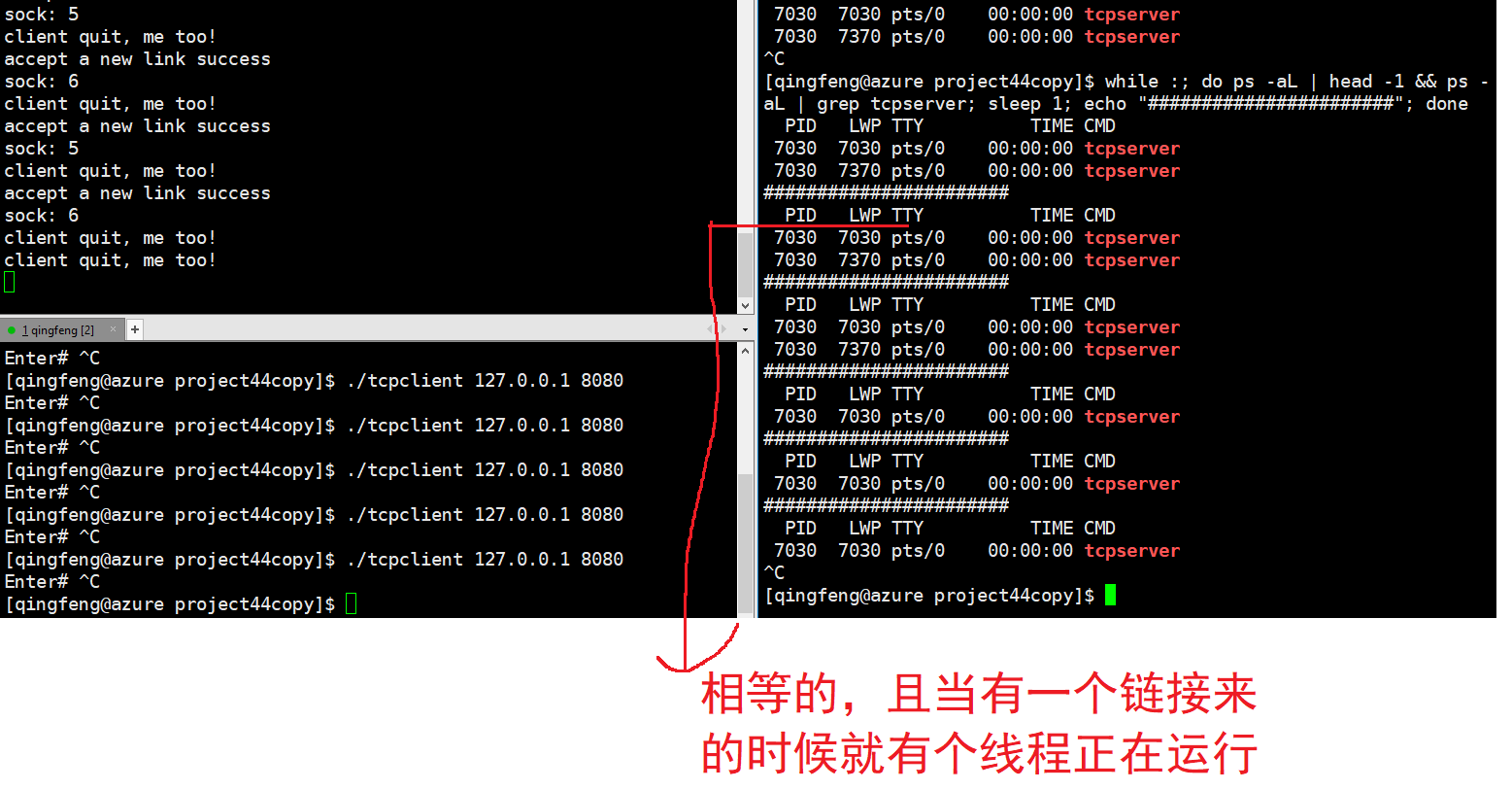
文章目录
- 0. 前言
- 1. CPU vs GPU
- 2. 并行计算简介
- 3. CUDA 简介
- 4. CUDA 的处理流程
0. 前言
在没有GPU之前,基本上所有的任务都是交给CPU来做的。有GPU之后,二者就进行了分工,CPU负责逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务(大规模计算任务)。
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。
NVIDIA 和 AMD 是主要的独立显卡制造商,其显卡分别称为N卡和A卡;N卡主要⽀持CUDA编程,A卡主要⽀持OpenCL编程。NVIDIA 公司是GPU界的⻰头,其GPU产品占市场份额的80%左右。
1. CPU vs GPU
本节推荐看博客 CPU和GPU到底有什么区别?
CPU 和 GPU 的架构如下图所示:

可以形象的理解为:
CPU 有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)
GPU 有 90%的ALU(运算单元),5%的Control(控制单元)、5%的Cache(缓存单元)
因此二者的架构不同,导致了不同的特点:
CPU: 强控制弱计算,更多资源⽤于缓存
GPU: 强计算弱控制,更多资源⽤于数据计算
因此 GPU 在设计时更多的晶体管用于数据处理,而不是数据缓存和流量控制,,可以高度实现并行计算。
此外,GPU的优势还有:
- 专注于浮点运算 / 性价比高:GPU在设计时避免或减弱了类似分⽀处理、逻辑控制等与浮点计算⽆关的复杂功能,专注于浮点计算,因此在制造成本上有着巨⼤优势。
- 绿⾊功耗⽐:GPU集成了⼤量的轻量级微处理单元,时钟频率有限,使得运算产⽣的功耗极⼩。
NVIDIA公司有三个主流的GPU产品系列:
- Teals 系列:专为⾼性能计算设计、价格昂贵;如著名的深度学习训练神器 A100、V100、P100 都是 Teals 系列
- Geforce 系列:专注游戏、娱乐,当然也可以用于深度学习计算;如 Geforce RTX 3060、Geforce RTX 4090 等
- Quadro 系列:专为图形图像处理⽽⽣,我个人没用过,不做介绍。
2. 并行计算简介
并⾏计算是指使用多个处理器共同解决同⼀个问题,其中每个处理器承担计算任务中的⼀部分内容。
并行计算包括时间并行(流水线式独立工作)和空间并行(矩阵分块计算),需要保证负载均衡和通信量小(CPU和GPU之间的通讯)。
并行计算的前提是应⽤问题必须具有并⾏度,即可以分解为多个可以并⾏执⾏的⼦任务
单独的⾼性能计算节点主要分为:
- 同构节点:仅采⽤相同厂家的硬件,如 CPU,Intel Xeon CPU、AMD Opteron CPU
- 异构节点:使用不同厂家的硬件,分为主机端和设备端,分别注重逻辑运算和浮点计算。一般的并行计算都是异构节点。
3. CUDA 简介
CUDA (Compute Unified Device Architecture),通用并行计算架构,是一种运算平台。CUDA 由 NVIDIA 公司在 2007 年发布,⽆需图形学API,采⽤类C语⾔,开发简单。
CUDA 是一种专⽤异构编程模型,CUDA是基于C语⾔的扩展,例如扩展了⼀些限定符 device、shared等,从3.0开始也⽀持 C++ 编程。
基于 CUDA 开发的程序代码在实际执⾏中分为两种:
- 运⾏在CPU上的宿主代码(Host Code)
- 运⾏在GPU上的设备代码(Device Code)
运⾏在 GPU 上的 CUDA 并⾏计算函数称为 kernel函数(内核函数),⼀个完整的 CUDA 程序是由⼀系列的设备端 kernel 函数并⾏部分和主机端的串⾏处理部分共同组成的。
kernel 在GPU上以多个线程的⽅式被执⾏,我们学的 CUDA 编程主要就是学怎么写 kernel 函数
4. CUDA 的处理流程
CUDA 的处理流程为:
- 从系统内存中复制数据到 GPU 内存
- CPU 指令驱动 GPU 运⾏
- GPU 的每个 CUDA 核⼼并⾏处理
- GPU 将CUDA处理的最终结果返回到系统的内存
CUDA 程序执⾏的基本流程为:
- 分配内存空间和显存空间
- 初始化内存空间
- 将要计算的数据从 Host 内存上复制到 GPU 内存上
- 把自己的程序写成 kernel 函数,执⾏ kernel 计算
- 将计算后 GPU 内存上的数据复制到 Host 内存上
- 处理复制到 Host 内存上的数据