为一个序列生成问题,它以自回归的方式预测对象边界盒。这与之前的Siamese跟踪器和transformer跟踪器不同,它们依赖于设计复杂的磁头网络,如分类和回归头。SeqTrack只采用了一个简单的编解码器变压器架构。编码器使用bidirectional transformer提取视觉特征,而解码器使用 causal transformer自动回归生成一系列边界盒值。损失函数是一个普通的交叉熵。这种序列学习范式不仅简化了跟踪框架,而且在基准测试上取得了竞争性能。
介绍
视觉目标跟踪是计算机视觉中的一项基本任务。它的目的是估计任意目标在视频序列中的位置,只给定它在初始帧中的位置。现有的跟踪方法通常采用分治策略,将跟踪问题分解为多个子任务,如目标尺度估计和中心点定位等。每个子任务都由一个特定的头网络来处理。例如,SiamRPN及其后续工作采用分类头进行目标定位,采用回归头进行规模估计,如图1(a).所示。STARK和基于变压器的跟踪器设计了角头网络来预测目标物体的边界盒角,如图1(b).所示。
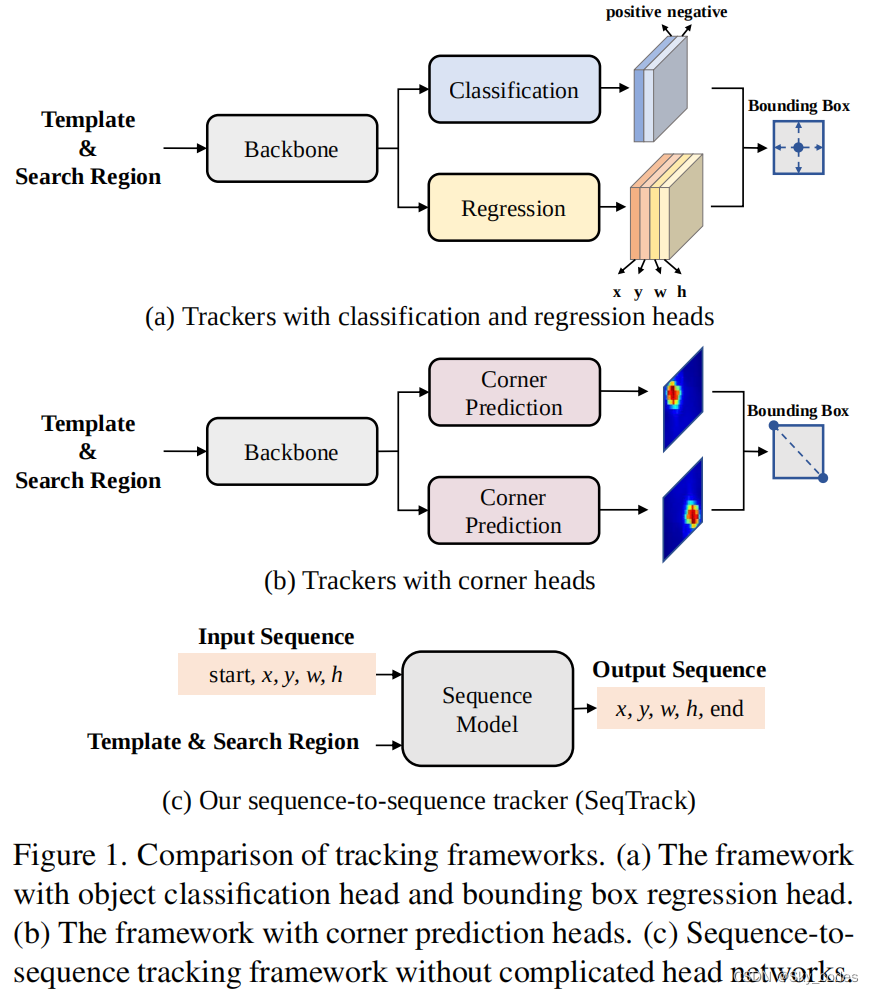
这种分治之策略在跟踪基准上表现出优越的性能,从而成为现有模型的主流设计。然而,仍然存在两个缺陷。首先,每个子任务都需要一个定制的头网络,从而导致一个复杂的跟踪框架。其次,每个头网络需要一个或多个学习损失函数,如交叉熵损失[7,27]、l1损失、generalized IoU损失,由于额外的超参数而使训练变得困难。为了解决这些问题,在本文中,我们提出了一种新的序列到序列跟踪(SeqTrack)框架,如图1©.所示。
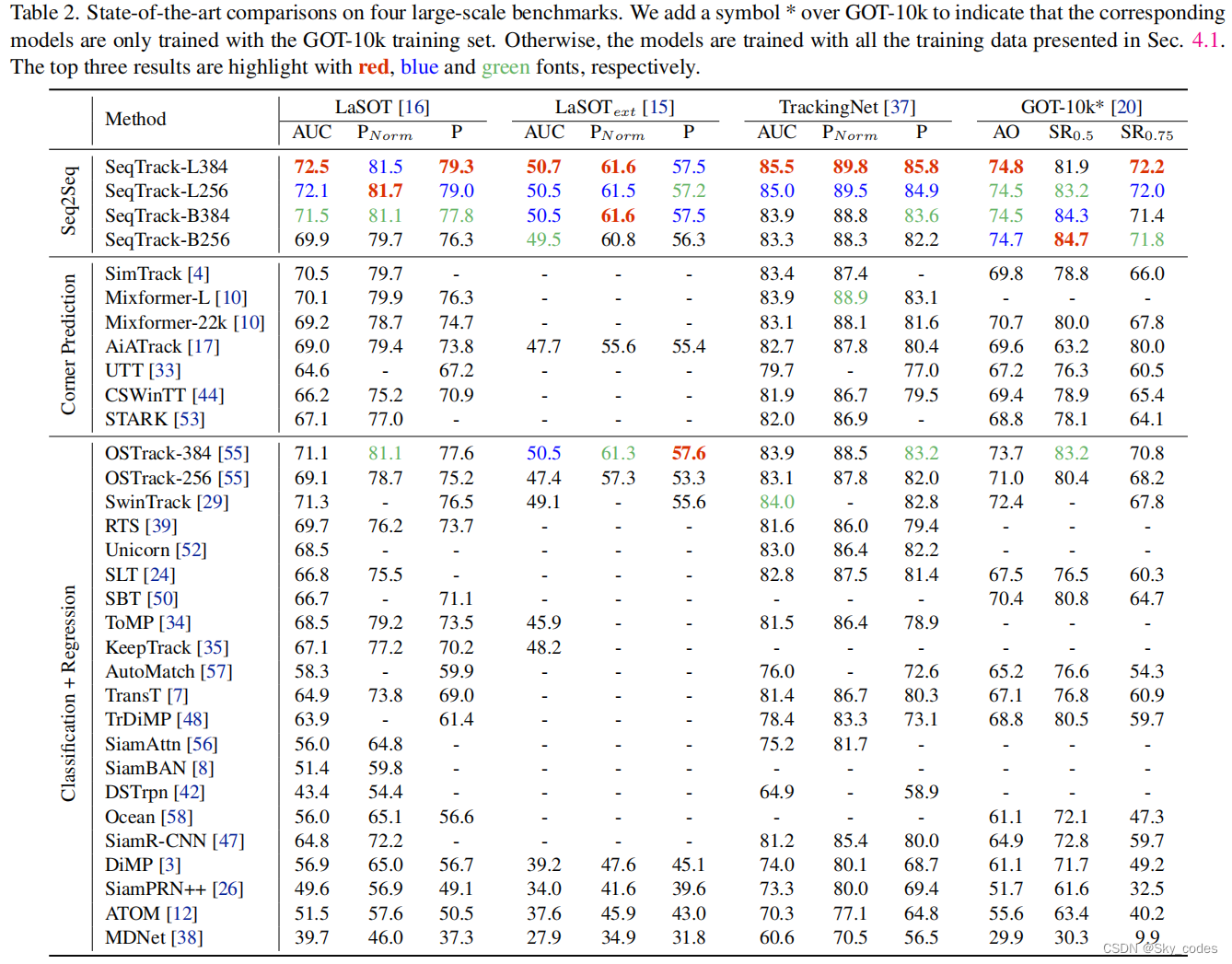
通过将跟踪建模为序列生成任务,SeqTrack摆脱了复杂的头网络和冗余损失函数。它基于直觉,如果模型知道目标对象在哪里,我们就可以简单地教它如何读取边界框,而不是使用分治策略明确地执行额外的分类和回归。为此,我们将边界框的四个值转换为一个离散令牌序列,并使模型学习逐标记生成这个序列令牌。我们采用一个简单的编码-解码器变压器来建模生成。该编码器是提取视频帧的视觉特征,而解码器是利用所提取的特征生成边界框值的序列。生成以自回归的方式执行,这意味着模型会根据之前观察到的标记生成一个令牌。在每一步中,一个新生成的令牌值被反馈到模型中以生成下一个值。我们在解码器中的自我注意模块上施加了一个因果掩模,以防止令牌关注后续的令牌。这种因果掩蔽机制确保了在位置i上的令牌的生成仅取决于其在小于i的位置上的继续进行的令牌。视觉特征通过交叉注意层[46]集成到解码器中。当生成输出边界框的四个标记值时,生成将结束。输出序列被直接用作结果。实验证明,我们的SeqTrack方法是有效的,在几个跟踪基准上实现了新的最先进的性能。例如,SeqTrack-B256在GOT-10k上获得了74.7%的AO分数,在对齐设置下,即使用相同的编码器架构和输入分辨率下,比最近的OSTrack-256跟踪器[55]高出3.7%。此外,与最近最先进的跟踪器MixFormer相比,SeqTrack-B256的运行速度快1.4倍(40 v.s 29 fps),而比LaSOT的AUC得分高0.7%。值得注意的是,所有这些先前的方法都严重依赖于设计良好的磁头网络和相应的复杂损失函数[30,41]。相比之下,我们的SeqTrack只采用了一个简单的编解码器变压器结构,并且具有简单的交叉熵损耗。
总之,这项工作的贡献有两方面:
- 我们提出了一种用于视觉跟踪的序列到序列的学习方法。它将跟踪作为一个生成任务,为跟踪建模提供了一个新的视角。
- 我们提出了一种新的序列跟踪模型家族,它在速度和准确性之间取得了很好的权衡。实验验证了新模型的有效性。
相关工作
- Visual Tracking
方法
本节详细介绍了所提出的SeqTrack方法。首先,我们简要地概述了我们的序列到序列的跟踪框架。然后,我们描述了图像和序列表示,以及所提出的模型架构。最后,我们介绍了训练和推理管道以及跟踪先验知识的集成。
Overview
SeqTrack的总体框架如图2(a).所示。它采用了一种简单的编解码器变压器结构。对象边界框首先被转换为一系列离散的标记,即,[x、y、w、h]。编码器提取输入视频帧的视觉特征,而解码器利用所提取的特征自动回归生成边界框令牌序列。
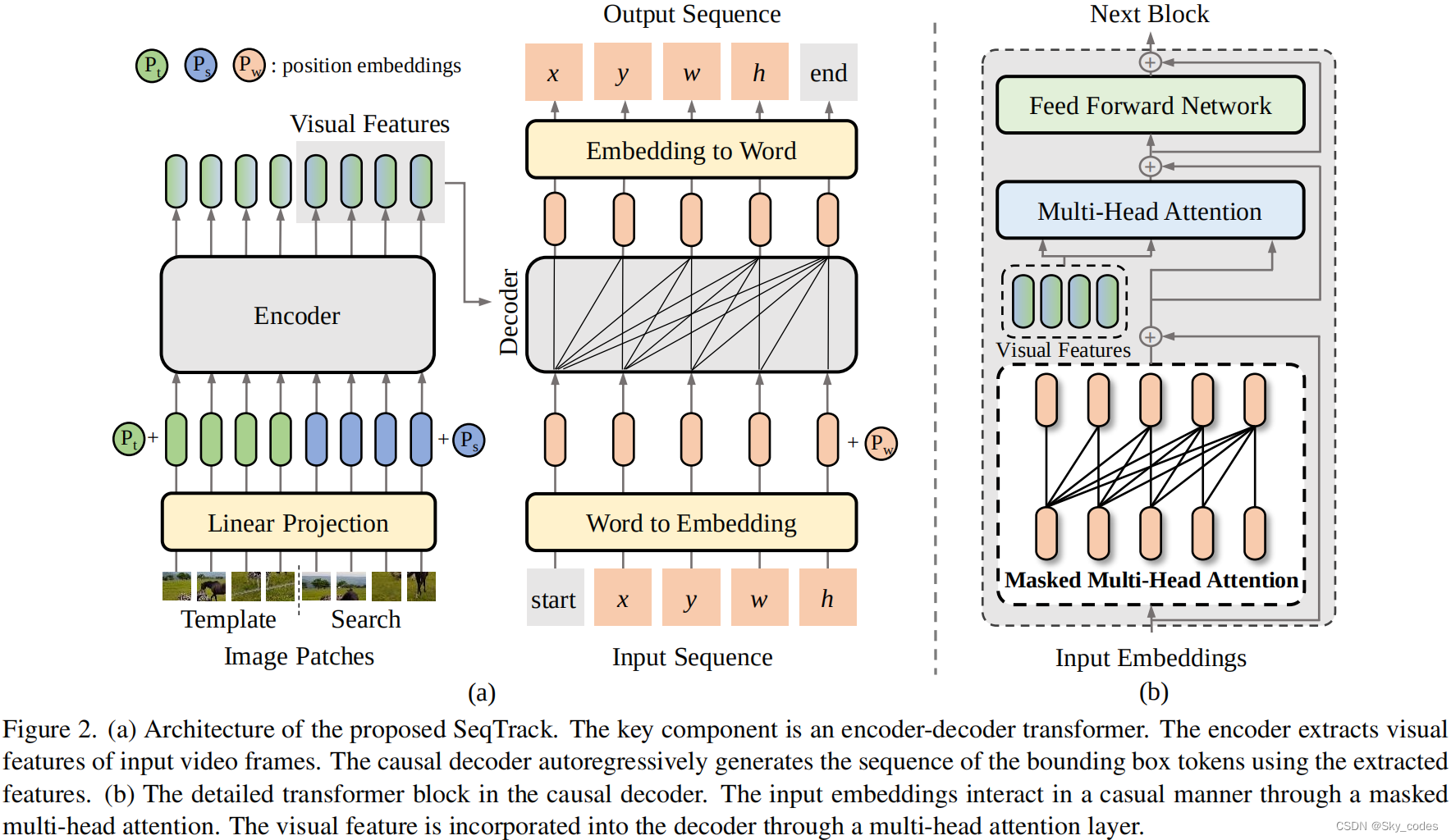
编码器提取输入视频帧的视觉特征,而解码器利用所提取的特征自动回归生成边界框令牌序列。在解码器中的自我注意模块上施加了一个因果注意面具,以限制令牌只关注它们的程序令牌。除了这四个边界框令牌之外,我们还使用了两个特殊的令牌:开始和结束。开始令牌告诉模型开始生成,而结束令牌表示生成的完成。在训练过程中,解码器的输入序列为[start,x,y,w,h],目标序列为[x,y,w,h,end]。在推理过程中,解码器的输入序列最初包含一个开始令牌。在每个步骤中,将生成一个新的边界框标记,并将其附加到输入序列中,以生成下一个标记。当生成边界框的四个标记值时,预测将结束。
Image and Sequence Representation
Image Representation
所述编码器的输入包括模板图像 t ∈ R 3 × H × W t∈R^{3×H×W} t∈R3×H×W和搜索图像 s ∈ R 3 × H × W s∈R^{3×H×W} s∈R3×H×W。图像t表示感兴趣的对象,而s表示后续视频帧中的搜索区域。在现有的跟踪器中,模板图像的分辨率通常小于搜索图像。相比之下,我们对这两幅图像使用相同的大小,因为我们发现在模板中添加更多的背景有助于提高跟踪性能。搜索图像和模板图像被划分为补丁: s p ∈ R N × P 2 × 3 s_p∈R^{N×P^2×3} sp∈RN×P2×3和 t p ∈ R N × P 2 × 3 t_p∈R^{N×P^2×3} tp∈RN×P2×3,其中(P,P)为补丁大小,N=HW /P2为补丁号。利用线性投影将图像补丁映射到视觉嵌入中。可学习的位置嵌入[46]被添加到补丁嵌入中,以保留位置信息。然后将合并后的嵌入数据输入编码器。
Sequence Representation.
我们将目标边界框转换为一系列离散的标记。具体来说,边界框是由它的中心点xy和缩放和wh决定的。有几种边界框格式,如[x、y、w、h]和[w、h、x、y]。我们使用[x,y,w,h]的格式,因为它与人类的先验知识相一致:首先定位物体的位置[x,y],然后估计它的尺度[w,h]。每个连续坐标被均匀地离散成 [ 1 , n b i n s ] [1,n_{bins}] [1,nbins]之间的一个整数。我们对所有的坐标都使用一个共享的词汇表V。 [ 1 , n b i n s ] [1,n_{bins}] [1,nbins]之间的每个整数都可以看作是V中的一个单词,所以V的大小为 n b i n s n_{bins} nbins(在我们的实验中为4000)。最终的输入序列为[start x y w h],目标序列为[x y w h end]。V中的每个单词都对应着一个可学习的嵌入,并在训练过程中进行了优化。特殊的标记start也对应于一个可学习的嵌入。输入word的相应嵌入被输入到解码器中。由于变压器是排列不变的,我们用可学习的位置嵌入来增加词嵌入。对于最终的模型输出,我们需要将嵌入映射回单词。为此,我们使用了一个带有softmax的多层感知器,根据输出嵌入从V中采样单词。
Model Architecture
我们的模型采用了一个简单的编解码器变压器架构,如图2所示。利用编码器提取输入视频帧的视觉特征,解码器以自回归的方式预测目标对象的边界盒。
*Encoder.*该编码器是一个标准的视觉变压器(ViT)。该架构与ViT相同,除了两个小的修改:1)该类标记将被删除,因为它是为图像分类任务而设计的。2)在最后一层附加一个线性投影,以对齐编码器和解码器的特征尺寸。编码器接收模板和搜索图像的补丁嵌入,并输出其相应的视觉特征。只有搜索图像的特征被输入解码器。该编码器的功能是联合提取搜索图像和模板图像的视觉特征,并通过注意层学习特征级的对应关系。
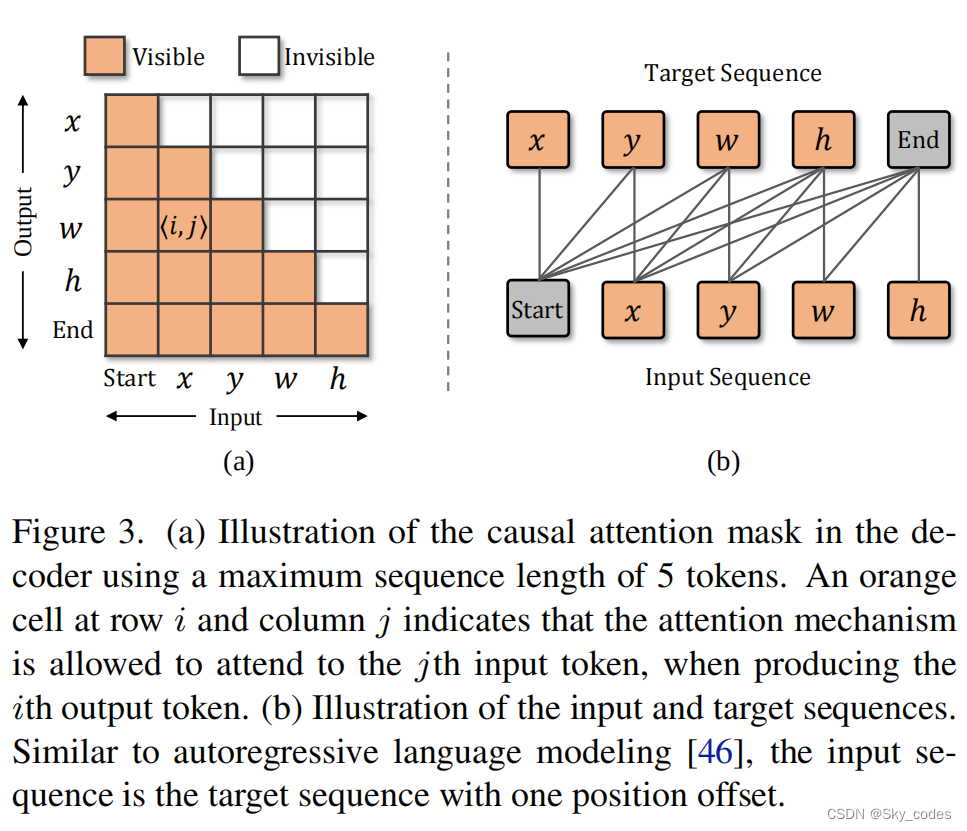
Decoder. SeqTrack的解码器是一个因果变压器。如图2(b)所示,每个变压器块由一个掩蔽的多头注意、一个多头注意和一个前馈网络(FFN)组成。更具体地说,掩蔽的多头注意力从前一个块接收单词嵌入,并利用因果掩码来确保每个序列元素的输出只依赖于其之前的序列元素。换句话说,注意掩模将位置i的输出嵌入限制为只关注小于i的位置的输入嵌入,如图3(a).所示
然后,多头注意力将提取的视觉特征整合到单词嵌入中,这使得单词嵌入能够来自编码器的视觉特征。最后,应用前馈网络(FFN)为下一个块生成嵌入。
Training and Inference
*Training.*与语言建模类似,SeqTrack被训练以最大限度地提高目标标记基于前面的子序列的对数似然,并使用交叉熵损失输入视频框架。学习目标函数的表述为:
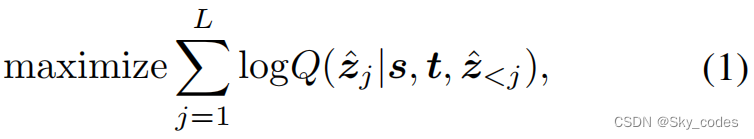
其中Q(·)为softmax概率,s为搜索图像,t为模板,zˆ为目标序列,j为标记的位置,L为目标序列的长度。这里,zˆ<j表示前面用于预测当前令牌zˆj的子序列。输入序列是具有一个位置偏移(省略开始和结束)的目标序列,如图3(b).所示这种偏移量与因果掩蔽相结合,保证了序列模型的自回归特性。目标序列可以看作是对对象边界框的描述。训练是教模型根据前面的单词“读出”描述中的单词。
Inference在推理过程中,编码器在后续的视频帧中感知模板图像和搜索区域。解码器的初始输入是开始令牌,它告诉模型开始生成。然后,模型逐个地“读出”目标序列[x、y、w、h、end]标记。对于每个标记,模型根据最大似然值从词汇表V中进行抽样,即zˆj=argmaxzjQ(zj|,t,zˆ<j),其中zj是V中的单词。此外,我们还引入了在线模板更新和窗口惩罚,在推理过程中集成了先验知识,进一步提高了模型的准确性和鲁棒性。这些细节将在下面的小节中进行描述。
Prior Knowledge Integration
先验知识,如窗口惩罚和在线更新,已被广泛纳入现有的跟踪模型,并被证明是有效的。在本小节中,我们将讨论如何将这些先验知识引入到所提出的序列到序列学习框架中,以进一步提高跟踪性能。
Online Update由于在在线跟踪过程中,目标对象的外观可能会发生巨大的变化初始模板图像对于目标定位并不总是可靠的。为了解决这个问题,我们将在线模板更新[53]集成到我们的方法中。更具体地说,除了初始模板图像外,我们还引入了一个动态模板来捕获目标对象的外观变化。动态模板将进行动态更新。众所周知,低质量的模板可能导致较差的跟踪性能。因此,我们使用生成的标记的可能性来自动选择可靠的动态模板。具体来说,我们对生成的四个边界框值上的softmax分数进行平均。如果平均得分大于特定的阈值τ,并且达到更新间隔Tu,则动态模板将与当前帧中的跟踪结果进行更新,否则保持之前的状态。实验表明,这种简单的方法可以提高跟踪精度。4.3).此外,与之前的方法不同,我们的方法没有带来任何额外的分数头来决定是否更新模板,这通常需要第二阶段的训练。
Window Penalty经验证明,连续两帧之间的像素位移是相对较小的。为了惩罚较大的位移,我们在在线推理过程中引入了一种新的窗口惩罚策略。具体地说,目标对象在前一帧中的位置对应于当前搜索区域的中心点。当前搜索区域中中心点的离散坐标为[ n b i n s / 2 n_{bins}/ 2 nbins/2, n b i n s / 2 n_{bins}/ 2 nbins/2 ]。当生成x和y时,我们根据词汇V与 n b i n s n_{bins} nbins的差异来惩罚词汇V中整数(即单词)的可能性。整数和 n b i n s / 2 n_{bins}/ 2 nbins/2之间的很大差异将会得到很大的惩罚。在实现过程中,整数的softmax分数形成了一个大小为 n b i n s n_{bins} nbins的向量。我们只需把这个向量乘以相同大小的汉宁窗口。这样,大的位移就被抑制了。与之前的实践[7,27]不同,我们不引入额外的超参数来调整惩罚的大小。
实验
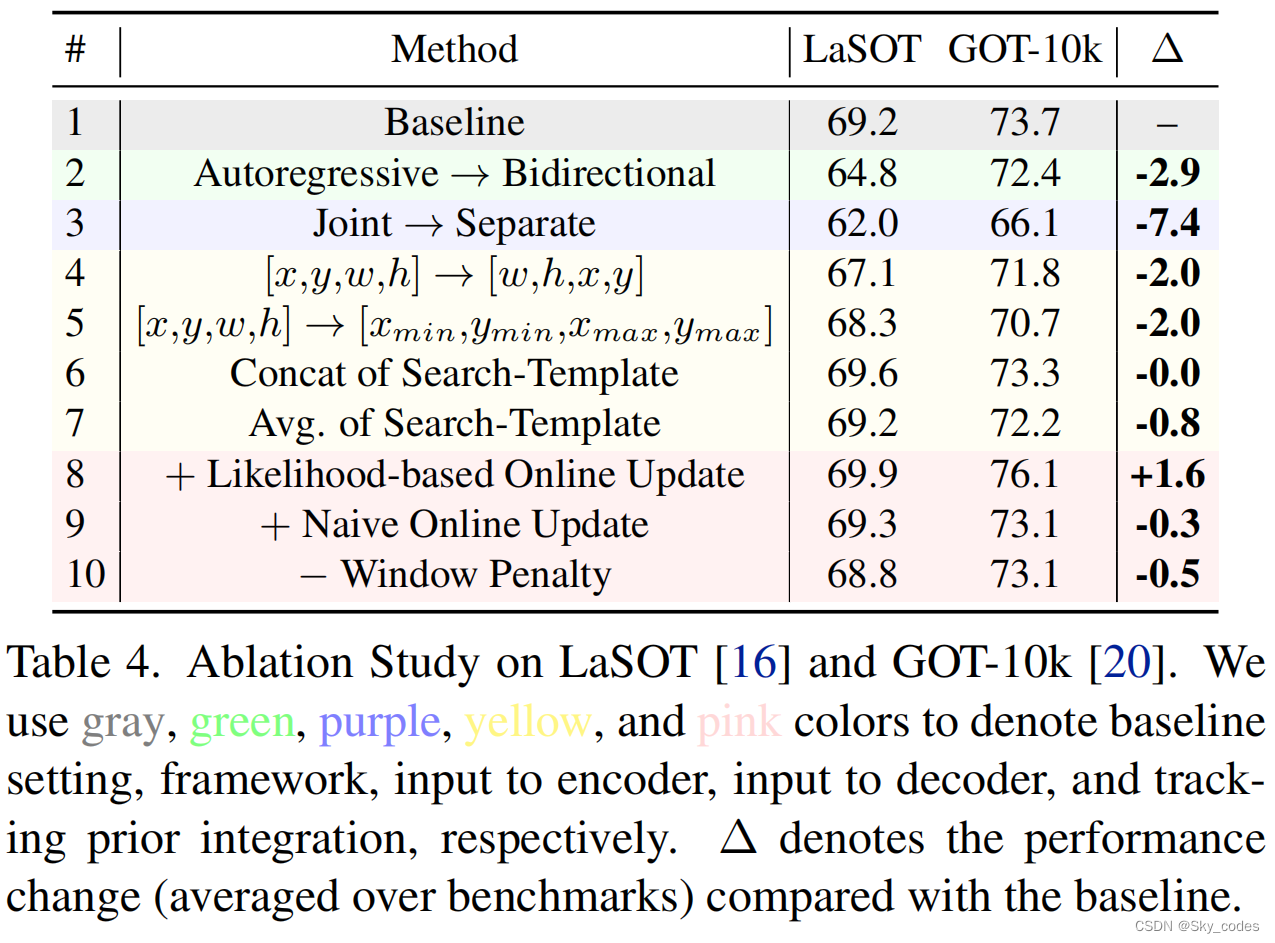
Ablation and Analysis.
可视化
为了更好地理解SeqTrack是如何“读取”目标状态的,我们将最后一个解码器块的交叉注意(平均在头部上)可视化。图7显示了模型生成令牌时的交叉注意图。当生成第一个标记x时,注意力是相对多样化的。当生成后续的令牌时,注意力很快就会集中在目标对象上。注意力更集中在关键信息上,例如,产生x和w时的人的手臂和斑马的尾巴,以及产生y和h时的脚。

结论
这项工作提出了一种新的序列到序列的跟踪框架,即SeqTrack,它将视觉跟踪作为一个序列生成问题。它使用一个简单的编码解码器变压器架构,摆脱复杂的头网络和损失函数。大量的实验表明,SeqTrack是有效的,与最先进的跟踪器相比,实现了具有竞争力的性能。我们希望这项工作能够催化更引人注目的研究序列学习的视觉跟踪。
SeqTrack的一个局限性是,尽管实现了具有竞争力的性能,但由于该方法的物体移出视野或被干扰物遮挡,很难处理干扰物没有明确的重新检测模块。此外,我们只使用少量的视频帧就建立了序列模型。一个更有前途的解决方案是将整个视频建模为一个序列,并教模型以自回归的方式逐帧“读出”目标状态。在未来的工作中,我们将研究这种长期视频的序列到序列建模。