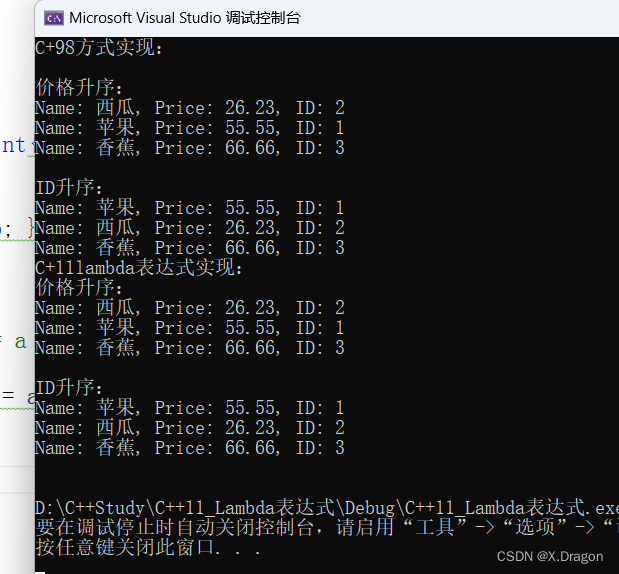
一.MQ概述
1.简介
MQ,Message Queue,是一种提供消息队列服务的中间件,也称为消息中间件,是一套提供了消息生产、存储、消费全过程API的软件系统。消息即数据。一般消息的体量不会很大。
2.用途
限流削峰
MQ可以将系统的超量请求暂存其中,以便系统后期可以慢慢进行处理,从而避免了请求的丢失或系统 被压垮。

异步解耦
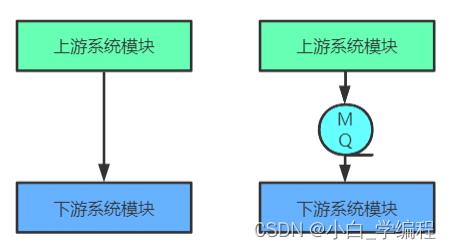
上游系统对下游系统的调用若为同步调用,则会大大降低系统的吞吐量与并发度,且系统耦合度太高。而异步调用则会解决这些问题。所以两层之间若要实现由同步到异步的转化,一般性做法就是,在这两层间添加一个MQ层
数据收集
分布式系统会产生海量级数据流,如:业务日志、监控数据、用户行为等。针对这些数据流进行实时或批量采集汇总,然后对这些数据流进行大数据分析,这是当前互联网平台的必备技术。通过MQ完成此类数据收集是最好的选择。(如Kafka)
3.MQ对比

二. RocketMQ概述
1.基本概念
消息(Message)
消息是指,消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题。
主题(Topic)
Topic表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。
标签(Tag)
为消息设置的标签,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
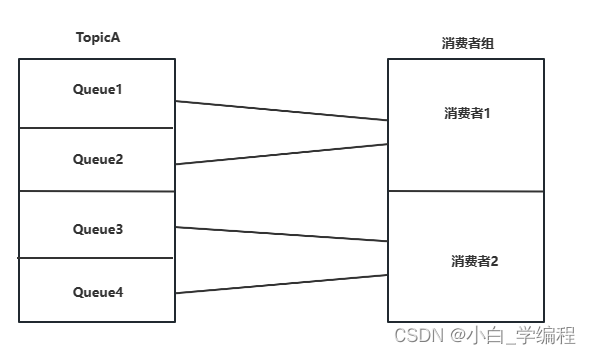
队列(Queue)
存储消息的物理实体。一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
一个 Topic 的 Queue 中的消息只能被一个消费者组中的一个消费者消费。一个Queue中的消息不允许同一个消费者组中的多个消费者同时消费。
补充:
分片不同于分区。在RocketMQ中,分片指的是存放相应Topic的Broker。每个分片中会创建出相应数量的分区,即Queue,每个Queue的大小都是相同的。

消息标识(MessageId/Key)
RocketMQ中每个消息拥有自己的MessageId,且可以携带具有业务标识的Key,以方便对消息的查询。MessageId有两个:
- 在生产者send()消息时会自动生成一个MessageId(msgId)
- 当消息到达Broker后,Broker也会自动生成一个MessageId(offsetMsgId)。
msgId、offsetMsgId与key都称为消息标识。
- msgId:由producer端生成,其生成规则为:producerIp + 进程pid + MessageClientIDSetter类的ClassLoader的hashCode +当前时间 + AutomicInteger自增计数器。[重复概率较低]
- offsetMsgId:由broker端生成,其生成规则为:brokerIp + 物理分区的offset(Queue中的偏移量) [重复概率较高]
- key:由用户指定的业务相关的唯一标识。[用户可控制不重复]
2.系统架构
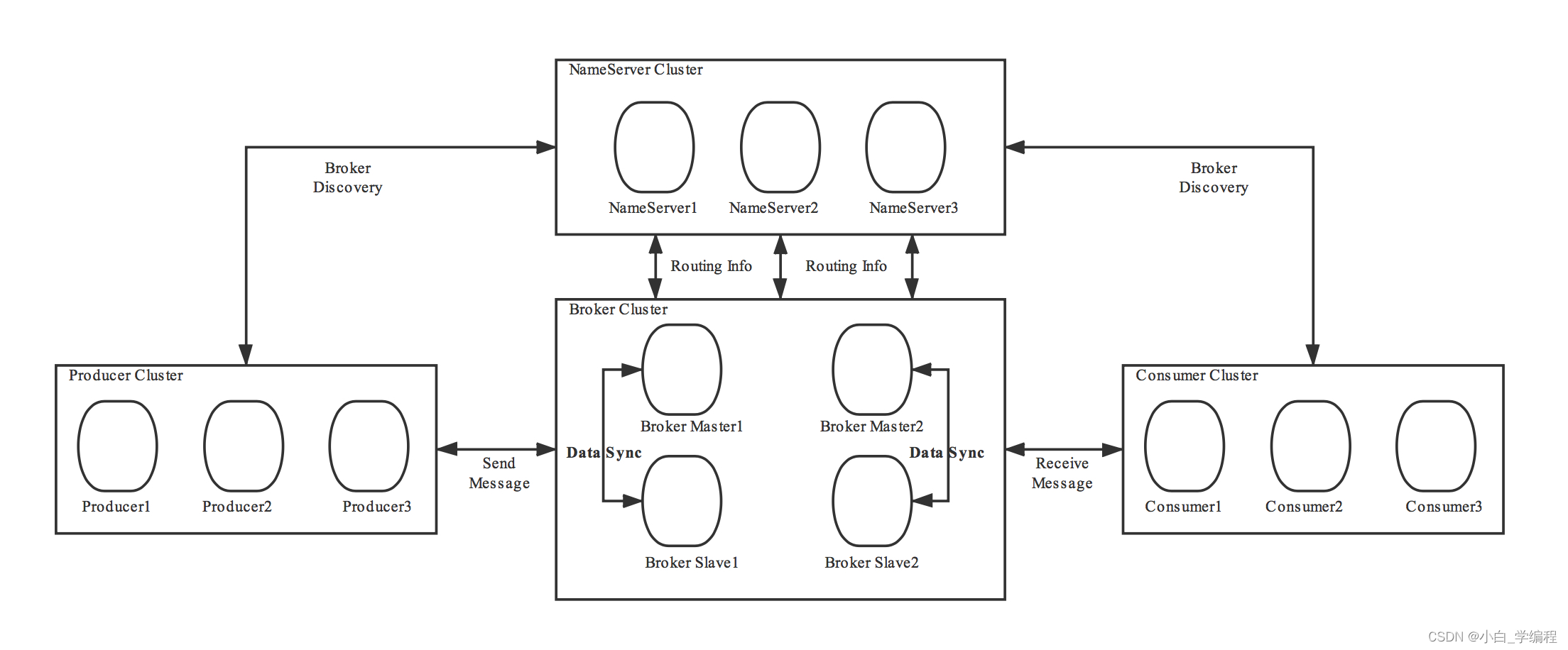
RocketMQ架构上主要分为四部分构成:
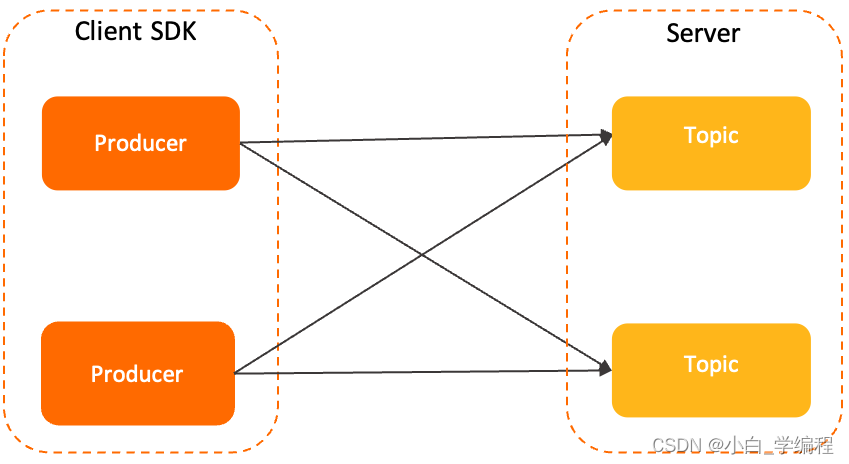
Producer
消息生产者,负责生产消息。Producer通过MQ的负载均衡模块选择相应的Broker集群队列(先选择Broker,再选择队列)进行消息投递,投递的过程支持快速失败并且低延迟。
RocketMQ中的消息生产者都是以生产者组(ProducerGroup)的形式出现的。一个生产者组可以同时发送多个主题的消息。
Consumer
消息消费者,负责消费消息。一个消息消费者会从Broker服务器中获取到消息,并对消息进行相关业务处理。
RocketMQ中的消息消费者都是以消费者组(ConsumerGroup)的形式出现的。消费者组是同一类消费者的集合,这类Consumer消费的是同一个Topic类型的消息。消费者组使得在消息消费方面,容易实现
- 负载均衡(将一个Topic中的不同的Queue平均分配给同一个ConsumerGroup的不同的Consumer,注意,并不是将消息负载均衡)
- 容错(一个Consmer挂了,该ConsumerGroup中的其它Consumer可以接着消费原Consumer消费的Queue)
注意:

- 消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的Consumer将不能消费消息。
- 一个Topic类型的消息可以被多个消费者组同时消费
- 消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息
- 消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息
NameServer
NameServer是一个Broker与Topic路由的注册中心,支持Broker的动态注册与发现。
主要包括两个功能:
- Broker管理:接受Broker集群的注册信息并且保存下来作为路由信息的基本数据;提供心跳检测机制,检查Broker是否还存活。
- 路由信息管理:每个NameServer中都保存着Broker集群的整个路由信息和用于客户端查询的队列信息。Producer和Conumser通过NameServer可以获取整个Broker集群的路由信息,从而进行消息的投递和消费。
①路由注册
NameServer通常也是以集群的方式部署,不过,NameServer是无状态的,即NameServer集群中的各个节点间是无差异的,各节点间相互不进行信息通讯。
各节点的数据同步:在Broker节点启动时,轮询NameServer列表,与每个NameServer节点建立长连接,发起注册请求。在NameServer内部维护着⼀个Broker列表,用来动态存储Broker的信息。
注意:NameServer的无状态特性使得它和ZooKeeper、Eureka、Nacos等注册中心不同
- 优点:NameServer集群搭建简单,扩容简单。
- 缺点:对于Broker,必须明确指出所有NameServer地址。否则未指出的将不会去注册。也正因 为如此,NameServer并不能随便扩容。因为,若Broker不重新配置,新增的NameServer对于 Broker来说是不可见的,其不会向这个NameServer进行注册。
Broker节点为了证明自己是活着的,为了维护与NameServer间的长连接,会将最新的信息以心跳包的方式上报给NameServer,每30秒发送一次心跳。心跳包中包含BrokerId、Broker地址(IP+Port)、 Broker名称、Broker所属集群名称等等。NameServer在接收到心跳包后,会更新心跳时间戳,记录这个Broker的最新存活时间。
②路由剔除
由于Broker关机、宕机或网络抖动等原因,NameServer没有收到Broker的心跳,NameServer可能会将其从Broker列表中剔除。
NameServer中有⼀个定时任务,每隔10秒就会扫描⼀次Broker表,查看每一个Broker的最新心跳时间戳距离当前时间是否超过120秒,如果超过,则会判定Broker失效,然后将其从Broker列表中剔除。
③路由发现
RocketMQ的路由发现采用的是Pull模型。当Topic路由信息出现变化时,NameServer不会主动推送给 客户端,而是客户端定时拉取主题最新的路由。默认客户端每30秒会拉取一次最新的路由。
补充:
- Push模型:推送模型。其实时性较好,是一个“发布-订阅”模型,需要维护一个长连接。而 长连接的维护是需要资源成本的。该模型适合于的场景
- Pull模型:拉取模型。存在的问题是,实时性较差
- Long Polling模型:长轮询模型。客户端发起请求后,服务端不会立即返回请求结果,而是将请求挂起等待一段时间,如果此段时间内服务端数据变更,立即响应客户端请求,若是一直无变化则等到指定的超时时间后响应请求,客户端重新发起长链接。

其是对Push与Pull模型的整合,充分利用了这两种模型的优 势,屏蔽了它们的劣势。
④客户端NameServer选择策略
这里的客户端指的是Producer与Consumer
客户端在配置时必须要写上NameServer集群的地址
客户端首先会生产一个随机数,然后再与NameServer节点数量取模,此时得到的就是所要连接的 节点索引,然后就会进行连接。如果连接失败,则会采用round-robin策略,逐个尝试着去连接其它节 点。 首先采用的是随机策略进行的选择,失败后采用的是轮询策略。
客户端首先采用的是随机策略进行的选择,失败后采用的是轮询策略。
Broker
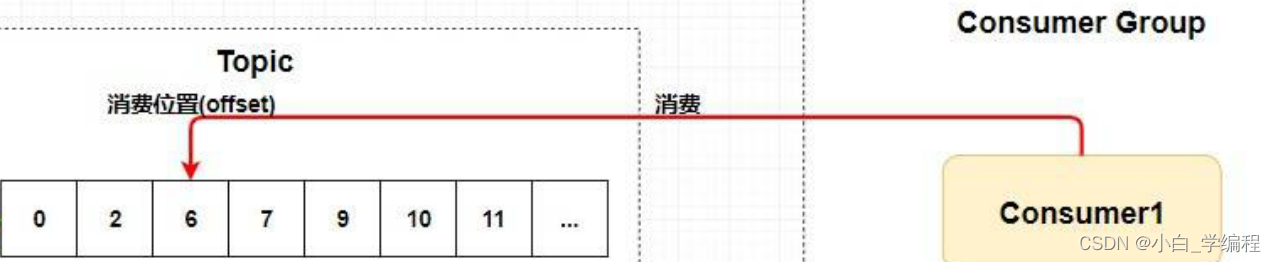
Broker充当着消息的中转角色,负责存储消息、转发消息。Broker在RocketMQ系统中负责接收并存储从 生产者发送来的消息,同时为消费者的拉取请求作准备。Broker同时也存储着消息相关的元数据,包括 消费者组消费进度偏移offset、主题、队列等。
①模块构成
Broker Server的功能模块示意图:

RemotingModule:整个Broker的实体,负责处理来自clients端的请求。而这个Broker实体则由以下模块构成:
- ClientManager:客户端管理器。负责接收、解析客户端(Producer/Consumer)请求,管理客户端。例 如,维护Consumer的Topic订阅信息
- StoreService:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘和消息查询功能。
- HAService:高可用服务。提供MasterBroker和SlaveBroker之间的数据同步功能。(主从集群)
- IndexService:索引服务。根据特定的Messagekey,对投递到Broker的消息进行索引服务,同时也提供根据MessageKey对消息进行快速查询的功能。
②集群部署(解决单点故障)
将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。所以这个Broker集群是主备集群。
一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。Master与Slave的对应关系是通过指定相同的BrokerName、不同的BrokerId来确定的。BrokerId为0表示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
工作流程
①具体流程
1)启动NameServer,NameServer启动后开始监听端口,等待Broker、Producer、Consumer连接。
2)启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后每30秒向NameServer定时发送心跳包。
3)发送消息前,可以先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,当然,在创建Topic时也会将Topic与Broker的关系写入到NameServer中。不过,这步是可选的,也可以在发送消息时自动创建Topic。
补充:Topic的创建模式
手动创建Topic时,有两种模式:
- 集群模式:该模式下创建的Topic在该集群中,所有Broker中的Queue数量是相同的
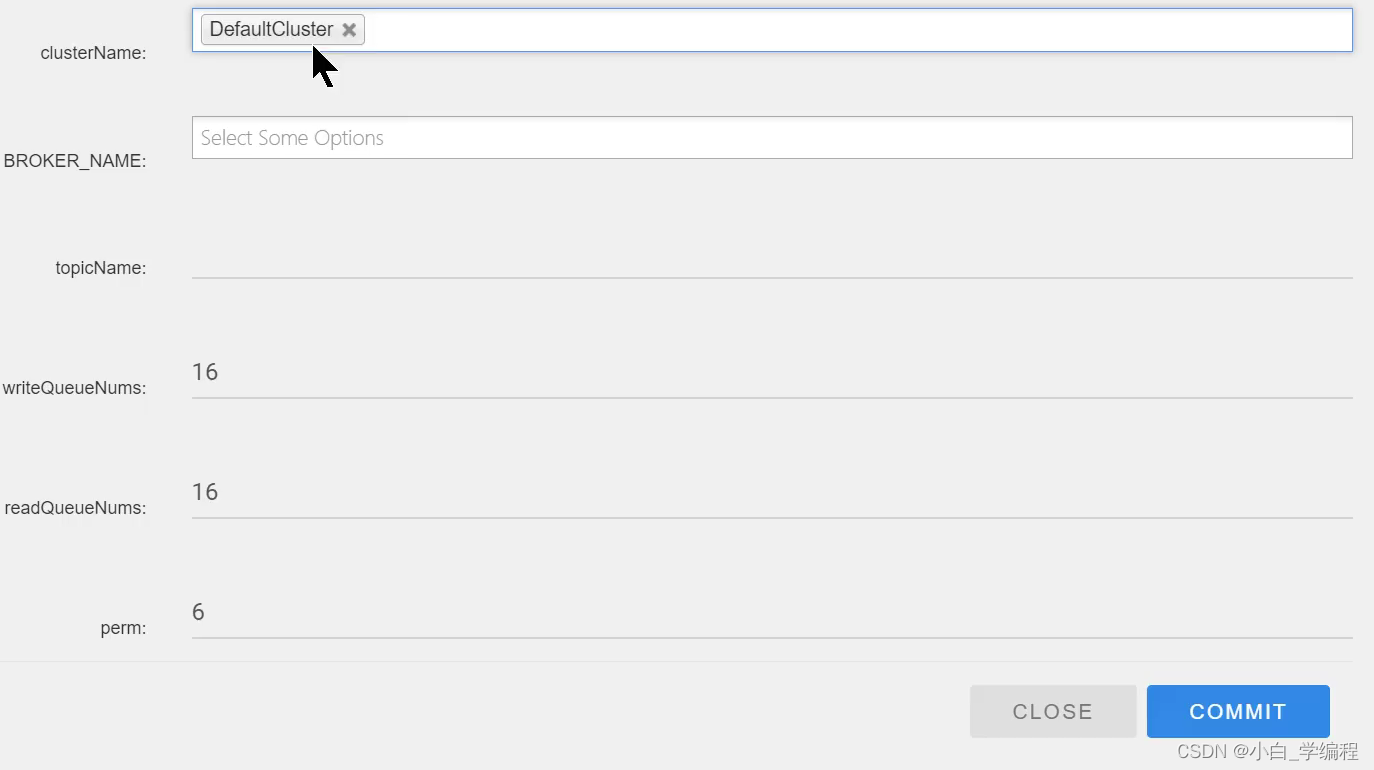
- Broker模式:该模式下创建的Topic在该集群中,每个Broker中的Queue数量可以不同
自动创建Topic时,默认采用的是Broker模式,会为每个Broker默认创建4个Queue
②读写队列
从物理上来讲,读/写队列是同一个队列。所以,不存在读/写队列数据同步问题。读/写队列是逻辑上进行区分的概念。一般情况下,读/写队列数量是相同的。
- 当写队列多于读队列时:例如,创建Topic时设置的写队列数量为8,读队列数量为4,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到这8个队列,但Consumer只会消费0 1 2 3 这4个队列中的消息,4 5 6 7 中的消息是不会被消费到的。
- 当读队列多于写队列时:例如,创建Topic时设置的写队列数量为4,读队列数量为8,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到0 1 2 3这4个队列,但Consumer只会消费0 1 2 3 4 5 6 7这8个队列中的消息,但是4 5 6 7中是没有消息的。此时假设ConsumerGroup中包含两个Consuer,Consumer1消费0 1 2 3,而Consumer2消费4 5 6 7。但实际情况是,Consumer2是没有消息可消费的。
也就是说,当读/写队列数量设置不同时,总是有问题的
那为什么还要这样设计呢?
为了方便Topic的Queue的缩容。例如,原来创建的Topic中包含16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息?
可以先动态修改写队列数量为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是 16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列数量动态设置为8。整个缩容过程,没有丢失任何消息。