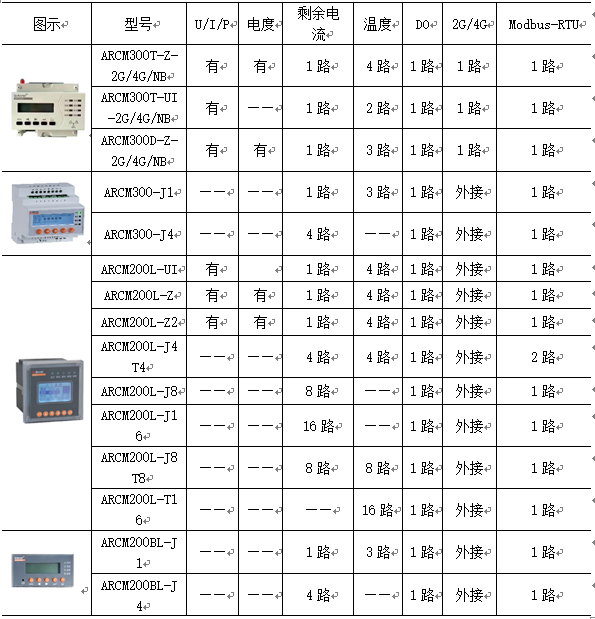
说在前面
在40岁老架构师 尼恩的读者社区(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、美团、极兔、有赞、希音的面试资格,Spring事务源码的面试题,经常遇到:
(1) spring什么情况下进行事务回滚?
(2) spring 事务的传播行为有哪些 ?
与之类似的、其他小伙伴遇到过的问题还有:
读过Spring源码吗?说说Spring事务是怎么实现的?
Spring事务的面试题,绝对是面试的核心重点, 也是核心难点。
这里尼恩给大家做一下系统化、体系化梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V79版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到文末公号【技术自由圈】取
文章目录
- 说在前面
- 什么是数据库事务
- 数据库事务的 ACID 四大特性
- 1、Atomic 原子性
- 2、Consistency 一致性
- 3、Isolation 隔离性
- 4、Durability 持久性
- 事务的并发执行
- (1)读未提交
- (2)读已提交
- (3)可重复读
- (4)串行化
- 事务的隔离级别总结
- JDBC的转账事务案例
- Spring 转账事务案例
- Spring 两种事务管理方式
- 基于 XML 配置文件进行配置
- 基于注解的声明式配置
- 转账案例的三层架构
- 一个简单的 Spring 转账事务案例
- 详解:事务注解 @Transactional
- @Tranasctional注解的使用注意事项
- Spring事务的传播规则
- Spring事务总体架构
- 二大核心模式
- 模式一: 策略模式
- 模式二: 动态代理模式
- 三大核心流程
- 核心流程一:AOP 动态代理装配流程
- 核心流程二:AOP 动态代理执行流程
- 核心流程三:事务执行流程
- Spring事务管理器架构和源码学习
- Spring事务管理模块架构
- 事务管理的超级接口
- JDBC 事务管理器
- Hibernate事务管理器
- Java持久化API(JPA)事务管理器
- Java原生API事务管理器
- TransactionDefinition基本事务属性定义
- 核心事务属性1:传播行为属性
- 核心事务属性2:隔离级别属性
- 不可重复读与幻读的区别
- Spring 隔离级别的定义
- 核心属性3: 事务只读属性
- 核心属性4:事务超时属性
- 核心属性5:Spring事务的回滚规则
- 核心流程一:AOP 动态代理装配流程源码剖析
- 注解@EnableTransactionManagement
- 核心流程二:AOP 动态代理执行流程源码剖析
- 核心流程三:事务执行流程源码剖析
- 开启事务源码分析
- 提交事务源码分析
- 回滚事务源码分析
- 尼恩总结
- 技术自由的实现路径 PDF:
- 实现你的 架构自由:
什么是数据库事务
数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。
简单来说: 事务是逻辑上的一组操作,要么都执行,要么都不执行。
通过事务,至少可以实现2点:
(1) 操作的原子性
(2)数据一致性。
我们系统的每个业务方法可能包括了多个原子性的数据库操作,比如下面的 savePerson() 方法中就有两个原子性的数据库操作。
这些原子性的数据库操作是有依赖的,它们要么都执行,要不就都不执行。
public void savePerson() {
personDao.save(person);
personDetailDao.save(personDetail);
}
事务就是保证这两个关键操作要么都成功,要么都要失败。 最经典也经常被拿出来说例子就是转账了。
假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
- 将小明的余额减少 1000 元。
- 将小红的余额增加 1000 元。
万一在这两个操作之间突然出现错误比如银行系统崩溃或者网络故障,导致小明余额减少而小红的余额没有增加,这样就不对了。
public class OrdersService {
private AccountDao accountDao;
public void setOrdersDao(AccountDao accountDao) {
this.accountDao = accountDao;
}
@Transactional(propagation = Propagation.REQUIRED,
isolation = Isolation.DEFAULT, readOnly = false, timeout = -1)
public void accountMoney() {
//小红账户多1000
accountDao.addMoney(1000,xiaohong);
//模拟突然出现的异常,比如银行中可能为突然停电等等
//如果没有配置事务管理的话会造成,小红账户多了1000而小明账户没有少钱
int i = 10 / 0;
//小王账户少1000
accountDao.reduceMoney(1000,xiaoming);
}
}
数据库事务的 ACID 四大特性
数据库事务的 ACID 四大特性是事务的基础,下面简单来了解一下。
事务的执行具备四大特征:
1、Atomic 原子性
事务必须是一个原子的操作序列单元,事务中包含的各项操作在一次执行过程中,要么全部执行成功,要么全部不执行,任何一项失败,整个事务回滚,只有全部都执行成功,整个事务才算成功。
2、Consistency 一致性
事务的执行不能破坏数据库数据的完整性和一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
3、Isolation 隔离性
在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。
即不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能相互干扰。
4、Durability 持久性
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。
即使发生系统崩溃或机器宕机,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。
比方说:一个人买东西的时候需要记录在账本上,即使老板忘记了那也有据可查。
以上的事务特性是由Innodb引擎提供,为实现这些特性,使用到了数据库锁、WAL、MVCC等技术。
事务的并发执行
并发场景、高并发场景下, 事务都是并发执行的。
多个事务,如果都是一个一个串行,想想数据库的性能会有多低下。
但是,事务的并发执行,可能会带来很多问题, 比如 脏读、不可重复读、幻读等问题。
如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形
- (1)一类丢失更新:两个事物读同一数据,一个修改字段1,一个修改字段2,后提交的恢复了先提交修改的字段。
- (2)二类丢失更新:两个事物读同一数据,都修改同一字段,后提交的覆盖了先提交的修改。
- (3)脏读:读到了未提交的值,万一该事物回滚,则产生脏读。
- (4)不可重复读:两个查询之间,被另外一个事务修改(update)了数据的内容,产生内容的不一致。
- (5)幻读:两个查询之间,被另外一个事务插入或删除了(insert、delete)记录,产生结果集的不一致。
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别。我们的数据库锁,也是为了构建这些隔离级别存在的。
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 读未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
(1)读未提交
如果一个事务正在处理某一数据,并对其进行了更新,
但同时尚未完成事务,或者说事务没有提交,
与此同时,允许另一个事务也能够访问该数据。
例如A将变量n从0累加到10才提交事务,此时B可能读到n变量从0到10之间的所有中间值。
**允许脏读。**在 读未提交 隔离级别下,允许 脏读 的情况发生。
脏读指的是读到了其他事务未提交的数据,
未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。
读到了并一定最终存在的数据,这就是脏读。

脏读最大的问题就是可能会读到不存在的数据。
比如在上图中,事务B的更新数据被事务A读取,但是事务B回滚了,更新数据全部还原,也就是说事务A刚刚读到的数据并没有存在于数据库中。
(2)读已提交
只允许读到已经提交的数据。
即事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。
在 读已提交 隔离级别下,禁止了 脏读,但是 允许不可重复读的情况发生
事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。
同时,
有事务C进行从10到20的累加,此时B在同一个事务内再次读时,读到的是20。
不可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况。

事务 A 多次读取同一数据,但事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
不可重复读 一词,有点反人类,不好记忆。是从 Nonrepeatable read 翻译过来的,感觉英文的,好记忆一点。
(3)可重复读
保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻时是一致的。
在可重复读隔离级别下,禁止了:脏读、不可重复读。
但是,允许幻读。
在可重复读中,该sql第一次读取到数据后,就将这些数据加锁(悲观锁),其它事务无法修改这些数据,就可以实现可重复读了。
但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,
这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。
(4)串行化
最严格的事务,要求所有事务被串行执行,不能并发执行。
事务的隔离级别总结
隔离级别有串行化读、可重复读、读已提交、读未提交四种级别。
- 串行化读级别下的事务并发度太低,原因是锁的粒度太大,基本没有场景可以被使用。
- 读未提交级别允许脏读,可以使用的场景并不多。
- 读已提交和可重复读是大多数数据库也是大多数项目会采用的数据库隔离级别。
读已提交隔离级别下由于读到其他事务已提交的数据,所以不会出现脏读,在普通读取时,使用到MVCC的快照读机制解决幻读问题;若在查询语句后增加for update,标识当前查询是当前读,当前读并不能解决幻读问题;允许不可重复读。
读已提交隔离级别并发度比较高,互联网行业需要数据库较高的事务并发度,一般会选择此种隔离级别。也是Oracle数据库的默认隔离级别。在使用锁方面,查询时对结果中数据的索引加共享锁,数据读取结束就会释放,更新时对操作的数据索引加排他锁,需要等到事务结束才会释放。
可重复读隔离级别是Mysql的默认隔离级别,事务并发度仅次于读已提交,普通读取的幻读问题与读已提交的解决方式一致,不过当前读可以使用 Gap Lock + Record Lock 解决。不可重复读的问题解决办法就是查询时对结果中数据的索引加锁共享锁,再事务结束时才会释放锁。解决不可重读的代价会牺牲掉并发度。
JDBC的转账事务案例
为了深入Spring 事务源码,先看一下在 JDBC 中对事务的操作处理.
还是以经典的 转账 事务为例。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TransactionExample {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt1 = null, pstmt2 = null;
try {
// 加载数据库驱动并建立连接
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "password");
// 关闭自动提交,开启事务
conn.setAutoCommit(false);
// 创建SQL语句
String sql1 = "UPDATE account SET balance = balance - ? WHERE id = ?";
String sql2 = "UPDATE account SET balance = balance + ? WHERE id = ?";
// 创建PreparedStatement对象
pstmt1 = conn.prepareStatement(sql1);
pstmt2 = conn.prepareStatement(sql2);
// 设置参数
pstmt1.setDouble(1, 1000);
pstmt1.setInt(2, 1);
pstmt2.setDouble(1, 1000);
pstmt2.setInt(2, 2);
// 执行更新操作
int count1 = pstmt1.executeUpdate();
int count2 = pstmt2.executeUpdate();
if (count1 > 0 && count2 > 0) {
System.out.println("转账成功");
// 提交事务
conn.commit();
} else {
System.out.println("转账失败");
// 回滚事务
conn.rollback();
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
try {
if (conn != null) {
// 回滚事务
conn.rollback();
}
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
} finally {
try {
if (pstmt1 != null) {
pstmt1.close();
}
if (pstmt2 != null) {
pstmt2.close();
}
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
java 代码中要使用事务,就是 三个步骤:
start transaction;-- 开启一个事务
commit;-- 事务提交
rollback;-- 事务回滚
mysql中事务默认是自动提交,一条sql语句就是一个事务.
所以,上面的代码,第一步,首先关闭自动提交,开启手动事务方式
// 关闭自动提交,开启事务
conn.setAutoCommit(false);
然后,第2步,如果顺利的话,就提交事务
// 提交事务
conn.commit();
如果发生异常的话,第3步,就回滚事务
// 回滚事务
conn.rollback();
这里总结一下,上面代码中的JDBC的转账事务案例几个重点步骤:
- 获取连接:
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "password")
- 关闭自动提交,开启事务:
conn.setAutoCommit(false) - 提交事务:
conn.commit() - 回滚事务:
conn.rollback()
Spring 转账事务案例
Spring 两种事务管理方式
Spring 支持两种事务管理方式:编程式事务和声明式事务。

编程式事务是指在代码中显式地开启、提交或回滚事务。这种方式需要在代码中编写事务管理的相关逻辑,比较繁琐,但是灵活性较高,可以根据具体的业务需要进行定制。
声明式事务是通过配置来实现的,不需要在代码中显式地管理事务。这种方式需要在配置文件中声明事务的属性,比如事务的传播行为、隔离级别等。声明式事务的好处是可以将事务管理的逻辑与业务逻辑分离,使得代码更加简洁、清晰,同时也方便了事务管理的统一配置和维护。
在 Spring 中,声明式事务主要是通过 AOP 实现的。Spring 提供了两种声明式事务的方式:基于 XML 配置和基于注解配置。基于 XML 配置的方式需要在 Spring 配置文件中声明事务管理器和事务通知等相关信息,而基于注解配置的方式则可以在代码中通过注解来声明事务的属性,比如 @Transactional。
基于 XML 配置文件进行配置
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.3.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.1.xsd">
<!-- 开启扫描 -->
<context:component-scan base-package="com.dpb.*"></context:component-scan>
<!-- 配置数据源 -->
<bean class="org.springframework.jdbc.datasource.DriverManagerDataSource" id="dataSource">
<property name="url" value="jdbc:oracle:thin:@localhost:1521:orcl"/>
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="username" value="pms"/>
<property name="password" value="pms"/>
</bean>
<!-- 配置JdbcTemplate -->
<bean class="org.springframework.jdbc.core.JdbcTemplate" >
<constructor-arg name="dataSource" ref="dataSource"/>
</bean>
<!--
Spring中,使用XML配置事务三大步骤:
1. 创建事务管理器
2. 配置事务方法
3. 配置AOP
-->
<bean class="org.springframework.jdbc.datasource.DataSourceTransactionManager" id="transactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<tx:advice id="advice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="fun*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- aop配置 -->
<aop:config>
<aop:pointcut expression="execution(* *..service.*.*(..))" id="tx"/>
<aop:advisor advice-ref="advice" pointcut-ref="tx"/>
</aop:config>
</beans>
基于注解的声明式配置
一般来说,更加推荐声明式事务比编程式事务,因为它可以使代码更加简洁、清晰,同时也方便了事务管理的统一配置和维护。
所以,这里使用 声明式事务 进行演示,并且是使用 基于注解配置的 声明式事务。
首先必须要添加 @EnableTransactionManagement 注解,保证事务注解生效
@EnableTransactionManagement
public class AnnotationMain {
public static void main(String[] args) {
}
}
其次,在方法上添加 @Transactional 代表注解生效
@Transactional
public int insertUser(User user) {
userDao.insertUser();
userDao.insertLog();
return 1;
}
下面的案例,用到基于注解的声明式配置,具体的注解是 @Transactional。
转账案例的三层架构
首先,看看日常项目中,转账案例的三层架构。
我们在日常生产项目中,项目由 Controller、Serivce、Dao 三层进行构建。

对于服务层的transfer 方法,实际对于DAO 调用来说,分别调用了两次 DAO的upate 方法,更新了两个账号的amount金额,也就是说,对数据库的操作为两次。
所以,我们要保证 transfer 方法是符合事务定义的,具备事务的四大特性:ACID。
一个简单的 Spring 转账事务案例
好的,下面是一个简单的 Spring 转账事务案例, 一共5步骤:
- 定义账户实体类
- 定义转账服务接口
- 实现转账服务接口
- 定义账户数据访问对象(DAO)
- 配置事务管理器
接下来,咱们step by step,一点点揭秘一下这个5步骤
- 定义账户实体类
public class Account {
private Long id;
private String accountNumber;
private double balance;
// 省略 getter 和 setter 方法
}
- 定义转账服务接口
public interface TransferService {
void transfer(String fromAccount, String toAccount, double amount);
}
- 实现转账服务接口
@Service
public class TransferServiceImpl implements TransferService {
@Autowired
private AccountDao accountDao;
@Transactional
public void transfer(String fromAccount, String toAccount, double amount) {
Account from = accountDao.findByAccountNumber(fromAccount);
Account to = accountDao.findByAccountNumber(toAccount);
from.setBalance(from.getBalance() - amount);
to.setBalance(to.getBalance() + amount);
accountDao.update(from);
accountDao.update(to);
}
}
- 实现账户数据访问对象(DAO)
@Repository
public class AccountDaoImpl implements AccountDao {
@Autowired
private JdbcTemplate jdbcTemplate;
public Account findByAccountNumber(String accountNumber) {
String sql = "SELECT * FROM account WHERE account_number = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{accountNumber}, new AccountRowMapper());
}
public void update(Account account) {
String sql = "UPDATE account SET balance = ? WHERE id = ?";
jdbcTemplate.update(sql, account.getBalance(), account.getId());
}
}
class AccountRowMapper implements RowMapper<Account> {
public Account mapRow(ResultSet rs, int rowNum) throws SQLException {
Account account = new Account();
account.setId(rs.getLong("id"));
account.setAccountNumber(rs.getString("account_number"));
account.setBalance(rs.getDouble("balance"));
return account;
}
}
- 配置事务管理器
@Configuration
@EnableTransactionManagement
public class AppConfig {
@Bean
public DataSource dataSource() {
// 配置数据源
}
@Bean
public JdbcTemplate jdbcTemplate() {
return new JdbcTemplate(dataSource());
}
@Bean
public PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
}
在上面的代码中,我们使用了 Spring 的声明式事务管理。
在 第3步,也就是服务层的实现方法上,添加 @Transactional 注解,告诉 Spring 这是一个需要进行事务管理的方法。
这里的事务方法,是transfer() 方法。
当 transfer() 方法被调用时,如果发生异常,事务管理器会自动回滚事务,保证数据库的一致性。
详解:事务注解 @Transactional
@Transactional 是 Spring Framework 中常用的注解之一,它可以被用于管理事务。通过使用这个注解,我们可以方便地管理事务,保证数据的一致性和完整性。
在 Spring 应用中,当我们需要对数据库进行操作时,通常需要使用事务来保证数据的一致性和完整性。
@Transactional 注解可以被用于类或方法上,用于指定事务的管理方式。当它被用于类上时,它表示该类中所有的方法都将被包含在同一个事务中。当它被用于方法上时,它表示该方法将被包含在一个新的事务中。
@Transactional 注解有多个属性,其中最常用的是 propagation 和 isolation。
- propagation 属性用于指定事务的传播行为,它决定了当前方法执行时,如何处理已经存在的事务
- isolation 属性用于指定事务的隔离级别,它决定了当前事务与其他事务之间的隔离程度。
除了 propagation 和 isolation 属性外,@Transactional 还支持其他属性,如 readOnly、timeout、rollbackFor、noRollbackFor 等,这些属性可以用于进一步细化事务的行为。
总之,@Transactional 注解是 Spring 应用中常用的事务管理注解。
@Tranasctional注解的使用注意事项
@Tranasctional注解是Spring 框架提供的声明式注解事务解决方案,在使用@Transactional注解时需要注意以下问题:
@Transactional注解只能用在public 方法上,如果用在protected或者private的方法上,不会报错,但是该注解不会生效。- 默认情况下,
@Transactional注解只能回滚 非检查型异常,具体为RuntimeException及其子类和Error子类
非检查型异常指(Unchecked Exception)的是程序在编译时不会提示需要处理该异常,而是在运行时才会出现异常。在 Java 中,非检查型异常指的是继承自 RuntimeException 类的异常,例如 NullPointerException、ArrayIndexOutOfBoundsException 等。这些异常通常是由程序员的代码错误引起的,因此应该尽可能避免它们的发生,但是在代码中并不需要显式地处理它们。
检查型异常(Checked Exception)是指在 Java 中,编译器会强制要求对可能会抛出这些异常的代码进行异常处理,否则代码将无法通过编译。这些异常包括 IOException、SQLException 等等,它们通常表示一些外部因素导致的异常情况,比如文件读写错误、数据库连接失败等等。
在编写代码时应该尽量避免抛出非检查型异常,因为这些异常的发生通常意味着程序存在严重的逻辑问题。
默认情况下,@Transactional注解只能回滚 非检查型异常,为啥呢?
可以从Spring源码的DefaultTransactionAttribute类里找到判断方法rollbackOn。
@Override
public boolean rollbackOn(Throwable ex) {
return (ex instanceof RuntimeException || ex instanceof Error);
}
- 如果需要对检查型异常(Checked Exception)进行回滚,可以使用rollbackFor 属性来定义回滚的异常类型,使用 propagation 属性定义事务的传播行为。
下面是一个例子:
@Transactional(rollbackFor = Exception.class,propagation = Propagation.REQUIRED)
上面的例子中: 指定了回滚Exception类的异常为 Exception 类型或者其子类型检查型异常(Checked Exception),另外,配置类事务的传播行为支持当前事务,当前如果没有事务,那么会创建一个事务。
@Transactional注解不能回滚被try{}catch() 捕获的异常。@Transactional注解只能对在被Spring 容器扫描到的类下的方法生效。
其实Spring事务的创建也是有一定的规则,对于一个方法里已经存在的事务,Spring 也提供了解决方案去进一步处理存在事务,通过设置@Tranasctional的propagation 属性定义Spring 事务的传播规则。
Spring事务的传播规则
Spring 事务的传播规则是指在多个事务方法相互调用的情况下,事务应该如何进行传播和管理。
Spring事务的传播行为一共有7种,定义在spring-tx模块的Propagation枚举类里,对应的常量值定义在TransactionDefinition接口里,值为int类型的0-6。
| PROPAGATION_REQUIRED | 支持当前事务,如果当前没有事务,则创建一个事务,这是最常见的选择。 |
|---|---|
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务来执行 |
| PROPAGATION_MANDATORY | 支持当前事务,如果没有当前事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务执行操作,如果当前存在事务,则当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED 类似的操作。 |
稍后一点,结合源码介绍。
Spring事务总体架构
40岁老架构尼恩的建议: 要学源码,先梳理架构。
pring事务总体架构,尼恩给大家梳理了两个要点:
- 二大核心模式
- 三大核心流程
二大核心模式
Spring事务架构 ,用到了二大核心模式

模式一: 策略模式
设计了统一的事务管理器超级接口, PlatformTransactionManager 是 Spring事务管理器设计的 基类。
PlatformTransactionManager 基类,实现了 事务执行设计到的三个核心方法:

不同的 数据管理组件JDBC、Hibernate等,为Spring都提供了对应的事务管理器 实现类。
既然是策略模式, 如何进行动态的决策呢?

在动态代理模式的 切面的支撑 类 TransactionAspectSupport 中, 会有一个 determineTransactionManager 方法, 动态的从IOC容器,加载 注册了的 PlatformTransactionManager 实现类。
尼恩的脚手架,用到的orm框架是 jpa。在spring的bean factory里边 注册了的 PlatformTransactionManager 实现类 是 JpaTransactionManager 。
所以,这里的 JpaTransactionManager 作为事务管理器。
模式二: 动态代理模式
动态代理有JDK的动态代理、 Aspectj的动态代理,SpringAOP动态代理 ,很多种。
SpringAOP 和 Aspectj的动态代理 有和联系呢? 本质上 Aspectj是一种静态代理,而SpringAOP是动态代理。但Aspectj的一套定义AOP的API非常好,直观易用。
但是,AOP联盟的关键词有Advice(顶级的通知类/拦截器)、MethodInvocation(方法连接点)、MethodInterceptor(方法拦截器)
SpringAOP与AOP联盟关系
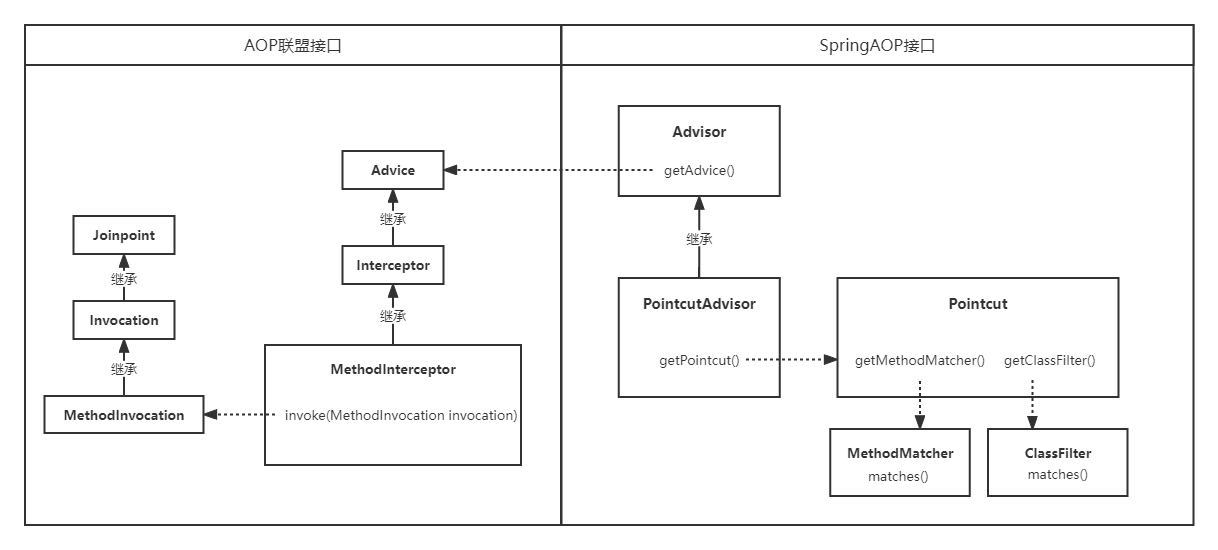
SpringAOP在AOP联盟基础上又增加了几个类,丰富了AOP定义及使用概念,SpringAOP 的核心名称和概念包括:
- Advisor:包含通知(拦截器),Spring内部使用的AOP顶级接口,还需要包含一个aop适用判断的过滤器,考虑到通用性,过滤规则由其子接口定义,例如IntroductionAdvisor和PointcutAdvisor,过滤器用于判断bean是否需要被代理
- Pointcut: 切点,属于过滤器的一种实现,匹配过滤哪些类哪些方法需要被切面处理,包含一个ClassFilter和一个MethodMatcher,使用PointcutAdvisor定义时需要
- ClassFilter:限制切入点或引入点与给定目标类集的匹配的筛选器,属于过滤器的一种实现。过滤筛选合适的类,有些类不需要被处理
- MethodMatcher:方法匹配器,定义方法匹配规则,属于过滤器的一种实现,哪些方法需要使用AOP
SpringAOP实现的大致思路:
1.配置获取Advisor (顾问):拦截器+AOP匹配过滤器,生成Advisor
2.生成代理:根据Advisor生成代理对象,会生成JdkDynamicAopProxy或CglibAopProxy
3.执行代理:代理类执行代理时,从Advisor取出拦截器,生成MethodInvocation(连接点)并执行代理过程。
如果对 在 Spring AOP 中,Advisor 和 Interceptor 是两个重要的概念。
Advisor 是用于定义切面的对象,它包含了切点和通知两个部分。
- 切点指定了哪些方法需要被拦截 , 使用@Pointcut 注解
- 通知则指定了拦截后需要执行的逻辑。
Interceptor 是用于拦截后,执行拦截逻辑的对象,它实现了 Spring 的 MethodInterceptor 接口,负责拦截方法的执行,并在方法执行前后执行一些操作。
下面是一个使用 Advisor 和 Interceptor 的示例:
@Aspect
@Component
public class MyInterceptor {
//切点
@Pointcut("execution(* com.example.service.*.*(..))")
public void pointcut() {}
@Around("pointcut()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
// 在方法执行前执行的逻辑
System.out.println("before method");
// 执行被拦截的方法
Object result = pjp.proceed();
// 在方法执行后执行的逻辑
System.out.println("after method");
return result;
}
}
在上面的代码中,我们使用了 Advisor 和 Interceptor 来实现对 com.example.service 包中所有方法的拦截。
首先,我们定义了一个切点 pointcut(),它指定了需要拦截的方法。
然后,我们定义了一个 around() 方法,并使用 @Around 注解将它与切点关联起来。在 around() 方法中,我们实现了拦截逻辑,即在方法执行前后分别输出 “before method” 和 “after method”。最后,我们通过 pjp.proceed() 方法执行了被拦截的方法,并返回了它的执行结果。
需要注意的是,为了让 Spring 能够识别 MyInterceptor 类并将它作为 Advisor 使用,我们需要在它上面加上 @Aspect 和 @Component 注解。
注意 Advisor 是动态生成的,但是Spring也会实现了一个类似于 PointcutAdvisor 的接口,可以根据配置的切入点和目标方法生成代理对象,调用咱们定义的MyInterceptor 实现拦截和AOP增强功能。

了解了SpringAOP 基本原理之后,我们来看看SpringAOP实现 事务的 动态代理模式的架构。
SpringAOP实现 事务的 动态代理模式的架构图如下:

动态代理模式的两个核心角色是:
- Advisor:
BeanFactoryTransactionAttributeSourceAdvisor - Interceptor:
TransactionInterceptor
Spring事务进行了Advisor 的扩展, BeanFactoryTransactionAttributeSourceAdvisor 是 Spring AOP框架中一个用于事务管理的类。
该 Advisor它实现了 PointcutAdvisor 接口,可以根据配置的切入点和事务属性来为目标方法生成代理对象,从而实现事务管理的功能。
在 Spring 中,事务管理是通过 TransactionInterceptor 实现的。该 Advisor 的作用就是为 Interceptor 提供事务属性信息。
该 Advisor 通过 TransactionAttributeSource 接口来获取事务属性,而 TransactionAttributeSource 可以从配置文件、注解等多种途径获取事务属性信息。该 Advisor 是从 Spring 容器中获取 TransactionAttributeSource 的实现类,并将其设置给 TransactionInterceptor,从而实现事务管理的功能。
三大核心流程
- AOP 动态代理装配流程
- AOP 动态代理执行流程
- 事务执行流程
核心流程一:AOP 动态代理装配流程
AOP 动态代理装配流程 ,大致如下:

咱们关注的是 Advisor 和 Interceptor的装配。
核心流程二:AOP 动态代理执行流程
AOP 动态代理执行流程 ,大致如下:

执行被@Transactional注解的方法时,首先会被AOP切面代理拦截, 先执行 事务的动态代理,再执行业务方法。
在事务的动态代理动态代理对象中,进行事务的 开启、提交、或者回滚。
核心流程三:事务执行流程
AOP 事务执行流程 ,大致如下:

这个使用 Spring事务管理器实现。
所以,学习Spring源码,咱们先从Spring事务管理器源码开始。
Spring事务管理器架构和源码学习
Spring事务管理的实现有许多细节,如果对整个模块架构有个大体了解,会非常有利于我们理解事务,
Spring事务管理模块架构
Spring事务管理模块架构,如下:

Spring并不直接管理事务,而是提供了多种事务管理器。
通过事务管理器,Spring将事务管理的职责委托给ORM框架,比如Hibernate或者JTA等,由ORM框架的持久化机制所提供的相关平台框架的事务来实现。
事务管理的超级接口
Spring事务管理器的超级接口是 PlatformTransactionManager,
PlatformTransactionManager超级接口的内容如下:
Public interface PlatformTransactionManager()...{
// 由TransactionDefinition得到TransactionStatus对象
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
// 提交
Void commit(TransactionStatus status) throws TransactionException;
// 回滚
Void rollback(TransactionStatus status) throws TransactionException;
}
通过这个超级接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器。
从这里可知:PlatformTransactionManager 具体的实现就是各个平台自己的事情了。
所以说,具体的事务管理机制对Spring来说是透明的,Spring并不关心那些,那些是对应各个平台需要关心的。
所以,Spring事务管理模块架构 的一个优点就是:为不同的事务API提供一致的编程模型,如JTA、JDBC、Hibernate、JPA。
下面分别介绍各个平台框架实现事务管理的机制。
JDBC 事务管理器
如果应用程序中直接使用JDBC来进行ORM持久化,DataSourceTransactionManager会为你处理事务,提供事务管理的的具体实现。
DataSourceTransactionManager 是 Spring Framework 中用于管理数据库事务的类,它是基于 JDBC 的事务管理器。
为了使用DataSourceTransactionManager,如果使用XML定义Bean,需要使用如下的XML将其装配到应用程序的上下文定义中:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
在 Spring Boot 中,如果你使用了 Spring Data JPA 或者 MyBatis 等 ORM 框架,那么默认会使用 DataSourceTransactionManager 进行事务管理。
SpringBoot在使用事物Transactional的时候,要在main方法上加上 @EnableTransactionManagement 注解开发事物声明,在使用的service层的公共方法加上 @Transactional (spring)注解。
如果我们不想使用事物 @Transactional 注解,想自己进行事物控制(编程事物管理),控制某一段的代码事务生效或者回滚,但是又不想自己去编写那么多的代码,怎么办呢?
可以使用springboot中的DataSourceTransactionManager和TransactionDefinition这两个类来结合使用,能够达到手动控制事物的提交回滚。
代码示例:
@Autowired
private DataSourceTransactionManager dataSourceTransactionManager;
@Autowired
private TransactionDefinition transactionDefinition;
public boolean transferMoney(User user) {
/*
* 手动进行事物控制
*/
TransactionStatus transactionStatus=null;
boolean isCommit = false;
try {
//开启事务
transactionStatus =
dataSourceTransactionManager.getTransaction(transactionDefinition);
System.out.println("查询的数据1:" + udao.findById(user.getId()));
// 进行新增/修改
udao.insert(user);
System.out.println("查询的数据2:" + udao.findById(user.getId()));
if(user.getAge()<20) {
user.setAge(user.getAge()+2);
udao.update(user);
System.out.println("查询的数据3:" + udao.findById(user.getId()));
}else {
throw new Exception("模拟一个异常!");
}
//手动提交
dataSourceTransactionManager.commit(transactionStatus);
isCommit= true;
System.out.println("手动提交事物成功!");
throw new Exception("模拟第二个异常!");
} catch (Exception e) {
//如果未提交就进行回滚
if(!isCommit){
System.out.println("发生异常,进行手动回滚!");
//手动回滚事物
dataSourceTransactionManager.rollback(transactionStatus);
}
e.printStackTrace();
}
return false;
}
特别说明:
在进行使用的时候,需要注意在回滚的时候,要确保开启了事物但是未提交,如果未开启或已提交的时候进行回滚是会在catch里面发生异常的!
实际上,DataSourceTransactionManager是通过调用java.sql.Connection来管理事务,而后者是通过DataSource获取到的。通过调用连接的commit()方法来提交事务,同样,事务失败则通过调用rollback()方法进行回滚。
Hibernate事务管理器
如果应用程序的持久化是通过Hibernate实现的,那么你需要使用HibernateTransactionManager。对于Hibernate3,需要在Spring上下文定义中添加如下的<bean>声明:
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
sessionFactory属性需要装配一个Hibernate的session工厂,HibernateTransactionManager的实现细节是它将事务管理的职责委托给org.hibernate.Transaction对象,而后者是从Hibernate Session中获取到的。
当事务成功完成时,HibernateTransactionManager将会调用Transaction对象的commit()方法,反之,将会调用rollback()方法。
Java持久化API(JPA)事务管理器
Hibernate多年来一直是事实上的Java持久化标准,但是现在Java持久化API作为真正的Java持久化标准进入大家的视野。
如果你计划使用JPA的话,那你需要使用Spring的JpaTransactionManager来处理事务。
你需要在Spring中这样配置JpaTransactionManager:
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
JpaTransactionManager只需要装配一个JPA实体管理工厂(javax.persistence.EntityManagerFactory接口的任意实现)。
JpaTransactionManager将与由工厂所产生的JPA EntityManager合作来构建事务。
Java原生API事务管理器
如果你没有使用以上所述的事务管理,或者是跨越了多个事务管理源(比如两个或者是多个不同的数据源),你就需要使用JtaTransactionManager:
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="transactionManagerName" value="java:/TransactionManager" />
</bean>
JtaTransactionManager将事务管理的责任委托给javax.transaction.UserTransaction和javax.transaction.TransactionManager对象,其中事务成功完成通过UserTransaction.commit()方法提交,事务失败通过UserTransaction.rollback()方法回滚。
TransactionDefinition基本事务属性定义
如何开启事务?
事务管理器接口PlatformTransactionManager通过getTransaction(TransactionDefinition definition)方法来开启一个事务,这个方法里面的参数是TransactionDefinition类,这个类就定义了一些基本的事务属性。
那么什么是事务属性呢?
事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。
总体来说,事务属性包含了5个方面,如图所示:

TransactionDefinition接口内容如下:
public interface TransactionDefinition {
int getPropagationBehavior(); // 返回事务的传播行为
int getIsolationLevel(); // 返回事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
int getTimeout(); // 返回事务必须在多少秒内完成
boolean isReadOnly(); // 事务是否只读,事务管理器能够根据这个返回值进行优化,确保事务是只读的
}
我们可以发现TransactionDefinition正好用来定义事务属性,下面详细介绍一下各个事务属性。
核心事务属性1:传播行为属性
事务的第一个方面是传播行为(propagation behavior)。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。
例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
Spring定义了七种传播行为:
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
使用spring声明式事务,spring使用AOP来支持声明式事务,会根据事务属性,自动在方法调用之前决定是否开一个事务,并在方法执行之后决定事务提交或回滚事务。
(1)PROPAGATION_REQUIRED
PROPAGATION_REQUIRED 功能说明:
- 如果存在一个事务,则支持当前事务。
- 如果没有事务,则开启一个新的事务。
methodA 调用 methodB
//事务属性 PROPAGATION_REQUIRED
methodA{
……
methodB();
……
}
methodB() 的代码
//事务属性 PROPAGATION_REQUIRED
methodB{
……
}
如果 单独调用methodB方法:
main{
metodB();
}
Spring保证在methodB方法中所有的调用,都获得到一个相同的连接。在调用methodB时,没有一个存在的事务,所以获得一个新的连接,开启了一个新的事务。
相当于
Main{
Connection con=null;
try{
con = getConnection();
con.setAutoCommit(false);
//方法调用
methodB();
//提交事务
con.commit();
} Catch(RuntimeException ex) {
//回滚事务
con.rollback();
} finally {
//释放资源
closeCon();
}
}
如果是 先调用MethodA时,在MethodA内又会调用MethodB. 执行效果相当于:
main{
Connection con = null;
try{
con = getConnection();
methodA();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
closeCon();
}
}
当在MethodA中调用MethodB时,环境中已经有了一个事务,所以methodB就加入当前事务。
(2)PROPAGATION_SUPPORTS
功能说明:
- 如果存在一个事务,支持当前事务。
- 如果没有事务,则非事务的执行。
但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_SUPPORTS
methodB(){
……
}
单纯的调用methodB时,methodB方法是非事务的执行的。
当调用methdA时,methodB则加入了methodA的事务中,事务地执行。
(3)PROPAGATION_MANDATORY
功能说明:
- 如果已经存在一个事务,支持当前事务。
- 如果没有一个活动的事务,则抛出异常。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_MANDATORY
methodB(){
……
}
当单独调用methodB时,因为当前没有一个活动的事务,
则会抛出异常
throw new IllegalTransactionStateException(“Transaction propagation ‘mandatory’ but no existing transaction found”);
当调用methodA时,methodB则加入到methodA的事务中,事务地执行。
(4)PROPAGATION_REQUIRES_NEW
- 总是开启一个新的事务。
- 如果一个事务已经存在,则将这个存在的事务挂起。
下面是一个例子
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_REQUIRES_NEW
methodB(){
……
}
调用A方法:
main(){
methodA();
}
相当于
main(){
TransactionManager tm = null;
try{
//获得一个JTA事务管理器
tm = getTransactionManager();
tm.begin();//开启一个新的事务
Transaction ts1 = tm.getTransaction();
doSomeThing();
tm.suspend();//挂起当前事务
try{
tm.begin();//重新开启第二个事务
Transaction ts2 = tm.getTransaction();
methodB();
ts2.commit();//提交第二个事务
} Catch(RunTimeException ex) {
ts2.rollback();//回滚第二个事务
} finally {
//释放资源
}
//methodB执行完后,恢复第一个事务
tm.resume(ts1);
doSomeThingB();
ts1.commit();//提交第一个事务
} catch(RunTimeException ex) {
ts1.rollback();//回滚第一个事务
} finally {
//释放资源
}
}
在这里,我把ts1称为外层事务,ts2称为内层事务。
从上面的代码可以看出,ts2与ts1是两个独立的事务,互不相干。
Ts2是否成功并不依赖于 ts1。
如果methodA方法在调用methodB方法后的doSomeThingB方法失败了,而methodB方法所做的结果依然被提交。而除了 methodB之外的其它代码导致的结果却被回滚了。
另外,使用PROPAGATION_REQUIRES_NEW, 需要使用 JtaTransactionManager作为事务管理器。
(5)PROPAGATION_NOT_SUPPORTED
功能说明:
- 总是非事务地执行,并挂起任何存在的事务。
使用PROPAGATION_NOT_SUPPORTED,也需要使用JtaTransactionManager作为事务管理器。
(6)PROPAGATION_NEVER
功能说明:
- 总是非事务地执行
- 如果存在一个活动事务,则抛出异常。
(7)PROPAGATION_NESTED
功能说明:
- 如果一个活动的事务存在,则运行在一个嵌套的事务中.
- 如果没有活动事务, 则按
TransactionDefinition.PROPAGATION_REQUIRED属性执行。
这是一个嵌套事务,使用JDBC 3.0驱动时,仅仅支持DataSourceTransactionManager作为事务管理器。
需要JDBC 驱动的java.sql.Savepoint类。有一些JTA的事务管理器实现可能也提供了同样的功能。
使用PROPAGATION_NESTED,还需要把PlatformTransactionManager的nestedTransactionAllowed属性设为true;而 nestedTransactionAllowed属性值默认为false。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_NESTED
methodB(){
……
}
如果单独调用methodB方法,则按REQUIRED属性执行。如果调用methodA方法,相当于下面的效果:
main(){
Connection con = null;
Savepoint savepoint = null;
try{
con = getConnection();
con.setAutoCommit(false);
doSomeThingA();
savepoint = con2.setSavepoint();
try{
methodB();
} catch(RuntimeException ex) {
con.rollback(savepoint);
} finally {
//释放资源
}
doSomeThingB();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
//释放资源
}
}
当methodB方法调用之前,调用setSavepoint方法,保存当前的状态到savepoint。
如果methodB方法调用失败,则恢复到之前保存的状态。
但是需要注意的是,这时的事务并没有进行提交,如果后续的代码(doSomeThingB()方法 调用失败,则回滚包括methodB方法的所有操作。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA事务管理器的支持。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
PROPAGATION_REQUIRES_NEW 启动一个新的,不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于,
PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
事务的传播属性,当如何选择?
一般情况下,PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
核心事务属性2:隔离级别属性
事务的第二个维度就是隔离级别(isolation level)。
隔离级别定义了一个事务可能受其他并发事务影响的程度。
(1)并发事务引起的问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务。并发虽然是必须的,但可能会导致一下的问题。
- 脏读(Dirty reads)——脏读发生在一个事务读取了另一个事务改写但尚未提交的数据时。如果改写在稍后被回滚了,那么第一个事务获取的数据就是无效的。
- 不可重复读(Nonrepeatable read)——不可重复读发生在一个事务执行相同的查询两次或两次以上,但是每次都得到不同的数据时。这通常是因为另一个并发事务在两次查询期间进行了更新。
- 幻读(Phantom read)——幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录。
不可重复读与幻读的区别
- (1)不可重复读的重点是修改
- (2)幻读的重点在于新增或者删除:
(1)不可重复读的重点是修改:
同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
例如:在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
con1 = getConnection();
select salary from employee empId ="Mary";
在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
con2 = getConnection();
update employee set salary = 2000;
con2.commit();
在事务1中,Mary 再次读取自己的工资时,工资变为了2000
//con1
select salary from employee empId ="Mary";
在一个事务中前后两次读取的结果并不一致,导致了不可重复读。
(2)幻读的重点在于新增或者删除:
同样的条件, 第1次和第2次读出来的记录数不一样
例如:目前工资为1000的员工有10人。
事务1,读取所有工资为1000的员工。
con1 = getConnection();
Select * from employee where salary =1000;
共读取10条记录
这时另一个事务向employee表插入了一条员工记录,工资也为1000
con2 = getConnection();
Insert into employee(empId,salary) values("Lili",1000);
con2.commit();
事务1再次读取所有工资为1000的员工
//con1
select * from employee where salary =1000;
共读取到了11条记录,这就产生了幻像读。
从总的结果来看, 似乎不可重复读和幻读都表现为两次读取的结果不一致。
但如果你从控制的角度来看, 两者的区别就比较大。
- 对于不可重复读, 只需要锁住满足条件的记录。
- 对于幻读, 要锁住满足条件及其相近的记录。
Spring 隔离级别的定义
数据库有自己的隔离级别的定义,Spring也有自己的 隔离级别的定义
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生 |
| ISOLATION_SERIALIZABLE | 最高的隔离级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读,也是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库表来实现的 |
核心属性3: 事务只读属性
事务只读属性: 表示这个事务只读取数据但不更新数据, 这样可以帮助数据库引擎优化事务。
具体来说: 如果事务只对后端的数据库进行读操作,数据库可以利用事务的只读特性来进行一些特定的优化。通过将事务设置为只读,你就可以给数据库一个机会,让它应用它认为合适的优化措施。
当使用 @Transaction 注解时,可以通过设置 readOnly=true 来指定这是一个只读事务,这样在事务执行期间就不会对数据进行修改,只会进行查询操作。
以下是一个使用 @Transaction 只读示例的代码片段:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional(readOnly = true)
public User getUserById(Long id) {
return userRepository.findById(id).orElse(null);
}
// 其他方法...
}
在上面的示例中,getUserById 方法被标记为只读事务,因此在执行期间只会进行查询操作。
如果在方法中尝试进行修改操作,将会抛出异常。
核心属性4:事务超时属性
事务超时属性:事务在强制回滚之前可以保持多久。这样可以防止长期运行的事务占用资源。
为了使应用程序很好地运行,事务不能运行太长的时间。
因为事务可能涉及对后端数据库的锁定,所以长时间的事务会不必要的占用数据库资源。
事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束。
@Transactional 注解中的 timeout 属性用于设置事务的超时时间,单位为秒。如果事务在超过指定时间后仍未完成,则会被强制回滚。
以下是一个示例:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional(timeout = 5)
public void updateUser(User user) {
userRepository.save(user);
// 执行一些其他操作
}
}
在上面的示例中,updateUser 方法使用了 @Transactional 注解,并设置了 timeout 属性为 5 秒。如果该方法执行时间超过 5 秒,事务将会被强制回滚。
需要注意的是,如果在事务内部调用了其他带有事务注解的方法,那么这些方法的超时时间也会受到影响。
因此,在设置事务超时时间时,需要考虑到事务内部所涉及的所有方法的执行时间。
核心属性5:Spring事务的回滚规则
事务五边形的最后一个方面是一组规则,这些规则定义了哪些异常会导致事务回滚而哪些不会。
好的,下面是一个简单的 Java 代码示例,演示了 @Transactional 注解的使用以及如何在出现异常时回滚事务:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public void createUser(User user) {
userRepository.save(user);
if (user.getId() == null) {
throw new RuntimeException("Failed to create user");
}
}
}
在上面的示例中,createUser 方法上使用了 @Transactional 注解,表示这个方法需要在事务管理下执行。如果在方法执行过程中发生异常,事务会自动回滚,保证数据的一致性。
在这个例子中,如果用户创建失败,createUser 方法会抛出一个 RuntimeException 异常,这会导致事务回滚,用户创建操作会被撤销。
需要注意的是,@Transactional 注解只能应用于公共方法,因为只有公共方法才能被代理,从而实现事务管理。
此外,@Transactional 注解默认只对受检查异常进行回滚,而对非受检查异常不进行回滚。
非检查型异常指(Unchecked Exception)的是程序在编译时不会提示需要处理该异常,而是在运行时才会出现异常。
检查型异常(Checked Exception)是指在 Java 中,编译器会强制要求对可能会抛出这些异常的代码进行异常处理,否则代码将无法通过编译。
一般来说,在编写代码时应该尽量避免抛出非检查型异常,因为这些异常的发生通常意味着程序存在严重的逻辑问题。
如果是检查型异常(Checked Exception), 可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
如果需要对非受检查异常也进行回滚,可以在 @Transactional 注解中指定 rollbackFor 属性,例如
@Transactional(rollbackFor = Exception.class)
public void createUser(User user) {
userRepository.save(user);
if (user.getId() == null) {
throw new RuntimeException("Failed to create user");
}
}
核心流程一:AOP 动态代理装配流程源码剖析
注解@EnableTransactionManagement
我们知道了使用 AOP 技术实现,那到底是如何实现的呢?
我们从 @EnableTransactionManagement 注解聊起,我们点进该注解:
@Import(TransactionManagementConfigurationSelector.class)
public @interface EnableTransactionManagement {
很明显,TransactionManagementConfigurationSelector 类是我们主要关注的内容
public class TransactionManagementConfigurationSelector extends AdviceModeImportSelector<EnableTransactionManagement> {
/**
* 此处是AdviceMode的作用,默认是用代理,另外一个是ASPECTJ
*/
@Override
protected String[] selectImports(AdviceMode adviceMode) {
switch (adviceMode) {
case PROXY:
return new String[] {AutoProxyRegistrar.class.getName(),
ProxyTransactionManagementConfiguration.class.getName()};
case ASPECTJ:
return new String[] {determineTransactionAspectClass()};
default:
return null;
}
}
}
一共注册了两个:
AutoProxyRegistrar.class:注册AOP处理器ProxyTransactionManagementConfiguration.class:代理事务配置,
注册事务需要用的一些类,而且Role=ROLE_INFRASTRUCTURE都是属于内部级别的
@Configuration(proxyBeanMethods = false)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public class ProxyTransactionManagementConfiguration extends AbstractTransactionManagementConfiguration {
@Bean(name = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public BeanFactoryTransactionAttributeSourceAdvisor transactionAdvisor(
TransactionAttributeSource transactionAttributeSource, TransactionInterceptor transactionInterceptor) {
// 【重点】注册了 BeanFactoryTransactionAttributeSourceAdvisor 的 advisor
// 其 advice 为 transactionInterceptor
BeanFactoryTransactionAttributeSourceAdvisor advisor = new BeanFactoryTransactionAttributeSourceAdvisor();
advisor.setTransactionAttributeSource(transactionAttributeSource);
advisor.setAdvice(transactionInterceptor);
if (this.enableTx != null) {
advisor.setOrder(this.enableTx.<Integer>getNumber("order"));
}
return advisor;
}
@Bean
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public TransactionAttributeSource transactionAttributeSource() {
return new AnnotationTransactionAttributeSource();
}
@Bean
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public TransactionInterceptor transactionInterceptor(TransactionAttributeSource transactionAttributeSource) {
TransactionInterceptor interceptor = new TransactionInterceptor();
interceptor.setTransactionAttributeSource(transactionAttributeSource);
if (this.txManager != null) {
interceptor.setTransactionManager(this.txManager);
}
return interceptor;
}
}
到这里,看到BeanFactoryTransactionAttributeSourceAdvisor 以 advisor 结尾的类,这就是进行创建AOP动态代理对象的核心类,其 Interceptor为 transactionInterceptor
到这里,我们思考一下,利用我们之前学习到的 AOP 的源码,猜测其运行逻辑:
- 我们在方法上写上
@EnableTransactionManagement注解,Spring 会注册一个BeanFactoryTransactionAttributeSourceAdvisor的类 - 创建对应的方法 Bean 时,会和 AOP 一样,利用该 Advisor 类生成对应的代理对象
- 最终调用方法时,会调用代理对象,并通过环绕增强来达到事务的功能
核心流程二:AOP 动态代理执行流程源码剖析
动态代理对象的代理方法被执行后,会执行到 Interceptor 拦截器。
我们从上面看到其 Interceptor正是 TransactionInterceptor。代理对象运行时,会拿到所有的 Interceptor并进行排序,责任链递归运行
这里先看一下 TransactionInterceptor 类图

然后看其源码内容:
这里的 invoke 方法执行的时候,会执行invokeWithinTransaction ,具体看代码
public class TransactionInterceptor extends TransactionAspectSupport implements MethodInterceptor {
@Override
@Nullable
public Object invoke(MethodInvocation invocation) throws Throwable {
// 获取我们的代理对象的class属性
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// Adapt to TransactionAspectSupport's invokeWithinTransaction...
/**
* 以事务的方式调用目标方法
* 在这埋了一个钩子函数 用来回调目标方法的
*/
return invokeWithinTransaction(invocation.getMethod(), targetClass, invocation::proceed);
}
}
@Nullable
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass, final InvocationCallback invocation){
// 获取我们的事务属性源对象
TransactionAttributeSource tas = getTransactionAttributeSource();
// 通过事务属性源对象获取到当前方法的事务属性信息
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 获取我们配置的事务管理器对象
final TransactionManager tm = determineTransactionManager(txAttr);
if (txAttr == null || !(ptm instanceof CallbackPreferringPlatformTransactionManager)) {
// 【重点】创建TransactionInfo
TransactionInfo txInfo = createTransactionIfNecessary(ptm, txAttr, joinpointIdentification);
try {
// 执行被增强方法,调用具体的处理逻辑
// 我们实际的业务方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// 异常回滚, 事务回滚
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
//清除事务信息,恢复线程私有的老的事务信息
cleanupTransactionInfo(txInfo);
}
// 提交事务
//成功后提交,会进行资源储量,连接释放,恢复挂起事务等操作
commitTransactionAfterReturning(txInfo);
return retVal;
}
}
// 创建连接 + 开启事务
protected TransactionInfo createTransactionIfNecessary(@Nullable PlatformTransactionManager tm,
@Nullable TransactionAttribute txAttr, final String joinpointIdentification) {
// 获取TransactionStatus事务状态信息
status = tm.getTransaction(txAttr);
// 根据指定的属性与status准备一个TransactionInfo,
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
// 存在异常时回滚事务
protected void completeTransactionAfterThrowing(@Nullable TransactionInfo txInfo, Throwable ex) {
// 进行回滚
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
}
// 调用事务管理器的提交方法
protected void commitTransactionAfterReturning(@Nullable TransactionInfo txInfo){
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
从上面的拦截器可以看到
- 在业务方法前面,开启事务
- 业务方法后面,捕获异常,执行事务回滚
- 如果没有异常,提交事务
核心流程三:事务执行流程源码剖析
Spring 事务设计了统一的事务管理器超级接口, PlatformTransactionManager 是 Spring事务管理器设计的 基类。

先看看看PlatformTransactionManager 的实现,其实现一共三个方法:
- 开启事务:
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) - 提交事务:
void commit(TransactionStatus status) - 回滚事务:
void rollback(TransactionStatus status)
接下来,我们分别看一下其如何实现的
开启事务源码分析
我们想一下,在开启事务这一阶段,我们会做什么功能呢? 参考DataSourceTransactionManager,这个阶段应该会 创建连接并且开启事务
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition){
// PROPAGATION_REQUIRED,PROPAGATION_REQUIRES_NEW,PROPAGATION_NESTED都需要新建事务
if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
//没有当前事务的话,REQUIRED,REQUIRES_NEW,NESTED挂起的是空事务,然后创建一个新事务
SuspendedResourcesHolder suspendedResources = suspend(null);
try {
// 看这里重点:开始事务
return startTransaction(def, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error ex) {
// 恢复挂起的事务
resume(null, suspendedResources);
throw ex;
}
}
}
private TransactionStatus startTransaction(TransactionDefinition definition, Object transaction, boolean debugEnabled, @Nullable SuspendedResourcesHolder suspendedResources) {
// 是否需要新同步
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// 创建新的事务
DefaultTransactionStatus status = newTransactionStatus( definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 【重点】开启事务和连接
doBegin(transaction, definition);
// 新同步事务的设置,针对于当前线程的设置
prepareSynchronization(status, definition);
return status;
}
protected void doBegin(Object transaction, TransactionDefinition definition) {
// 判断事务对象没有数据库连接持有器
if (!txObject.hasConnectionHolder() ||
txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
// 【重点】通过数据源获取一个数据库连接对象
Connection newCon = obtainDataSource().getConnection();
// 把我们的数据库连接包装成一个ConnectionHolder对象 然后设置到我们的txObject对象中去
// 再次进来时,该 txObject 就已经有事务配置了
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
// 【重点】获取连接
con = txObject.getConnectionHolder().getConnection();
// 为当前的事务设置隔离级别【数据库的隔离级别】
Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
// 设置先前隔离级别
txObject.setPreviousIsolationLevel(previousIsolationLevel);
// 设置是否只读
txObject.setReadOnly(definition.isReadOnly());
// 关闭自动提交
if (con.getAutoCommit()) {
//设置需要恢复自动提交
txObject.setMustRestoreAutoCommit(true);
// 【重点】关闭自动提交
con.setAutoCommit(false);
}
// 判断事务是否需要设置为只读事务
prepareTransactionalConnection(con, definition);
// 标记激活事务
txObject.getConnectionHolder().setTransactionActive(true);
// 设置事务超时时间
int timeout = determineTimeout(definition);
if (timeout != TransactionDefinition.TIMEOUT_DEFAULT) {
txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
}
// 绑定我们的数据源和连接到我们的同步管理器上,把数据源作为key,数据库连接作为value 设置到线程变量中
if (txObject.isNewConnectionHolder()) {
// 将当前获取到的连接绑定到当前线程
TransactionSynchronizationManager.bindResource(obtainDataSource(), txObject.getConnectionHolder());
}
}
到这里,我们的 获取事务 接口完成了 数据库连接的创建 和 关闭自动提交(开启事务),将 Connection 注册到了缓存(resources)当中,便于获取。
提交事务源码分析
public final void commit(TransactionStatus status) throws TransactionException {
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
// 如果在事务链中已经被标记回滚,那么不会尝试提交事务,直接回滚
if (defStatus.isLocalRollbackOnly()) {
// 不可预期的回滚
processRollback(defStatus, false);
return;
}
// 设置了全局回滚
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
// 可预期的回滚,可能会报异常
processRollback(defStatus, true);
return;
}
// 【重点】处理事务提交
processCommit(defStatus);
}
// 处理提交,先处理保存点,然后处理新事务,如果不是新事务不会真正提交,要等外层是新事务的才提交,
// 最后根据条件执行数据清除,线程的私有资源解绑,重置连接自动提交,隔离级别,是否只读,释放连接,恢复挂起事务等
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
// 如果是独立的事务则直接提交
doCommit(status);
//根据条件,完成后数据清除,和线程的私有资源解绑,重置连接自动提交,隔离级别,是否只读,释放连接,恢复挂起事务等
cleanupAfterCompletion(status);
}
这里比较重要的有两个步骤:
doCommit:提交事务(直接使用 JDBC 提交即可)
protected void doCommit(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
try {
// JDBC连接提交
con.commit();
}
catch (SQLException ex) {
throw new TransactionSystemException("Could not commit JDBC transaction", ex);
}
}
cleanupAfterCompletion:数据清除,与线程中的私有资源解绑,方便释放
// 线程同步状态清除
TransactionSynchronizationManager.clear();
// 清除同步状态【这些都是线程的缓存,使用ThreadLocal的】
public static void clear() {
synchronizations.remove();
currentTransactionName.remove();
currentTransactionReadOnly.remove();
currentTransactionIsolationLevel.remove();
actualTransactionActive.remove();
}
// 如果是新事务的话,进行数据清除,线程的私有资源解绑,重置连接自动提交,隔离级别,是否只读,释放连接等
doCleanupAfterCompletion(status.getTransaction());
// 此方法做清除连接相关操作,比如重置自动提交啊,只读属性啊,解绑数据源啊,释放连接啊,清除链接持有器属性
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 将数据库连接从当前线程中解除绑定
TransactionSynchronizationManager.unbindResource(obtainDataSource());
// 释放连接
Connection con = txObject.getConnectionHolder().getConnection();
// 恢复数据库连接的自动提交属性
con.setAutoCommit(true);
// 重置数据库连接
DataSourceUtils.resetConnectionAfterTransaction(con, txObject.getPreviousIsolationLevel(), txObject.isReadOnly());
// 如果当前事务是独立的新创建的事务则在事务完成时释放数据库连接
DataSourceUtils.releaseConnection(con, this.dataSource);
// 连接持有器属性清除
txObject.getConnectionHolder().clear();
}
这就是我们提交事务的操作了,总之来说,主要就是 调用JDBC的commit提交 和 清除一系列的线程内部数据和配置
回滚事务源码分析
public final void rollback(TransactionStatus status) throws TransactionException {
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
processRollback(defStatus, false);
}
private void processRollback(DefaultTransactionStatus status, boolean unexpected) {
// 回滚的擦欧洲哦
doRollback(status);
// 回滚完成后回调
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
// 根据事务状态信息,完成后数据清除,和线程的私有资源解绑,重置连接自动提交,隔离级别,是否只读,释放连接,恢复挂起事务等
cleanupAfterCompletion(status);
}
protected void doRollback(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
// jdbc的回滚
con.rollback();
}
回滚事务,简单来说 调用JDBC的rollback 和 清除数据
尼恩总结
很多的小伙伴,当时对 Spring 懵懂无知,或者,看完源码,转眼间忘记了
非常痛苦
看了此文,记住尼恩梳理的2大模式和三大核心流程
再也不会忘记Spring事务的核心源码了。
通过这篇顶奢好文,99.99% 的人应该都可以理解了 Spring 事务 的来龙去脉.
如果做不到,可以看10遍,一定就可以做到了。
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
尼恩 架构笔记、面试题 的PDF文件更新,▼请到下面【技术自由圈】公号取 ▼