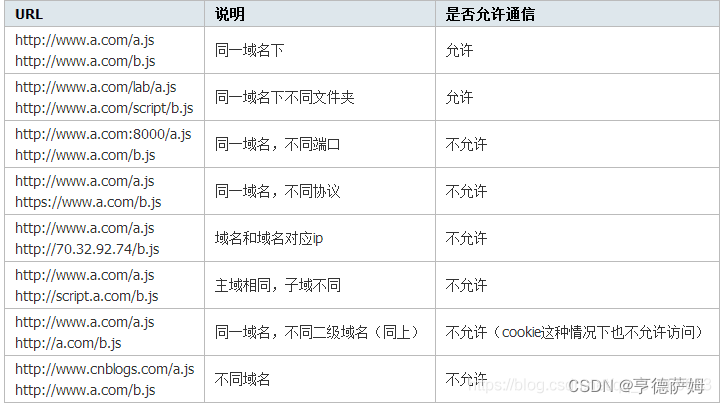
文章目录
- 一 独立访客数量计算
- 二 布隆过滤器
- 1 什么是布隆过滤器
- 2 实现原理
- (1)HashMap 的问题
- (2)布隆过滤器数据结构
- 3 使用布隆过滤器去重
一 独立访客数量计算
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.readTextFile("E:\\develop\\MyWork\\flink2022tutorial\\src\\main\\resources\\UserBehavior.csv")
.map(new MapFunction<String, Example7.UserBehavior>() {
@Override
public Example7.UserBehavior map(String value) throws Exception {
String[] arr = value.split(",");
return new Example7.UserBehavior(
arr[0],arr[1],arr[2],arr[3],
Long.parseLong(arr[4]) * 1000L
);
}
})
.keyBy(r -> r.behavior.equals("pv"))
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Example7.UserBehavior>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Example7.UserBehavior>() {
@Override
public long extractTimestamp(Example7.UserBehavior element, long recordTimestamp) {
return element.timestamp;
}
})
)
.keyBy(r -> true)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.aggregate(new CountAgg(),new WindowResult())
.print();
env.execute();
}
public static class WindowResult extends ProcessWindowFunction<Long,String,Boolean, TimeWindow>{
@Override
public void process(Boolean s, Context context, Iterable<Long> elements, Collector<String> out) throws Exception {
String windowStart = new Timestamp(context.window().getStart()).toString();
String windowEnd = new Timestamp(context.window().getEnd()).toString();
Long count = elements.iterator().next();
out.collect("窗口" + windowStart + "~" + windowEnd + "的统计值是:" + count);
}
}
// 使用hashset对用户id进行去重,输出访客数量
public static class CountAgg implements AggregateFunction<Example7.UserBehavior, HashSet<String>,Long>{
@Override
public HashSet<String> createAccumulator() {
return new HashSet<>();
}
@Override
public HashSet<String> add(Example7.UserBehavior value, HashSet<String> accumulator) {
accumulator.add(value.userId);
return accumulator;
}
@Override
public Long getResult(HashSet<String> accumulator) {
return (long)accumulator.size();
}
@Override
public HashSet<String> merge(HashSet<String> a, HashSet<String> b) {
return null;
}
}
此程序有一个隐患:现将所有数据keyBy到了同一条流,每一个小时取一次uv,添加到hashSet去重,如果程序的用户向很大,如1亿个独立访客,一个用户的用户id为100个字符,那么一个窗口中的独立访客就要占用10G的内存。
想要优化这种使用了增量聚合与全窗口聚合的程序,就需要使用一种新的数据结构 – 布隆过滤器。
二 布隆过滤器
1 什么是布隆过滤器
本质上布隆过滤器是一种数据结构,是一种比较巧妙的概率型数据结构(probabilistic datastructure),特点是高效地插入和查询,可以用来告诉你“某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
2 实现原理
(1)HashMap 的问题
通常我们判断某个元素是否存在用的是什么?
HashMap 可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦值很多,例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
再加入我们的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
(2)布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,如下图:

如果要映射一个值到布隆过滤器中,需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位重置为 1,例如针对值“baidu”和三个不同的哈希函数分别生成了哈希值 1、4、7,之后“baidu”字符串就被丢弃,则上图转变为:

那么此时现在再存一个值“tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。
现在如果想查询“dianping”这个值是否存在,哈希函数返回了 1、5、8 三个值,结果发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此可以很确定地说“dianping”这个值不存在。
而当需要查询“baidu”这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后检查发现这三个 bit 位上的
值均为 1,那么不可以说“baidu”存在,只能是“baidu”这个值可能存在,不确定1、4、7这三位没有被其他数据覆盖过。
3 使用布隆过滤器去重
使用org.apache.flink.shaded.guava18.com.google.common.hash.BloomFilter包下的布隆过滤器。
// 使用布隆过滤器对用户id进行去重,输出访客数量
public static class CountAgg implements AggregateFunction<Example7.UserBehavior, Tuple2<Long,BloomFilter<String>>,Long>{
@Override
public Tuple2<Long, BloomFilter<String>> createAccumulator() {
// 参数依次为要去重的元素类型,预估有多少人,误判率
return Tuple2.of(0L,BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01));
}
@Override
public Tuple2<Long, BloomFilter<String>> add(Example7.UserBehavior value, Tuple2<Long, BloomFilter<String>> accumulator) {
if(!accumulator.f1.mightContain(value.userId)){
accumulator.f1.put(value.userId);
accumulator.f0 += 1L;
}
return accumulator;
}
@Override
public Long getResult(Tuple2<Long, BloomFilter<String>> accumulator) {
return accumulator.f0;
}
@Override
public Tuple2<Long, BloomFilter<String>> merge(Tuple2<Long, BloomFilter<String>> a, Tuple2<Long, BloomFilter<String>> b) {
return null;
}



![[附源码]Python计算机毕业设计Django网上电影购票系统](https://img-blog.csdnimg.cn/ec4d30a0a8df4f0a8476e79644931cbe.png)



![[Cortex-M3]-4-如何在内嵌RAM中运行程序](https://img-blog.csdnimg.cn/563f907e9f3b464f93246d05a677b75d.png)