一、题目描述
小华负责公司知识图谱产品,现在要通过新词挖掘完善知识图谱。
新词挖掘: 给出一个待挖掘文本内容字符串Content和一个词的字符串word,找到content中所有word的新词。
新词:使用词word的字符排列形成的字符串。
请帮小华实现新词挖掘,返回发现的新词的数量。
二、输入描述
第一行输入为待挖掘的文本内容content
第二行输入为词word
三、输出描述
在中找到的所有word的新词的数量
四、解题思路
- 首先读取输入的待挖掘的文本内容 content 和词 word;
- 将词 word 转换为字符数组,并对字符数组进行排序,得到排好序的字符串 wordStr;
- 获取词 word 的长度 len;
- 初始化变量 count 为 0,用于记录新词的数量;
- 如果待挖掘文本内容的长度小于词的长度,则直接输出 count,表示没有新词;
- 使用循环从 0 到 line.length()-len,依次截取与词长度相等的子串进行处理:
- 计算子串的结束位置 j;
- 将子串转换为字符数组,并对字符数组进行排序,得到排好序的字符串 str2;
- 如果 str2 与 wordStr 相等,则说明找到了一个新词,将 count 加一;
- 输出 count,即为发现的新词的数量;
五、JavaScript算法源码
function findNewWords(content, word) {
// 将词 word 转换为字符数组,并对字符数组进行排序,得到排好序的字符串 wordStr
const arr = word.split('');
arr.sort();
const wordStr = arr.join('');
// 获取词 word 的长度 len
const len = word.length;
// 记录新词的数量
let count = 0;
// 待挖掘文本内容的长度小于词的长度,表示没有新词
if (content.length < len) {
return count;
}
for (let i = 0; i <= content.length - len; i++) {
const j = i + len;
// 依次截取与词长度相等的子串进行处理
const str = content.substring(i, j);
const chars = str.split('');
chars.sort();
// 将子串转换为字符数组,并对字符数组进行排序,得到排好序的字符串 str2
const str2 = chars.join('');
if (str2 === wordStr) {
count++;
}
}
// 发现的新词的数量
return count;
}
六、效果展示
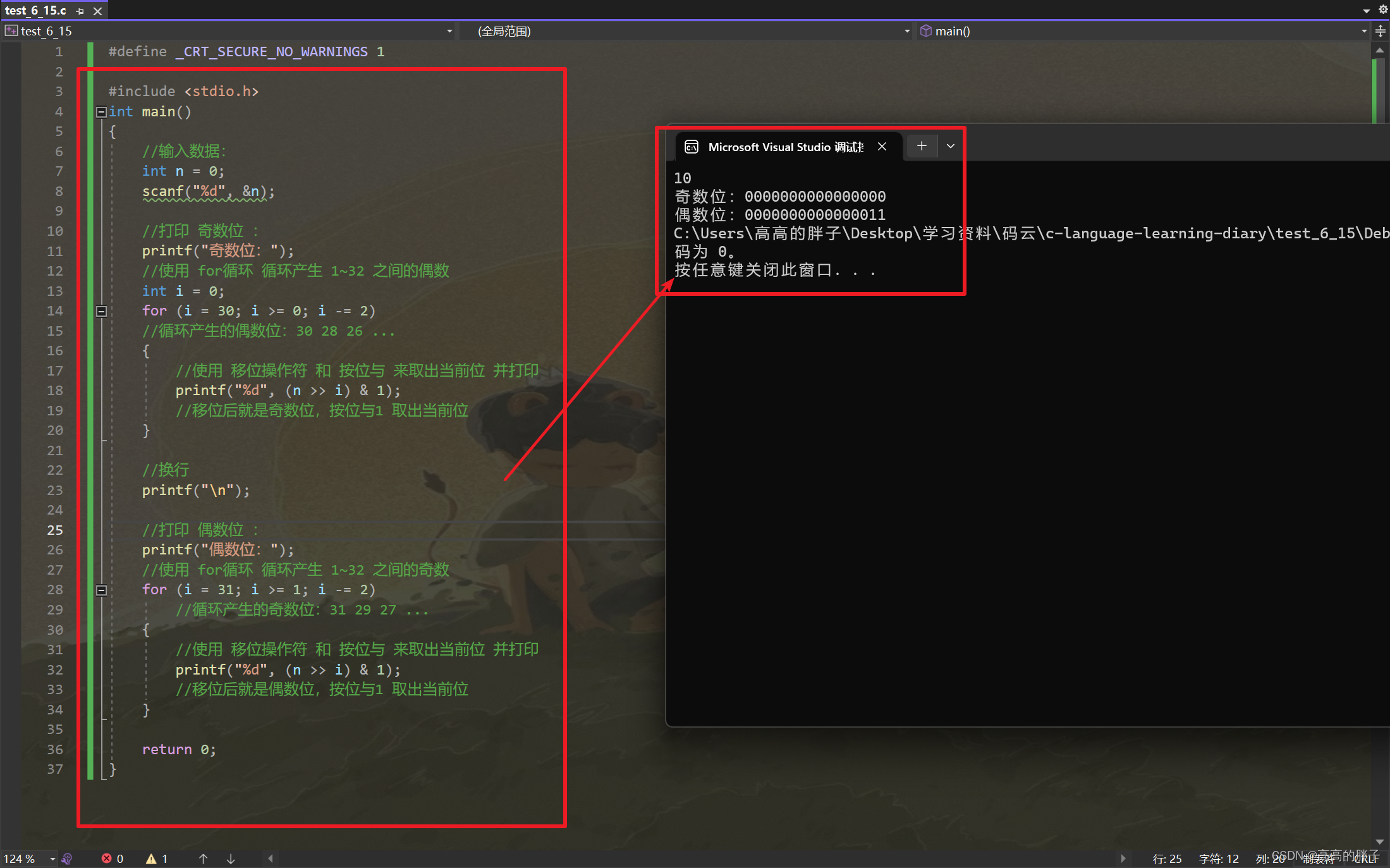
1、输入
nezhastudyjavaahz
zha
2、输出
2
3、说明
zha是zha的新词;
ahz是zha的新词;

🏆下一篇:华为OD机试真题 JavaScript 实现【相对开音节】【2022Q4 100分】,附详细解题思路
🏆本文收录于,华为OD机试(JavaScript)真题(A卷+B卷)
每一题都有详细的答题思路、详细的代码注释、样例测试,订阅后,专栏内的文章都可看,可加入华为OD刷题群(私信即可),发现新题目,随时更新,全天CSDN在线答疑。