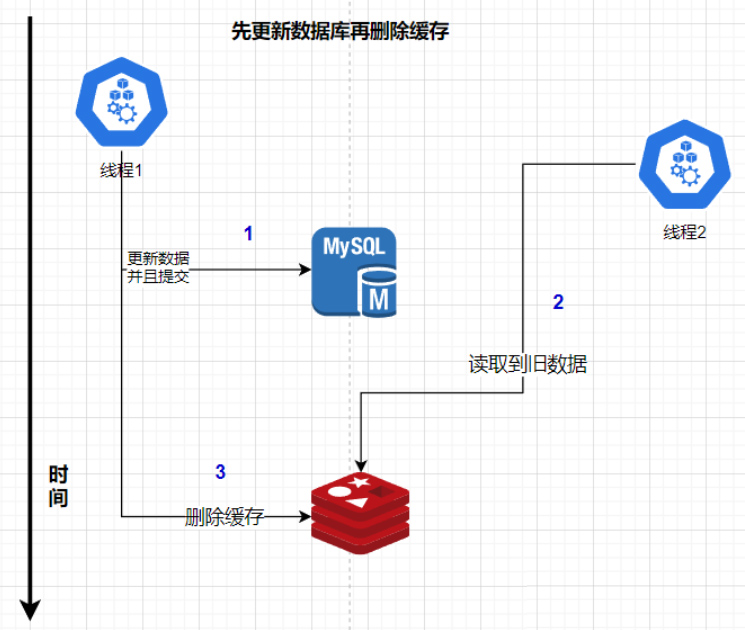
文章目录
- Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers
- 摘要
- 本文方法
- Content-aware token sharing framework
- Content-aware token sharing policy
- 实验结果
Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers
摘要
本文介绍了Content-aware Token Sharing(CTS),这是一种Token 减少方法,可以提高使用视觉转换器(ViTs)的语义分割网络的计算效率。现有的工作已经提出了Token 减少方法来提高基于ViT的图像分类网络的效率,但这些方法并不直接适用于我们在本工作中解决的语义分割。我们观察到,对于语义分割,如果多个图像块包含相同的语义类,则它们可以共享一个Token ,因为它们包含冗余信息。我们的方法通过使用一个高效的、与类无关的策略网络来利用这一点,该策略网络可以预测图像补丁是否包含相同的语义类,并允许它们共享Token 。
代码地址
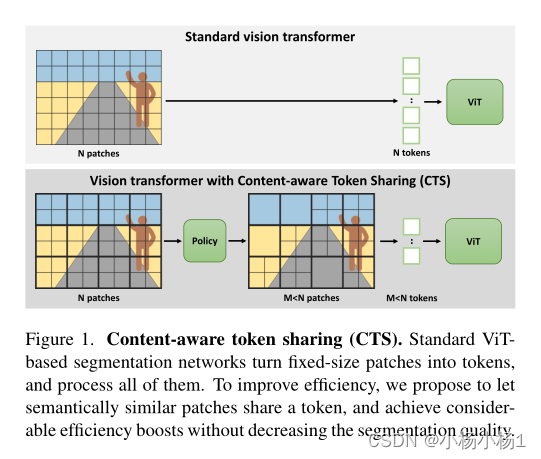
Content-aware Token Sharing(CTS)。基于ViT的标准分割网络将固定大小的patch转换为token,并处理所有这些patch。为了提高效率,我们建议让语义相似的patch共享一个token,并在不降低分割质量的情况下实现相当大的效率提升。
本文方法
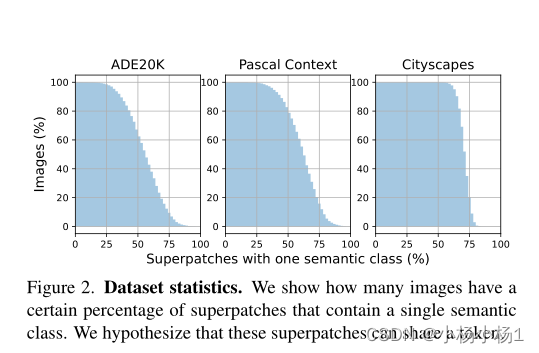
数据集统计信息:展示了有多少图像具有一定百分比的包含单个语义类的超匹配。我们假设这些超级伙伴可以共享一个token。
Content-aware token sharing framework
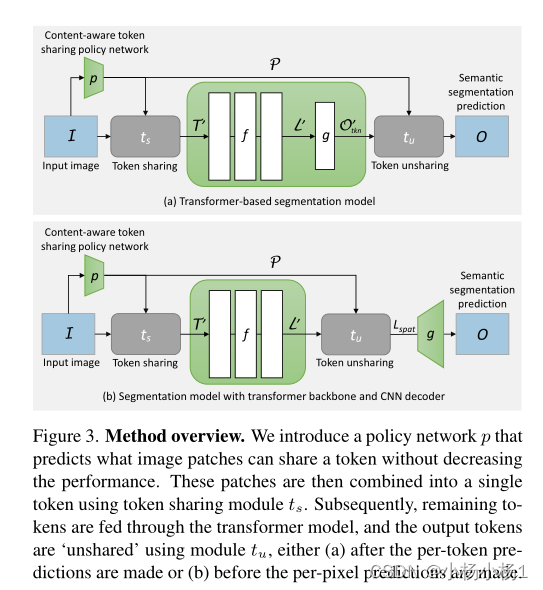
方法概述:
- 引入了一个策略网络p,该网络预测哪些图像patch可以在不降低性能的情况下共享令牌。
- 使用token共享模块ts将这些patch组合为单个令牌。随后,剩余的token通过 transformer模型馈送,并使用模块tu“共享”输出token
- 在进行每个token预测之后或在进行每像素预测之前
Content-aware token sharing policy
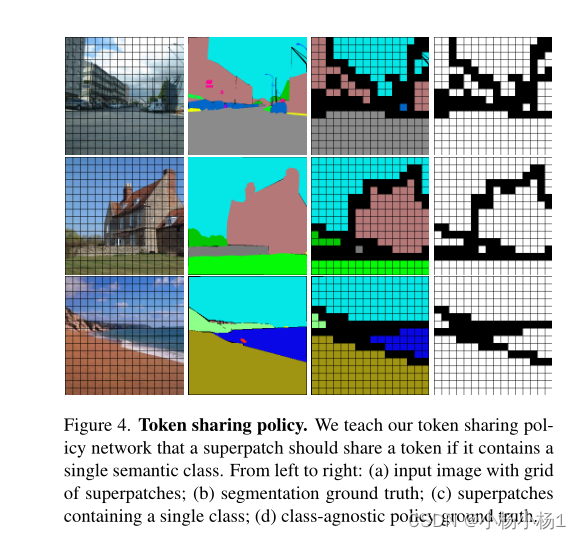
Token sharing policy:我们教导我们的Token sharing policy网络,如果超级patch包含单个语义类,那么它应该共享token
从左到右:(a)具有超级patch网格的输入图像;(b) 分割标签;(c) 包含单个类的超级patch;(d) 类别不可知的标签
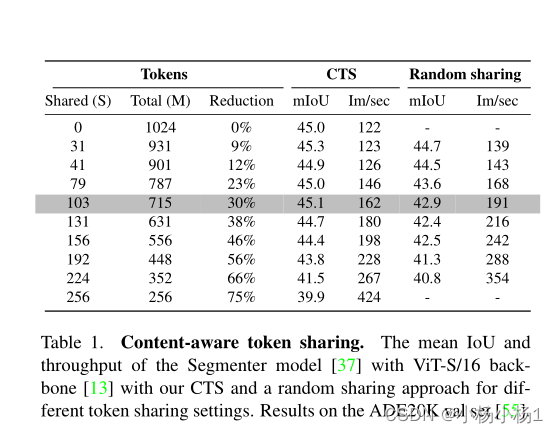
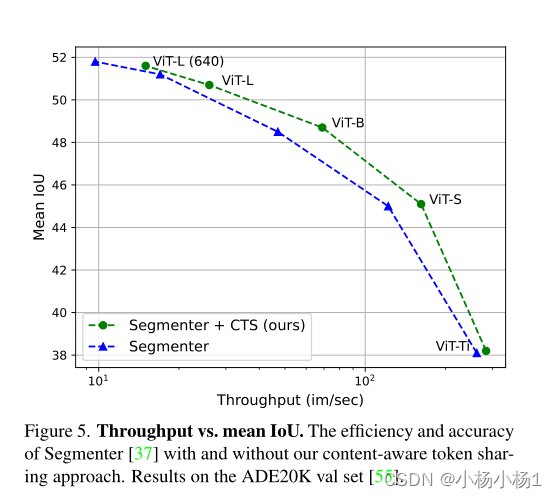
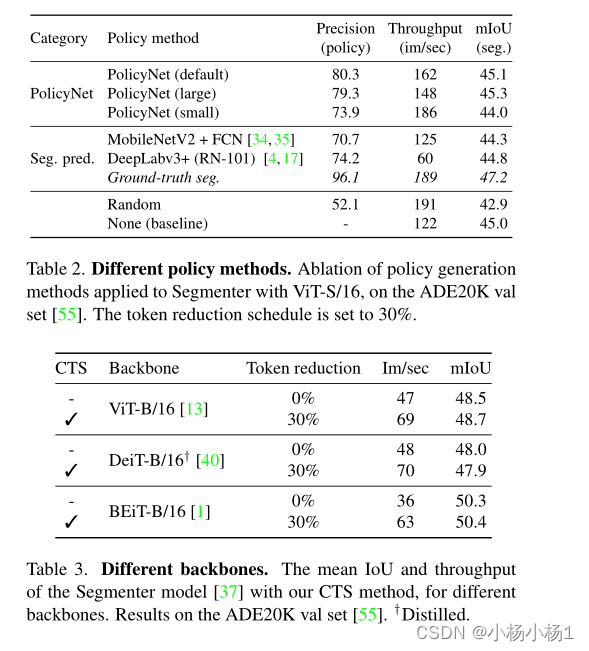
实验结果
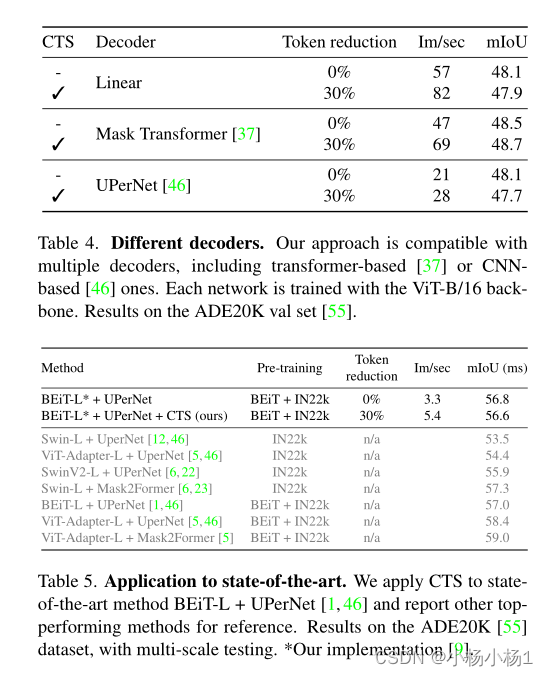
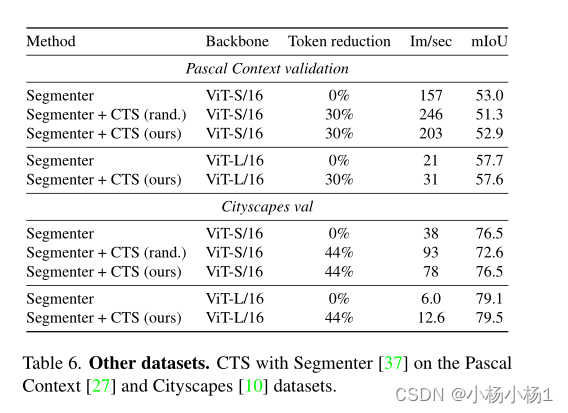












![深度学习应用篇-元学习[15]:基于度量的元学习:SNAIL、RN、PN、MN](https://img-blog.csdnimg.cn/img_convert/d2041142de5a74da65c2ca3c81567fe5.png)