定向写作模型CTRL
介绍
CTRL全称为Conditional Transformer Language有条件的文本生成模型,它始于Salesforce在2019年发布的论文《A Conditional Transformer Language Model for Controllable Generation》,该模型用于定向写作。论文地址如下:https://arxiv.org/pdf/1909.05858.pdf
这两年非常流行的BERT和GPT-2都基于Transformer模型,虽然代码量不大,逻辑也并不复杂,但是极大规模的数据量、训练强度和模型容量,以及利用无监督文本建模,使模型的能力空前强大,在一些领域已超过人类水平。
GPT-2使用各种类型的文章训练模型,包括散文、小说、新闻、科技文章,用它写作的文章也综合了各种风格。如果想生成“金庸风格”的小说,则需要用所有金庸先生的小说重新训练模型;或者从原模型中提取特征构造新模型;也可以在原有模型基础上fine-tuning。如需撰写新闻稿,则需要另行训练。
GPT-2模型根据文章开头的内容,继续向后联想,控制不了文章的具体内容,因此也有人把它称为“造谣神器”。除了瞎编,它的实际用途又在何处?如何更好的控制文章的内容,生成有价值的文本。
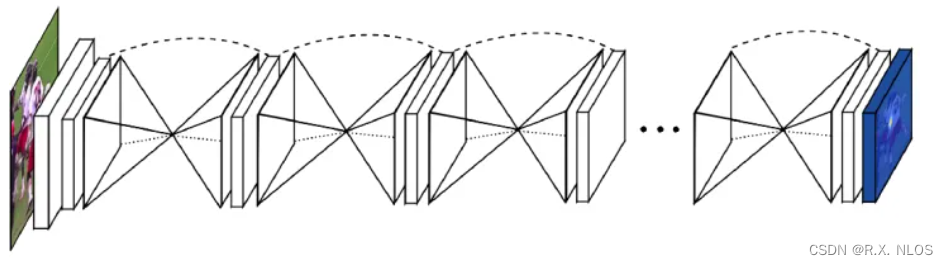
CTRL是继GPT-2后出现的写作模型,同样也基于Transformer。与之前模型不同的是:它无需进一步训练就可以解决特定领域的具体问题。CTRL模型可以指定文章的领域、风格、主题、时间、实体,实体间的关系,以及任务相关的行为等等,因此可以将其看成命题作文。它使用140G数据训练,参数规模1.63 billion(16亿,比GPT-2更大)。模型维度1280维,48层EncoderLayer,16头Attention,也是一个体量巨大的模型。
CTRL模型的最大优势是在生成文本时可指定文章的类型,同一模型可以写作不同风格的文章。论文也举出了用同一开头续写不同类型文章的实例,比如高分评论和低分评论的差异;“刀”在购物评论和恐怖小说的场景中生成的不同文章;按时间、国家写出文章中涉及的不同总统等等。

不同的角度,有不同的答案。换言之,CTRL关注了语料在不同场景中的不同含义。模型更符合实际应用的场景:使用者在同一时间,只可能生成某一特定类型,同时又希望单个模型支持生成各种类型的文章,CTRL可视为多任务学习。
由人写一个故事梗概:时间、地点、人物、事件,用模型按照某种风格遣词造句填充内容。它与之前的问答系统、文章概要又有何区别呢?原来的模型先用无监督数据训练模型,然后用有标注的问与答,内容与概要代入模型调优。标注数据毕竟有限;CTRL则海量的无监督数据进行了分类,这类似于简单的自动标注,让数据从一开始就更有针对性。
具体实现
CTRL的核心思想是从无监督的海量数据集中定位文章所在的领域。大多数训练数据都从网络上抓取,在抓取过程中通过网址标题等信息估计它所在领域,并作为特征,代入训练。从而让模型写出各种类型的文章,同理在问答等领域中运用此技术,也可以更有针对性地解决问题。
CTRL底层同样也基于Transformer,使用了其中Encoder部分,模型底层改动不大。之前的模型是根据词序列中的前n-1个词计算下一个词n是哪个词的可能性,如式一所示:
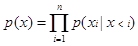
(式一)
CTRL又加入了条件c,即文章的控制信息如类型,在计算概率的同时考虑条件c。具体操作是在每一个序列的具体内容前加了入类型描述,使得在计算Attention过程中,类型与序列中的所有元素建立联系。如式二所示:
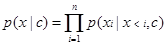
(式二)
代码中定义了一些常见,并且可以在抓取时识别的类型,如下图示:

除了类型,还支持将标题、下载的地址(有些下载地址中包含时间、实体等信息)……放在正文之前。除了上述改进,它还引入了新算法优化了后序词的筛选逻辑。
代码分析
CTRL官方代码可从以下网址下载: https://github.com/salesforce/ctrl
其中包括TensorFlow和Pytorch 两种实现方法,又细分为训练和应用两部分。以Pytorch为例,其核心代码主要在pytorch_transformer.py和pytorch_generation.py两个文件中。pytorch_transformer.py主要实现了Transformer模型,其内容是基础版Transformer模型的Encoder部分。pytorch_generation.py用于使用该模型撰写文章,其中包含解析数据和调用模型的方法。需要注意的是,使用该模型时,序列的第一位应为类型。模型训练部分在training_utils目录中用TensorFlow实现。
相对官方代码,更推荐Hugging Face团队发布的Transformer例程集,支持TensorFlow和Pytorch两种实现方式,其中也包含CTRL的实现,源码位置在:
https://github.com/huggingface/transformers/blob/master/src/transformers/
实现Pytorch版本CTRL的代码有:configuration_ctrl.py, modeling_ctrl.py, tokenization_ctrl.py,其中核心是modeling_ctrl.py,建议读者用debug工具跟踪调用模型的完整流程,查看每一步的输入及输出,便可完全理解该模型。调用方法如下:
01 import torch
02 from transformers import CTRLTokenizer, CTRLModel
03 tokenizer = CTRLTokenizer.from_pretrained('ctrl')
04 model = CTRLModel.from_pretrained('ctrl')、input_ids =
05 torch.tensor(tokenizer.encode("Links Hello, my dog is cute",
06 add_special_tokens=True)).unsqueeze(0) # Batch size 1
07 outputs = model(input_ids)注意:运行时将下载6.5G的预训练模型,虽然模型很大,但在没有GPU且机器性能不高的情况下也能正常调用模型预测部分。
总结
CTRL不仅是一个自然语言处理问题的解决方案,同样也可应用到其它的序列处理问题之中。从NLP的演进可以看到,用无标注数据训练模型,生成一般性“常识”逐渐成为主流。人工不可能标注海量信息,目前,人们正试图使用更多知识和分析方法处理信息,并将知识融入模型结构,使人与工具更好地结合,并生成更加可控的模型。