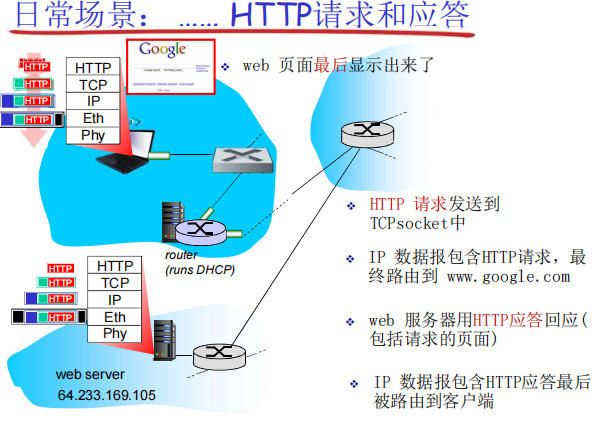
常用大数据框架结构

1.大数据测试常用到的软件工具
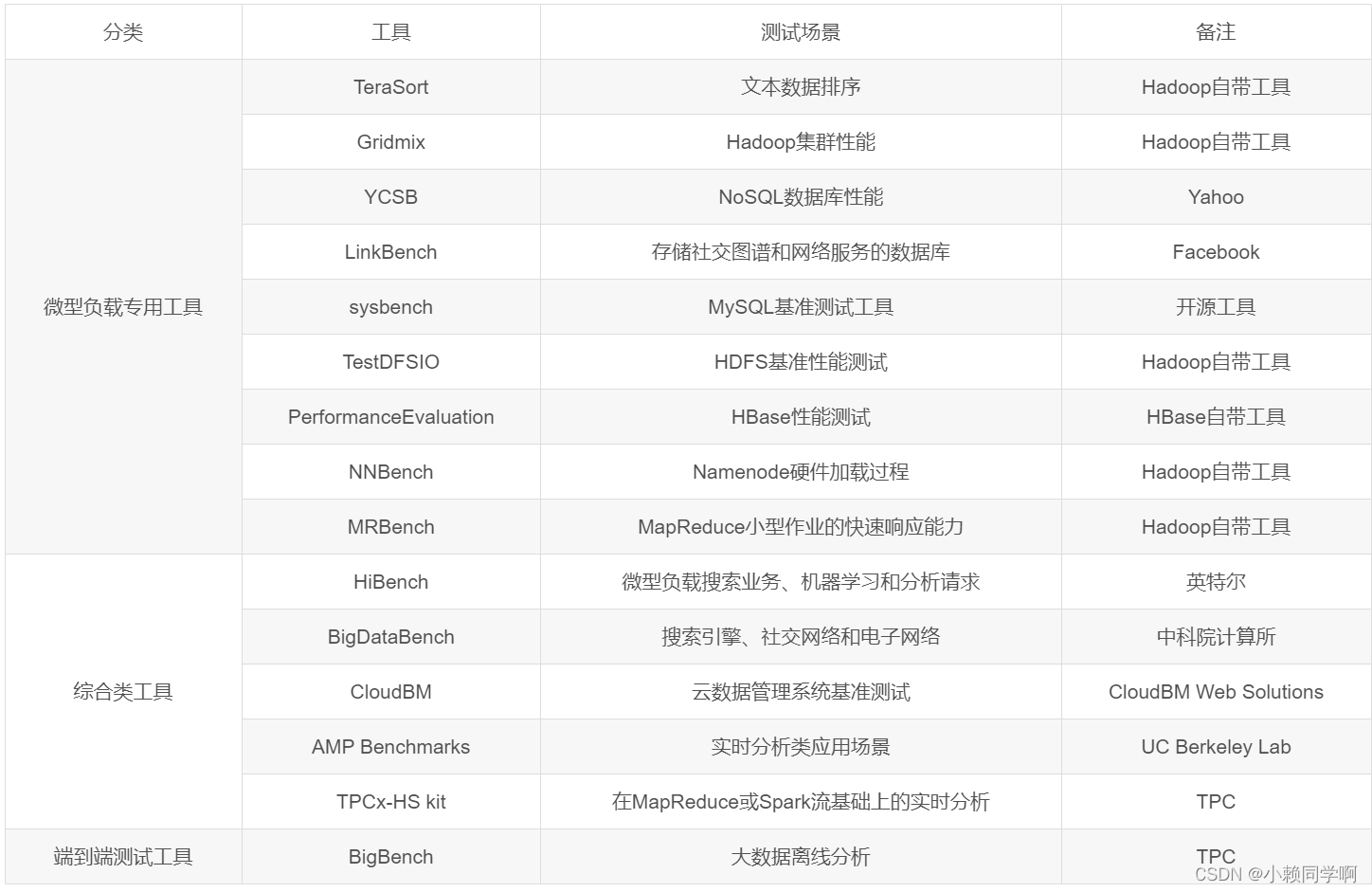
工具推荐,对于测试数据构造工具有:Datafaker、DbSchema、Online test data generator等;ETL测试工具有:RightData、QuerySurge等;数据质量检查工具:great_expectations、mobyDQ、DataQuality、GriFFin、Qualitis等。
大数据生态圈


1.基于hadoop的大数据生态圈
2.基于大数据生态圈平台
3.基于大数据搜索引擎
如果需要实现大数据生态圈平台化,不用单独搭建每个服务,则采用
• CDH5.4
http://archive.cloudera.com/cdh5/
•Cloudera Manager5.4.3:
http://www.cloudera.com/downloads/manager/5-4-3.html
快速编写测试用例
1.对齐测试用例需求
用例文档使用者:测试人员
用例文档范围:覆盖产品所有需求
用例模板内容:编号、模块、子模块、测试功能点、预置条件、数据、步骤、预期结果、优先级、用例类型、关联需求、(编写人、更新时间、执行人、状态、执行时间、执行结果)
测试用例粒度:所有功能的正反用例
测试用例验收负责人:活久见(对齐目标)
快速了解产品
横向业务扩展
纵向架构分层
以某云的大数据云平台为例,大数据云平台的核心是集群。大数据云平台集群是由一个或多个虚拟机实例组成的Hadoop、Flink、ZooKeeper集群。以Hadoop为例,每个虚拟机实例上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager和NodeManager),集群上还可安装各类大数据服务组件(例如:HBase、Hive、Presto、Spark等)。
大数据云平台的横向核心业务功能全景线路图(以Hadoop集群为例),其核心流程有:Hadoop集群创建->集群管理->大数据组件管理->虚拟主机管理-> ... ->Hadoop集群释放;功能全景如图1所示:

用例覆盖范围
1、 从产品业务功能全景出发,围绕PRD(Product Requirement Document)、结合纵向架构层次,用例无死角全面覆盖产品(论范围)。
(1)水平方向拓宽【宽度】,围绕它的产品的主生命周期由大模块至小模块、主功能至次要功能逐步扩展支叶,借用鱼骨图梳理或Xmind脑图来整理。先梳理内部,然后梳理外部对接的服务或产品场景(如:消息中心、费用中心、告警中心、文档中心、数据开发等等)。
2)横向扩展发散完成后,开始纵向挖掘【深度】,比如,大数据云平台核心架构分为四层,每一层都需要拆开了看:
-
最顶层:UI层端对端用例走查(如前面所述),从顶层UI操作测试除了验UI结果、还要确保底层集群服务器上的实际结果与界面显示一致
-
次顶层:第二层是门户后端Api,直接调用OpenApi的相关测试用例覆盖
-
次底层:直接操作使用或强干预Hadoop集群服务组件、检验整个大数据云平台的质量;由于大数据平台上的服务组件非常多(有三十多),除了单个服务使用外,更要多个常用服务组件搭配组合验证。
-
最底层:直接操作使用或强干预服务器层(增、删、停、重启、扩、缩、升、网络、磁盘、软件配置等),检验整个大数据云平台的质量
用例设计方法
从测试类型出发,有功能与非功能测试用例覆盖。本次不需要交付非功能用例,因此不展开;功能性用例设计方法:
-
等价类划分法(正等价类、负等价类)
-
边界值分析法(边界内、边界外)
-
判定表分析法
-
因果图
-
错误推测法
用例编写原则
-
拆分原则: 全文制定统一的边界。比如:以模块为边界、当不同模块之间有关联互动时、预置条件作为分界线,预置条件里的内容放在上游模块验证。
-
优先级原则: 【创建】【查看】【使用(启停等)】【修改】【删除】为序 【主场景】优先、【次要场景】其次 【正例】优先、【反例】其次
制定统一标准
以某云大数据云平台产品为例,很多需求功能统一要求,为此设计一套标准化用例:
比如: 创建新增的页面,表单输入项,需求约束统一要求(是否必填、长度限制、字符要求),设计一套标准化用例,供其他页面复用。
比如:每个模块的权限测试用例,设计统一标准用例;
比如:所有的OpenApi测试,都是针对返回码200、400、401、403、405、500的场景测试;
比如:大数据平台服务30多个,每个服务是不同的,但操作是类似:添加、启动、停止、修改配置、部署,为此设计统一标准用例 (此刻你是否有一种代码重构的既视感,定义一个标准的方法、供大家反复调用)。
前边提到过设计了多套统一标准用例,新的页面复用时,直接替换变量内容,生成当前用例。又或者需求变更的刚好是统一标准用例的内容,活用全文查找替换、一分钟搞定用例维护。
总之,必须要总结一套自己的方法来应对这么庞大的编写工作量,否则在短期的时间内无法完工。而高效编写用例的秒招,离不开可复用、找共性、提炼统一标准,借用一些手段或工具自动生成。
以某云大数据云平台产品为例,其中包含了10个以上的列表页面,对于每个列表都有分页组件、筛选、搜索、排序,这些公共组件的用例抽为【公共组件用例】,设计一套标准化用例,相关页面复用即可。
注意:统一标准用例中,可变的项用{ABC}来替换,比如:在集群查看列表中筛选集群状态时,把统一标准用例中的{ABC}替换成{集群状态}即可。
批量编写与自动生成
在用例编写过程中,发现很多情况除了{某名称或字段}不同,其它都是一样的,此时可以批量编写(如:借助Sublime或直接传变量用代码生成),这样也可以大大提高编写效率。
在编写OpenApi相关测试用例时,直接定义出一套OpenApi标准用例,以QA设计出的标准用例为模板,然后编写代码生成用例,通过读取OpenApi的Json文件,快速生成71个Api的测试用例,近1000条详细测试用例,高效。
活用全文替换
编写用例时,QA人员一定要用统一语言文字或格式,一来是给阅读的人方便、二来是方便查找替换,即通过全文查找替换能 快速维护用例。
有一次需求变更:由原来的一级菜单A001下二级菜单B002,变为了一级C001下D002;由于在整个产品的用例中,从一级菜单进入二级菜单,全部都使用:A001->B002这种格式,本次需求变更,直接全文查找替换一鍵完成。
提效手段
以上的测试实践活动,帮助团队把控质量,即"保质"。其实,测试增加,必然拉低整体速率。那么,如何使的团队不降质量标准的前提下,高效开发与测试?即"保质"的同时还要"保量"?
避免返工
前面介绍敏捷QA实践活动为得就是尽早参与、提前发现问题、预防缺陷,避免返工,从而达到高效开发。
工具代替人工(即自动化代替手动)
在项目中,开发人员的数据建模处理、指标开发、指标管理应用发布、标签API发布、数据监控,这些功能都是研发同学提炼工具,由工具自动生成代码,完成开发。大大节约了项目时间,提高了开发速度。
特别提一下EXCEL自动化测试工具(详细参见廖光明的博客文章《数据集成测试支持工具》数据集成测试支持工具 - 知乎),可以用一页EXCEL即可完成所有的数据测试用例的构造。大家都知道数据项目构建数据集是一个费时费力的活儿。有了这个EXCEL编写测试数据的工具,团队的UT大大节约了时间。
-
-
提高复用、减少重复
项目开发过程中,相同的代码逻辑抽取公共片断或者合理分层(输出中间表),这样避免相同的业务逻辑开发重复和重复测试。比如:同类指标的维度计算都是相同的,抽取了公共的维度代码片断,针对公共代码片断进行了测试验证,即使之后业务有变动,修改一处代码即可。 -
精准抽样
构建测试数据时,精准抽样测试。一条测试数据精准覆盖一个逻辑,避免重复用例的构造。在Review UT时,经常发现有重复场景,会提醒大家及时删除重复用例。多余的用例没有价值反而还会造成干扰至少随时用例的增多,运行速度也会影响。 -
数据报告
通过data filling生成数据报告,大多数据探索Checklist的结果通过数据报告即可拿到,减少人工探索的成本。 -
ETL测试
ETL测试通过有以下几种测试类型:
1.表数据量对比测试
通过对比处理前后的数据量变化,验证ETL开发过程中是否有代码错误导致数据丢失,这种直接对比量表数据量的比较适用数据仓库底层仅做数据过滤和数据转化时,不太适合聚合过程的测试。
2.统计值总量对比测试
这种测试方法适用于对部分表进行聚合统计前后做数据无损验证。举个例子,挖掘同学在挖掘购物偏好时一般会向ETL同学提交需求,要求把源数据零散的查看和购买等行为聚合统计为某类目在一天内的访问、购买次数,这种情况由于聚合过程存在,源表和结果表数据量必然不同,此时可通过统计源表的数量总量对比结果表SUM(行为次数)的方式来确保聚合过程中是否有数据量损失。
部分聚合统计过程可能缺失存在正常的损失数据,这种情况下也需要对比源表和结果表数据,分析这种损失是否合理。
3.数据清洗测试
这种情况首先需要分析出那些数据是异常数据,举一些例子:ip、imei、邮箱、mac地址等这些信息本身是有规则的,可以考虑使用对应的正则来判断是否存在符合相应规范,不符合的数据视为异常数据清洗掉,又如部分数据中存在明显的乱码等数也是属于异常数据,测试过程可通过统计源表符合规则的数据总量和结果表的数据量对比,判断数据异常数据是否过滤正常
4.数据转化测试
由于各业务的数据源对于各种字段的格式并不统一,所以数仓在ETL开发过程中会对字段的格式做统一处理。例如时间字段,有些业务使用时间戳,有些业务使用日期时间格式,这些数据数仓会按照数仓定义的规范做相关数据转化,测试过程可通过极值、平均值且对比源表数据的方式验证转化是否正确。
5.枚举字段验证(例如:年龄、性别、学历、职业)等:
枚举字段主要验证两方面:通过group by 找出全部枚举值,判断枚举分布是否符合常识(如大姨妈类软件男女比为8比2,通过认为违背常识)、是否存在异常枚举(异常枚举需过滤);验证ETL开发过程是否将各业务各自定义枚举值是否映射为数仓标准的枚举值,如将某业务性别的中的0,1,2分别映射为F,M,null
6.敏感字段加密验证
验证敏感信息是否有做加密操作,加密后的数据是否可正常解密等
7.数字字段的极值验证
验证部分数值字段最大最小平均值等,是否符合常识,比如商品收藏数为负数,通常这种数据需过滤
8.抽样测试验证
9.字段逻辑验证
通过字段本身一些互斥属性也可以发现部分数据源异常或者ETL开发过程中导致的异常,举例如下:
枚举类型的字段查看枚举分布:
性别分布:查看性别分布,根据产品用户人员的特点分析性别是否合理
地域分布:查看网民的省份分布,省份分布可以参考网上的中国网民省份排名
活跃小时段:一般来说大部分产品凌晨用户不太活跃,活跃时间也有规律,要结合具体产品(如办公产品应该是上班时间活跃,休闲产品午休时间可能更活跃)
年龄分布:90年后的用户应该是个峰值
学历比例:结合社会情况看
操作系统:安卓 ios pc结合实际产品应该有合理的比例
字段本身的逻辑性:
购物订单本身不应该同一时间出现多次
统计数:通过查看数量判断正常否,比如一天购物次数如果超过100,是不是需要查下是不是正常
新闻类目、音乐歌手和语种、考拉类目和品牌被用户触发的总次数排行,可以结合实际情况看看是否合理
手机设备、汽车、美妆、家电的品牌和型号可以看被触达的排行,结合实际情况分析是否合理
有多个设备(或车)的id占总id数的比例(理论上有但是不应该太高)
字段之间的逻辑关系:
ip和城市对应关系
订单的商品单价和订单总价的计算关系
七天活跃城市和30天活跃城市相等的数量占总用户数的比例,一般来说这种比例应该很高,只有少数出差的人才会是不同的
设备型号和设备品牌的对应关系抽查
车型号和车品牌的对应关系抽查
字段之间的互斥关系:
地域与时间互斥:如同一个时间在不同城市
职业和年龄互斥:比如学生一般小于25
年龄和是否有小孩:18岁一下一般不会有小孩儿三.数据监控
测试上线完成后,集群会对相关任务进行日常调度刷数据,由于网络、传输等各个环节都可能出问题从而导致数据跑不出来,所以已上线的表需要通过监控的方式来保证后续的数据正常。
数据监控可以考虑通过使用hive提供的原生接口,开发一些内部的工具进行相关监控。 -
大数据性能测试工具-YCSB · TesterHome
-
大屏驾驶舱
-
(4)数据同步之道(Sqoop、dataX、Kettle、Canal、StreamSets)
https://www.modb.pro/db/86290(1)数据抽取工具比对:Kettle、Datax、Sqoop、StreamSets
https://blog.csdn.net/xiaozm1223/article/details/89670460(2)ETL学习总结(2)——ETL数据集成工具之kettle、sqoop、datax、streamSets 比较
https://zhanghaiyang.blog.csdn.net/article/details/104446610(3)数据集成工具Kettle、Sqoop、DataX的比较
https://www.cnblogs.com/bayu/articles/13335917.html(5)Datax与Sqoop的对比
https://blog.csdn.net/lzhcoder/article/details/107902791(6)Datax和Kettle的对比
https://blog.csdn.net/lzhcoder/article/details/120830522(7)超详细的Canal入门,看这篇就够了!
https://blog.csdn.net/yehongzhi1994/article/details/107880162让人眼前一亮的数据分析的报告,竟可自动生成啊_报告自动生成_Python数据挖掘的博客-CSDN博客
-
GitHub: https://github.com/pandas-profiling/pandas-profiling
-